基于甲骨文字形动态描述库的甲骨文输入方法
2012-07-09栗青生吴琴霞
栗青生,吴琴霞,王 蕾
(1.安阳师范学院 计算机与信息工程学院, 河南 安阳 455002;2.武汉理工大学 信息工程学院,湖北 武汉 430070;3. 甲骨文数字化工程研究中心,河南 安阳 455002)
1 引言
甲骨文字作为一种独特的符号系统,具有和现代语言系统的文字一样的社会、历史和文化的传承功能。随着计算机信息技术的发展,研究学者对标准甲骨文字形产生巨大的需求,要求计算机能像现代文字一样处理甲骨文字。多年来,在甲骨文数字化过程中一直存在着甲骨文难以输入的问题。
可以看到,在解决甲骨文的计算机输入的过程中,许多学者参照现代汉字的计算机输入方案,从形码、音码等多个方面研究出发,提出了各种各样的解决方案,解决了部分甲骨文字在输入方面的困难。但到目前为止,仍然没有一个完整的方案能够解决全部甲骨文字的输入问题[1-3]。
解决甲骨文的输入和输出问题和解决现代汉字的输入和输出问题的方法是不同的,现代汉字已经有确定的内码,只要找出一个描述外码和内码这两个状态空间的一致性的方法,现代汉字问题的编码方案就可以解决。近年来,有学者提出用解决汉字的不规范字的方法去解决所有的古文字的输入和输出,例如,参考文献[4]给出了一种笔段网格的形式化描述方案,但该方案仅针对了汉字的集外字的处理,而甲骨文字不仅有未识别的集外文字,还有很多和现代文字对应的集内文字,显然,这一方案不能处理甲骨文字。也就是说,甲骨文字的输入问题不仅要解决甲骨文的外部编码(输入码)问题,更重要的是要解决好甲骨文字的内部编码和现代文字内部编码的对应该关系问题。可以说,如果甲骨文字的内码问题解决了,现代汉字的一些成熟的解决方案(如拼音、五笔输入方法等)完全可以用于甲骨文的输入。
2 常用的甲骨文编码方法及存在的问题
将一个给定的甲骨文字数字化为计算机能够进行编辑和识别的甲骨文字,就是要通过合理安排Unicode空间中现代汉字和甲骨文字的计算关系,给甲骨文字一个确定的内部编码(Unicode码)。通常可选两种类型的编码方法,一是将甲骨文视为一种特殊字体,其编码就是现代汉字的对应编码;二是使用Unicode空间的中Private Use Area区间进行重新编码,即现代汉字和它所对应的甲骨文字采用不同的编码方式。
第一种编码方法的优点是保证了每一个甲骨文字和现代对应的文字编码的统一性,用现代汉字输入法解决甲骨文的输入困难,不足的是这种编码方法解决不了甲骨文中异体字的输入问题和目前没有识别的甲骨文的输入问题。和现代汉字不同的是,甲骨文字几乎每一个字都有异体字,而且大多数不只一个,如现代汉字“身”和“妹”对应的甲骨文字其异体字就有四个[5](表1)。另外,由于目前还有近三分之二的甲骨文字没能完全考释,这些文字如何输入?现在的汉字输入方法回答不了这样的问题。
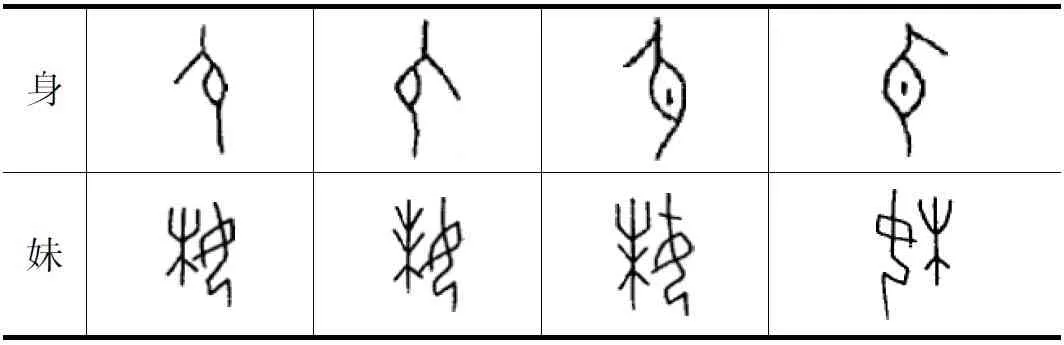
表1 汉字“身”和“妹”部分甲骨文异体字
