面向网络传输的无损压缩算法优化研究
2012-09-03周国祥
孙 超, 周国祥
(合肥工业大学 计算机与信息学院,安徽 合肥 230009)
0 引 言
进入信息时代,人们逐渐对数据压缩已不再陌生,数据压缩软件已成为计算机的必备软件,而一些不易被人们察觉的数据压缩也渗透进入生活中。大多数多媒体文件标准中都内嵌了压缩算法,例如,数码相机拍摄的JPG格式图片是由BMP格式文件压缩而成,但体积只有原来的1/10;MP3格式音频文件也是由CD格式文件压缩而来,体积也只有原来的1/10。近20年,LZ系列无损数据压缩算法日趋成熟,在实践中被广泛应用,包括著名的软件 WINRAR、WINZIP。该系列算法以LZ77衍生的LZSS算法和LZ78衍生的LZW算法最突出,在日常使用中最多。
1 优化思想分析
近年来由于信息技术的飞速发展,计算机软硬件性能都得到大幅度提高,压缩/解压缩的计算能力已不再是考虑的重点。而网络传输的瓶颈现象日益显现,高压缩率更符合实际的需求。使用无损数据压缩算法时,主流的LZW算法或LZSS算法对不同数据文件压缩的效果有时候区别很大,这是因为无损数据压缩算法的收敛速度还与数据文件本身属性有关。网络上传输量极大的图形界面文档文件、图像图形文件、超文本文件等大多属于LZW算法收敛速度快的数据文件[1],所以本文采用LZW算法为主体的方法,结合LZSS算法中一些巧妙的方法,形成一个新的算法应用于当前网络。
LZ77算法由文献[2]提出,该算法是把数据压缩从Huffman和算术编码的思路中解放出来。LZ77算法巧妙运用类似于查字典的方法,运用了近邻原则,在压缩的数据流中设2个窗口,即滑动窗口和前向缓冲区。
将2个窗口比较后编码,使用1个三元组〈offset(偏移量)、length(匹配长度)、char(字符)〉代替输出。
LZSS算法是由LZ77算法发展而来,改变了对滑动窗口查询的方法,由顺序遍历变成了二叉树遍历,大大提高了匹配的查询速度;另外,将三元组的输出方式改变成二元组〈offset(偏移量)、length(匹配长度)〉的方式。
