AHM分类方法的改良
2012-08-16韩裕娜张敏强
韩裕娜,张敏强
(1.华南师范大学心理应用研究中心,广东广州510631;2.华南师范大学基础教育培训与研究院,广东广州510631)
基于经典测验理论、概化理论和项目反应理论的传统测验最终只是给出一个分数或等级.然而有的考生分数或等级虽然相同,所掌握的知识却不同.为了通过测验从考生的反应模式中获得更多考生的信息,有些研究者提出“将认知与测量相结合”.按照不同的假设,提出了各自不同的方法和模型,并称这些模型为认知诊断模型.常见的认知诊断模型有规则空间模型(Rule Space Model,RSM)、属性层级模型(Attribute Hierarchy Method,AHM)、DINA 模型(Deterministic Input,Noisy-And gate,DINA)、NIDA模型(Noisy Input,Deterministic-And gate,NIDA)等.
本研究将在前人研究的基础上,对AHM模型2种基于IRT的判别方法——方法A和方法B进行改良,得到2种新分类方法——方法C和方法D.进而设计蒙特卡洛模拟试验考察4种分类方法的诊断性能.
1 AHM模型简介
AHM模型假设属性之间有一定的层级关系,并把观察反应模式划归为期望反应模式,该模型也采用了RSM模型的Q矩阵理论[1-3],两者的判别方法不同.RSM对被试的认知诊断是通过建构规则空间,采用距离判别法,将其判归为相应的典型属性掌握模式.AHM则是根据最大相似概率进行判别,将观察反应模式划归为期望反应模式.
使用属性层级模型进行认知诊断,共包含如下4 个步骤[4].
1.1 构建和表征测验内容的属性层级关系模型
属性间的层级关系共有4种基本关系(图1),其他复杂的关系可以由这4种基本关系组合生成[5].用邻接矩阵 A(adjacency matrix)来表征属性间的邻接关系.并通过布尔代数计算(布尔加和布尔乘)由矩阵A计算得到可达矩阵R(reachability matrix),用R来表征属性间的前提关系.
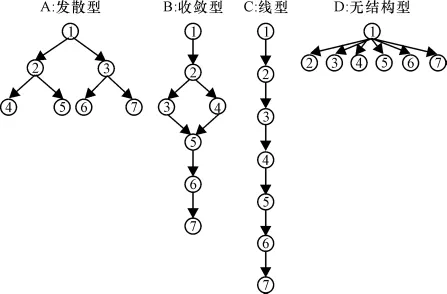
图1 4种不同的属性层级关系Figure 1 Four hierarchical structures using seven attributes
1.2 根据层级关系模型编制测验并施测
1.2.1 建立事件矩阵 Q 事件矩阵 Q(incidence matrix)k行n列,描述各属性与可能的项目类型间的关系.其中,k表示属性数目,n指可能的项目类型数,由组合数学可知n=2k-1.
1.2.2 建立缩减矩阵Qr建立缩减矩阵Qr目前有2种方法:缩减法和扩张算法.缩减法是由TATSUOKA提出的,先得到Q矩阵,然后删除不可能存在的项目类型.而扩张算法则是由R矩阵,通过扩张算法直接得到缩减矩阵Qr[6].
1.2.3 编制测验并施测 一般来说,在设计测验时,先选定可达阵R对应的所有题型作为测验的一部分,再根据所需依据矩阵Qr选择适当数量的题目类型构成测验,得到测验所对应的测验Q矩阵Qt.Qtk行n列,k表示属性数目,n指测验的项目数[7].
接着进行施测,得到被试的作答情况(也称为观察反应模式).
1.3 根据观察反应模式,对被试进行诊断分类
AHM中分类方法有IRT分类法和非IRT分类法.LEIGHTON等[5-6]提出了2种基于项目反应理论和概率论的分类方法:A方法和B方法.方法A和方法B都是通过分析观察反应模式同各类期望反应模式的一致程度来进行分类的,是根据最大相似概率进行判别.
