基于WN6102的杜比AC-3音频解码优化
2012-07-18李训根
童 鼎,李训根,黄 凯,杨 洋
(1.杭州电子科技大学电子信息学院,浙江杭州310018;2.浙江大学超大规模集成电路设计研究所,浙江杭州310027;3.杭州微纳科技有限公司,浙江杭州310012)
0 引言
杜比AC-3音频技术是由日本先锋公司与美国杜比实验室共同研制而成。杜比AC-3具有5.1声道的环绕立体声系统,由5个全频带声道和1个超低音声道组成[1]。这6个声道的信息能完美再现高音质的立体声。杜比AC-3解码算法的核心是通过逆改进离散余弦变换(Inverse Modified Discrete Cosine Transform,IMDCT)完成频预到时域的转换。本文首先在软件上对IMDCT运算进行了优化,使得该运算所需的存储空间和运算量大幅缩减。之后,将优化后的算法移植到了自主的32位WN6102 MCU平台上,最后结合该芯片所特有的音频加速模块(Audio Accelerator,AUAC),将该算法中软件实现的IMDCT运算进一步优化成硬件直接完成运算。实验证明,优化后的算法在完成相同的时频转换条件下,显著提升了系统运算速度,有效节省了系统资源,使得该算法可以更加广泛高效地应用于更多的领域。
1 杜比AC-3解码
1.1 AC-3比特流格式
AC-3输入码流由一系列同步帧构成,如图1所示。每个同步帧包括同步信息、比特流信息、6个音频数据块、辅助信息单元以及2个CRC校验字。每个音频块内又包含了指数编码数据、比特分配参数,量化尾数等信息。
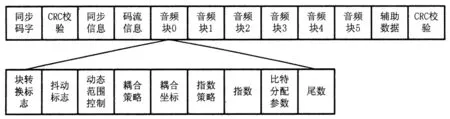
图1 AC-3码流帧结构
1.2 AC-3 解码原理
AC-3解码器的解码流程如下:解码器接收AC-3比特流后先与先进行数据校验,经过误码检测后从数码流中提取出控制数据、系统配置参数、编码后的频谱包络及量化后的尾数等数据。然后根据声音的频谱包络产生比特分配信息,对尾数部分进行解量化,恢复出变换系数的指数和尾数。再经过合成滤波器组,把数据由频域变换到时域,最后输出重建的PCM信号。解码原理框图如图2所示。
在整个解码算法中,综合滤波器组的作用便是使用IMDCT运算将输入的256点的频域采样序列转化成512点的时域序列,再乘以时间窗还原出原来的音频信号。
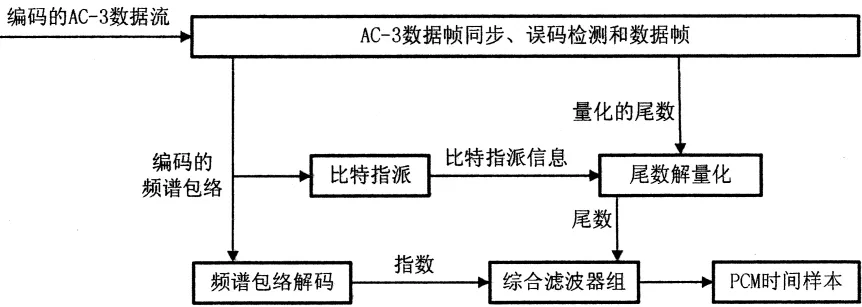
图2 AC-3音频解码算法框图
2 IMDCT的软件优化
杜比AC-3解码中的IMDCT变换有短变换和长变换两种方式,解码时采用方式取决于比特流中的块切换标志位。它们的区别在于使用的正弦、余弦变换表的元素个数及取值不同。
本文以长块为例进行优化,长块IMDCT的变换表达式为:
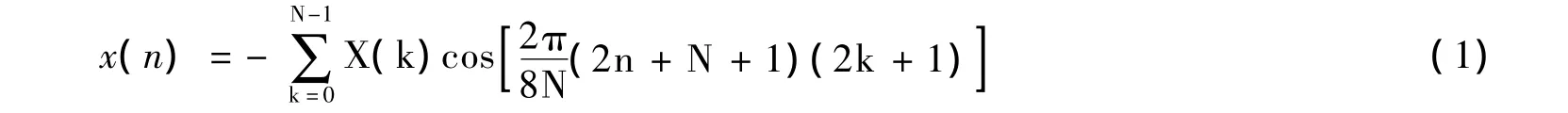
式中,0≤n≤2N-1,x(n)表示时域采样序列,X(k)表示频域采样序列,本文中N=256。
可见直接进行IMDCT运算是相当耗时的,且占用大量存储空间。因此,本文将512点的IMDCT运算优化成128点的FFT进行运算。这样可以大大减少计算量和存储空间。
