关于语义相关度一些技术的探讨*
2012-09-02陈洪生吴守华
陈洪生,吴守华
(1.湖北科技学院 计算机科学与技术学院,湖北 咸宁 437100;
2.通城县地方税务局,湖北 通城 437400)
与前些年的信息资源匮乏相比,现在信息用户更加关注的是如何从海量的信息资源中发掘其所需要的信息.信息资源异构性的存在,尤其是语义异构性的存在,使得采用传统以字符串匹配为基础的信息检索系统难以满足用户对信息和知识的深层次需求,因此,加强基于概念匹配的信息检索系统的研究就显得尤为重要.简而言之,概念匹配就是计算词语之间的语义相似度[1].与传统的以词形为切入点、建立在词语字面匹配基础上的检索算法相比,语义相似度计算是对源和目标词语间在概念层面上相似程度的度量,需要考虑词语所在的语境和语义等信息.在我国,以知网[2]为基础的词汇相似度计算是较好的方法之一,并在机器翻译、信息检索、文本分类、文本聚类答问、案提取、答系统等领域有着一定程度的应用;刘群[3]等人提出的方法可以解决同一特征文件中义原间的语义相似度问题,但不能解决不同特征文件义原间的语义相关性问题.李素建[4]将知网和同义词词林结合起来计算不同特征文件中词语的相似度,在一定程度上解决了不同特征文件间词语的语义相关性,但是知网和同义词词林词语的组织方式完全不同,所以计算结果不是很理想;许云[5]、王广正[6]等提出了各自的语义相关度计算方法.
1 语义相关度
研究语义相关度评价方法会牵涉到语义相似性和语义相关性问题,在具体的研究前,先对基本概念做出解释.语义相似性是指主题间有共同特性,意义相似;而相关是指在人的直觉中两个主题关联,关联的原因多种多样,可以说语义相似是语义相关一种特例,相关性是比相似性更普遍一个概念.除了语义相关和语义相似,语义距离被用于度量主题间的相关性,它被视为语义相关的逆,即主题间语义距离越小,则语义相关度越大.研究中具体采用哪种概念作为语义关联的度量取决于相关度评价方法构建,同时指出文中常提到的关联量化及相关度评价两个名词都是对相关性度量的称谓.
目前,根据语义相关度评价方法依赖的知识资源区分,主要有两类评价方法:分布方法和基于本体的方法.国内学者通常把分布方法称为统计方法(Distribution Measure),把基于本体的方法(Ontology—Based Measure)称为语义词典方法.分布方法是对大型文本语料库进行统计分析,通过判断两个单词的上下文(上下文是由一些共现词组成的)的相关程度,间接计算单词对的相关度[7].分布方法计算相关度依赖语料库知识资源,计算结果的准确度外部受语料库的规模、质量、专业性的影响,内部受共现词的出现窗口大小、句型结构的选择等因素的影响,具有局限性;基于本体的方法[8]是以某种方式,把知识资源构建为网络或者有向图,使之形成一个确定的概念化体系,基于图中概念间连通的路径属性来计算相关度.基于本体的方法计算相关度依赖本体资源的质量,主题图本身是一种针对专业领域构建的知识本体,且主题间的相关度具有强烈的领域特色,例如说:主题对“空间”和“时间”在量子力学中关系非常相似,但在其他大部分领域中都并不那么相近,主题间的语义相关度无法脱离特定的主题图本体而独立得出,因此基于本体的方法适用于衡量主题间的相关度[9].
目前,基于本体的方法主要是基于WbrdNet语义词典的方法,在详细讨论下述基于本体的语义相关度评价方法时,首先给出一些符号、概念的定义:
(1)同义词集c1到同义词集c2的最短路径的长度用len(c1,c2)来表示;
(2)一个节点的深度是指从该节点到根节点的路径的长度;
(3)c1和c2的最近共同父类,即同时包含才c1和c2并且深度最大的类,记为lso(c1,c2);基于本体的语义相关度评价方法通过主题间路径的属性来计算相关度,本体作为一个分类层次化语义网络体系,网络结构的局部密度、主题节点在网络层次中的深度、网络中蕴含的连接类型、主题间的路径长度、连接强度都是影响语义相关度的关键因素.
2 语义相关度中的技术
2.1 基于词关联度的语义相关度
此方法是基于向量空间模型以及信息论,提出一个与文章内容相关的语义相关度算法模型.该模型将文章语义抽象为词频表,并通过机器学习构建词语之间的关联度表,以此词关联度为基础,计算文章之间的相关度,此方法可以有效的根据文章之间的语义相关度大小进行排名[10].