假设第j种期望反应模式对应的被试能力为θj,由项目反应理论可知,第j种期望反应模式在第k题的正确作答概率Pk(θj)和错误作答概率Qk(θj)=1-Pk(θj)可由IRT模型及模拟方法计算得到.
A方法认为,当被试的观察反应模式和任何一类期望反应模式都不一样时,则计算各种期望反应模式转化为观察反应模式的概率,假设第p种期望反应模式的转化概率最大,则将被试归为第p类被试.转化概率的计算公式如下:
其中:Si(0→1)表示对于被试i期望反应为0,但观察反应模式为1的所有题的集合;Si(1→0)表示对于被试i期望反应为1,但观察反应模式为0的所有题的集合.
B方法则认为,拥有某个观察反应模式的被试掌握了所有逻辑包含在其中的期望反应模式的属性组合.对于那些不逻辑包含的期望反应模式,则只需要考虑失误而不考虑猜测,即只计算1→0的可能性,公式如下所示.假设第p种期望反应模式的转化概率最大,且最大转化概率大于等于截断点(cutpoint),则被试有可能归为第p类被试.最后结合逻辑包含部分的诊断结果和不逻辑包含的部分的诊断结果,给出最终的诊断结果.
GIERL等[5]则提出了非IRT方法,该方法是用多层感知器神经网络来估计被试对每个属性的掌握概率.
1.4 报告认知诊断分析结果
将被试进行归类,最终报告认知诊断分析结果.
2 IRT分类方法的改良
以往的研究[5]表明,方法A和方法B的诊断准确率均不高,有待进一步改良.
方法A在判别具有观察反应模式Si的被试是否属于第j类被试(对应期望反应模式Sj,能力为θj)的关系时,计算概率时是以第j类被试为主体,计算的是第j类被试出现观察反应模式Si的概率.使用到的是2类事件的概率:
(1)Pk(θj):对于题目k,第j类被试事实上并没有掌握该题所考察的属性,然而却答对了的概率.
(2)1-Pm(θj):对于题目m,第j类被试事实上掌握该题所考察的属性,然而却答错了的概率.
方法A在判别被试属于哪一类时使用上述概率并不合理,是该方法诊断准确率不高的一个原因.在判别具有观察反应模式Si的被试是否属于第j类被试(对应期望反应模式Sj,能力为θj)的关系时,应该以观察反应模式Si为主体,计算的是具有观察反应模式Si的被试是第j类被试的概率,换句话说,计算的是观察反应模式Si转移到期望反应模式Sj的概率值.
因而使用到的概率应该是另2种:
(1)当受测者答对试题q时,受测者实际上并未掌握试题q所考察的属性的概率P(q:1→0),称为猜测概率,用PG(q)表示.
(2)当受测者答错试题q时,受测者实际上掌握了试题q所考察的属性的概率P(q:0→1),称为失误概率,用PS(q)表示.
由A方法的计算公式,以猜测概率PG(q)和失误概率 PS(q)代替Pk(θj)、Qk(θj),即得到判别方法C:对于某观察反应模式Si,记从Si转移到期望反应模式Sj的概率值为Pij,Pij实际上等于从Si转移到Sj时对不同的答题结果进行0/1反转的概率PG(q)、PS(q)的乘积.计算各观察反应模式Si转移到各个期望反应模式概率值,最大概率值对应的期望反应模式就是Si进行状态转移的目标状态,换句话说,观察反应模式Si是由最大概率值对应的期望反应模式衍生的.
例如,对于观察反应模式S(10001)转移到期望反应模式S1(10000)的概率为PG(q5),而转移到期望反应模式S2(11111)的概率为PS(q2)×PS(q3)×PS(q4).
同样地,可由B方法得到对应的D方法,D方法使用的公式如下:
3 模拟研究
从理论上看,方法C和方法D的计算方法比方法A和方法B更科学,具有更高的诊断性能.为了比较方法A、B、C和D的诊断性能,本研究通过蒙特卡洛模拟试验,以计分准确率、模式判准率、边际判准率为评价指标,对4种判别方法的诊断性能进行考察.
