一种用于图像分类的改进的有偏特征采样方法
2012-07-13徐盱衡陈秀君
徐盱衡,陈秀君
(西北工业大学 计算机学院,陕西 西安 710129)
图像特征的提取是整个分类算法流程的开始,图像特征的好坏,很大程度上影响着后续算法的区分力的高低。图像特征具有多样性,不同的图像目标往往在颜色、纹理、几何形状乃至提取的兴趣点等一种或若干种特征上具有很大差异,这就是图像分类算法能够具有区分能力的基础。
目前常用的特征点检测算法,能够有效地检测图像的特征,但是一幅图像中往往有多个目标,而且背景混乱、存在遮挡等问题导致图像信息复杂,对于分类任务来说,需要有效地鉴别出图像中的目标,最好将特征采样点尽可能的集中于期望得到分类的目标样本上。一个可能的途径就是先提取图像中感兴趣的区域(Region of Interest,ROI),再对这些区域进行特征采样。
图像分割为我们提供了一个连接图像低层和高层语义的工具,由图像分割得到的同一区域,具有特征上的相似性,而且有效的图像分割算法,能够最大限度地将目标和背景分割开来。如果要计算图像目标出现概率和特征的关系,可以考虑使用图像分割作为沟通目标和区域特征的桥梁。
文中基于文献[1]的方法做出了一些改进。文献[1]中基于以上思想及BoF框架提出的有偏采样方法在分割后对特征聚类之前采用了硬量化编码的方式,量化后编码不能有效反映图像区域特征,本文通过使用基于局部约束的线性编码方式[2](Locality-constrained Linear Coding,LLC)替代硬编码,减少了量化误差。同时,使用VOC数据集中对目标的标注数据,以目标在某区域出现的多少作为依据计算后验概率;使用近年来新发展的显著性检测算法[3]取代Itti的算法[4],取得了较优的效果。
1 图像特征的有偏提取
对于一幅图像来说,要识别其中特定的目标类别,仅靠BoF模型可能会导致误判。有多种情况可能会导致这一问题,例如目标物体过小,如果对整个图像均匀采样,那么代表目标的特征将只在全部特征中占据很小的部分,如见图1所示,或者目标被其他物体所遮挡,等。
对人视觉的研究表明,人观察外部事物是采取的是自顶向下的记忆选择机制[5]和自底向上的显著注意结合的方式,这启发我们采取同样的方式思考图像分类算法的过程。能否同时采取两种方法结合的方式,计算出图像中相对最可能出现目标的区域,以便于后续的处理。文献[1]给出了一种具体的方法,如图2所示,下节将介绍这种方法的详细过程及对其的改进。

图1 全局的特征表示有时会导致判别失败Fig.1 Global feature representation sometimes causes discrimination failure
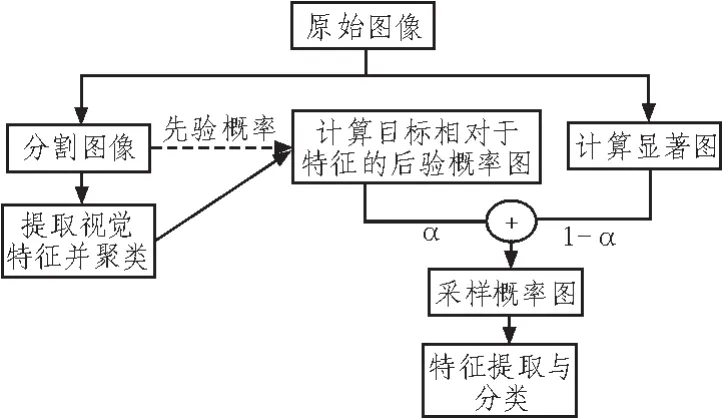
图2 有偏采样算法的主要步骤Fig.2 Key steps of the biased sampling strategy
1.1 自顶向下的目标类后验概率计算
首先使用mean-shift算法[6]分割图像,对相应的颜色、纹理[7]、几何特征[8]直方图,分别聚类得到3个词典。将所有图像分割区域的特征都硬编码到词典的某一视词。令F代表基于区域的某一种特征,Fi表示特征词典里的某一视词,O表示图像中有某类目标表示图像没有此类目标,定义R为给定Fi而出现O的后验概率,
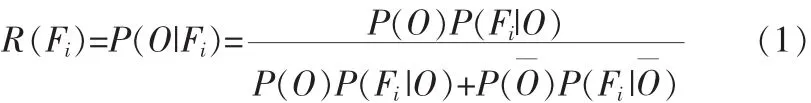
假定P(O)=P(O),也就是认为目标在图像中出现与否的先验概率是相等的。事实上这个假设对于PASCAL VOC等数据集并不合理。以VOC2007的分类集为例,共有20类,分类时采取1对多的方式,共要训练20次,每次正样本和负样本之比约为 1:19。
R(Fi)=0 表示预测为负样本图像,R(Fi)=1 表示正样本图像,R(Fi)=0.5时正好介于两者之间。因此选择