LZ78对LZ77做了修改,最大的变化就是改变了字典的构成方式[3]。LZ77使用临近的已编码部分作为字典;而LZ78的字典是一个潜在的先前所见短语的无序序列,先将数据流与字典中的记录项进行对比,当查询到不能匹配的数据时,则将新的结果添加到字典中,再输出原查询到的最长的匹配。
LZW是LZ78的变种,最大的特点是预先对所有单字符(256个)进行了加载,这样输出中就不会有单字节。
2 优化算法原理
LZW算法有2个致命的弱点,一是自适应速度缓慢;二是旧字典满了后清除,再重新建立字典,初期压缩率会急剧下降。
LZSS算法虽然可以获得较高且稳定的压缩率,但是由于使用的是二叉树进行遍历查询,造成压缩速度过慢,并且对大文件的压缩率不够理想。
LZW算法必须有足够的前置代码建立一个足够大的字典后,才能达到最佳的压缩率,而LZSS算法较好地克服了这一难题。
例如字符串“ABCDABCD”,LZW算法需要“ABCD”出现4次才能将整个字符串添加到字典中,而LZSS在“ABCD”出现第2次就可以对其进行整体压缩。文献[1]提出过一种组合使用LZ78和LZ77的思想,定义一个相似结构的字典表,在字典构建初期使用LZ77算法,当字典足够大时再进行字典转换使用LZ78算法,该思想规避了2种算法的弱点。
本文受其启发,并且将该思想进行了发展,吸收2种算法构造字典方法的优点[4-5],运用偏移编码的方法,通过生成一个字典表和一个与之关联的字典编码表,创新地修改了压缩的输出方式,进一步提高了压缩效率。
改进的压缩算法生成字典的基础方法是使用LZW算法的字典构造法,同时在字典构造的过程中变通地引入LZSS算法的滑动窗口偏移编码思想,将滑动窗口演变成一张与字典每个记录都有关联的字典编码表(表在压缩/解压缩过程中建立,不需要传输)。压缩数据的输出是通过字典和关联的字典编码表共同决定,首先输出字典记录,然后通过关联找出偏移匹配项,最终组合输出压缩数据。
通过对输出方式和字典结构的优化,优化算法可以在更高效地获得2种算法优点的同时,避免构建字典过程中2种算法的频繁切换。特别是在字典建立初期和中期,最大限度地提高了压缩率;其次偏移匹配有效地增加了各个字典记录的联系,可以实现对原文中相邻的字符串进行跨字符串压缩,在相同的规模下字典将包含更大的信息量,有效地减少了字典重建的次数,始终保持着较高压缩率的状态。
