高校BBS舆情监测系统设计与实现
2012-07-25陈立章陈晓鹏
陈立章,李 斌,陈晓鹏
(哈尔滨工业大学,威海264209)
1 引言
随着互联网的快速发展,互联网已经为我国锻造出一个全新的舆情传播机制。截止到2010年底,我国互联网网民学生总数占到总网民数的30.6%[1],对于这么一个庞大的一个高校大学生群体,他们对社会诸多现象、现实和问题等反映最为敏感,各种思潮交流相对活跃,喜欢通过BBS对一些社会焦点和热点问题以及国际国内的一些重大问题以及高校内的一些事情展开讨论,产生较大的影响,形成汹涌的网络舆情越来越多。面向高校大学生的网络舆情安全预警与控制手段的不足导致由高校为源头而引发的重大网络舆情事件激增,并有愈演愈烈的趋势,如2008年引起巨大轰动的“学位门”事件等。因此有必要建设高校舆情监测系统,通过舆情监测系统,高校管理者可以准确把握本校校园网整体舆情动态,及时了解舆情信息,密切关注校园网动态,敏锐捕捉一些苗头性、倾向性、群体性问题,提出正确引导大学生舆论的对策建议,及时化解舆情危机。
2 高校BBS舆情监测系统的设计
传统的舆情热点发现技术,通常是通过网络爬虫爬取Web页面,利用自然语言处理和数据挖掘技术对Web页面进行聚类分析,进而在结果中识别热点话题[2]。爬虫开始设计的初衷,其目的是在给定爬行周期内,尽可能多地下载Web网页,并且需要消耗大量的系统资源和网络带宽,爬虫策略的选取对于爬虫的效率有很大的影响,同时爬虫获取网页的实时性有一定限制,周期太短系统负担太重,周期太长获取信息内容滞后。通过改进爬虫策略算法进行主题爬取,在一定程度上提高了爬虫爬取网页的质量[3]。但是如果论坛中的帖子在爬行周期内被论坛管理员或者作者本人删除,爬虫无法获知这些内容的具体信息。有些论坛还可以对某些讨论主题加以权限要求,爬虫由于权限的原因,也无法获知讨论主题的具体内容。而通过旁路模式,可以监控一切发表的主题内容,不会因为由于某些信息获取不到而导致舆情信息分析不周全。
系统在高校网络的出入口处,通过旁路方式实时捕获高校论坛的网络流量,还原出用户访问高校论坛的Web内容,用户IP、论坛的版块、主题、访问时间、以及用户提交的帖子内容等相关信息,将分析出的帖子的URL作为输入数据流,利用改进型LC算法分析出当前访问最频繁的网页,也就是高校学生访问的关注重点内容。系统将论坛用户发表的帖子内容还原出来,通过层次增量聚类算法进行聚类,实时精准地分析出高校论坛舆情热点话题以及话题的关键词集。系统还提供管理接口支持自定义关键字来控制论坛内容的访问范围、访问时间限制等,聚类出来的某些关键词也可以动态添加到系统中。
高校BBS舆情监测系统主要由四大部分组成,数据采集、还原部分、数据分析挖掘部分以及系统管理部分。系统架构及工作流图如图1所示。系统基于哈尔滨工业大学(威海)观海听涛论坛为研究基础,该论坛采用基于 php语言开发的开源系统Discuz,国内许多高校论坛均采用此系统。

图1 系统结构图
3 高校BBS舆情监测系统的具体实现
3.1 数据采集模块
由于高校学生教师人数众多,有的高校同时在线用户达到几万人,因此高校的网络链路带宽都比较大,来满足校内教职员工的上网需求,链路带宽从100M-3G左右不等。系统采用旁路模式来进行数据分析,这么大的流量如果采用传统的捕包方式肯定不能满足系统要求,传统的报文捕获方式是网卡从网络上捕获报文后,会通过中断告知主机CPU,CPU会把报文拷贝到操作系统的协议栈,协议栈经过层层分析,最后把报文提交给应用程序,这个过程会消耗大量的CPU资源,在小包情况下,一般千兆网卡很难实现线速捕包。本系统采用了零拷贝技术[4],网卡收到的报文不再经过操作系统协议栈的层层拷贝,而是直接DMA到应用缓冲区中,避免了数据拷贝的开销。系统通过更改网卡的驱动程序,将网络中的数据报文直接DMA到系统用户区,给上层应用系统提供读取接口,直接调用报文的具体内容。
3.2 数据还原模块
根据Discuz论坛的特点,每一个讨论板块的链接地址:bbs.ghtt.net/forum-1-1.html,其中 bbs.ghtt.net表示站点名,forum表示板块,第一个1表示板块编号、第二个1表示对应板块的页面编号。一个讨论主题的连接地址:bbs.ghtt.net/thread-269118-1-1.html,其中thread表示帖子标识,269118表示帖子编号,第一个1表示帖子的第一页,最后的1无实际意义。通过分析论坛的URL,可以很方便的得到用户访问的板块编号、主题ID等等信息。
