商品品牌名称挖掘
2012-07-09何正焱王厚峰
何正焱,王厚峰
(北京大学 计算语言学教育部重点实验室,北京 100871)
1 引言
词汇的获取是语言学研究的一个重要内容。传统的词典通常需要大量的人力编撰,同时具有覆盖面小,实时性不强等缺点,不能为一些任务如命名实体识别提供足够有效的信息。
在中文命名体识别中, 对识别人名、地名和机构名的研究较为深入。使用的方法主要有基于规则的命名体识别和基于序列标注的命名实体识别[1]。
商品和品牌名称的识别较人名、地名的识别较难。人名有一定的规律可循,且用字比较固定;地名相对变化不大。品牌名称的取名较随意,规律性不强,并且有很多来自外文译名,识别相对困难。
虽然命名实体在用字和上下文有一定规律,但命名实体识别通常是一个严重依赖人类知识的领域,在地名识别中经常用做特征的地名词典(gazetteer)[2],机构名词典便是人类知识的体现。因此挖掘和收集同类别实例,例如,地名、机构名和商品品牌名称对该类别命名体识别有很大作用。本文考虑从网络资源中收集和挖掘大量的同一类别的实体名称,为中文命名实体识别提供足够的领域信息。
近年来,利用网络信息获取大量同类别实例逐渐成为一个研究的热点。如文献[3]使用分布相似性抽取Web表格中的分类实例;文献[4-5]介绍了使用基于二次优化的半指导的 Adsorption 算法综合多个信息源抽取类别实例的方法。这类方法的优点是只利用少量需人工标记的种子节点,利用网页文本的表格或共享属性等信息,获取大量同类别实例,既解决了人工标注的时间代价和覆盖率小的问题,而又不损失准确率。
百度百科是一个较大的中文知识库,包含了大量的人物、地理、历史、机构、商业知识,为新词条的发现提供了大量可供发觉的知识源。我们利用百度百科固有的“开放分类”和“相关词条”信息构造词条间的相似度,使用少量的种子词条,通过半指导的方法扩充同一类别的词条。同样的方法可以用来获取地名、机构名、人名,或获取更细致的分类下的词条;本文选取商品品牌名称作为抽取和评价的对象。
2 相关工作
在一个链接丰富的图结构上定义相似度是一个被深入研究的领域[6]。图上相似度度量的方法主要有基于图的如 personalize pagerank, 其基本思想是将pagerank中某个节点的重启概率设置为1, 静态分布后的排序就是其他节点对该节点的相似度。hitting time[7]定义为从节点i随机游走在重新回到i之前到达j的期望步数,两个节点越相似,期望步数越小。Katz 得分[8]定义为节点i到节点j的长度为k的路径数的加权平均,加权系数随距离增加指数下降,当大多数权重集中在短路径上时,katz得分类似于common neighbors。公共邻节点(common neighbors)定义为两个节点共有的邻节点数, Adamic/Adar 得分[9]定义为公共邻节点的加权和,每个公共邻节点的权值是其度的对数值的倒数,其本质是对公共邻节点的改进。
在异质的图网络中,文献[10]在文章—作者的异构图网络中,利用作者间共同创作,文章间相互引用和作者和文章的写作关系,耦合两个pagerank的随机游走过程,同时对作者和文章排序。文献[11]提出了一种在任意异构图网络上计算相似度的框架,节点间的边含有类型和权值,权值可以通过在训练数据上的错误反向传播学习,相似度的计算结合了随机游走和重新排序(reranking)、随机游走历史(walk history)等信息,实际上相当于在不同类型的边上增加权重。
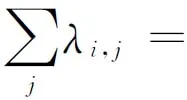
标记传播(label propagation)[13]是一种基于图的半监督的机器学习方法,相对于完全监督的学习算法,在较少训练数据的情况下具有较好的性能。标记传播中关键在于定义好转移矩阵T,其中
wij是ij的相似度,l和u为带标和不带标节点的个数,Tij可以理解为j传递给i的相似度的难易程度。
3 品牌名称抽取
3.1 数据整理