字典编码表的偏移匹配借助于字典的Hash查找,极大地提高了查找的速度[6],提高了整体的压缩速度。
实现这个方法的核心就是改变原来的字典结构[6],添加1个编码字节偏移位置索引的属性,建立1个四元组字典:

long Order-index;/* 编码字节偏移位置索引*/}
再建立1个字典编码表来维护1个与当前字典对应的已编码字符窗口,每读入1个待压缩字符时,字典编码表也实时更新,字典满后初始化时也会将字典编码表初始化,压缩/解压缩时可以通过字典快速索引,找到其在字典编码表中的相对位置。例如,Order-index=3,则表示该符号代码所对应的后续偏移匹配从字典编码表中第3位开始比较。
此时,算法输出发生了变化,有2种输出方式,为了区别2种输出格式的输出数据,在输出前需要增加标志位用来标记是哪种输出格式[7]。一种是原LZW算法输出方式,使用“11”作为标志;另一种是新增的算法输出格式,使用“10”作为标志。对于第2种输出格式,为了增强算法的适应性,本文引入参数调节机制,在LZW字典最大匹配位置后加入了L位,用来表示后续匹配的字符偏移长度。
例如,字符串“ABCDEFABCDEFABCDEF”。使用一般LZW压缩过程和结果见表1所列,压缩后的输出为“ABCDEF(259)(261)(263)(265)(262)F”,字符串在字典中添加了11组数据,并且输出需要12组数据。
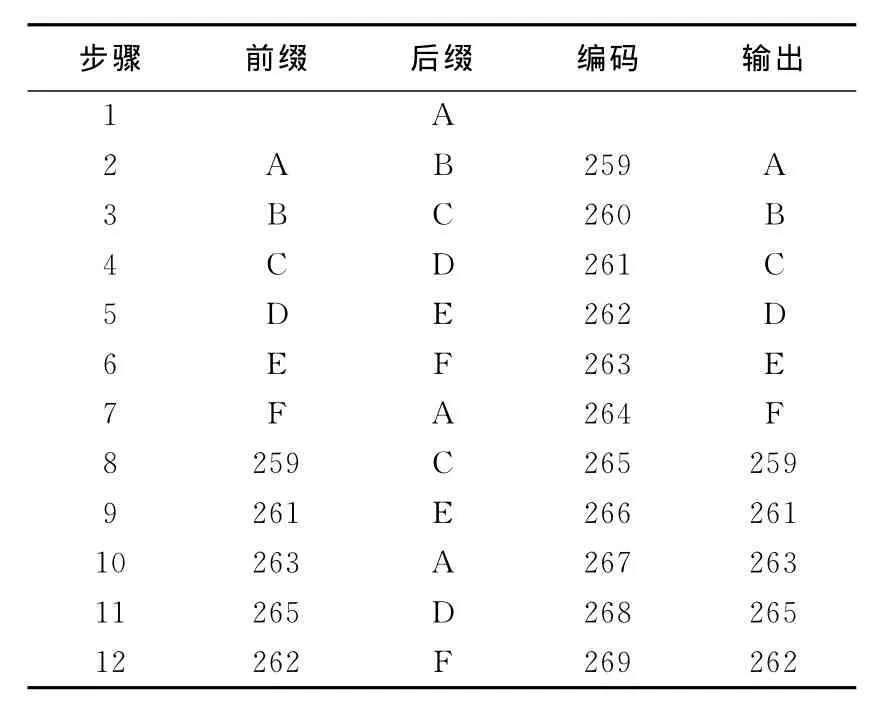
表1 LZW算法字典
优化的压缩算法过程和结果见表2所列(设定匹配最大值L<8),同时维护后完整的字典编码见表3所列,压缩后的输出为“ABCDEF(258+7)262”,字符串在字典中只添加了8组数据,并且输出只需要8组数据。
比较可知,对于相同的数据,优化的方法减少了压缩后的输出数据,同时有效地减少了字典中存储记录数量,优化方法是有效的。
具体压缩算法流程如图1所示,其中L为一次匹配成功的偏移长度。
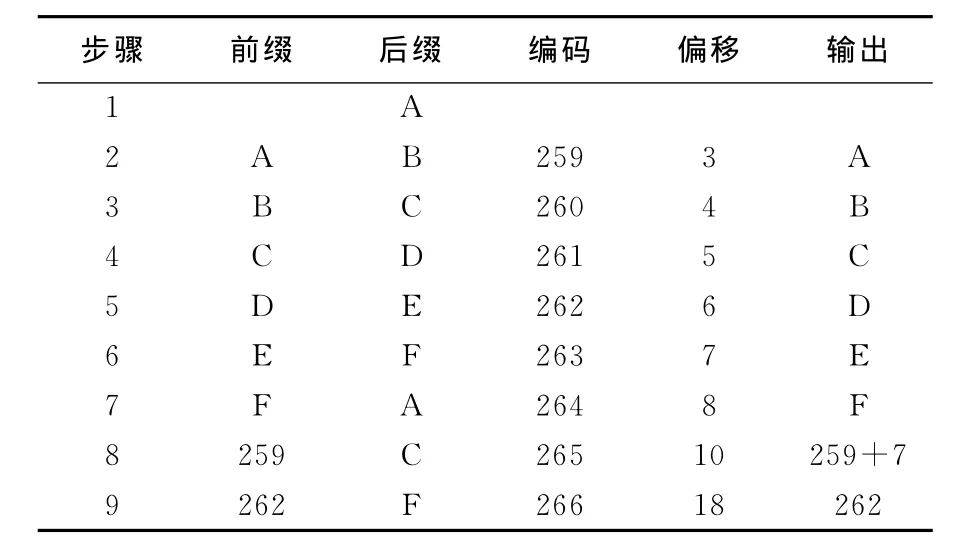
表2 优化的LZW算法字典
