数据挖掘技术在井斜控制中的应用
2012-07-02邱振东石永泉
邱振东,石永泉,任 远
(成都理工大学环境与土木工程学院,成都610059)
1 井斜控制
钻井工程中,按照设计井眼轨道的不同,井可分为2类:直井和定向井[1]。其中直井的轨迹为铅垂线,看似简单,但我们从钻井历史中发现,在钻井工程中直井的井眼轨迹控制难度往往比定向井的轨迹控制难度更大。因为地下情况复杂,井斜是不可避免的,关键在于如何将井斜角和井眼曲率控制在可接受的范围之内,井斜一旦超出此范围会造成很大的损失和危害,必要时需要填井纠斜。
在实际钻进过程中,引起井斜的因素是复杂多样的。大致可以分为3类:地质因素、技术因素和工艺因素。其中,地质因素是客观存在的,其对井斜的影响有很强的规律性。所以,我们一般将地质因素视为客观因素,而技术因素和工艺因素对井斜的影响会因操作严格程度或大或小,具有一定的可控性和偶然性。因此,技术因素和工艺因素为主观因素[2]。
目前,虽然国外出现了数种专用新型主动防斜打直工具,如:hcy装置、VDC系统和SDD直井钻井系统等,但这些效果优秀的专用工具成本较高,很难在钻井工程中普遍采用。因此,目前的钻井工程中大部分采用被动防斜,主动纠斜的方法进行直井钻进。最常用的有钟摆钻具和满眼刚性钻具,其中,钟摆钻具因不可使用大钻压而大大降低钻进效率,满眼刚性钻具只能用于防斜与稳斜。而且这2种防斜技术效果并不可靠,所以在钻井施工中须多次测斜,以保证井斜在控制范围之内,这样增大了钻井周期,降低了钻井效益[3]。以上2种被称为传统防斜打直技术,此外还有一种动力学防斜打直技术。其通过大钻压使底部钻具组合处于涡动状态来保持井眼垂直并获得了较快的钻进速度。采用此技术时,底部力学状态复杂,可控性差,而且钻压值的选取目前还没有成熟理论支持。此外还会产生钻头和钻具因疲劳损伤而加速失效的问题。
本文提出应用数据挖掘技术分析已有钻井数据,发现钻井施工中主要的致斜因素,进而为同一区域接下来的钻井工程提出有针对性的调整建议。
2 数据挖掘介绍
数据挖掘是从大量的、不完全的、有噪声的、模糊的、随机的实际数据中提取隐含在其中的、不为人们所知的、但又有潜在应用价值的信息和知识的过程[4]。
现代社会是一个信息社会,在我们周围存在着海量的数据,并且正在爆炸性增长中。在这些数据中蕴涵着无数宝贵的信息和知识,但目前对这些数据的利用率很低。因此,我们处在一个数据丰富,信息贫乏的境地。借助数据挖掘我们完全有能力从浩瀚的数据海洋中,发现有价值的信息和知识,为商业事物、知识库、科学界作出了巨大贡献。数据挖掘是一门多学科交叉的领域,它涉及数据库技术、统计技术、机器学习、人工智能等。数据挖掘技术已被广泛地应用于各个领域,如天文学用来帮助天文学家发现遥远的类星体,生物学研究中用数据挖掘技术对DNA进行分析,利用数据挖掘技术识别顾客的购买行为模式,对客户进行分析等等。
数据挖掘的任务一般可以分为2类:描述和预测。它的功能以及它们可以发现的模式类型有:概念/类描述,挖掘频繁模式、关联和相关,分类和预测,聚类分析,离群点分析和演变分析。目前,数据挖掘工具的种类很多,根据其适用范围主要分为2类:专用数据挖掘工具和通用数据挖掘工具。
专用数据挖掘工具是针对某特定领域而开发,在涉及算法的时候充分考虑了数据、需求的特殊性,并且进行优化。主要软件包有:KD1(针对零售业),Options&Choices(针对保险业),HNC(针对信用卡欺诈或呆账检测)和Unica Model 1(针对营销业)。而通用数据挖掘工具不区分具体数据的含义,采用通用的挖掘算法,处理常见的数据类型。通用数据挖掘工具可以做多种模式的挖掘,挖掘什么、用什么来挖掘都由用户根据自己的应用来选择。通用数据挖掘工具主要有:SQL2005(及更高版本),SAS Enterprise Miner,IBM Intelligent Miner,SPSS Clementine等[5]。
3 应用实例
本文实例中的钻井为地热井,终孔孔深为1 680m。钻进至275.85m时井斜严重超过容许范围,回填至117.88m重新钻进。在后来的钻进过程中曾多次使用钟摆钻具组合进行降斜。因此,通过数据挖掘技术分析钻井数据,从繁杂的数据中发现各参数中哪些对井斜影响较大。
数据挖掘的完整步骤为:(1)理解数据和数据的来源;(2)获取相关知识和技术;(3)整合与检查数据;(4)去除错误或不一致的数据;(5)建立模型和假设;(6)实际数据挖掘工作;(7)测试和验证挖掘结果;(8)解释和应用。事实上,许多专家都认为整套数据挖掘的过程中,数据预处理阶段占整个数据挖掘工作的60%~90%。因此,数据预处理是否合理直接影响挖掘成果的好坏。