3.1 试验步骤
在诊断前,首先指定测验需测量的属性以及属性层级关系,属性间的层级关系共有4种基本关系(图1),其他复杂的关系可以由这4种基本关系组合生成[5].本模拟试验以图1为例,考察在4种不同的属性层级结构下4种诊断方法的诊断性能.
以七属性发散型结构为例(图1 A),模拟步骤如下:
(1)设定初始值 测验项目数:20;属性个数:7;属性层级关系:发散型(图1 A);被试先验分布:被试成绩按正态分布;被试人数:5 000;IRT模型:二参数Logistic IRT模型;失误水平参数假定为0.1.
(2)根据初始值得到A、R、Qr和D 根据属性层级关系图确定邻接矩阵A,通过布尔代数计算可达矩阵R.由R通过扩张算法得到缩减矩阵Qr.再由Qr得到知识状态矩阵D.
(3)模拟诊断过程 为了尽量减少无关变量随机抽取Qr项目的影响,本部分步骤采取随机化试验设计并重复10次.
①根据初始设定,测验项目数量为20.其中,有7个项目对应R的7个列,剩余的13个项目从Qr中随机抽取确定,从而得到测验Q矩阵Qt.进而由D和Qt得到期望反应矩阵E.
②根据先验分布假设模拟产生5 000个被试的期望反应矩阵.由期望反应矩阵计算各类被试能力参数 θj和各题试题参数 ai、bi(1≤j≤5 000,1≤i≤20).根据所得参数计算 Pi(θj)(1≤j≤5 000,1≤i≤20)、Qi(θj)、PG(i)和 PS(i).
③由期望反应矩阵模拟产生5 000个被试的观察反应模式矩阵.由于本研究的目的在于研究在相同条件下4种诊断方法的诊断性能,因而失误水平参数的大小并不是本研究关注的对象,进行模拟试验时失误参数假定为0.1.
④对观察反应模式矩阵分别使用4种方法进行诊断,并计算计分准确率、模式判准率、边际判准率.
上述步骤重复10次后,求10次模拟各种指标的平均值.
3.2 试验结论
本研究通过R软件编程实现上述模拟试验并统计各种方法的计分准确率、模式判准率、边际判准率,蒙特卡洛模拟试验的结果见表1~表3.
从计分准确率(表1)和模式判准率(表2)2项诊断指标看,对于线型结构,B方法的诊断指标高于A方法,D方法的诊断指标高于C方法,即B方法优于A方法,D方法优于C方法.而对于其他3种结构则反过来,均是A方法优于B方法,C方法优于D方法.不过不管对于哪种结构,新方法均优于对应的原方法.换句话说,C方法的诊断指标高于A方法,D方法的诊断指标高于B方法.
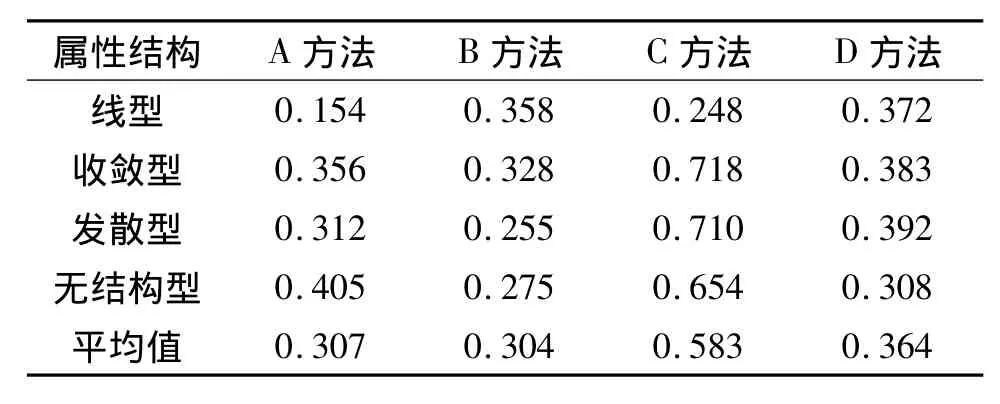
表1 各种诊断方法的计分准确率Table 1 Scorematch ratios for differentmethods
从边际判准率来看,对于线型结构,B方法的平均边际判准率高于A方法,D方法的平均边际判准率高于C方法.从总体来说,D方法的平均边际判准率0.758最高,其次是B方法.不过从各个属性的边际判准率来看,则是C方法对属性A1、A2、A3的边际判准率最高,D 方法对属性 A4、A5、A6、A7的边际判准率最高.对于其他3种结构,情况则不同,均是A方法的平均边际判准率高于B方法,C方法的平均边际判准率高于D方法,且C方法对各个属性的边际判准率最高.