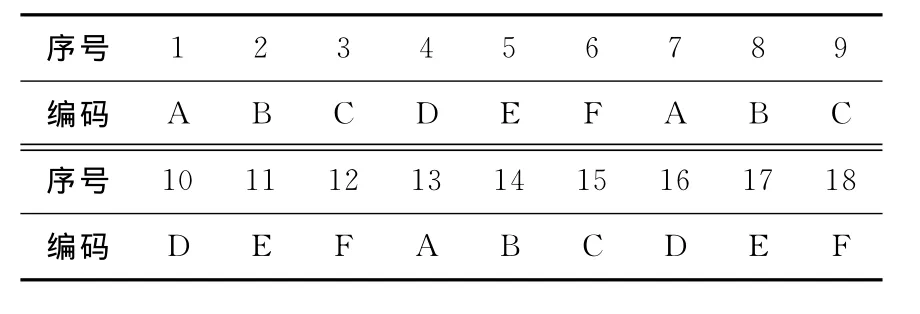
表3 完整的字典编码

图1 优化算法流程
改进算法的核心是字典编码表的维护和偏移编码统计,在前7个步骤中,字典中没有前缀的压缩记录,每次都是向字典编码表中写入1个刚刚接收的待压缩编码字符,见表4所列。

表4 前7个步骤后字典编码
第8个步骤中,字典编码表会分2个部分接收待编码字符。
(1)第1部分来源为构造字典记录项。由于有前缀记录可以压缩,将压缩部分的字符维护到字典编码表中,结果见表5所列。

表5 第8个步骤构造字典后字典编码
(2)第2部分来源为压缩输出计算偏移编码匹配。首先查询前缀字符,本例中前缀记录编码Hash-code为259,字典编码表匹配首位置Order-index为3,比较得3位置的字符与后缀字符是一样的,选择使用改进的压缩数据输出方式,并且开始统计偏移字符的匹配情况,读入下一个待压缩的字符“D”,写入字典编码表中,见表6所列。判断与前缀记录的字典编码表匹配首位置加1位置(即4位置)相同,匹配统计累加。

表6 第8个步骤偏移匹配第1次成功后字典编码
如此反复,最终第8个步骤完成时,形成的字典编码见表7所列。
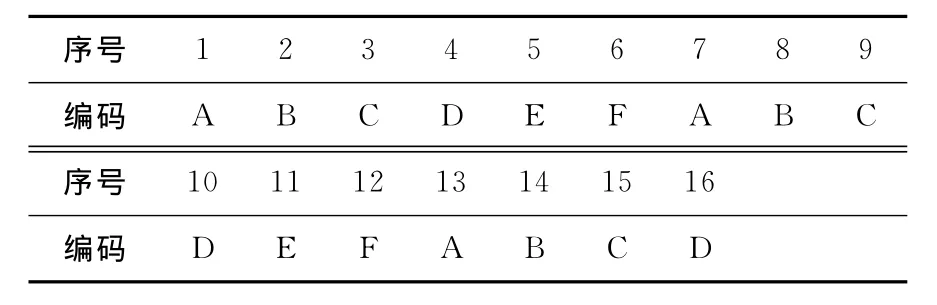
表7 第8个步骤后字典编码
3 算法性能分析
3.1 压缩比RC
为方便与信源的熵值做比较,引入压余率的概念。压余率P代表源文件每字节压缩后平均所占的位数,它与压缩比的转换为即压余率越低,压缩比越高。
改进算法的压余率主要由字典和字典编码表决定。改进算法字典相似于LZW算法的字典构造,而字典编码表则是由LZSS算法的滑动窗口演化而来,故提取这2种算法压余率作为性能分析的标准。
(1)LZSS算法总的压余率:
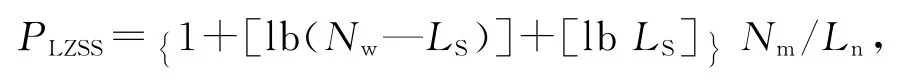
其中,Nw代表滑动窗口缓冲区的大小;LS为预定最大匹配长度;Nm为总的拆分的段数;Ln是源文件的长度。
(2)LZW算法总的压余率:

其中,Lc为单位编码位长度;Y为信源字符串;A为信源字符集合。
优化算法的压缩分解成压缩初期R1和压缩中后期R22个部分。