3.1 数据预处理
表1为某钻井部分原始数据。从表中可以看出该井的原始数据是根据班报表录入的,有些变量,比如“钻具”、“泵量”等为描述型数据。此外,还存在许多缺失值。数据挖掘软件无法直接对这些数据进行分析计算。因此,首先要对原始数据进行预处理。

表1 某井的原始数据
数据有2种类型:连续型数据和离散型数据(定性数据)。Excel数据挖掘软件在准备数据时会自动或根据用户设置将连续型数据离散化,并在表格中加入新的数据列,如图1中“交班孔深(离散)”、“单位钻压(离散)”、“顶角变化率(离散)”所示。预处理后的数据格式如图1所示。表中“顶角变化率”在取值时假定2个测井点之间顶角为均匀变化。此井的顶角变化率K 为-0.73~2.1°/10m,离散化后为:降斜段(K≤0.1°/10m),稳斜段(K∈-0.09-0.09°/10m);轻微增斜段(K∈0.1-0.19°/10m);严重增斜段(K≥0.2°/10m)。
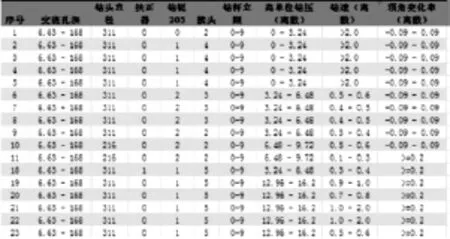
图1 预处理后的部分数据
3.2 数据挖掘及计算结果分析
Excel数据挖掘组件提供了多种算法:决策树、贝叶斯概率分类、关联规则、聚类分析、时序聚类、线性回归、Logistic回归、类神经网络和时间序列分析。经多次试验,本文最终采用贝叶斯概率分类算法(bayes classifier)。贝叶斯分类是一种简单实用的分类方法。简单贝叶斯分类是根据贝叶斯定理,交换先验概率和后验概率,在分类属性相互独立的假设下预测分类的情形[5]。其公式如下:
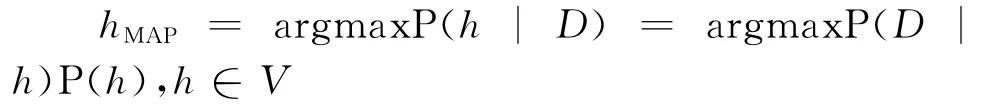
式中:hMAP——最大可能的假说;
D——训练样本;
V——假设空间;
对此,海口市食品药品监督管理局工作人员表示,竹签虽然可以反复使用,但发黑、发霉的竹签是不可以使用的。“具体情况还需检查后才能定论。”工作人员表示。
P(D|h)——训练样本的事前概率,对于假说h而言,为一常数;
P(h)——假说h事前概率(尚未观察训练样本时的概率);
P(h|D)——在训练样本D集合下,假说h出现的条件概率。
因为挖掘目的为预测引起井斜的关键因素,因此将顶角变化率设为“仅预测”其他变量设定为“输入”。在计算分析中的输入变量均为离散化后的数据。如图2所示。

图2 计算变量用法设置
通过贝叶斯概率分类分析,图3为钻井数据中各变量对井斜影响的具体情况。图中增斜指数越高表示改变量处于特定状态时对井斜的加剧作用越大。
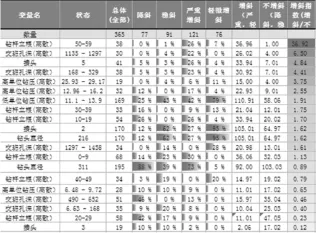
图3 计算结果
从图3中可知,钻杆立跟数量为50~59根;交班孔深为1 135~1 297m;接头数量为5及高单位钻压处在25.93~29.17kg/mm等均为增斜较严重的因素。结合专业知识分析,钻杆立跟数量与交班孔深有很强的相关性,“钻杆立跟数量为50~59根”与“交班孔深为1 135~1 297m”出现在同一井段。因此,可推断此井段主要致斜因素为地层原因。此外还有钻压和接头数量对井斜变化有较大影响。较高的钻压会加剧井斜,接头数量为5和2时增斜,而为3时减斜。接头数量不同代表所用的钻具组合也不同,因此可根据计算结果调整钻具组合。
4 结语
由上述应用实例可看出,数据挖掘可以从大量的复杂的钻井数据中分析出引起井斜的原因,并具有较高的可信度,但是还存在一些问题。
在接下来的研究中还需要解决的问题有:(1)钻井数据记录格式;(2)数据挖掘过程中考虑参数的选择,参数太少,模型简单,但精度差,因素多,可能会产生信息冗余,增大分析难度,模型建立复杂;(3)探索其他算法在本领域的应用;(4)建立适用性强的挖掘系统等等。
总之,数据挖掘技术的应用能够为钻井工作者提供较客观的决策支持,为井斜控制技术提供了新的发展方向和思路。
[1]王建学.钻井工程[M].北京:石油工业出版社,2008:45-46.
[2]李世忠.钻探工艺学(上册)[M].北京:地质出版社,2008:170-174.
[3]常领.动力学防斜打直理论研究及实践应用[J].西部探矿工程,2007(10):75-76.
[4]Jiawei Han,Micheline Kamber.数据挖掘:概念与技术[M].范明,孟小峰译.北京:机械工业出版社,2007:56-58.
[5]谢邦昌.Excel 2007数据挖掘完全手册[M].北京:清华大学出版社,2008:11-13.