2.2 基于相关数据库的语义相关度计算
目前有很多公开的数据库供研究者使用,特别是如维基百科、知网等很多数据库都可以使用,当然有很多基于这些数据库的语义相关度研究,刘军等在[11]文中提出基于Wikipedia的语义相关度计算方法.在构建Wikipedia类别树的基础上,通过 Wikipedia类别向量表示Wikipedia中的词汇,形成一部包含各种领域知识的 Wikipedia词典,利用该词典计算语义相关度.张振幸等在[12]文中以知网理论相似度计算为基础,提出了一种计算词语相关度方法;该方法将知网中不同特征文件间的义原通过其解释义原与其它特征文件中的义原建立联系,进而计算它们之间的相关度,并用该方法提取文本特征,实验结果表明,该方法更趋于合理,绝大部分结果更符合人们的日常体验 ,有效提高了计算结果的精确度和准确性.
2.3 中文语义相关度计算的研究
目前,国外学者对于语义相关度的评价方法的已做了较为深入的研究,它可以分为两类,一类是基于语义词典的方法,一类是统计的方法[7].其中基于语义词典的方法大多基于WordNet提出的许多度量语义相关的度量方法.但是,国内在语义相关原理和应用方面的研究还比较欠缺,特别缺少在中文环境下的分析与应用,大多数的研究都选择英文环境,少部分采用中文环境.如颜伟和荀恩东计算了WordNet中英语单词的相关度[13],孙爽和章勇提出了基于语义相似度的聚类算法[14],但是他们研究的语言环境还是英语.在中文环境下,章成志介绍了上文若干种度量方法[15],但没有进行相互之间的比较,刘群和李素建基于知网提出新的度量方法,但仍囿于知网的规模相对较小[3].李峰等人根据现有的方法,提出了多个相似度计算公式,但比较时实验集很小,并且缺乏在实际应用中的比较[16].Raftopoulou P[17]等在文中提出了一个新的语义相关的定义,认为两个词所表达的概念之间,如果存在用类似“知网”的知识描述体系所描述的语义关系,那么这两个概念之间就是语义相关的.通过挖掘这些直接或间接的关系,提出了一种新的语义相关度的计算模型,适用于所有类似知网的知识体系中语义相关度的计算.最后将该计算模型应用于词义排歧,验证了该计算模型的有效性.
2.4 基于本体的语义相似度计算方法
目前,基于本体的语义相似度计算方法研究已经形成了丰富的研究成果,语义相似度和语义距离之间存在着密切的关系:两个词语的语义距离越大,其相似度越低;反之,两个词语的语义距离越小,其相似度越大.词语语义距离的计算方法基本上可以分为两类:基于某种世界知识的计算方法和基于大规模语料库的统计计算方法[16].本体概念体系可用层次树来描述,其中节点表示本体中的概念词;边表示本体中概念词与概念词之间的关系.一般来讲,概念范畴较广的概念词在树中的位置一般比较高,周围节点密度相对较少;概念范畴较为具体的概念词在树中的位置相对较低,且周围节点密度相对较大.因此,树中概念词间语义相似度计算主要受以下因素影响[17-19]:
(1)被比较概念词在本体层次树中所处的深度
在本体层次树中,概念词所处层次越高,越抽象;所处层次越低,越具体.高层次的概念词间的语义相似度一般小于低层次概念词间的语义相似度.因此,路径相同的两个节点,高层次节点所表征的语义距离要大于低层次节点所表征的语义距离.
(2)被比较概念词在本体层次树中所处区域的密度
在本体层次树中,局部区域密度越大,说明该区域对节点概念的细化程度也越大.因此,对组成被比较概念词连接路径的各个边来说,其在本体层次树中所处的密度越大,对应的权重也应该越大.
(3)被比较概念词连通路径上各个边的类型
在本体中,不同的概念关系所表征的语义相似度是不同的.例如,“同义关系”所表征的语义相似度应大于“整体-部分关系”所表征的语义相似度.
(4)被比较概念词连通路径上各个边在本体层次树中的关联强度
在本体层次树中,一个节点可能与多个节点相连接,但这些节点的重要程度通常存在差异,因此,相应的连接边对语义相似度的影响也必然不同.