我们从百度百科收集了约 130 万个词条,从每个词条中提取出标题、别名(同义词跳转等)、开放分类、相关词条。开放分类不同于维基百科的层次分类,倾向于扁平结构的标签(tag),命名较随意。因此虽然比较方便,却不够规范。例如,一个词条可以是被标记为分类“中国地理”,另一个词条被标记为“地理”,虽然他们在概念上很接近,分类标记却不能匹配。这就造成了分类上的数据稀疏问题。
3.2 相似度表示
在本文中我们考虑两类信息“开放分类”(tag)和“相关词条”,而不考虑文档内容、文档结构、文档内链接、文档主题、作者协作编辑等信息。“相关词条”可以看作是类型相同的词条,具有相同“开放分类”的词条也视作相同类型的词条。130万词条中有约125万包含至少一个开放分类,约29万个包含至少一个相关词条。
相关词条间的等价关系相对准确,例如,“北京大学”的相关词条包含科研院所和高校,基本属于同类实体;“舒肤佳”的相关词条包含洗化用品品牌;但是这类信息相对较少。
“开放分类”信息较丰富,大多数的词条都包含开放分类信息,但是开放分类信息通常具有用词随意的特点,并且百度百科的分类体系不像 wikipedia 具有层次结构,而是类似于任意给定的标签。另一个现象是标记省略[14],例如,“张朝阳”的开放分类有“画家,教师,企业家”,却没有“人物”。因此需要处理分类(tag)之间的相似关系。
本文提出了类似 simfusion 中的相似度表示,结合上述两种信息,在给定少量种子的情况下,通过半指导的算法进行品牌名称的挖掘。
为了表述方便,定义一个词条i的相关词条的集合为R(i),开放分类的集合为C(i);如果词条j∈R(i),j是i的邻节点。N(i)定义为邻节点的集合。
两个词条节点的相似度定义为它们公共邻节点的个数,
Le(i,j)=|N(i)∩N(j)|
词条和分类之间的关系定义为词条包含分类标签,
Lee(i,j)=1 ifj∈C(i)
分类与分类的相似度定义为它们在相同词条中共现的次数,实际是分类节点之间的公共词条节点个数。考虑到分类之间是具有层次结构和包含关系的,因此分类的相似度传播不是对称的。例如,P(人物|企业家)P(企业家|人物),由于“企业家”一定是“人物”,而“人物”未必是“企业家”,因此前者的概率要大于后者。
设同质节点和异质节点间相对重要性为α,总的相似度矩阵定义为:
3.3 基于图的半指导学习算法
本文使用基于图的半指导学习算法,标记传播(label propagation)[13]。其具体步骤如下:
1. 传递标记,Y←TY;
2. 对行归一化,∀
3. 重置种子节点的概率分布Y。
T 为相似度矩阵,对列做归一化,T(i,j)=P(j→i)可以理解为j传递标记给i的难易程度。l、u分别为带标数据和不带标数据的个数,C 为类别个数,Y(l+u)*C是所有数据在类别上的概率分布。
在这里我们设T=L,如果不考虑节点的类别,实际上相当于将所有带标节点的标记不断传递给不带标数据,最后按照概率由高到低排序,获得与种子(认为是品牌的词条)的类别接近的词条或分类。
3.4 种子词条
我们手工设计了几十个不同领域的品牌名称(见表1),包含日化、服装、汽车、电子、家电、餐饮、化妆品、食品等领域。由于品牌名称的定义广泛,可能包含几十种不同领域。每种领域内部链接通常丰富,分类较一致;类别之间链接相对较少,分类也相对分散。因此每个领域我们选择几个具有代表性的词条作为种子节点。

表1 品牌名称的种子节点
4 实验与分析
4.1 实验设计和评价
我们从百度百科中收集了130万个词条进行实验。由于实验的数据量很大,矩阵运算我们使用 scipy*http://www.scipy.org的稀疏矩阵。我们过滤掉了不包含相关词条和开放分类的词条,过滤掉频率小于5的开放分类。利用 L 作为相似度矩阵,经过标记传播算法迭代 1 000次,此时矩阵Y 每个元素的平均迭代误差小于10-4,可以认为基本收敛。
由于标记传播结果的概率分布 Y 表明了某个词条和种子词条的相似性,我们将120万个词条按概率由高到低排列,得到词条列表。概率越大,排序越高,越可能是一个商品品牌名称。