这样给定一幅新图像,就可以通过分割-提取特征-计算的步骤得到目标基于区域特征的后验分布图T1:

其中N(·)是归一化运算符。
1.2 最终采样图的生成
Yang[1]采用Itti[4]的算法计算显著图。我们在实验部分将采用Goferman[3]的算法计算显著图。
令计算得到的显著图为T2,通过加权求和的方式表示最终的采样概率图T:

更进一步,为了得到在(x,y)点任意尺度的概率密度函数,对T进行逐像素的积分:
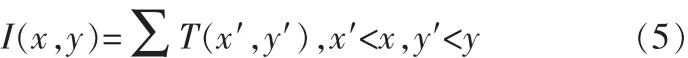
那么在(x,y)点处尺度为s×s的图像块的采样概率为

这样,就可以使用上述的概率分布大小为s×s的图像块上利用DoG方法提取图像特征点。
2 对有偏采样算法的改进
在上节中叙述的有偏采样算法中目标类后验概率的计算方法,其中不乏可改进之处。 如前所述,(1)中假定P(O)=P(O)对VOC等数据集并不合理;其次,对每个被分割区域的特征根据视觉词典进行硬编码,会导致对视词分界线附近的较大的不可避免的特征量化误差,应该用软编码方式替代;最后,原方案中令O表示图像中有某类目标,并直接与图像某区域特征相关联,这并不合理,因为即使待分类目标在图像中出现,也仅仅和部分区域有关,不能将其和没有出现该目标的区域特征联系起来。
基于上述讨论,对公式(1)做出修改。定义O′表示图像分割区域中有某类目标,且此目标占分割区域面积一半以上,表示分割区域中没有此类目标,或者目标占分割区域面积到一半。使用LLC编码方法代替硬编码方法,那么P(Fi|O′)和P(Fi′)仍然表示出现或者不出现目标时有特征的Fi概率,但由于一个区域的同一个特征直方图被量化到若干视词Fi上,对不同的Fi计算P(Fi|O′)和P(Fi|′)时可能会多次包含同一区域,且累加的是区域特征相对于Fi的系数值。于是(1)变为
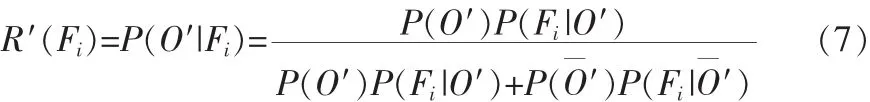
仍然使用式(2),给定一幅新图像,先对其进行分割,计算每个区域的特征,将特征编码以后得到的非零系数与其对应的视词概率相乘,求和以后作为该特征对应的目标出现的后验概率,即

其中cij对应于第i类(i=1,2,3)区域特征编码后的非零系数。于是得到目标基于区域特征的后验分布图T1′:

