Web挖掘在网络广告点击欺诈检测中的应用
2012-07-25李爱春滕少华
李爱春,滕少华
(广东工业大学 计算机学院,广东 广州510006)
0 引 言
互联网经济的蓬勃发展也使网络广告市场一直保持着高度增长的态势,网络广告已经成为一种新的市场推广手段。点击欺诈 (click fraud)[1]存在于网络广告的按点击付费模式中,它的产生和泛滥极大地危害了互联网广告业的健康发展,所以对检测网络广告中的点击欺诈行为的研究意义重大。
在国内外,Web挖掘应用在点击欺诈的开放性研究较少,国内文献中从技术上检测广告欺诈行为的介绍极少,文献 [2]给出一种基于图形验证码的预防点击欺诈策略,该策略能屏蔽类似于木马点击器多次重复点击的欺诈行为,但是人工输入验证码势必会影响广告效果,而且这种方法不能杜绝人为的点击欺诈。其它的一些研究涉及广告定制、个性化广告等Web内容挖掘。对于Web使用上的挖掘主要还局限于学习和探索阶段,而企业内部的研究一般处于保密状态。文献 [3]对 Web用户行为的点击流挖掘进行了系统的介绍,同时提出了具体的应用模型。文献 [4]提出进行计费模式创新和引入第三方来检测点击欺诈,但按点击付费广告是目前互联网界最简单易行且最为流行的广告计费方式,让网络广告经营者短时间内放弃按点击付费模式,并向第三方开放点击流数据显然是不现实的。
Mehmed Kantardzic[5]等人开发一个 CCFDP 系统来实时检测点击欺诈。但点击欺诈的检测需要考虑时效性,如果放在实时的点击流中去检测,势必会影响广告的展示速度和效果。本文提出一种新的解决办法,处理步骤分两步,第一步在广告展示并点击之后,根据用户评估参考分和本次点击的数据做出相应的操作,然后再初步评估该点击,并给予初步评估分 (0-1之间,越靠近1表示越有可能是点击欺诈),然后回馈到用户初步评估参考分;第二步在服务器空闲时对初步评估分和用户评估参考分进行校对,本次评估会把历史点击流放进来进行二次分析和预测。试验结果表明,基于这些Web挖掘算法的点击欺诈检测模型是有效可行的。
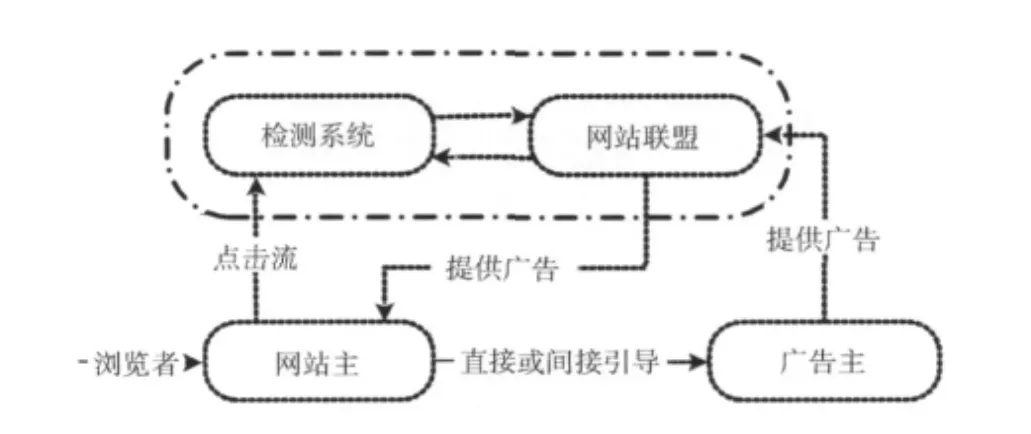
图1 网络广告三角色关系及流程
1 相关工作
1.1 相关知识介绍
市场营销人员通过在线广告宣传自己的产品时,也要为这些网络广告支付相应的广告费用。这些广告分为按点击付费(cost per click,CPC)、按展示付费 (cost per ThousandImpression,CPM)、按销售付费 (cost per sales,CPS)等,其中按点击付费广告是目前互联网界最简单易行且最为流行的广告计费方式[2]。它以每次网页上的广告被点击并连接到相关网站或者详细内容页面为基准的网络广告收费模式[1]。点击欺诈主要存在于按点击付费 (CPC)模式中。
点击欺诈是指以某种金钱或者商业目的为出发点,对网络广告进行恶意点击并达到消耗广告费用和抬高成本的目的的行为。简单来说,当网络出版商点击其网站上的广告提高他们的收入,或企业点击竞争对手的广告来蚕食对方的广告预算时,就构成了点击欺诈。网络广告收入是当今世界各国基于互联网企业的主要收入来源,点击欺诈损害了虚拟世界的诚信基石及互联网发展的经济基石。
网络广告投放模式有关键字广告、主题广告等,两者没太大区别,关键字广告显示在搜索引擎上,它根据用户搜索内容显示相应的广告,由于是直接投放在自己的搜索引擎上,更易分析点击前的行为,这给判断点击欺诈带来很大的便利;主题广告显示在普通的Web页面上,这对检测点击欺诈增加了难度。本文研究的模型侧重于后者。
Web挖掘[6]是从 Web页面和 Web用户访问活动中发现、抽取有用的模式和隐藏的信息,是将传统的数据挖掘技术与Web结合起来的一门新兴学科。Web挖掘按照处理对象不同一般可分为三大类[7]:Web内容挖掘 (web content mining)、Web结构挖掘 (web construct mining)和Web使用挖掘 (web usage mining)。本文对点击流主要进行Web使用挖掘。
1.2 网络广告流程
主题广告中的网站广告联盟、网站主、广告主是分开的。图1给出了三者及检测点击欺诈模块的关系及流程图。
1.3 点击欺诈动机
点击欺诈动机具有多样性:
(1)网站主通过各种方式点击自己网站上的广告来获得广告佣金。
(2)广告主的竞争者通过消耗完对手的广告预算来提升自己的广告排名。
(3)广告联盟为了获得每次点击的广告佣金。
其中 (1),(2)最为常见,方式也具有多样性,他们通过人为或者特制的软件程序恶意点击,更有甚者组织一群人互点彼此的广告。
2 检测体系
2.1 体系概述
将Web数据挖掘技术应用到检测体系中,图2给出了该体系的检测过程。