第二种编码方法用Unicode的E000到F8FF的Private Use Area区间内进行编码固然可行,但同样存在对异体字进行编码的困难,目前,对于甲骨文中的异体字的认识还没有一个统一的标准,在参考文献[6]中,异体字被限定为有限多个,因此,整个文字的规模和数量完全可以放在Private Use Area区间,但随着对甲骨文字研究的深入,对字形结构的不同的认识和处理,都会导致文字和异体字的数量增加,例如,有学者提出,形状和位置略有不同的甲骨文字都应视为异体字,这样,有限的Private Use Area区间就不能容纳多达几万个甲骨文字了。
输入甲骨文字的特殊性,要求在建立甲骨文字的输入和编码方案之前必须先建立一个合适的解空间,使得包括目前可识的(或可隶定的),不可识的,同字异形的,异字同形的等等都能在这个解空间中进行定义和计算[7],显然,从目前标准的Unicode编码系统的一字一码的编码特点和所能提供的有限的码位空间来看,这个解是很难确定的。
3 甲骨文字形描述方法和规则
3.1 甲骨文字形描述的方法
由于在有限的编码空间内不能实现所有的甲骨文字及异体字编码,甲骨文的编辑和处理就变得异常复杂,影响了甲骨文字的输入和输出。通过多年的研究和试验,我们提出了基于甲骨文字形动态描述库的甲骨文输入方法,使用这一方法的前提是建立甲骨文字形动态描述库。甲骨文字输入和输出过程都是针对动态描述库来进行,具体实现方法和步骤如下。
步骤1 整理甲骨文字拓片,进行文字采集,按目前甲骨文的考释结果,将甲骨文分为可识甲骨文和不可识甲骨文两组。
步骤2 对可识甲骨文,按照和现代汉字的对应文字进行编码,内码和现代汉字相同。 对不可识甲骨文,在Unicode的E000到F8FF的Private Use Area区域按笔画结构(注: 即下文中的笔元)的顺序进行编码排序,创建字形库。
步骤3 对创建的字形库进行动态描述,得到字形描述库。
步骤4 在字形描述库中,对现有的甲骨文异体字进行动态描述,并建立字形库和描述库中字形对照表。
步骤5 对已经识别的甲骨文的输入,使用通用的输入方法输入现代汉字,利用步骤4中建立的字形对照表调用甲骨文字形描述库进行输出。
步骤6 对目前还没有识别的甲骨文字有两种输入方法,一是使用字形描述库中的索引号直接输入,二是通过步骤5先输入和已经识别文字的相似字形,通过动态的调整形成新的需求字形,并且存储后输出。
在这五个步骤中,除第三步以外,其他步骤实现起来比较容易,而第三步涉及字到图到字和字到图的转化,必须设计甲骨文字形描述规则。另一方面,描述库中的字形并没有完全囊括所有字形,更多的新发现字形、不规则字形和异体字等在使用时要对某些字形进行动态的编辑和调整,因此,称为动态描述。
3.2 甲骨文字形描述规则
3.2.1 概念、规则和定义
与汉字不同的是甲骨文字是契刻文字,不像现在的汉字一样有完整的笔画结构,给计算机输入和识别带来了很大的困难。因此参照现代汉字的书写方法,引入有向笔段和笔元的概念。
(1) 有向笔段的定义
有向笔段: 是有方向的线段,设(Xi,Yi)是起始点,(Xj,Yj)是结束点,则一个完整的有向笔段的描述为:
Bij={(Xi,Yi)|(Xj,Yj)}
(1)