依据时域混叠特性[2],式1中只需计算x(n)的偶数项序列,便可得到其奇序列。不论输入X(k)为实数还是复数,FFT总是复数的运算过程[3]。式1可以优化成如下表达式:
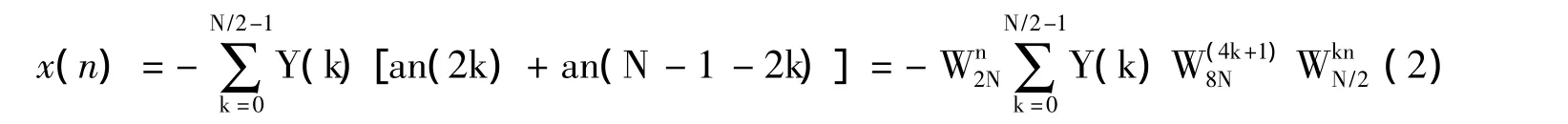
此时,0≤n≤N/2-1,把式2中的Y(k)W(4k+1)8N看做N/2点的输入序列,则式2便是一个标准的DFT表达式。而DFT又可以转化为FFT方式大幅降低运算量,之后再进行时域加窗混叠处理,即可得到2N点的时域采样序列。
本文先在PC机的平台上,使用VC6.0编译工具分别实现了优化前与优化后两种IMDCT算法,优化前后结果如表1所示,表1中N=256。表1数据显示,优化后IMDCT运算所需的计算量和存储空间都有了显著的提升。
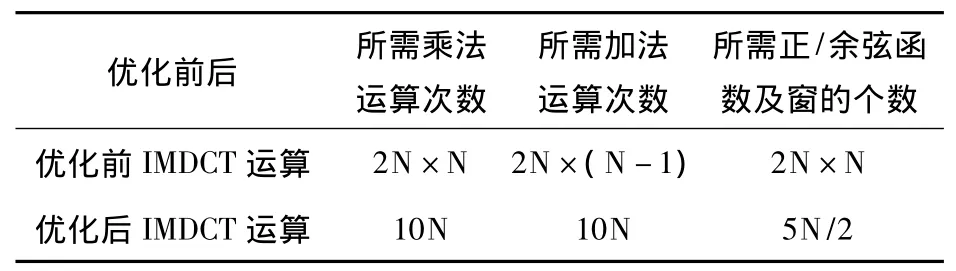
表1 算法软件优化前后数据
3 基于WN6102平台的优化
3.1 硬件平台介绍
本实验算法的目标硬件开发平台是以CK610E CPU处理器为核心的高性能32位MCU—WN6102。CK610E处理器是由浙江大学和杭州中天微系统公司联合开发的32位嵌入式CPU[4]。WN6102的AUAC模块,使其可以在音频领域得到广泛的应用。AUAC内部结构如图3所示。
图3显示AUAC内部结构主要由5部分组成:主数据接口、从数据接口、逻辑控制、寄存器地址以及运算器。它支持多种运算模式,有加法、乘法、累加、乘累加、减法、快速傅里叶变换等运算。不同运算模式间主要区别在于运算器运算方式选择的不同。
3.2 基于AUAC的优化
实验显示软件优化后的IMDCT算法消耗的CPU资源依旧很大,使其应用受到限制。结合AUAC支持乘累加和FFT运算的特点,实验中将IMDCT运算做了进一步优化。优化后的IMDCT分为4步来实现,分别为:(1)FFT变换前加窗处理;(2)128点FFT运算;(3)FFT变换后加窗处理;(4)时域混叠处理还原出512个时域信号。
就运算量和运算方式而言:第一步加窗运算需2N次乘法运算和N次加法运算,转换成AUAC的乘累加模式来实现;第二步N/2点的FFT运算可以直接由AUAC的FFT模式直接完成;第三步加窗运算需2N次乘法运算和N次加法运算,转换成AUAC的乘累加模式来实现;第四步时域混叠需5N/2次乘法运算和N次加法运算,采用AUAC的乘累加模式来实现。
在这一实现过程中,AUAC需执行3次不同的乘累加运算和1次FFT运算才能实现1次IMDCT运算。在此本文将每一步运算都转换成4个阶段来完成。4个阶段的运算逻辑结构如图4所示。
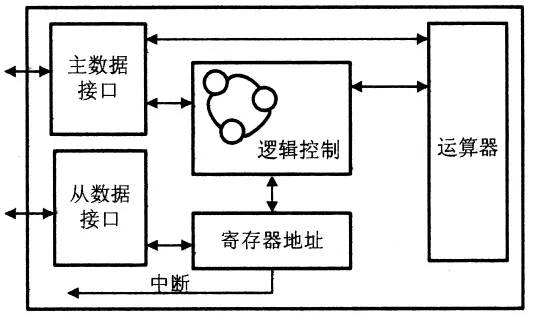
图3 AUAC内部结构框图
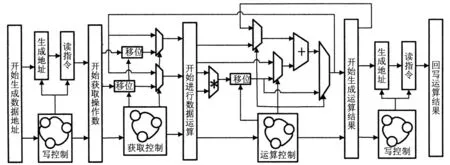
图4 AUAC运算逻辑结构图
图4显示的4个阶段为:数据地址生成、获取操作数、运算、回写。每一阶段的实现方式及功能如下:(1)数据地址生产阶段,配置操作数的类型、位宽及操作数所存储的内存空间等,运算时将生成内存数据读取操作,并发送读数据指令;(2)获取操作数阶段,操作数种类有内存中待计算原始数据和中间计算结果数据。本文中AUAC所实现的IMDCT运算中有3步是基于乘累加模式实现的,故而每步都需配置相应的中间计算值数据的存储地址以供完成相应的运算;(3)运算阶段,在获取操作数后,该阶段就会根据运算类型进行相应的运算操作。执行乘累加运算模式时,在选择操作模式后,还需分别配置相应的乘或加的运算次数。优化后的IMDCT运算中第二步的FFT运算则可以直接配置相应寄存器,使得AUAC工作于FFT模式,来直接替代繁琐的软件运算;(4)回写阶段,配置计算结果的存储地址,该阶段会将最终的计算结果回写到指定的的内存空间中。
