面向中文客户评论的产品属性抽取方法研究
2012-07-25曹付元张永奎
陈 炯,张 虎,曹付元,张永奎
(1.山西职业技术学院 计算机工程系,山西 太原030006;2.山西大学 计算机与信息技术学院,山西 太原030006;3.山西大学 计算智能与中文信息处理教育部重点实验室,山西 太原030006;4.山西大学 商务学院,山西 太原030031)
0 引 言
评论挖掘是当前数据挖掘、文本挖掘、自然语言处理等领域的热点研究课题之一,在电子商务、商业智能、信息监控、舆情分析等方面具有重要的应用。面向网络用户评论的产品属性抽取研究,作为评论挖掘的重要研究方向之一,旨在从客户评论中挖掘出备受关注的产品特征信息,以便总结出基于这些产品特征的观点及其情感倾向,从而为用户提供更为具体和有价值的信息。网络产品评论中的产品属性包括产品名称、产品的组成部分、产品的特点和功能以及产品属性的特点和功能等[1]。
近年来围绕产品评论的属性抽取研究,国内外研究人员进行了大量的探索并取得了一些成效。在英文世界的评论挖掘领域,研究者已经初步取得一些成果[2-4],而针对中文的研究还处于起步阶段。为了推动中文倾向性分析理论和技术的研究和发展,我国于2008年开展第一届中文倾向性分析评测大会 (COAE2008)。张姝等提出将属性词和评价词的识别融合到一个模型中,定义了多种特征并采用条件随机场 (CRF)模型实现了属性词和评价词的一体化识别,在COAE2008的评价对象抽取的评测结果中,取得了较好的成绩[5]。但是单纯采用统计学的方法具有很大的不确定性,难以取得理想的效果[6]。有的学者基于评价对象是名词或名词短语的假设,采用手工或自动的方法统计语料中属性词的词性序列特征,构建词性模板并抽取评价对象的属性,取得了不错的效果[7-9]。但是属性词的词性序列反映的语言信息非常有限,很难取得较高的精度。娄德成等则通过对观点句实施依存关系分析,发现主谓依存对可以提供主语和谓语的修饰关系等信息,借助主谓结构识别产品的属性,并取得了一定的效果[6]。然而依存对仅仅反映了评价语句的局部语言规律,也难取得理想效果。而李实等参考英文世界中基于关联规则分类的产品特征挖掘算法,通过对产品特征挖掘方法进行技术拓展,把目前主要面向英文的评论挖掘方法拓展到中文世界,在5种产品的评论语料上进行实验,平均精确率达到了63.6%,平均召回率达到了77.8%[10]。但方法的基础仍然是面向英文评论,用于中文领域存在一定的局限性。
由于汉语是一种大字符集的孤立语,形态变化少,语法关系靠词序和虚词表示,而且句子由词组成,词在组成句子时,需要遵守一定的规则和约束[11]。依存语法的描述侧重反映语义关系,这种表示更倾向于人的语言直觉,有利于一些上层应用[12]。通过对语料的观察和分析,句子中的词性和依存关系序列在多数情况下能够反映评论语句的语言组合规律,因此本文综合利用词法分析、句法分析、同义词词林等多项技术和资源,挖掘真实语料中蕴藏的语言知识,从词法和句法两个角度综合分析和归纳评论句的全局语言规则,在此基础上构建产品属性模板,指导产品属性的抽取。
1 属性模板库生成
1.1 语料预处理
仅从包含观点词的句子中提取产品属性是基于这样的假设,即语料中包含观点词的句子包含评价观点,并且经常出现在评价句中的属性才是我们需要抽取的属性[13]。本文选取评论网站上的主观句作为训练语料,并对搜集到的语料进行预处理,然后进行词法、句法分析构建标注语料集。
语料预处理阶段,需要对收集到的评论句进行去噪处理,人工滤除语法错误和成分残缺的句子,修正标点符号错误和错别字词,得到符合语法规则、表达规范的句子。
使用哈尔滨工业大学研制的语言技术平台LTP对预处理后的句子进行处理。LTP包括语料资源、语言处理模块、数据表示和可视化工具等4个模块。本文使用语言处理模块对预处理后的句子进行分词、词性标注和依存句法分析,获得输入句子的分词、词性标注结果和依存句法树。
例1:价格比较之后感觉还是很厚道的。
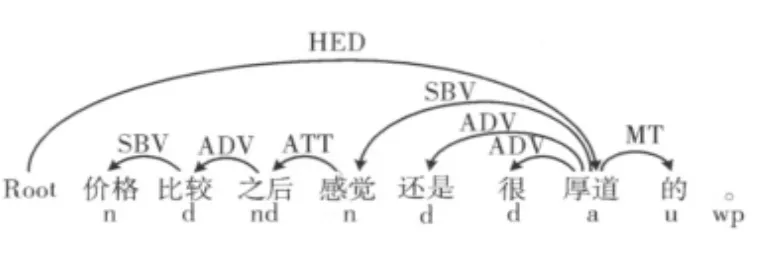
图1 例1的分析结果