由于收集的词条数目太多,我们还专门从 globrand*http://www.globrand.com/brandlisttxt/搜集了756个品牌名称,其中 667 个在我们搜集的百科词条中或别名中存在。我们利用这667个词条在所有120万个词条中的 rank 值相加,相当于在所有正例中采样出 667 个样本点,以采样的 rank 均值作为所有正例的期望 rank 值。如果 rank 值越小,表明排名越靠前,模型效果越好。
定义 rank(e) 为词条 e 在所有 120 万个词条中的排序值,表2 列出了不同α下 667 个样本词条的排序和。

表2 不同α下667个词条的排序和
从表2可以看出,当α→1时,逐渐忽略分类对词条的影响,相当于只考虑词条间的相似性,而不考虑类别对词条的影响,效果逐渐变差,这表明整合两种信息能够提高品牌名的 rank 值,产生更好的效果。
4.2 实验结果分析
我们人工检查了排序较高的非品牌词条。我们将其分为几类,见表3。某些是由于包含的信息太少,而唯一包含的信息又与正例很相关,例如,“板砖”,“掏耳勺”仅仅包含一个分类“日常”,而“日常”与很多洗化品牌相关;“苦事”的唯一一个相关词条“乐事”是品牌;另一些如“HR”、“名表”等虽然有多个分类和相关词条,但是仅有少数和品牌相关,即存在不一致性和多义性。如何建模这两种情况是我们将要考虑的方向。
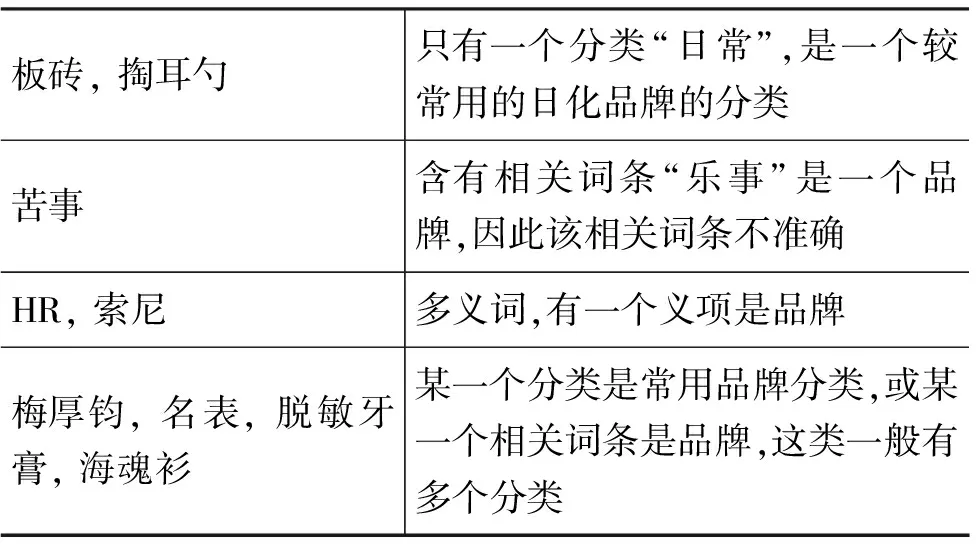
表3 排序较高的非品牌词条

表4 排序较低的品牌名称。
在667个样本中,前450个排序都在10 000以内。对667个品牌名称 rank 值较低的样例(表4)进行分析,我们可以发现多数存在歧义和多义词现象,因此这类词条只在特定上下文下才是品牌名称(例如,白云山, 见表4)。另外一些词条的“开放分类”或“相关词条”提供的信息太少,或使用了很少使用的分类名称;如何整合更多的文档结构和内容信息是另一个将要研究的方向。
5 结论
我们提出了一种基于图的半监督学习算法,从大量百科知识库中抽取品牌名称。结合百度百科的相关词条和开放分类两种链接关系,定义了结合两种关系的相似度表示方法,给定少量品牌领域的种子样例,挖掘出更多的品牌名称。实验中我们仅利用“开放分类”和“相关词条”两类信息,而没有利用诸如文档内容、文档结构、文档内链接、文档主题、作者协作编辑等信息,取得了较好地效果。使用我们的方法,可以在指定任意领域(如机构名作为种子)的少量实例的情况下,获取更多的该领域相关的概念。抽取出的词表可以用在命名实体识别领域。
下一步,我们将进一步利用和融合更多信息(如文档内容、文档内链接、文档模板结构等),并提出更合理和可行的评价方法。
[1] 周俊生,戴新宇,尹存燕,等. 基于层叠条件随机场模型的中文机构名自动识别[J]. 电子学报, 2006: 34(5):804-809.
[2] David Nadeau, Satoshi Sekine. A survey of named entity recognition and classification[J].Lingvisticae Investigationes, 2007.
[3] Van Durme, B., Pas ca, M.. Finding cars, goddesses and enzymes: Parametrizable acquisition of labeled instances for open-domain information extraction[C]//Proceedings Twenty-Third AAAI Conference on Artificial Intelligence.2008.
[4] Talukdar P. P., Reisinger J., Pasca,M., et al. Weakly-Supervised Acquisition of Labeled Class Instances using Graph Random Walks[C]//Proceedings of the 2008 Conference on Empirical Methods in Natural Language Processing, 2008, 581-589.