有向笔段的起始点也叫始点(或势点),有向笔段的结束点也叫驻点。将笔段定义为有方向性的重要意义在于方便弧线的描述和机器识别。
(2) 笔元的定义
笔元: 笔元是由一个或者多个有向笔段组成的甲骨文中一个完整的笔画结构,设一个笔元由n个有向笔段来组成,则笔元的描述为:
SSn={BS1,BS2,BS3,……,BSn}
(2)
或者为:
SSn={(Xi1,Yil)|(Xj1,Yj1),(Xi2,Yi2)|(Xj2,Yj2),……,(Xin,Yin)|(Xjn,Yjn) }
3.2.2 甲骨文的基本笔元
笔元相当于现代汉字的笔画。一个甲骨文字笔元的多少与这一文字的结构有关,由于笔元有方向性,因此同一笔元的描述方法有多种,例如,一横“—”的描述可以以左边做为起始点描述,也可以右边为起点描述,一竖“|” 可以以上边做为起始点描述,也可以下边为起点描述,同样,“撇”和、“捺”也同样如此,参照现代汉字的书写原则,笔元的描述按照“由左到右,由上到下,由外到内”的顺序去描述。根据对目前5 917个甲骨文的笔元进行统计,我们将甲骨文的笔元分成两类基本的笔元: 一类是折线笔元(在这里将横、竖、撇和捺线都视为特殊的折线),另一类是弧线笔元,如表2所示。

表2 甲骨文的基本笔元
3.2.3 两种基本笔元的有向笔段
有向笔段的方向性是参照现代汉字的书写顺序而确定的,即按照“从左到右,从上到下,从右上到左下,从左上到右下”的书写顺序来确定笔段的方向。例如,横线的方向性是从左到右,竖线的方向性是从上到下,撇线的方向性是从右上到左下、捺线的方向性是从左上到右下。笔段的方向性确定了笔元描述的一致性规则,便于后期对甲骨文字的编码和识别。
折线笔元的有向笔段: 组成折线笔元的有向笔段比较简单,通常由一到四个有向笔段组成,例如,横线、竖线、撇线、捺线只有一个有向笔段,上折线、下折线、左折线和右折线有两个有向笔段,三角形线有三个有向笔段,矩形线有四个有向笔段。
弧线笔元的有向笔段: 组成弧线笔元的有向笔段比较复杂,通常最少设定由五至十个有向笔段组成,考虑到不同弧线的书写顺序不同,将书写方向不同的弧线描述为不同的弧线。例如,左侧弧线“(”书写顺序包括从右上到左下,从上到下,从左上到右下等,右侧弧线“)”书写顺序包括从左上到左下,从上到下,从右上到左下等,因此描述左侧弧线和右侧弧线的有向笔段应该使用不同的笔元。如表3所示是各个弧线笔元的有向笔段组成图。
现代汉字中有的字形使用精度更高的B样条曲线与Bezier曲线来描述汉字中的弧线,而甲骨文为刻绘文字,使用有向笔段来描述更加接近原始字形。一个笔元中,有向笔段的数量越多,数据描述越精细,将来文字的识别越准确,但计算的复杂度会越高。

表3 甲骨文弧线笔元的有向笔段
3.2.4 笔元的起始点和终结点的界定
甲骨文字由笔元组成,每一个笔元都有起点和终点,为了不使多个笔元之间的起始点和终结点发生错乱,必须对笔元的起始点和终结点进行界定,为此,我们使用二维特征字符进行分割界定。设(Si,Si)为笔元的起始界点,(Ei,Ei)为笔元的终结界点。这样,每个笔元就可以描述为:
SSn={(Si,Si),BS1,BS2,BS3,……,