例1的分析结果如图1所示。从分析所得的依存句法树中提取属性词 “价格”节点到观点词 “厚道”节点的路径中词性和依存关系序列为: “n-SBV-d-ADV-nd-ATT-n-SBV-a”,其中小写字母表示词性标记,大写字母表示依存关系。最后按照如下格式生成句子的标注结果。
<tag>
<sentence> 句子内容 </sentence>
<seg> 句子分词和词性标注后结果 </seg>
<dps> 依存句法树中属性词节点到观点词节点的最短路径序列 </dps>
<o> 观点词在分词结果中的序号 </o>
<f> 属性词在分词结果中的序号 </f>
</tag>
其中,<sentence> </sentence>标签的内容是经过预处理后的主观性句子;<dps> </dps>标签的内容用词性标记和依存关系标记表示;<o> </o>、<f> </f>中序号从0开始,小于0的序号表示没有该项内容。
例1经过上述标注后的结果为:
<tag>
<sentence>价格比较之后感觉还是很厚道的</sentence>
<seg> [0]价格/n[1]比较/d[2]之后/nd[3]感觉/n[4]还是/d[5]很/d[6]厚道/a[7]的/u[8]。/wp</seg>
<dps> n-SBV-d-ADV-nd-ATT-n-SBV-a</dps>
<o>6</o>
<f>0</f>
</tag>
1.2 模板定义
为了提高模板的适用性和有效性,模板应遵循以下几条原则:①模板应能方便准确地识别评论句中的产品属性词。②模板应该便于高效率地检索。③模板应该具有较好的覆盖面和适应性。
在产品评论中,不同的用户往往使用不同的评价词对同一属性进行评价,以表达自己的观点,然而语料的覆盖面非常有限,标注获得的观点词很难覆盖真实评论中不同的用词,为了扩大模板的覆盖面,使得模板尽可能多地概括同类语言模式,需要对观点词进行同义词扩充。哈尔滨工业大学研制的同义词词林 (扩展版)把词语分为大、中、小类三级,共分为12个大类,94个中类,1428个小类,小类下再以同义原则划分词群,每一个词群以一标题词立目,共3925个标题词。采用同义词词林扩充观点词的方法如下:对于语料中标注的每个观点词,在同义词词林中查找该词所在词群中的同义词,并将获得的同义词连同该词一起组成同义词列表,作为对应模板中ops列表节点的内容。模板的结构组成如下:
<template>
<id> 模板编号 </id>
<ops> 观点词及其同义词列表 </ops>
<dps> 依存句法树中属性词节点到观点词节点的最短路径序列 </dps>
<f> 属性词在dps序列中的词性序号 </f>
</template>
其中,<template> </template>标签标记了一个模板,模板中的第一个节点是模板编号,编号从0开始;<dps> </dps>节点用词性标记和依存关系标记表示;<f> </f>节点序号从0开始。
由例1所生成的一个候选属性模板为:
<template>
<id>0001</id>
<ops>厚道忠厚敦厚温厚仁厚宽厚憨厚笃厚淳厚浑厚人道浑朴淳朴纯朴诚朴朴实忠厚老实不念旧恶以德报怨 息事宁人 隐恶扬善 古道热肠 憨直 厚朴 朴 以直报怨 憨 拙朴 醇朴 淳 恽 </ops>
<dps> n-SBV-d-ADV-nd-ATT-n-SBV-a</dps>
<f>0</f>
</template>
1.3 模板归并与过滤
在生成的候选模板中,若两个模板的dps序列和f序号都相同,说明这两个模板反映了相似的语言现象,需要考虑这两个模板是否应当归并的问题。设模板template_1和template_2的dps序列和f序号都相同,它们的观点词列表分别为L1= {w11w12… w1p}和L2= {w21w22… w2k},若L1∩L2≠ ,则将这两个模板归并为一个模板,归并后的模板的ops列表为L=L1∪L2。经过模板的归并,可以减少模板库的冗余模板,提高模板检索的效率。经过归并后的候选模板中,有些候选模板在训练语料中出现的次数相对较多,这些候选模板相对比较可信,而那些出现次数较少的候选模板可信度相对较差,因此需要对候选模板进行过滤。过滤阈值设置为式 (1)

式中:α——比例系数,0≤α≤1;pf——所有候选模板在训练语料中出现的总频次;pn——候选模板的总数。当α一定时,θ的大小反映了候选模板在语料中出现的平均频次。