数据还原模块调用数据捕获模块提供的接口,将网络中的数据报文进行TCP重组还原。通过HTTP协议分析、URL编解码、字符集编解码转换等等步骤,将论坛中用户发表的帖子内容还原并保存。由于本系统主要处理文字相关的信息内容,因此在保存之前还需要做一步数据净化,过滤系统中用不到的数据部分,如图像、视频、声音、样式表等数据,避免给系统产生干扰数据。数据过滤后,还原用户访问论坛的双向数据,上行数据处理部分主要包括获取用户名和密码,发表帖子的内容。根据主题、作者、作者的IP、发布时间、发布内容等相关项生成xml格式的文件,文件名称为论坛帖子的ID号。下行数据主要根据系统需要记录访问者IP地址、访问页面、访问页面的标题、访问时间、访问页面的内容等等进行存储,以供数据分析模块使用。
3.3 数据分析模块
数据分析模块主要由三部分组成,高频访问分析模块、高频讨论分析模块、热门话题分析模块。这部分是系统的关键部分。高频访问分析模块,主要分析出当前用户访问最多的网络页面,高频讨论分析模块主要分析当前最热门的讨论话题,热门话题分析模块主要分析出当前讨论的主题热门词集。
3.3.1 高频访问分析模块
如果将访问高校论坛的网页流看成数据流,将热门的主题看作频繁项。那么从实时的网络流中可以发现,高校论坛中大家访问的热门主题的问题本质上就是数据流中的频繁模式挖掘问题,访问页面的URL即是频繁集中的数据流。
数据流频繁模式挖掘指,给定支撑度阈值s∈[0,1],对输入数据流 X=(x1,x2,……,xi,……),在任意时刻都能输出当前出现频率超过s·n的数据项列表,其中n是当前数据流的长度。通常的挖掘策略有[5]:抽样法、滑动窗口法、直方图法、哈希法、计数法和Sketch法。计数策略中的LC(Lossy Counting)[6]算法是目前最为有效的方法之一,Lossy Counting算法的基本思想是:在主存中维护数据流的一个样本集合,每当数据流到来一个数据项,若其值已经出现在样本集合中,则将相应的计数器加1;否则,将新到的数据项以及该数据项此前在数据流中出现频率的上界(估计值)加入到样本集合中.数据流每到来1/ε个数据项,Lossy Counting算法对样本集合进行一次扫描,删除其中频率低于εN的样本。Lossy Counting算法的空间复杂度为 O(1/εlogεN)[6]。本系统在 LC 算法基础上,设计了改进型LC算法,采用差值编码的有序双向链表,其中差值编码双向链表的数据结构包括一张散列表和一条双向链表。散列表中每个节点存储一个计数器指针,双向链表中每个节点包含两部分:一部分存储与前一节点计数差值,但首节点存储实际计数值;另一部分存储一条计数器队列,且队列中的计数器具有相等计数值。计数器按升序在链表中排列,头结点的计数器存储数据项实际出现的次数,其他结点的计数器存储和前一结点的计数器的差值,这样只需要修改头结点的计数器值就可以在常数时间内将所有的计数器减1。从而整个算法的时间复杂性就变成了O(1),相比LC的O(log(εN)),有了极大地提升。算法描述如下:
把持续到来的数据流分成若干个桶,每个桶的大小相等w=「1/ε⏋,对 bucket从1开始编号,Bcurrent表示当前桶编号。ε是预先定义的误差界,s是用户指定的支撑度阈值,n表示当前数据流的长度,f表示数据项e的计数器,fe表示e的真实频率,(e,f)表示数据项e在内存中的摘要数据结构,D为摘要数据结构的集合。
Procedure改进型LC
(1)初始化 D=φ,n=0,w=「1/ε⏋
(2)For(每一个数据项e){
(3)总数据长度n加1
(4)If(数据项e在数据集合D中){
(5)数据项e的计数器f加1
(6)}Else{
(7)将数据项e加入到集合D中,e的计数器加1
(8)}
(9)If数据项长度n与桶w大小相等){(10)数据集合D中每一个元素的计数器减1
(11)移除数据集合D中所有计数器为0的元素(12)}
(13)If(如果查询集合中高频元素){
(14)返回集合D中所有频率f≥(s-ε)·n的元素
(15)}