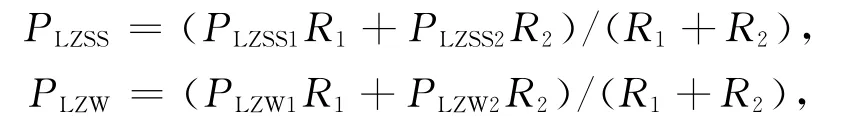
改进算法总的压余率为:
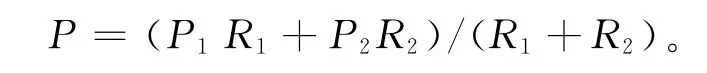
对于改进的压缩算法,压缩初期,压余率P1依靠字典编码表可达到和LZSS算法初期一样低的压余率,再通过字典记录项的匹配又可能部分降低了压余率,故P1<;在压缩中后期,压余率P2依靠字典可以获得一样低的压余率,并且可以查询字典编码表信息进行跨记录项的匹配压缩,故P2<。
改进的压缩算法的压余率将低于LZW算法和LZSS算法,以及它们任意的最优组合算法。
3.2 压缩速度
压缩速度主要取决于对字典的搜索和更新速度,而相对的编码时间开销很小。在优化算法中,字典的更新和搜索使用的是Hash查找算法,这是一种高效的查找算法,有力地保证了优化算法的压缩速度。
4 算法验证
对于判断压缩算法的优劣,最重要的性能评判因素是压缩比和压缩速度。压缩比计算方法为文件压缩前后的字节大小比值,压缩比越高,压缩速度越快,算法性能越好。
使用LZ系列压缩算法,其特点是对于不同的类型文件压缩的效果会有一定的差异,这是待压缩文件的结构和内容所决定的。所以,对于不同的类型文件,应当选择合适的允许最大偏移匹配个数[8]。
本算法主要面向网络压缩传输,压缩的文件主要为图形界面文档文件、图像图形文件、超文本文件。将该算法嵌入新开发的网站代码中,实际检测算法压缩效率。
(1)采用从9位开始最大12位编码的LZW9-12算法为基础进行优化。
(2)本文重点研究无损网络压缩传输,使用网站的HTML文件作为实验样本,为了得到更加准确的结果,选取3个不同大小的文件增加实验的准确性。
(3)扩展位从3位起最大到9位,准确测试网络传输中最合适的参数设置。
测试参数结果见表8所列,由于压缩时间全部分布在810ms以内,都在可以接受的范围内,故压缩时间已不是重要的考虑因素。
图2所示为本次实验3种不同大小文件在不同参数下的测试结果对比,可以直观地看到偏移扩展位为6位时,获得的整体压缩比最优[6],压缩比提高的幅度在0.49~0.84之间。
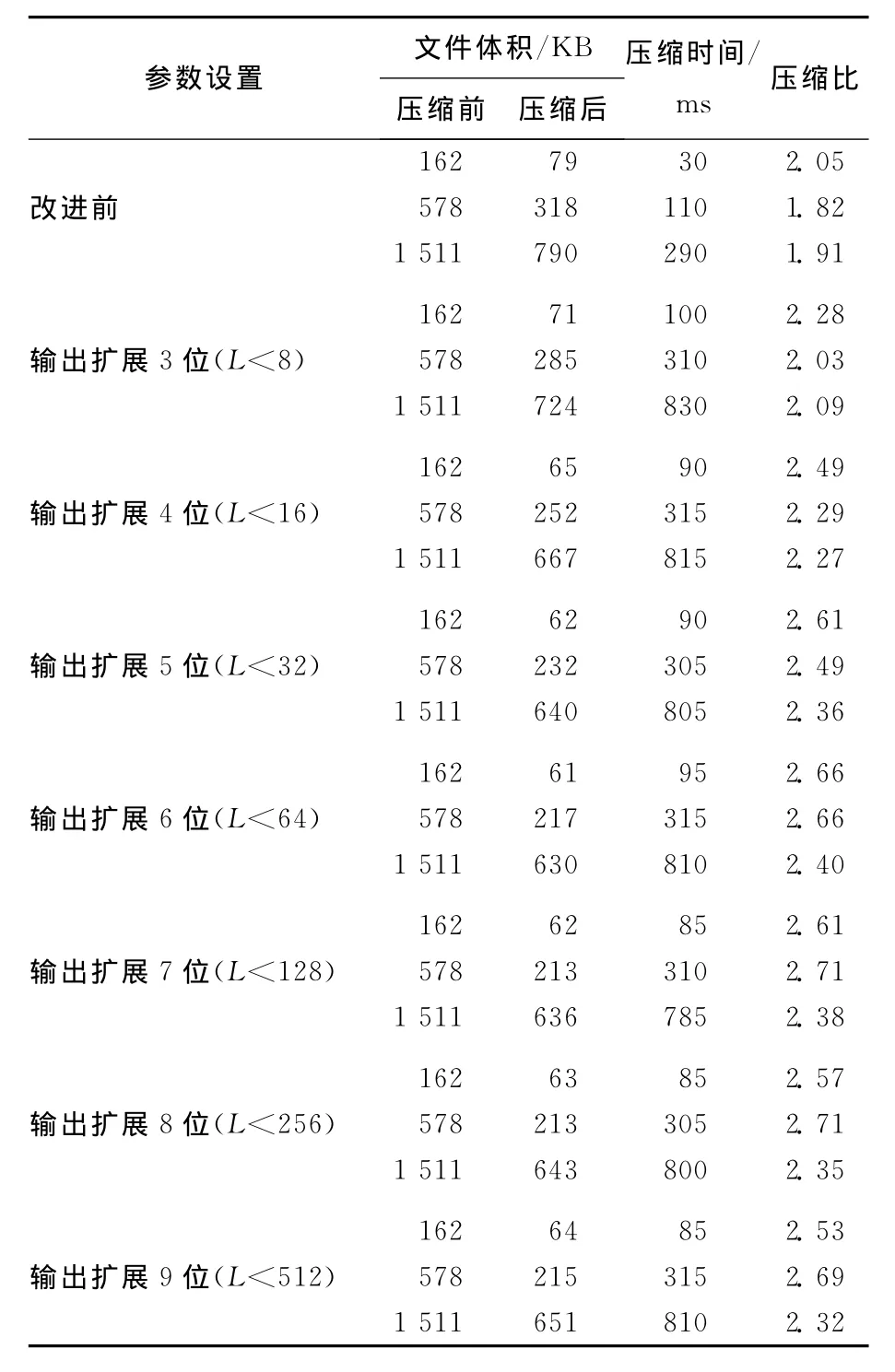