(5)被比较概念词连通路径上各个边的两端节点概念词的属性
本体,尤其是领域本体,不仅会对概念及其关系进行准确定义,还会对概念的属性进行详细描述.如果某条边两端的概念词所用的相同属性越多,那么其对语义相似度的影响也越大.
国内外精典计算模型有以下一些方法:基于距离的语义相似度计算,基于信息内容的语义相似度计算,基于属性的语义相似度计算,混合式语义相似度计算,基于概念向量模型的语义相似度计算等.孙海霞等在[20]文中在对基于本体的词语语义相似度进行界定的基础上,对基于本体的语义相似度研究进行综述,分别阐述基于距离的语义相似度计算、基于内容的语义相似度计算、基于属性的语义相似度计算和混合式语义相似度计算等算法模型,最后从宏观层面指出今后本领域的研究方向.
2.5 使用时间语义分析计算单词间相关度
计算语义相关度在语言应用中非常重要,如查找、聚类、消除歧义等方面.以前的计算语义相关度的方法大部分都采用了静态语言资源,而忽略了它们时间的影响,其实通过学习过去一段时间的单词使用样式是可以找到单词间的相关性信息的.比如说,我们考虑很多年的报纸存档信息,两个单词“战争”与“和平”,也许这两个词很少在同一个文章里使用,但是它们的使用样式在过去一段时间里也许是相类似的.在文献[21]中,作者提出了一种新的语义相关度模型,时间语义分析(TSA),这种方法获取时间信息.以前的研究方法,直接语义分析(ESA)通过概念向量来表示单词的语义.TSA使用了一种改进的表示方法,每个向量不再是一个标准值,而是过去一段时间的文档的一个时间序列,并且这是第一次尝试将时间信息放入语义相关度分析模型中.
在文献[21]中,主要贡献如下:首先,作者提出了使用时间信息作为发现单词间语义相关的的互补资源,尤其是,作者介绍了时间语义分析,这改变了一些信息并计算出了语义相关改变度.然后,作者构建了一个新的语义相关度的数据库,并且通过Amazon'sMechanical Turk提供的服务进行了评价,最后实验结果显示TSA比ESA性能优越性好很多.
时间语义分析(TSA)主要包含两部分,自然语言中字词的语义表示和字词间语义相关度的计算.作者的方法是建立在每个单词与一个有一定权值的概念向量表示,这种概念向量可以从维基百科,Flickr或者从在线书签服务来表示,这跟最近的语义分析方法ESA很相似.然而,ESA使用的是静态语义表示每个向量,作者使用了概念度即通过这一概念发生的时间序列表示时间变化行为.因此,不仅仅是用一个单位向量来表示一个单词,向量的时间序列也加入进来,每个时间序列通过时间概念度来描述.我们的假设是概念行为随着时间是类似的,那么语义就相关.TSA有三个步骤:
(1)把单词通过概念向量表示:通过概念库选择(Wikipedia or Flickr im-age tags)
(2)提取每个概念的时间度:通过使用文档选择(NewYork Times archive)
(3)把时间段扩展到静态表示中去
下面我们分析一下文献[21]中TSA方法中的一些主要的思想及算法,首先看时间概念度(TemporalConceptDynamics)的计算,假设C是一个概念可以通过一系列的单词Wc1,….Wck表示,d表示一个文档.我们说如果每个单词对(Wci,Wcj),在文档d中出现的位置距离小于给定的一个值Q,那么就说C这个概念在文档d中出现过.一般的Q是一个近似松弛系数,在此文中作者设置此值为20,即单词对的间隔不超过20个.这也就是说一个概念在一篇文档中出现实际上就是有一个大小为Q的窗口包含了概念C中的所有单词.比如,有一概念“GreatFireof London”,我们说这个概念在一个文档 d中出现时指单词“Great”、“Fir”、“of”、“London”四个单词同时出现在它们间的距离小于Q个单词的文档d中.