图2 检测体系流程
2.2 模块介绍
从图2可以看出,本文提出的检测体系分为5个模块:数据采集,初步评估,评估修正,数据仓库和信息反馈:
(1)数据采集:我们的数据集是通过嵌入在网络广告中的JavaScript脚本来收集的,然后存到关系数据库中。总属性共41个,其中比较重要的属性如表1所示。

表1 点击流数据集的关键属性
(2)初步评估:网页浏览者点击广告后必须很快做出响应,所以在服务器端的请求时间不能过长,这就要求广告的响应不能在点击流初步评估之后再执行。本文采用一种独特的方式来解决这一问题:我们做出响应是根据之前的用户评估参考分来判断的。用户评估参考分受之前的每次点击流初步评估和评估校对影响。这样就解决了广告响应速度的限制,使得广告响应和本次点击流初步评估同步进行。对于数据预处理,当前的研究已有不少的解决办法[8-9]。
(3)评估修正:修正过程可按天、周、月或者在给网站主结算前进行,由于有一定量的点击数据,Web挖掘才更有意义,该挖掘过程包括两种数据集:已修正数据集(历史数据集)、未修正数据集。
(4)数据仓库:主要存放着历史数据集。在对点击流进行评估修正后根据相关策略存放到该数据仓库中,以备后期的数据挖掘操作。
(5)信息反馈:当作完评估修正后,修正结果会及时的反馈到广告联盟、广告主、网站主那里。比如对于网站主存在严重点击欺诈行为的,修正结果将会封锁网站主账号,并告知广告联盟,同时根据数据向广告主返回相应的广告费用。
3 检 测
3.1 点击流初步评估
一个点击流的初步评估影响因子很多。每个影响因子都有自己的权值wi(0≤wi≤1)和属性分值ri(0≤ri≤1),最终加权成一个总的评估分S
关键评估因子介绍如下:
无效值分析:根据常识Click_X(属性意义见表1,下同)<1、Click_Y<1、Click_X>2000、Click_Y>2000、Viewtime<1等为无效点击 (有点击欺诈的可能性)。
点击率:点击率是点击次数与总浏览次数的比值。一般来说,如果不是恶意点击,无意点击造成的点击率不会太高。
点击坐标分析:点击坐标的分布一般都有一个热图区域,这跟视觉学有关系,如果一个站内有很多点击偏离这个点击热图就有可能存在点击欺诈。
显示分辨率分析:其中包括它的宽度Screen_w、高度Screen_h和色度Screen_s范围,比如一个站经常出现16位色度的属性就有必要怀疑了。
点击覆盖率/独立IP分布[1]:单个IP的点击覆盖率(点击/浏览)分布超过了3倍的系统误差范围内则有作弊嫌疑。
属性组相似性分析:如果一段时间内,referer,siteurl,ip段,Click_X,Click_y等属性值高度相似,则有点击欺诈的可能。
点击覆盖率/IP/时间分析[1]:根据时间序列对点击率进行分析,如果在某一段时间上有明显的峰值,那么这将意味着有潜在的点击欺诈的可能。
时间差分析/页面打开时间[1]:网页下载的时间和广告点击时间应该是一个平缓的分布情况即泊松分布 (Possion distribution),而每次点击之间的时间差应该是一个泊松分布。