表8 测试结果统计表
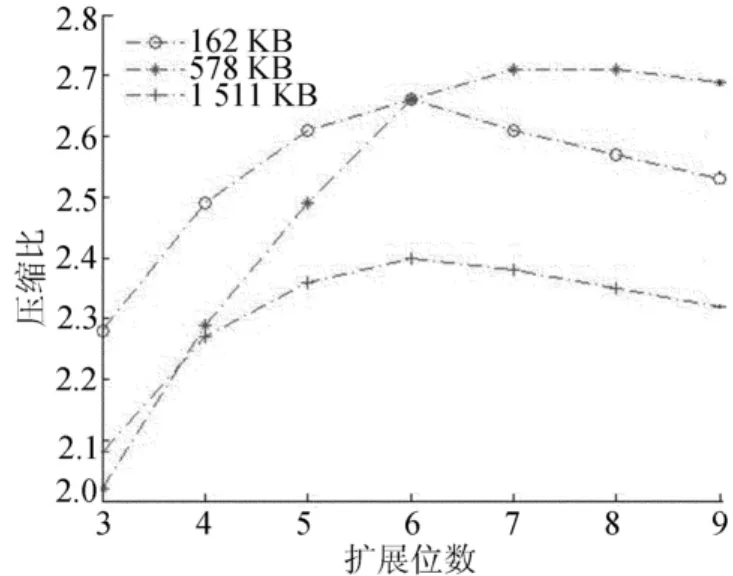
图2 测试结果图
5 结束语
本文提出了一种新颖的组合使用LZ压缩方案,有效地对LZW算法进行了改进,更好地适应现实网络使用环境的需求。但是,改进算法尚有进一步改进的空间[9],例如,可以用多字典代替单字典避免字典重建时的低压缩率,引用反馈机制自动调节参数维持高压缩率等。
[1]华 强.LZ77和LZ78在数据压缩中的组合带参运用[J].小型微型计算机系统,2000,21(2):211-215.
[2]Ziv J,Lempel A.A universal algorithMfor sequential data compression[J].IEEE Transactions on Information Theory,1977,23(3):337-343.
[3]Ziv J,Lempel A.Compression of individual sequences via variable-rate coding[J].IEEE Transactions on Information Theory,1978,24(5):530-536.
[4]张 燕,王 沁,余文裕,等.宽带接入网中的动态压缩技术[J].计算机工程,2009,35(23):27-29.
[5]胡浪涛,何辅云,沈兆鑫.油气管道高速漏磁检测系统中数据压缩研究[J].合肥工业大学学报:自然科学版,2009,32(3):320-323.
[6]张凤林,刘思峰.LZW*:一个改进的LZW数据压缩算法[J].小型微型计算机系统,2006,27(10):1897-1899.
[7]许 霞,马光思,鱼 涛.LZW无损压缩算法的研究与改进[J].计算机技术与发展,2009,19(4):125-129.
[8]任学军,房鼎益.一种适合无线传感器网络的混合编码数据压缩算法[J].小型微型计算机系统,2011,32(6):1055-1058.
[9]何 岳,王素玉,沈兰荪.高光谱图像无损压缩算法的DSP优化实现[J].计算机应用研究,2008,25(1):178-180.