3 实验结果与讨论
使用Normalized Cuts[9]方法分割图像,每幅图像分割成10块。使用基于BoF[10]的颜色直方图、纹理直方图和矩信息三种特征表示图像区域。对于颜色直方图,使用Lab颜色空间,每个通道有23个直方区间。对于纹理直方图,使用一个总数为18的滤波器组 (共有6个方向,3个层次),1个高斯滤波器,1个拉普拉斯-高斯滤波器。将纹理texton通过k-means聚类量化成400个,将每个像素的对应值硬编码量化到其中的一个,最后每个图像分割区域中的texton视词累积形成一个纹理直方图。对于几何量度,使用Hu的矩不变量[8],对每幅图像计算得到1个7维向量。假定各视觉特征相互独立,通过k-means分别聚类得到3个词典,词典的视词个数分别是KC=1 024,Kt=1 024,Km=512。 使用[3]提供的显著性检测方法提供显著图。图3显示了根据不同采样方法进行采样的结果。可以看到,较中列的普通SIFT检测,右列的有偏SIFT特征在目标区域(分别是人、鸟、牛)更集中一些。在第二幅图片中的鸟颜色和纹理与背景相似,所以采样点也有很多在背景上面。

图3 有偏采样示意图Fig.3 Illustration of biased sampling
随后在VOC数据集上进行实验不同的采样点数对分类精度的影响。使用BoF模型,并采用金字塔框架[11]以增强分类精度。使用稠密兴趣点检测的方法,网格尺寸设为4×4像素,提取的图像块设为16×16像素。一般而言,在这个参数组合下单幅图像的稠密SIFT特征个数都能大于7 500;如果单幅图像总共的SIFT特征没有达到10 000,就全部选取。
对于VOC 2007数据集,使用k-means方法聚类得到词典,词典基向量个数为25 000。采用LLC编码方式与liblinear分类器,在实验中均取α=0.5。结果如图4所示。
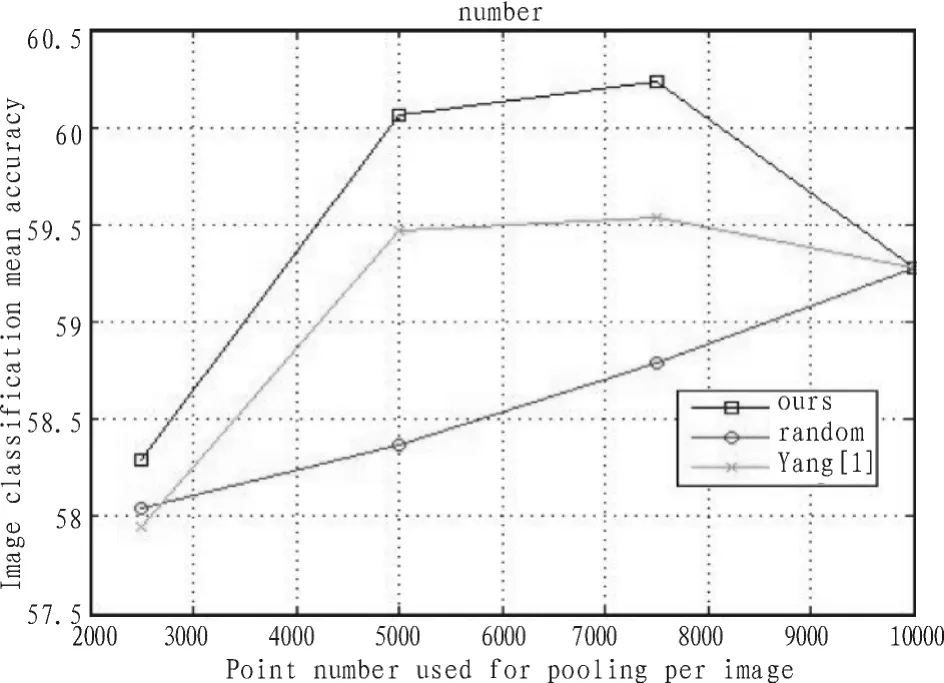
图4 采样算法分类性能比较(VOC 2007)Fig.4 Comparison of different sampling algorithms(VOC 2007)
在VOC 2010数据集上进行实验,词典基向量个数为20 000,结果如图5所示。
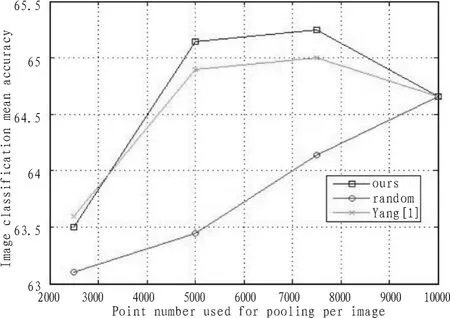
图5 采样算法分类性能比较(VOC 2010)Fig.5 Comparison of different sampling algorithms(VOC 2010)
在两个实验结果中可以看到,随着每幅图像选取采样点数的下降,随机选择会导致分类性能逐渐下降(VOC2007:平均精度从采样点数10 000时的59.3%下降到点数2 500时的58.1%;VOC2010:平均精度从采样点数10 000时的64.7%下降到点数为2500时的63.1%)。Yang的有偏采样算法在采样点数为7 500时分类精度最高,在5 000时略有下降,在2 500时降到最低,改进的有偏采样算法也显示了同样的效果。这一方面说明了有偏采样算法的有效性,滤除了一部分和目标判别没有直接关系的特征点,导致分类精度有一定的提升;另一方面也间接地证明了pooling过程在分类中的作用:能够挑选出具有区分度的编码系数。如果采样点数选的太少,则pooling的区分度下降,这和Yang[1]中显示的结果一致。另外,在两个数据集上,我们的改进算法较Yang[1]的算法都有0.3~0.5%的性能改进。
4 结束语
文中提出了一种改进的有偏采样算法。使用自顶向下的概率方法与自底向上的显著性检测方法相结合的策略,对图像的特征点进行有偏采样。通过用基于局部性约束的线性编码方式替代硬编码方式对区域特征进行编码,并且改变计算后验概率计算方式,实验结果验证了算法的有效性和改进算法的效果。