BSn,(Ei,Ei)}
(3)
或者为:
SSn={(Si,Si),(Xi1,Yi1)|(Xj1,Yj1),(Xi2,Yi2)|
(Xj2,Yj2),……,(Xin,Yin)|
(Xjn,Yjn),(Ei,Ei)}
笔元的起始界点也称为始界点,笔元的终结界点也称为终界点。
3.2.5 归一化处理
甲骨文字形可以描述为多个笔元的组合,这个组合可以表示为排列(空间)位置上的组合或者书写顺序(时间)上的组合,由于甲骨文不象汉字那样规范,因此,按笔元排列位置上的组合不便于操作,因而采用书写顺序上的组合,也就是按照书写的顺序将各个笔元进行排列,设一个甲骨文字有n个笔元,则这个字的描述可以表示为:
ZX={(Si1,Si1),(Xi1,Yi1)|(Xj1,Yj1),
(Xi2,Yi2)|(Xj2,Yj2),……,(Xin,Yin)|
(Xjn,Yjn),(Ei1,Ei1),(Si2,Si2),(Xi1,Yi1)|
(Xj1,Yj1),(Xi2,Yi2)|(Xj2,Yj2),……,(Xin,Yin)|(Xjn,Yjn),(Ei2,Ei2),
(Si3,Si3),(Xi1,Yi1)|(Xj1,Yj1),
(Xi2,Yi2)|(Xj2,Yj2),……,(Xin,Yin)|(Xjn,Yjn),(Ei3,Ei3),
……,
……,(Ein,Ein)
}
(4)
在组合后的笔元中,分割界定的二维特征字符只是一个分界符号,与笔元没有直接的关系,另外,一个起点和一个终点的分界符可以合成为一个起点的分界符。因此将其作归一化处理,这样表达式(5)就可以表示为:
ZX={(S,S),(Xi1,Yi1)|(Xj1,Yj1),(Xi2,Yi2)|
(Xj2,Yj2),……,(Xin,Yin)|(Xjn,Yjn),
(S,S),(Xi1,Yi1)|(Xj1,Yj1),(Xi2,Yi2)|
(Xj2,Yj2),……,(Xin,Yin)|(Xjn,Yjn),
(S,S),(Xi1,Yi1)|(Xj1,Yj1),(Xi2,Yi2)|
(Xj2,Yj2),……,(Xin,Yin)|(Xjn,Yjn),(S,S),
……,
……,(E,E)}
(5)
归一化处理之后的始界点和终界点统称界点。
3.3 甲骨文字形描述示例
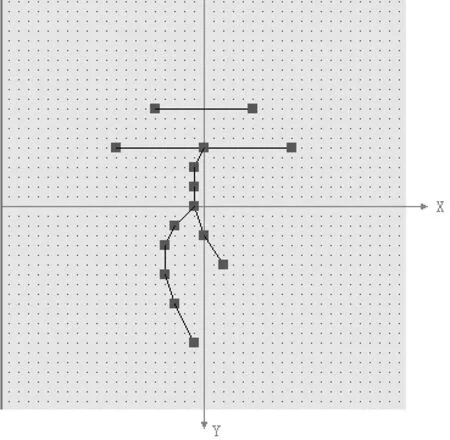
图1 字形描述坐标系
(-64,0) (-5,-10)(5,-10) (-64,0)
(-9,-6)(9,-6) (-64,0) (0,-6)
(-1,-4)(-1,-2)(-1,0)(0,3)(2,6)(2,6) (-64,0) (-1,0)(-3,2)(-4,4)
(-4,7)(-3,10)(-1,14) (-64,-64)。

表4 甲骨文描述示例
4 甲骨文字形的描述
根据第3节所描述的方法,我们设计了甲骨文字形描述和编辑实验平台,在我们已经完成的字形库的设计基础上,利用该平台,我们整理出了5 917个甲骨文字形的描述库,如图2,3所示。
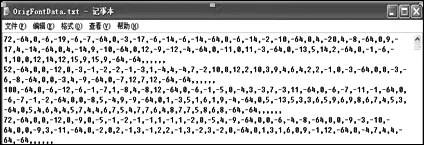