1.4 模板库生成
由于中文自然语言文本中表达方式、遣词造句的多样性以及句式的复杂性[14],同一个观点词可能用于不同的句式,相同的句式也可能使用不同的观点词来表达某种情感倾向。为了能够有效组织模板,将生成的模板组织成阵列形式,每行模板的dps序列相同,而每列模板的ops列表相同。模板库的逻辑组织结构如图2所示。

图2 模板库的逻辑组织结构
其中,c0,c1,…,cn模板库中模板的列序号,r0,r1,…,rm为行序号。
2 产品属性抽取
由于网络评论中包含有大量的噪声,一定程度上会降低处理的效率和识别的准确率,因此需要对待识别的主观性评论句进行去噪处理。通过对语料中出现的特殊符号的观察和统计,构建停用符号表。对于给定的主观性评论句,先采用停用符号表过滤句子中的特殊符号,然后对句子进行分词、词性标注和依存句法分析,最后提取句子中的形容词w和句子的词性依存序列s。在提取句子中的形容词过程中,可能存在一个句子中有两个或多个形容词的情况,这个句子可能存在两个或多个属性,此时需要将这些形容词分别作为检索词进行模板检索。
2.1 模板检索
以提取的形容词w为检索词,在模板库中检索ops列表包含该检索词的模板并获取该模板在模板库中的列序号c,然后按如下算法检索匹配的模板:
步骤1 j=0,position=-1。
步骤2 dps=template_jc.dps。
步骤3 若dps是s的一个子序列,则匹配成功,用position记录s中与dps相同的子序列的起始位置,并记录模板的行序号j,转步骤4;否则,j=j+1,若j≤m,转步骤2。
步骤4 结束。
算法执行后,若position=-1,表明未检索到匹配模板;否则说明评论句在模板库中找到匹配的模板template_jc。
2.2 属性抽取
利用模板检索后获得的模板编号jc和序列匹配的起始位置position,可定位待识别句子中的属性词。设匹配模板template_jc的<f> </f>节点值为d,则待识别评论句的分词结果中序号为position+d的词即为属性词。
例2:清晰的屏幕,漂亮的外观设计,凸显了它品质的高贵。
例2词性标记后结果为:[0]清晰/a[1]的/u[2]屏幕/n[3],/wp[4]漂亮/a[5]的/u[6]外观/n[7]设计/v[8],/wp[9]凸显/v[10]了/u[11]它/r[12]品质/n[13]的/u[14]高贵/a[15]。/wp。分析后结果如图3所示。

图3 例2的分析结果
句子中出现了3个形容词 “清晰”、 “漂亮”和 “高贵”,分别以3个形容词为检索词在模板库中检索模板,执行检索算法后,形容词 “清晰”获得的检索结果为:position=0,匹配模板是template_41;同理,形容词 “漂亮”和 “高贵”获得的匹配模板分别是template_71和template_60。根据3个模板获得对应的属性词。例如,形容词 “清晰”的匹配模板template_41为:
<template>
<id>41</id>
<ops> 清晰 明晰 清 清楚 历历 分明 鲜明 一清二楚黑白分明 旁观者清 清清楚楚 明明白白 冥 澄 丁是丁 白纸黑字 清丽 不可磨灭</ops>
<dps>a-DE-u-ATT-n</dps>
<f>2</f>
</template>
则待识别评论句的分词结果中序号为position+2=2的词 “屏幕”即为该句的一个属性词。同样的方法可识别另两个属性词分别为 “外观”和 “品质”。
3 实验设置及结果分析
3.1 实验语料构建
由于缺乏标准的评测语料可供使用,本文选取了与文献 [10]来源相同的5种产品评论作为实验语料,以便于展开对比。从5种产品的网络评论中各选取150个主观性评论句作为实验语料,5种产品分别是一款手机 (HTC A9191),两款数码相机 (Nikon D90,Canon IXUS 210),一款MP3播放器 (蓝魔RM970)和一本图书 (《杜拉拉升职记》)。其中手机、数码相机及MP3播放器的评论从itl68网站下载 (http://www.it168.com/),图书评论从卓越网下载 (http://www.amazon.cn/)。实验选取的每一个评论句至少包含一个产品属性。从750句实验语料中随机选取每种产品的100个评论句,共500句评论组成训练集,其余250句组成测试集。
