浅谈全文检索系统中文档相关性排序问题
2012-07-12北京政法职业学院信息技术系胡晓凤侯佳路
北京政法职业学院信息技术系 李 迎 胡晓凤 侯佳路
当人们艰难的在信息的海洋里查找自己所想要的内容时,搜索引擎是由此而生一种技术,并且在互联网中得到重要的应用。全文检索技术是现代信息检索技术的一个重要的分支,现在的搜索引擎主要研究的是全文检索技术,它是搜索引擎的核心技术,是处理非结构化数据的强大工具,全文检索技术当前的成果除了对以前信息检索的功能实现,同时能直接根据信息的内容进行检索,能实现对多角度信息资源的综合利用。
在全文检索系统的设计中主要包括两大部分的设计第一就是索引的建立第二是检索索引,此论文是关于第二个问题中检索到的文档的相关性打分的一些见解。在全文检索系统的检索过程设计中,当检索者输入查询语言后,系统对查询语句进行语法分析及语言处理,在语法处理过程中主要为了实现辨别单个字和关键字,发现查询语句不满足语法规则的,系统会报错,词法分析中发现不合法的关键字,系统会出现错误。检索系统中语言处理的过程同索引建立过程中的语言处理几乎相同,在搜索索引时,得到符合语法树的文档,并根据得到的文档和查询语句的相关性,对文档结果进行排序。对查询结果的排序是按照与查询语句的相关性进行的,越相关者越靠前。
那么计算文档和查询语句的相关性的做法是什么呢。我们把用户输入的查询语句看成一个短小的文档,然后对文档与文档之间的相关性(relevance)进行打分(scoring),分数高的它的相关性就好,就应该在前面排列,因此关键部分的设计就是如何对文档之间的关系进行打分。
一、文档相关性算法模型
检索系统的作用是根据用户提出的查询需求在索引库中快速查找所需要的文档信息,并对文档与查询的进行相关度评价,然后排序将要输出的结果,同时实现某种用户相关性反馈机制。当用户在进行信息检索时,都想得到与自己需要密切相关的检索结果时,就需要检索系统解决一个核心问题那就是,当用户给定期查询后,对文档集中的每一个文件与用户查询相关程度做出判断。那如何判断文件与用户查询相关,便是信息检索模型所要解决的问题。
通过判断词之间的关系从而得到文档相关性的过程的算法经常用的检索模型主要包括布尔模型、向量空间模型、概率模型,这里只讨论向量空间模型。
向量空间模型(VSM:Vector Space Model)是近年来使用较多且效果较好的一种信息检索模型。在VSM中,将文档看作是由相互独立的词条组(T1,T2…Tn)构成,对于每一词条Ti,都根据其在文档中的重要程度赋以一定的权值Wi,并将T1,T2…Tn看成一个n维坐标系中的坐标轴,W1,W2…Wn为对应的坐标值。这样由(T1,T2…Tn)分解而得的正交词条向量组就构成了一个文档向量空间,文档则映射成为空间中的一个点。对于所有文件和用户查询都可映像到此文本向量空间,用词条向量(T1,W1,T2,W2…Tn,Wn)来表示,从而将文件信息的匹配问题转化为向量空间中的向量匹配问题。假设用户查询为Q,被检索文档为D,两者的相似程度可用向量之间的夹角来度量,夹角越小,说明相似度越高。
检索模型提供了度量查询和文档之间相似度的办法。总之这些模型具有共同的理念即当文档中词和查询中词共有的词项(term)越多,则认为这篇文档和此次查询越相关。语言本身就存在着很多的不确定因素,一个相同的概念可以用多个不同的词来表达(如“漂亮”和“美丽”可能指的是同一含义)。另外,相同的词也有多种语义(比如“希望”和“圈”,它们的名词形式和动词形式的意思不同。通过上面介绍的一些检索算法来解决这些语言中的不确定性问题。
检索模型就是一种算法,这种算法处理对象是查询Q和文档集合{D1,D2,…,Dn},处理过程就是计算每篇文档Di(1≤i≤n)和这个查询的相似度SC(Q,Di)。[注:SC是Similarity Coefficient(相似度)的缩写,有时记作RSV(Retrieval Status Value),用来表示检索状态值]。
二、文档之间的关系进行打分
1.找出文档中重要的词
一篇文档有很多个词(Term)组成,例如有中、法、国、律、地、啊等。对于文档之间的关系,不同的词重要性不同,有的文档法、律、地就相对重要一些,国、中,可能相对不重要一些。因此若两篇文档都包含法、律,则这两篇文档的相关性强一些,然而就算一篇文档包含的、啊、呢,另一篇文档不包含的、啊、呢,也不能影响两篇文档的相关性。因而在判断文档之间关系时,应首先找出哪些词(Term)对文档之间的关系最重要,如中、法、率。然后判断这些词(Term)之间的关系。