图2 甲骨文字对应的描述字符序列

图3 字符序列对应的描述字形库

表5 甲骨文“”字的描述结果

续表
对于已经识别的甲骨文字,在输入时可以使用目前通用的汉字输入方法进行输入,如图4所示在汉字位置输入汉字“每”一个,便可在甲骨文位置出现每个“每”字的三种甲骨文字形。它是由已经建立的现代汉字和描述字形库的映射关系,调用甲骨文字形描述库进行检索而输出的。
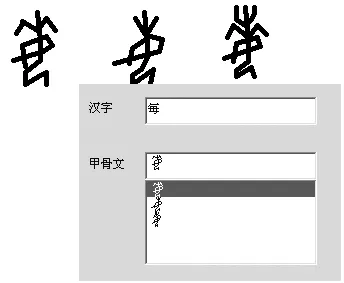
图4 可识甲骨文文字的检索输入
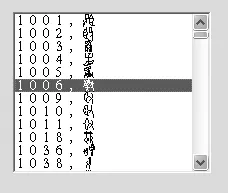
图5 不可识甲骨文列表输入
对没有识别的甲骨文字,可以直接通过描述库中提供的索引号来输入(图5),由于输入和输出操作都是针对字形描述库来进行,任意增加一个字形或修改一个字形都不会改变该原有字形的Unicode编码,因此,保证了同一文字的不同字形的输入编码的稳定性。
5 结论
本论文所提出的甲骨文字形动态描述方法,利用有向笔段和笔元对甲骨文进行动态的描述,为甲骨文中异体字和未识别的甲骨文的输入找到了一个解决方法,解决了因内码空间太少而无法对更多的甲骨文字进行编码和输入问题。同时,由于描述字形的是文本字符并且是有次序的阵列,因此更方便了机器识别。本课题的下一个目标是建立这些有序字符序列的机器识别模型,实现甲骨文的手写和扫描识别。
[1] 胡金柱,肖明.关于甲骨文象形码输入法的编码原理研究[J]. 计算机科学,2002,29(8):109-111.
[2] 刘永革,栗青生.可视化甲骨文输入法的设计与实现[J]. 计算机工程与应用, 2004, 40(17): 139-140.
[3] 栗青生,杨玉星.甲骨文识别的图同构方法[J]. 计算机工程与应用, 2011,47(11):45-48.
[4] 林民,宋柔.一种笔段网格汉字字形描述方法[J]. 计算机研究与发展,2010,(2): 318-327.
[5] 刘志基. 读《新编甲骨文字形总表》兼论甲骨文字形检索系统的完善[J]. 辞书研究, 2006,(2)-013.
[6] 肖明,赵慧,等.甲骨文象形码编码方法研究[J]. 中文信息学报,2003,17(5):60-65.
[7] 沈建华,曹锦炎.新编甲骨文字形总表[M].香港中文大学出版社,2001.
[8] 江铭虎,邓北星,等,甲骨文字库与智能知识库的建立[J]. 计算机工程与应用,2004(4):5-47.
[9] 顾绍通.甲骨文数字化处理研究进展[J]. 广西民族大学学报(自然科学版),2008,(2):80-82.
[10] 沈娟,马小虎.甲骨文的曲线轮廓字形自动生成系统[J], 计算机应用与软件,2009,01-024.
[11] 顾邵通,马小虎,杨亦鸣.基于字形拓扑结构的甲骨文输入编码研究[J].中文信息学报,2008,22(4):123-128.
[12] 陈婷珠,李新城.《新编甲骨文字形总表》中的异部误增[J].汉字文化,2010(2):65-68.
[13] 聂艳召,刘永革.甲骨文自由笔画输入法[J].中文信息学报,2010,24(6):103-107.