[5] Talukdar P. P., Pereira, F. Experiments in graph-based semi-supervised learning methods for class-instance acquisition[C]//Proceedings of 48th Annual Meeting of the Association for Computational Linguistics (ACL).2010.
[6] Purnamrita Sarkar. Tractable Algorithms for Proximity Search on Large Graphs[D]. PhD thesis, Carnegie Mellon University, 2010.
[7] D. Aldous, J. Fill. Reversible Markov Chains and Random Walks on Graphs[M]. Book in preparation.
[8] Leo Katz. A new status index derived from sociometric analysis[C]. Psychometrika, 1953.
[9] Lada A. Adamic, Eytan Adar. Friends and neighbors on the web[J]. Social Networks, 2003.
[10] Ding Zhou, Sergey A. Orshanskiy, Hongyuan Zha, and C. Lee Giles. Co-ranking authors and documents in a heterogeneous network[C]//Data Mining, IEEE International Conference on, 2007:739-744.
[11] Einat Minkov. Adaptive Graph Walk Based Similarity Measures in Entity-Relation Graphs[D].PhD thesis, Carnegie Mellon University, 2008.
[12] Wensi Xi, Edward A. Fox, Weiguo Fan, et al.. Simfusion: measuring similarity using unified relationship matrix[C]//Proceedings of the 28th annual international ACM SIGIR conference on Research and development in information retrieval, SIGIR ’05, New York, NY, USA, 2005: 130-137.
[13] Xiaojin Zhu, Zoubin Ghahramani. Learning from labeled and unlabeled data with label Propagation[R]. Technical report, 2002.
[14] Xiance Si, Zhiyuan Liu, Maosong Sun. Explore the structure of social tags by sub-sumption relations[C]//Proceedings of the 23rd International Conference on Computational Linguistics (Coling 2010), Beijing, China, August 2010:1011-1019.