T1……Tn表示连续的不相关的时间点(如天),H=D1….Dn表示文档收集集的历史表示,其中Di是跟时间Ti相关的文档收集.所以定义概念C的度可以用其出现在H中的频率的时间序列表示公式如下:
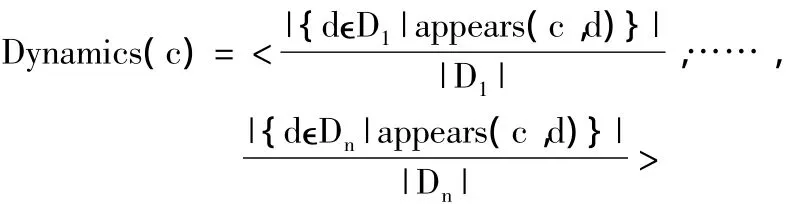
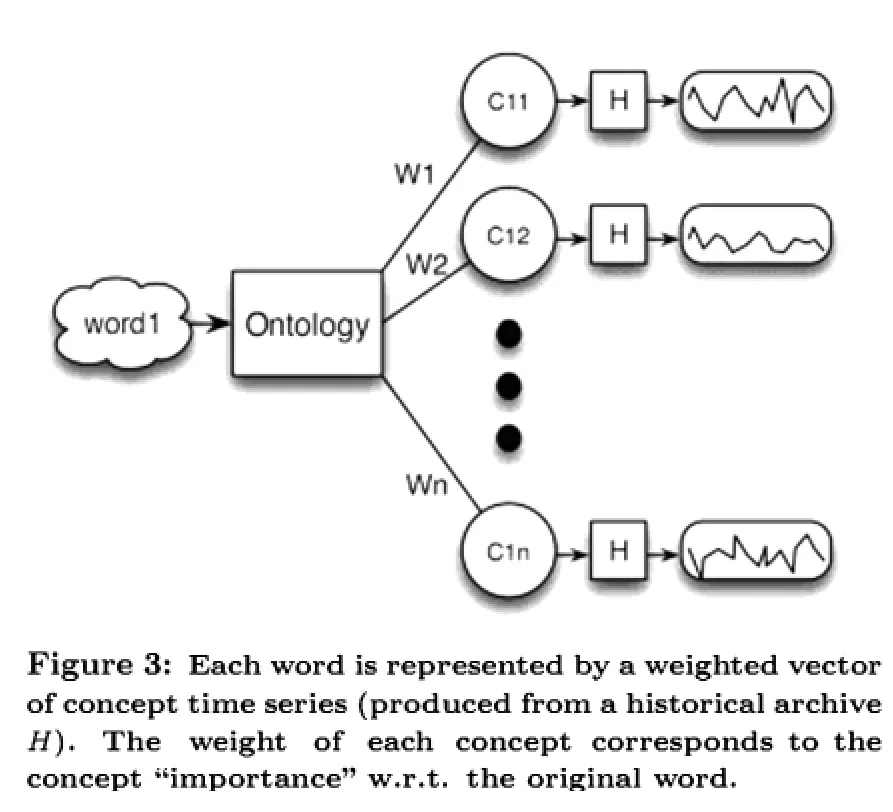
将时间信号扩展到静态表示中,作者用权重和概念时间序列混合来表示一个单词,权重相当于概念关于原始词意的重要程度,具体的表示如下图所示:
根据对以前文档的统计计算得出时间概念度之后,就可以使用TSA来计算语义相关度了,为了计算一对单词间的语义相关度,我们使用多个时间序列间权重距离测量来比较他们的向量,并且结合静态语义相似度概念测量方法.所以这个方法整合了单词的时间和静态意义行为.基于TSA的语义相关度算法如下:
作者仅假设高权重相关的概念单词也相关,假设我们想找到两个单词T1和T2之间的相关度,假设T1映射到一个概念集C(T1)={C11,….Cn1},T2映射到一个概念集C(T2)={C12,….Cm2}.假设有一个函数Q通过使用它们之间的概念时间度来决定两个单独的概念之间的相关度,并且假设n<=m,我们就可以定义T1与T2之间的相关度R为所有有序子集C(T2中每对概念相关度和的最大值,具体公式如下:
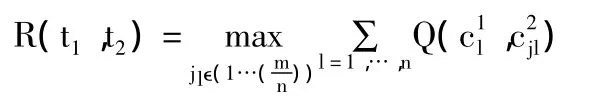
实际上如果按照以上的公式进行穷举计算求最大值是很难实现的,所以作者提供了一种取舍贪婪方法,在算法中每步是找出最高相关度的一对时间序列.然后在相应集合中删除它们,如此循环,最后通过求和得到一个相关度.此过程的时间复杂度为O(n*m*max(|ts|)),其中ts是表示概念的时间序列长度.
其中Q函数计算语义相关度的方法有两种即 交叉相关(CrossCorrelation)和动态时间包装(Dynamic TimeWarping),经过实验交叉相关在TSA中效果比动态时间包装(Dynamic TimeWarping)要好,故在文献[21]中采用的是交叉相关(CrossCorrelation)方法求语义相关度.