(16)}
3.3.2 高频讨论分析模块
高频分析讨论模块调用数据分析还原模块的生成的xml文件,按照自定义xml文件的格式,将用户Ip、访问时间、帖子主题、帖子内容等等信息存入数据库中。通过Mysql数据库的触发器和存储过程可以从数据库很方便的得出当前论坛中一定时间周期如小时、天、周、月、年内论坛用户讨论最积极的帖子编号,回帖数目等等相关信息,以及发帖量最多的用户,通过这些信息,高校的学生工作者可以很方便的得到当前热点讨论话题、或者论坛上最活跃的用户,来确定下一步需要重点跟踪的话题或者用户。
3.3.3 热门话题分析模块
热门话题分析模块主要由分词部分和主题聚类两部分组成。
分词部分采用中科院的ICTCIAS(Institute of Computing Technology,Chinese Lexical Analysis System)分词系统。ICTCLAS采用了层叠隐马尔可夫模型[7](Hierarchical Hidden Markov Model),将汉语词法分析的所有环节都统一到一个完整的理论框架中,该系统支持自定义词典,为了让系统的分词系统分词更加准确,系统将学校的院系、教师、专业、地名等等信息加入自定义词典。通过读取数据还原部分生成的xml文件,将每个帖子的内容进行分词和词性标记,并且通过对词性的过滤,只保留名词和动词,来尽可能缩小程序所占用的存储空间,并且尽量保留原句的涵义,下一步对剩余词语进行分析。并且根据论坛帖子编号进行索引文档的建立,建立正序索引和倒序索引。
正序索引:帖子中出现词语1帖子中出现词语2……帖子中出现的词语n。
倒序索引:词语出现在帖子中的编号ID1、ID2。
然后通过增量层次聚类的方式将帖子中的词语进行聚类得到论坛中讨论的热门话题词集。增量层次聚类算法描述如下。
(1)聚类部分算法描述
步骤一、通过对一部分固定帖子进行聚类,产生聚类结果,并产生高频词集。同时,存储每个类别所产生的所有词语和对应词频,存储到外存之中。
步骤二、增量获取帖子内容,放入待处理帖子集中。对待处理帖子集中的文本设置处理阈值,文本集中的文本数量到达阈值的时候,开始处理集合中的文本。首先,按照以往的模块将文本预处理,包括分词,词性过滤等步骤。然后将每个帖子与已经产生的类别的高频词集中的词语进行匹配。当帖子与高频词集中部分或者全部词语相匹配时,计算匹配词语的皮尔逊相似度。
假设帖子中的词语(a1,……ai)与高频词集中的(b1,……bi)相匹配,它们对应的词频值为(va1,……vai)和(vb1,……vbi),那么采用皮尔逊距离的相似度计算公式就是:
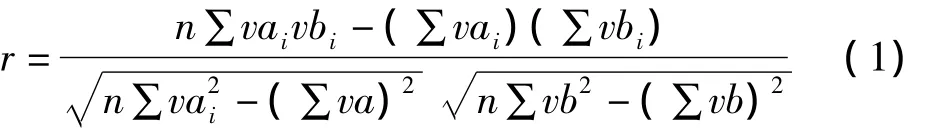
为其设定阈值为α,当r≥α时,就要将该帖子放入已经存在类别当中,如果r<α,就要将其放入待聚类的集合中。
步骤三、当匹配完所有的待处理帖子集合中的所有帖子之后,就可以来处理待聚类集合中的帖子。将这个集合中的帖子采用层次聚类算法进行聚类,这样会产生新的类别,同时,将新产生的类别中的高频集与之前类别的高频词集放在一起,完成本次增量聚类。
(2)更新部分算法描述
步骤一、将新加入该类别的帖子的词语和高频集合有序放入该类别原始的词语权重集合中,如果符合高频词标准的词语有变化,更新高频词集。
步骤二、对有帖子加入原始类别的,需要将新加入类别的贴子所有词语和对应词频加入到原始类别的词语集合中,并按照高频词集选取的方法,更新原有的高频词集。
通过上述算法、就能够得到讨论话题对应主题的高频词集。
3.4 系统监控管理模块
系统监控管理模块主要控制某部分主题的访问范围,达到话题裁剪的目的。
系统监控管理模块通过web界面提供人机交互界面,管理员可以自己添加自定义的关键字、也可以从聚类分析中分析出来的高频词中选择,关键字内容可以为网页的URL、也可以为具体的词语。由于论坛讨论的主题具有时间性,系统可以通过关键字添加附加属性如关键字生效的时间、生效的范围(校内或者校外)来限制帖子中包含有相关关键字内容的访问范围。