实验中进行1次IMDCT运算,用Timer(CPU时钟频率为48M)分别测试经过软硬件优化后IMDCT 4个模块运算消耗的时钟数,测试结果如表2所示:

表2 两种优化后IMDCT运算的结果
表2显示软件实现的IMDCT运算1次需要消耗0.6M的CPU资源,而AUAC硬件实现的IMDCT运算1次只需消耗0.02M的CPU资源。实际音频解码中1帧音频数据包含了6个音频块,以解压成双声道音频为例,那么解压1帧的数据就需要进行12次IMDCT运算。软件实现需要消耗7.6M的CPU资源,而AUAC模块实现只需要0.24M的CPU资源,它能高效的满足嵌入式音频的实时性要求,该方法实现的AC-3解码算法可以更好得应用于嵌入式领域。
4 结束语
目前国内外对AC-3音频解码系统的设计主要可分为:纯硬件设计、纯软件设计、软硬件协同处理。纯硬件实现的解码速度是最快的,但这样做成本太大,可移植性低,目前国内外对AC-3解码纯硬件实现的研究还很少。纯软件实现方面,文献5对AC-3音频解码算法的复杂度和解码运算量方面进行了估算,得出解码器大致需要40M的运算量。文献6则只在VC6.0平台上对标准AC-3解码算法的IMDCT运算进行了优化,使得解码总时间缩短了16%左右。显然纯软件的解码方式效率还是比较低,无法满足嵌入式的实时性要求。
本文对AC-3音频解码中运算量最大的IMDCT进行分析,在对其进行软件优化后,结合WN6102芯片的特性,有效地通过AUAC硬件模块实现了IMDCT运算。整个解码的其余部分通过软件实现。实验结果表明,经过硬件实现后的IMDCT所占系统资源已相当低了,这种软硬件协同处理实现的AC-3音频解码效率远高于纯软件的实现方式。
[1] 王文卿,韩泽耀.杜比AC-3的MDCT算法分析及定点仿真[J].计算机仿真,2007,24(5):306-310.
[2] Princen J,Brandley A.Analysisi/synthesisi filter bank design based on time domin aliasing cancellation[J].IEEE Trans ASSP,1986,34(5):1 153 -1 161.
[3] 窦维蓓,刘若珩,王建昕,等.基于DSP的IMDCT快速算法[J].清华大学学报(自然科学版),2000,40(3):99-103.
[4] 杨洋,郭斌林,黄凯.一种面向无线传输的音频编解码算法的实现和优化[J].计算机系统应用,2010,19(6):70-73.
[5] 刘晓华,陈健.Dolby Digital音频压缩技术的研究和仿真[J].电声技术,1998,12(1):2-7.
[6] 陈玮,余晔.AC-3音频解码的IMDCT算法优化[J].微计算机信息,2011,27(4):206-207.