2.计算词的权重(Term weight)的过程
词的权重是指计算词在文档中重要性的过程称。计算词的权重(term weight)有两个参数,第一个是词(Term),第二个是文档(Document)。词的权重(Term weight)表示此词(Term)在此文档中的重要程度,越重要的词(Term)有越大的权重(Term weight),因而在计算文档之间的相关性中将发挥更大的作用。
影响一个词(Term)在一篇文档中的重要性主要有两个因素:
Term Frequency(tf):即此Term在此文档中出现了多少次。tf越大说明越重要。
Document Frequency(df):即有多少文档包含次Term。df越大说明越不重要。
设计到词的权重计算公式中:

文档中一个词(Term)出现的次数越多,说明这个词对这个文档重要性大,如“法律”这个词,在本文档中出现的次数很多,说明本文档主要就是讲与该词相关的内容。但在一篇英文文档中,this出现的次数多,也不能说这个词重要,这时第二个因素就开始起作用了,它说明有越多的文档包含这个词,说明此词普通,在区分此文档重要性时就低。对于文档中词项的权重因素,主要综合考虑词频即tf和逆文档频率即idf。
三、标准化因子的影响
在开源的全文检索系统luence中谈到标准化因子对文档排序打分的应用。在搜索过程中,搜索出的文档要按与查询语句的相关性进行排序,相关性大的打分高,从而排在前面。这里相关性打分使用向量空间模型,在计算相关性时需要计算词的权重(Term Weight),这在第一个问题中已经阐述,也即某Term相对于某Document的重要性。在计算词的权重时,主要有两个影响因素,一个是词在此文档中出现的次数,一个是词的普通程度。显然该词在同一篇文档中出现的次数越多,这个词在此文档中越重要。
这种词的权重计算方法是最普通的,但却存在以下两个问题:
1.在不同需求中文档重要性不同。
有的文档重要些,有的文档相对不重要,比如对于做软件的,在索引书籍的时候,我想让计算机方面的书更容易搜到,而文学方面的书籍搜索时排名靠后。
2.文档中不同的域重要性不同。
有的域很重要,例如关键字、标题,但附件中的内容相对不那么重要等。因此对于相同的词,出现在关键字中要比出现在附件中打分高。只根据词在文档中出现的绝对次数来判断该词在这篇文档中的重要性,是不太合理的。
由上面两个原因,并参照全文检索引擎Lucene,在计算词权重时,乘上一个因子,即标准化因子(Normalization Factor),来减少上面随时会遇到的两个问题对文档排序的影响。
标准化因子(Normalization Factor)是会影响查询时打分(score)的计算,在搜索引擎系统中有关打分计算的设计,一部分在索引建立过程中,一般是与查询语句无关的参数如标准化因子,而大部分设计在搜索过程中,标准化因子(Normalization Factor)在索引过程总的计算如下:
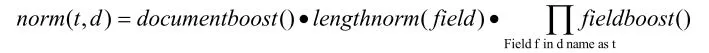
它包括三个参数:
Document boost:此值越大,说明此文档越重要。
Field boost:此域越大,说明此域越重要。
lengthNorm(field)=(1.0/Math.sqrt(numTerms)):一个域中包含的Term总数越多,也即文档越长,此值越小,文档越短,此值越大。
从上面的公式可以知道,一个词(Term)出现在不同的文档或不同的域中,标准化因子不同。若两个文档,每个文档有两个域,如果不考虑文档长短,就有四种排列组合分别为:在重要文档的重要域中,在非重要文档的重要域中,在重要文档的非重要域中,在非重要文档的非重要域中。每种组合都有不同的标准化因子。公式中第一个因子是不同文档的重要程度不同,第二个因子是文档长度的影响,第三个因子是不同的域的重要程度不同。
[1]张进.计算机信息检索软件设计原理[M].武汉:武汉大学出版社,1996.
[2]余海燕,张仲义.基于单汉字索引的全文检索系统的优化研究[J].中文信息学报,2001.
[3]杨建林.全文检索研究[J].情报理论与实践,2000,1.
[4]李广建,黄永文.基于WWW的全文检索系统的设计与实现[J].现代图书情报技术,2000,2.