表2 各种诊断方法的模式判准率Table 2 Patternmatch ratios for differentmethods

表3 各种诊断方法的边际判准率Table 3 Marginalmatch ratios for differentmethods
综合考虑3种评价指标,对线型结构进行诊断,最优方法是D方法,平均边际判准率在0.7以上,尤其是属性A6和A7的边际判准率高达0.944和0.988.模式判准率仅有0.372偏低,计分准确率也仅有0.372.最优方法是C方法,平均边际判准率在0.9以上,有一些属性的边际判准率还高达0.99以上,模式判准率和计分准确率也均在0.6以上.
4 讨论
(1)蒙特卡洛模拟试验的结果与理论研究结果相符,经过改良得到的方法C和方法D的诊断性能均优于对应的原方法.且从总体上看,新方法的评价指标比对应原方法的评价指标有较大幅度提高.使用方法C和方法D更能准确的得到被试真实的知识状态和认知结构,为教学提供更为准确的诊断结果.
(2)由于使用D方法对线型结构进行诊断的模式判准率和计分准确率较低.相对来说,使用C方法对发散型、收敛型和无结构型3种属性结构进行诊断的各项指标则较好.因而在设计测验时,不妨设法增加待测属性,使线型结构转化为发散型、收敛型或者由基本关系组合生成的复杂结构,以便提高诊断性能.
(3)评价指标的高低除了跟属性结构、诊断方法有关,还有可能受其他因素影响,例如:测验长度、测验题目的复杂程度、测验属性的个数、试题随机参数、IRT模型、考生成绩分布状态、计分形式等.本研究组业已设计一系列蒙特卡洛模拟试验考察A、B、C、D等4种诊断方法的分类准确率如何受到测验不同的因素的影响,以便探究在哪种情况下使用哪一种的方法可以得到最准确的诊断结果,具体研究方法及结论将另文撰之.这些试验结论可用于指导测验编制.
[1]TATSUOKA K.A probabilistic model for diagnosing misconceptions in the pattern classification approach[J].Journal of Educational Statistics,1985,10:55-73.
[2]文剑冰.规则空间模型在诊断性计算机自适应测验中的应用[D].香港:香港中文大学,2003.
[3]张敏强,简小珠,陈秋梅.规则空间模型在瑞文智力测验中的认知诊断分析[J].心理科学,2011,34(2):266-271.
[4]LEIGHTON JP,GIERL M J.Cognitive diagnostic assessment for education:Theory and applications[M].Cambridge,UK:Cambridge University Press,2007:242-274.
[5]CUIY,LEIGHTON JP,ZHENG Y.Simulation studies for evaluating the performance of the two classification methods in the AHM[R].San Francisco,CA:The annualmeeting of the National Council on Measurement in Education,2006.
[6]祝玉芳.RSM改进及多级评分AHM的开发研究[D].南昌:江西师范大学,2008.
[7]丁树良,汪文义,杨淑群.认知诊断测验蓝图的设计[J].心理科学,2011,34(2):258-265.