[1]Yang L,Zheng N,Yang J,et al.A biased sampling strategy for object categorization[C]//Int.Conf.on Computer Vision(ICCV), Kyoto, Japan,2009:1141-1148.
[2]Wang J,Yang J,Yu K,et al.Locality-constrained linear coding forimage classification [C]//Proceedingsofthe Conference on Computer Vision and Pattern Recognition(CVPR),2010.
[3]Goferman S,Zelnik-Manor L,Talr A.Context-aware saliency detection[C]//Conference on Computer Vision and Pattern Recognition,2010:9-16.
[4]Itti L,Koch C,Niebur E.A model of saliency based visual attention for rapid scene analysis[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,1998,20 (11):1254-1259.
[5]Navalpakkam V,Itti L.Top-down attention selection is fine grained[J].Journal of Vision,2006,6(11):1180-1193.
[6]Comaniciu D,Meer P.Mean shift:a robust approach toward feature space analysis[J].IEEE Trans.PAMI,2002,24(5):603-619.
[7]Martin J, Belongie S,Shi J,et al.Leung.Textons, contours and regions:cue combination in images segmentation[C]//In Proc.ICCV’99,1999:918-925.
[8]Hu M.Visual pattern recognition by moment invariants[J].IEEE Trans.Information Theory,1962(IT-8):179-187.
[9]Shi J,Malik J.Normalized cuts and image segmentation[J].TPAMI,2000,22(8):888-905.
[10]Lee Y J,Grauman K.Object-graphs for context-aware category discovery [C]//In Computer Vision and Pattern Recognition (CVPR),2010:1-8.
[11]Yang J,Yu K,Gong Y,etal.Linearspatialpyramid matching using sparse coding for image classification[C]//in Proceedings of the Conference on Computer Vision and Pattern Recognition(CVPR),2009.