为了能够快速地在大流量的网络数据中检测出敏感信息,并且及时进行限制或者阻断敏感信息,系统采用多模快速的字符串匹配技术,扫描一遍数据流就能判断是否有敏感信息出现,从而可以快速发送阻断数据包,保证了限制帖子访问的有效性。此管理模块由协议分析还原模块调用,系统在作分析还原时进行关键字匹配。此模块构造了两个自动机匹配模块,第一个是帖子的URL地址、主要用于对论坛进行URL过滤;第二个是帖子中具体的关键字内容,主要用于讨论主题具体内容过滤。当系统匹配到敏感关键字时系统根据关键字预指定的策略采用相应的措施,放行或阻止。并且记录该行为的日志,可以通过这些日志分析出论坛中那些用户访问敏感信息最频繁,那些主题信息被访问频繁,给管理员管理论坛提供更直观的数据,更好的管理好论坛数据。
4 系统运行结果与分析
系统运行的操作系统为Red Hat Enterprise5,机器配置,CPU为 P4双核处理器,硬盘320G,内存4G,数据库为Mysql5.3,编程语言为C语言。
系统检测环境为观海听涛论坛。系统在4月份开始运行,能够准确分析出当前论坛中讨论的热点话题,每天访问讨论的热点话题。比如我校在4.26日宣布对院系进行合并,主要关系到几个院系的合并。接下来的两三天,学校论坛讨论的热点话题都是围绕院系合并来进行。系统对这些天的帖子聚类结果为:Cluster 1:计算机学院/un、软件学院/un、学位证/n、学费/n、毕业证/n、排序/n、合并/v、广电/un、计算机/un;
聚类结果跟实际主题中讨论的内容基本一致。系统能够准确发现每天论坛访问的热点主题和讨论的最热门主题,同时能够聚类出讨论的关键词集。
对于系统管理部分,为了测试系统的管理功能,分别设置了50个过期页面的URL和100个关键字、在学校内部进行了测试、对于URL的访问、系统均能够成功阻断、阻断率为97%左右,而对于关键字的阻断由于系统工作于旁路模式、关键字在页面中出现的位置以及网络速度的影响,阻断成功率在95%左右,说明系统管理模块功能非常有效。阻断成功后,用户通常在浏览器看到的结果有:空白的页面迟迟打不开、显示连接被重置、显示页面无法打开等。
5 结束语
针对传统采用爬虫的高校BBS舆情发现技术实时性和精准性差、开销大的缺点,提出了基于旁路模式分析还原BBS论坛帖子及URL数据作为论坛热点发现数据源,设计了一套舆情监测管理系统,有效分析出论坛的热点讨论内容。系统经过试运行,系统能够准确发现论坛中的热点话题,并且有效控制主题的访问范围。如果系统稍作适当修改,可以应用到别的类型的论坛、微博、博客等系统的舆情分析和管理、具有一定的通用性。
[1] 中国互联网络信息中心.第27次中国互联网络发展状况统计报告[R].北京:CNNIC,2011.http://www.cnnic.cn/research/bgxz/tjbg/201101/P020110221534255749405.pdf.
[2] Mark Levene,George Loizou.Zipf's Law for Web Surfers[J].Knowledge and Information Systems,2001(3):120-129.
[3] 葛玲,蒋宗礼.基于共现词查询的主题爬虫研究[J].计算机工程,2010(4):286-288.
[4] 王佰玲,方滨兴,云晓春.零拷贝报文捕获平台的研究与实现[J].计算机学报,2005(1):46-52.
[5] 屠莉.流数据的频繁项挖掘及聚类的关键技术研究[D].南京:南京航空航天大学,2009:8-11.
[6] G S Manku,R Motwani.Approximate Frequency Counts Over Data Streams.Proceedings of the 28th International Conference on VLDB[C].Hong Kong,China,2002(8):346-357.
[7] Zhang Hua-Ping,Liu Qun,Cheng Xue-Qi,et al.Chinese lexical analysis using hierarchical hidden Markov model:Proceedings of the second SIGHAN workshop on Chinese language processing-Volume 17[C].Sapporo,Japan,2003.Association for Computational Linguistics,2003:63-70.