针对训练集中每一种产品的评论句,首先进行预处理,然后对训练集中的语料进行半自动标注,根据标注结果生成了563个候选模板,经过模板归并和过滤后得到374个属性模板,最后由374个模板生成模板库。
3.2 评价指标
采用在文本处理研究领域普遍使用的性能评估指标:精确率P(precision)、召回率R(recall)和F值对实验结果进行评测

3.3 实验结果及分析
首先将测试集中5种产品的250个评论句子输入实验系统,对于每一种产品,不同句子中识别出的相同属性应当看作是不同的属性;然后将实验结果与文献 [10]进行了对比。虽然两种方法选取的实验语料不同,但是所用的语料来源、评论的产品种类和语料规模完全相同,对比结果如表1所示。
D从表1的结果可以看出,本文的平均精确率达到了0.762,平均召回率达到了0.703,与文献 [10]的抽取方法相比,召回率下降了7.5%,但精确率却提高了12.6%,综合评价指标F值提高了3.4%,说明本文方法取得了较好的效果。
分析精确率提高的原因,文献 [10]继承并拓展了面向英文评论的产品特征挖掘方法,虽然也针对中文语言特点和中文评论风格对方法局部进行了技术创新,但由于中英文语言在词汇、语法、语义以及语用等各个层面都上存在着很大的差异,方法的拓展效果比较有限。而本文方法则借助从真实的中文评论语料中提取出的属性模板识别产品属性,模板既包含了反映评论句语言组合规律的词性和依存关系序列,也包含了特定的语言组合序列可能关联的观点词,因而能够更好地刻画中文产品评论的语言规律,提高识别准确率。

表1 本文方法与文献 [10]实验对比结果
本文的召回率有所降低,主要是因为训练语料的规模比较小,只有500个句子,模板库包含的模板数量依赖于训练语料的规模,模板的覆盖面仍然比较小,有些测试语料是模板没有覆盖到的,可以通过建立更为完备的训练语料来增加模板的数量,从而提高系统的性能。
为了进一步提高方法识别的准确率,通过对识别错误的句子进行分析。引起错误的原因主要有以下几个因素:
(1)分词、词性标注及句法分析工具是后续产品属性识别的基础,但是目前这些工具本身还有一定的误差。例如,“性价比”也是一种产品属性,但在分词时切分为 “性价/比”,影响了后续属性识别的准确率。
(2)人工标注的主观性和隐式产品属性对识别的准确性有一定的影响。实验结果对照的是人工标注的属性,然而对于产品属性人工标注的主观性可能会影响到标注结果的客观性,从而影响实验结果的准确性。另外,本文对属性的识别仅是针对产品的显式属性进行识别,而对于隐式属性却无能为力。
(3)网络用户评论的风格及语言的特殊性对实验结果也产生了影响。由于评论文本风格的特殊性,再加上网络用语中新词、新含义、新用法和新句型的不断出现,降低了识别方法各环节处理的准确率。例如,“超酷”词性被标记为 “ws”,但它的真实含义却是一个褒义的观点词;“外观很山寨”中 “山寨”一词被标记为名词,但它的真实含义却转化为一个贬义观点词。
(4)为了提高模板的覆盖面,采用同义词词林对观点词进行了同义词扩展,这种扩展是基于这样一种假设,即同义词或近义词的语法功能也相同,虽然这种假设对于多数情况是正确的,但有时也有例外。
4 结束语
针对句子粒度的中文在线产品评论,在分析现有产品属性抽取方法的基础上,综合采用了词法分析、句法分析、同义词词林等多项技术和资源,提出了一种基于产品属性模板的方法。考虑到在线产品评论的特点,本文首先对训练评论语料进行了预处理,并使用哈尔滨工业大学研制的语言技术平台LTP对预处理后的句子进行分词、词性标注和依存句法分析,生成语料标注集。然后采用半监督学习的方法构建了产品属性模板,最后借助模板实现了对产品属性的自动识别。实验结果表明该方法是有效的。
[1]TANG Hui-feng,TAN Song-bo,CHENG Xue-qi.A survey on sentiment detection of reviews [J].Expert Systems with Applications,2009,36 (7):10760-10773.