IP和timezone对应关系:大量IP和时区不一致的点击就有使用代理等方式点击的嫌疑。
针对http agent的分析[1]:通过 Http agent的时间序列进行分析,当峰值超过3方差时就有很大的嫌疑。
针对http referral的分析:通过http referral的时间序列进行分析。
3.2 点击流评估分修正
评估分修正主要是对点击流再次检测,并根据检测结果修正初步评估分。
3.2.1 基于密度的局部离群点检测
此过程主要是离群点检测,这些离群点存在很大可能的欺诈性,要具体分析。根据我们对点击流数据集综合分析,各点击流属性值有局部聚合的现象,所以我们采用“基于密度的局部离群点检测[10]”方法来进行离群点挖掘。
离群点检测是为了消除噪声或发现潜在的、有意义的知识[11]。局部离群点[12]的检测需要解决局部邻域的确定和对象与邻域的比较计算这两个子问题。图3所示为简单的数据集和,该集和有两个明显的簇,即C1.C2,另外两个对象o1,o2明显是离群噪声点。然而如果通过一般的基于距离的离群点检测,仅能发现o1是合理的离群噪声点。如果将o2判为离群点,那么C1中所有点都会同样被认为是离群点[13]。

图3 包含两个离群噪声点的数据集合[10]
这样就引出了局部离群点的概念。如果一个对象相对于它的局部邻域,特别是相对于邻域密度,它是远离的,那么该对象是局部离群点。显然,局部离群点是指在数据集中与其邻域表现不一致或大大地偏离其邻域的数据点。
点击流数据集中的任一对象p的k距离 (k-distance)是p到它的最近邻的最大距离,记作k-distance(p)。对象p的k距离邻域 (k-distance neighborhood)记作 Nk-distance(p)(p)。它包含所有距离不大于p的k距离的对象[11]。
对象p关于对象o(其中o在p的k最近邻中)的可达距离[11]定义为

p的局部可达密度 (lrdk(p))是基于p的k最近邻点的平均可达密度的倒数[11]。其数学表达式为

p的局部离群点因子 (LOF)表征了我们称p为离群点的程度[11]。其数学表达式为

3.2.2 多元线性回归分析
此过程主要是通过历史数据集对未修正的数据集进行预测分析,并通过对比初步评估分进行修正用户的评估参考分。对Web用户行为的预测可以使用马尔可夫模型结合有向图来提高其预测准确度[14]。也可以运用基于差别矩阵的粗糙集提取Web日志中的关联规则,并将生成的关联规则集用于用户行为的预测[15]。由于评估分的影响因子不止一个,通过分析和必要的实验,我们最终选择多元线性回归分析[16]进行预测。
当影响因变量Y的自变量X不止1个时,Y和X间的线性回归方程为
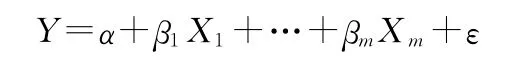
式中:α,β1…βm——回归系数;ε——随机误差。通常假定ε遵从正态分布:ε~N(0,σ2)。
设 {(Yi,Yi1,…,Xim),i=1,…,m}为观测值,回归分析的首要任务是利用他们来估计α,β1…βm和σ,它们的最小二乘估计记作α,b1,…,bm和σ,求估计值b1,…,bm需要解下面的线性方程组