TSA方法性能上比ESA要好,但是也存在一些缺陷,TSA在识别复杂隐含联系时存在一些与人们认识不同的结果,也就是不能准确把握语义联系.存在这种问题的原因是作者所选用的时间序列文档集不够完全,太单一,没有涉及特殊领域的文档,如科学技术等,可以考虑增加一些时间文档,如博客、评论等信息.
对于文献[21],本人有一些不成熟的想法,此文提出的是一种新颖并且有效的方法通过语义分析来解决字词间相关性问题,并且通过实验验证了其想法的有效性.但是也有局限性如自己提到的由于使用的数据库的局限性本文中作者必然导致一些语义相近词鉴别不出来,可以针对性进行分类比较,比如科普性的、大众性的等,是否可以先对大量的文档进行一个分类,然后再进行统计计算效果应该会更好.
3 结论
本文对语义相关度中的一些技术及前沿方法进行了简要的介绍,主要从基于词关联度、基于相关数据库的语义相关度计算、中文语义相关度计算的研究、基于本体的语义相似度计算方法、使用时间语义分析计算单词间相关度进行了阐述,重点以文献[21]介绍了使用时间语义分析计算单词间相关度,并且提出了一些自己想法和有待于研究的问题,总之,在语义相关度中还有很多问题值得人们去思考,研究和实践.
[1]Semantic Similarity Measures in MeSH Ontology and Their Application to Information Retrieval on Medline[EB/OL].[2007 -12 -10].http://www.intelligence.tuc.gr/publications/Hliautakis
[2]董振东,董强.知网简介[EB/EL].http://www.keen2age.com.
[3]刘群,李素建.基于《知网》的词汇语义相似度计算[J].Computational L inguistics and Chinese Language Process zing,2002:59 -76.
[4]李素建.基于语义计算的语句相关度研究[J].计算机工程与应用,2002,(7):75 -77.
[5]许云,樊孝忠,张锋.基于知网的语义相关度计算[J].北京理工大学学报,2005,20(5):411 -414.
[6]王广正,王喜凤.基于知网语义相关度计算的词义消歧方法[J].安徽工业大学学报(自然科学版),2008,(1):71-75.
[7]Mohammat S,Hirst G.Distributional Measures as Proxies for Semantic Relatedness.In Submission[EB/OL].http://www.cs.toronto.edu/compling/publications.
[8]Budanitsky A,HirstG..EvaluatingWordNet-based Measures of Lexical Semantic Relatedness[J].Computational Linguistics.2006,32(1):13 -47.
[9]李丽冬,主题图的语义相关度评价方法研究,硕士论文,大连理工大学,2008.12.
[10]张增杰等,基于词关联度的语义相关度算法研究,微型电脑应用[J].2011,27(3).
[11]刘军,姚天昉,基于 Wikipedia的语义相关度计算[J].计算机工程,2010,(10).
[12]张振幸,李金厚,一种基于知网的语义相关度计算方法[J].洛阳师范学院学报,2010,4.
[13]颜伟,荀恩东.基于语义网计算英语词语相似度[J].情报学报,2006,25(1):43 ~48.
[14]孙爽,章勇.一种基于语义相似度的文本聚类算法[J].南京航天航空大学学报,2006,38(6):712 ~716.
[15]章成志.词语的语义相似度计算及其应用研究[C].//第一届全国信息检索与内容安全学术会议,上海,2004.
[16]李峰,李芳.中文词语语义相似度计算——基于《知网》2000[J].中文信息学报,2007,21(3):99 ~105.
[17]Raftopoulou P,Petrakis E.Semantic Similarity Measures:A Comparison Study[R],2005.
[18]黄果,周竹荣.基于领域本体的语义相似度计算研究[J].计算机工程与科学,2007,29(5):112 ~117.
[19]张忠平,赵海亮,张志惠.基于本体的概念相似度计算[J].计算机工程,2009,35(7):17 ~19.
[20]孙海霞,钱 庆,成 颖,基于本体的语义相似度计算方法研究综述[J].现代图书情报技术,2010(1).
[21]Kira Radinsky,Eugene Agichteiny,Evgeniy Gabrilovichz,and Shaul Markovitch,A Word at a Time:Computing Word Relatedness using Temporal Semantic Analysis,in proc ofWWW,2011.