[2]Popescu A,Etzioni O.Extracting product features and opinions from reviews [C].Proceedings of the Conference on Human Language Technology and Empirical Methods in Natural Language Processing.Stroudsburg,PA:ACL,2005.
[3]WEI C P,CHEN Y M,YANG C S,et al.Understanding what concerns consumers:A semantic approach to product feature extraction from consumer reviews [J].Information Systems and E-business Management,2010,8 (2):149-167.
[4]Niklas J,Iryna G.Extracting opinion targets in a single-and cross-domain setting with conditional random fields [C].Proceedings of the Conference on Empirical Methods in Natural Language Processing.Stroudsburg,PA:ACL,2010:1035-1045.
[5]ZHANG Shu,JIA Wen-jie,XIA Ying-ju,et al.Research on CRF-based evaluated object extraction [C].Harbin:Proceedings of the COAE,2008(in Chinese).[张姝,贾文杰,夏迎炬,等.基于CRF的评价对象抽取技术研究 [C].Harbin:Proceedings of the COAE,2008.]
[6]LOU De-cheng,YAO Tian-fang.Semantic polarity analysis and opinion mining on Chinese review sentences [J].Journal of Computer Applications,2006,26 (11):2622-2625 (in Chinese).[娄德成,姚天昉.汉语句子语义极性分析和观点抽取方法的研究 [J].计算机应用,2006,26 (11):2622-2625.]
[7]QIAO Chun-geng,SUN Li-hua,WU Shao,et al.Patternbased Chinese semantic orientation analysis[C].Harbin:Proceedings of the COAE,2008(in Chinese).[乔春庚,孙丽华,吴韶,等.基于模式的中文倾向性分析研究 [C].Harbin:Proceedings of the COAE,2008.]
[8]HE Ting-ting,WEN Bin,SONG Le,et al.Research on sentiment terms’polarities identification and opinion extraction[C].Harbin:Proceedings of the COAE,2008 (in Chinese).[何婷婷,闻彬,宋乐,等.词语情感倾向性识别及观点抽取研究 [C].Harbin:Proceedings of the COAE2008,2008.]
[9]SONG Xiao-lei,WANG Su-ge,LI Hong-xia.Research on comment target recognition for specific domain products[J].Journal of Chinese Information Processing,2010,24 (1):89-93 (in Chinese).[宋晓雷,王素格,李红霞.面向特定领域的产品评价对象自动识别研究 [J].中文信息学报,2010,24 (1):89-93.]
[10]LI Shi,YE Qiang,LI Yi-jun,et al.Mining features of products from Chinese customer online reviews [J].Journal of Management Sciences in China,2009,12 (2):142-152 (in Chinese).[李实,叶强,李一军,等.中文网络客户评论的产品特征挖掘方法研究 [J].管理科学学报,2009,12 (2):142-152.]
[11]ZONG Cheng-qing.Statistical natural language processing[M].Beijing:Tsinghua University Press,2008:147-189(in Chinese).[宗成庆.统计自然语言处理 [M].北京:清华大学出版社,2008:147-189.]
[12]LIU Ting,MA Jin-shan.Theories and methods of Chinese automatic syntactic parsing:A critical survey [J].Contemporary Linguistics,2009,11 (2):100-112 (in Chinese).[刘挺,马金山.汉语自动句法分析的理论与方法 [J].当代语言学,2009,11 (2):100-112.]
[13]SONG Rui,LIN Hong-fei.DUTIR at COAE2008 [C].Harbin:Proceedings of the COAE,2008 (in Chinese). [宋锐,林鸿飞.DUTIR关于 COAE2008评测报告 [C].Harbin:Proceedings of the COAE,2008.]
[14]ZHOU Li-zhu,HE Yu-kai,WANG Jian-yong.Survey on research of sentiment analysis [J].Journal of Computer Applications,2008,28 (11):2725-2728 (in Chinese).[周立柱,贺宇凯,王建勇.情感分析研究综述 [J].计算机应用,2008,28 (11):2725-2728.]
[15]ZHENG Jia-heng,ZHANG Hu,TAN Hong-ye,et al.Intelligent information processing-Chinese corpus processing technology and application [M].Beijing:Science Press,2010:112-137(in Chinese).[郑家恒,张虎,谭红叶,等.智能信息处理—汉语语料库加工技术及应用 [M].北京:科学出版社,2010:112-137.]