求得b1,…,bm后,计算:a=珚Y-b1珚X1-…-bmXm,由计算得出的α,b1,…,bm和σ就可以建立回归方程了[11]。
4 实验及结果分析
4.1 数据集选取
为了更好地检测点击欺诈,该脚本在收集点击流数据时不进行任何处理,直接传送到服务器。服务器端根据原始数据进行初步评估。
截至到2010年7月25收集点击流数据共计242 298条,这些数据全部作为训练数据。为了更突出实验的可靠性,我们测试数据集是通过自己模拟点击欺诈者通过人为和计算机程序两种方式来验证。
4.2 实验结果
在人为方式上,我们模拟点击欺诈者分时段,换IP地址,随机访问网站内容并点击广告。在计算机自动程序上我们使用网上比较流行的广告点击软件来测试。
4.2.1 点击流初步评估
在人为方式上,我们模拟点击频率f(分钟)为:10、20、40、80、160。检测时间t(分钟)为:120、240、480、960。我们实验的规则是:在每个f随机时间内浏览网页并随机点击广告;在t时间时记录各个模拟点击频率的评估分s。
我们首先模拟的是个人点击欺诈行为,此过程IP、上网地点等环境变动不大。实验结果如表2所示。

表2 模拟个人点击欺诈行为评估结果
从表2可以看出点击欺诈者点击的越频繁,评估分s增的就越快,点击频率f为160是看似效果不太理想,其实是因为f较大,在t的时间内收集到的点击流数据较少,如果实验结果按照收集点击次数来统计就能看到它的检测效果是不差的。
接下来我们模拟的是IP、上网地点等环境都是变化的,这样的检测更具有代表性,比如通过代理、组群互点等方式来进行点击欺诈。实验结果如表3所示。

表3 模拟更具代表性的点击欺诈评估结果
从表3可以看出,检测结果还是非常乐观的,在检测8个小时后5组里就有3组评估分超过了0.5,后面的由于收集的点击流数据少评估分还不够明显。
在计算机自动程式上,我们通过比较市场上存在的作弊程序,选了个比较流行的点击欺诈软件来进行实验。由于此类作弊软件易于操作,一般设置好参数就行了。我们对实验参数调整如下:每随机浏览网页1000次点击广告的最大次数n为:5、20、50、100、200。检测时间T (小时)为:8、16、24、48。
我们的检测结果如表4所示。

表4 计算机自动程式点击欺诈评估结果
从表4可以看出点击率越高,效果越明显,主要是因为收集到的点击次数较多,点击数据更有规律。4.2.2 点击流评估校对
在人为方式上,对模拟个人点击欺诈行为的评估校对实验结果如表5所示。

表5 模拟个人点击欺诈校对结果
对第二种人为模拟方式的评估校对实验结果如表6所示。

表6 模拟更具代表性的点击欺诈校对结果
对计算机自动程式模拟方式的评估校对实验结果如表7所示。

表7 计算机自动程式点击欺诈校对结果
从表5~表7可以看出,检测结果更好地参考了历史数据集,经过对初步评估的校对,使评估分更接近于真实。当然本实验也有不如意的地方,比如没有正常点击数据流的参与、实验周期短等因素不能使结果更具有说服力。
5 结束语
本文介绍了点击欺诈和Web挖掘相关的知识,分析了国内外解决的办法和局限,在此基础上提出了一种基于Web挖掘的检测点击欺诈的方法,能在不影响广告时效性的基础上,提升检测点击欺诈行为的效果,同时通过Web挖掘相关算法的运用使检测结果更为准确。
本文介绍的方法不足之处是通过脚本来收集点击流信息,对于那些不支持该脚本的浏览器,或者用户故意禁用该脚本则导致广告无法显示,点击流无法收集等问题。同时在用户识别上仅仅是通过点击流属性,没有对cookie、session和服务器端的数据流进行统一验证,这也是我下一步要做的事情。同时下一步的工作还有:设计一种方案去收集浏览者点击进入广告主网站那边后的浏览行为,这种浏览行为更能反映出浏览者是否是自愿点击过来的,这对判断点击欺诈是很有用的。
[1]SHU Zhengyong.The study on click fraud of commercial search engine [D].Dalian:Thesis For Master Degree of Liaoning Normal University,2008 (in Chinese).[舒正勇.商业搜索引擎的点击欺诈问题研究 [D].大连:辽宁师范大学硕士学位论文,2008.]
[2]YUAN Jian,ZHANG Jinsong.Effective strategy to prevent clickfraud [J].Journal of Computer Application,2009,29 (7):1790-1792 (in Chinese).[袁健,张劲松.一种有效预防点击欺诈的策略 [J].计算机应用,2009,29 (7):1790-1792.]
[3]SU Jiangyu.Web user behavior mining base on click-stream[D].Guangzhou:Thesis For Master Degree of Guangdong University of Technology,2010 (in Chinese).[苏疆煜.基于点击流Web用户行为挖掘 [D].广州:广东工业大学硕士学位论文,2010.]
[4]GAO Zhijian.Radical measure of click fraud use a third party[J].Productivity Research,2007,22 (18):72-73 (in Chinese).[高志坚.引入第三方监测根治点击欺诈 [J].生产力研究,2007,22 (18):72-73.]
[5]Mehmed Kantardzic,Chamila Walgampaya,Brent Wenerstrom,et al.Mproving click fraud detection by real time data fusion [C].Proc of IEEE International Symposium on Signal Processing and Information Technology,2008.
[6]ZHANG Rong.Research on technology of web mining [J].Computer Engineering,2006,32 (15):4-6 (in Chinese).[张蓉.Web挖掘技术研究 [J].计算机工程,2006,32 (15):4-6.]
[7]SUN Tao.Targeting of user behavior of online advertising system [D].Shanghai:Thesis For Master Degree of Fudan University,2008(in Chinese).[孙涛.网络广告系统的用户行为定向研究 [D].上海:复旦大学硕士学位论文,2008.]
[8]FAN Yuankang,HU Xueguang,XIA Qishou,et al.Advanced data preprocessing technology for web log [J].Computer Engineering,2009,35 (10):73-74 (in Chinese). [方元康,胡学钢,夏启寿,等.改进的Web日志数据预处理技术 [J].计算机工程,2009,35 (10):73-74.]
[9]ZHANG Bo,WU Lili,ZHOU Min.The analysis of user behavior based on web usage mining [J].Computer Science,2006,33 (8):213-214 (in Chinese).[张波,巫莉莉,周敏.基于Web使用挖掘的用户行为分析 [J].计算机科学,2006,33 (8):213-214.]
[10]XU Xiang,LIU Jianwei,LUO Xionglin.Research on outlier mining [J].Application Research of Computers,2009,26(1):34-40 (in Chinese). [徐翔,刘建伟,罗雄麟.离群点挖掘研究 [J].计算机应用研究,2009,26 (1):34-40.]
[11]HAN Jiawei,Micheline K.Data mining:Concepts and techniques [M].2nd ed.San Francisco:Morgan Kaufmann Publishers,2006.
[12]ZHAO Zhanying,CHENG Changsheng.On improved algorithm for local outlier mining based on cluster analysis and its implementation [J].Computer Applications and Software,2010,27 (11):255-258 (in Chinese). [赵站营,成长生.基于聚类分析局部离群点挖掘改进算法的研究与实现 [J].计算机应用与软件,2010,27 (11):255-258.]
[13]ZHANG Yi,LIU Xumin,GUAN Yong.Density-based detection for outliers and noises [J].Journal of Computer Applications,2010,30 (3):802-805 (in Chinese).[张毅,刘旭敏,关永.基于密度的离群噪声点检测 [J].计算机应用,2010,30 (3):802-805.]
[14]GAO Weihua,XIE Kanglin.New model and related algorithm for the prediction of web user’s directions [J].Computer Applications and Software,2007,24 (3):142-144 (in Chinese).[高卫华,谢康林.Web用户行为预测的一种新模型及 算 法 [J].计 算 机 应 用 与 软 件,2007,24 (3):142-144.]
[15]LI Xuejun,LI Longshu,XU Yi.Research on web user’s behavior prediction base on rough set [J].Computer Engineering and Applications,2008,44 (13):134-136 (in Chinese).[李学俊,李龙澍,徐怡.基于粗糙集的Web用户行为预测研究 [J].计算机工程与应用,2008,44 (13):134-136.]
[16]FAN Jixiang,ZHANG Hong.Application of BP neural network and multi-variable linear regression in rate prediction[J].Computer Engineering and Applications,2007,42(23):203-204.
