基于SQL-Like语言的分布式推荐系统*
2012-07-01薛羽李炜沈奇威
薛羽, 李炜, 沈奇威
(1 北京邮电大学网络与交换技术国家重点实验室, 北京 100876;2 东信北邮信息技术有限公司, 北京 100191)
基于SQL-Like语言的分布式推荐系统*
薛羽1,2, 李炜1,2, 沈奇威1,2
(1 北京邮电大学网络与交换技术国家重点实验室, 北京 100876;2 东信北邮信息技术有限公司, 北京 100191)
Hadoop应用的开发要求用户掌握分布式编程的相关知识,造成了一定的开销,Apache Pig则提供了一种轻量级的开发方式,用户通过编写类SQL(Structured Query Language)语句,即可调用Hadoop的分布式处理能力。本文将结合Apache Pig和Item-Based协同过滤算法,设计并实现一种轻量级、可维护性较高的分布式推荐系统。
推荐系统;分布式;Hadoop;SQL;协同过滤
随着互联网行业的迅猛发展,出现了信息过载的现象,用户很难从海量信息中找到其感兴趣的内容。推荐系统很好地解决了这一问题,它通过对用户的历史行为进行分析,得出用户行为习惯,并根据这种习惯产生推荐结果,达到信息过滤的目的。然而,用户的历史行为记录往往都是海量数据,对存储和计算环境有着较高的要求。Hadoop是一个开源的分布式计算平台,适用于大数据处理,它主要包括Hadoop分布式文件系统(HDFS, Hadoop Distributed File System)和分布式计算框架MapReduce。Hadoop应用的开发要求用户掌握分布式编程的相关知识,造成了一定的开销,Apache Pig则提供了一种轻量级的开发方式,用户通过编写类SQL语句,即可调用Hadoop的分布式处理能力。本文将结合Apache Pig和Item-Based协同过滤算法,设计并实现一种轻量级、可维护性较高的分布式推荐系统[1,2]。
1 推荐系统设计
1.1 功能模块划分
根据推荐系统的一般处理流程[3],将推荐系统分为6个功能模块,如图1所示,本文将重点介绍推荐引擎部分的实现过程。
(1) 数据采集:从多种数据源获取用户记录,存储在HDFS中;
(2) 数据清洗:对原始数据做初步统计,过滤不符合规定格式的记录;
(3) 数据准备:处理数据,使其符合推荐引擎输入数据的格式要求;
(4) 推荐引擎:根据用户历史记录,利用推荐算法,产生推荐结果;
(5) 结果展示:将推荐结果展示给用户,包括Web、报表等多种形式;
(6) 反馈修复:根据用户对推荐结果的反馈情况,修改相关推荐参数。
1.2 相关定义说明
设用户集合为U,物品集合为B:
(1) “用户-物品”矩阵:矩阵中的每个元素表示用户对物品的偏好值pref,如果pref=0,表示不存在相应的(uid, bid,pref)记录。
(4) 物品间相似度矩阵:矩阵中的每个元素表示两个物品间的相似程度sim,值越大,表示这两个物品被多个用户同时喜欢的程度越高。
Pig中的数据被抽象为一张张的关系表,后文中统一用phase:(uid, bid, pref)表示,关系表中列的类型也可以为一张关系表,如:(uid,{(bid, pref)})[2]。

图1 模块划分
2 偏好值的标准化处理
用户对物品的偏好值往往都带有一定的用户特征。比如,有的用户对物品的打分整体偏高,而有的用户却恰好相反,所给出的分数都分布在一个低分区间,用户之间的这种特征差异会影响后续物品之间相似度计算的准确性。偏好值的标准化处理屏蔽了这种差异,具体处理步骤如下(如图2和图3所示):

图2 偏好值标准化-运算步骤
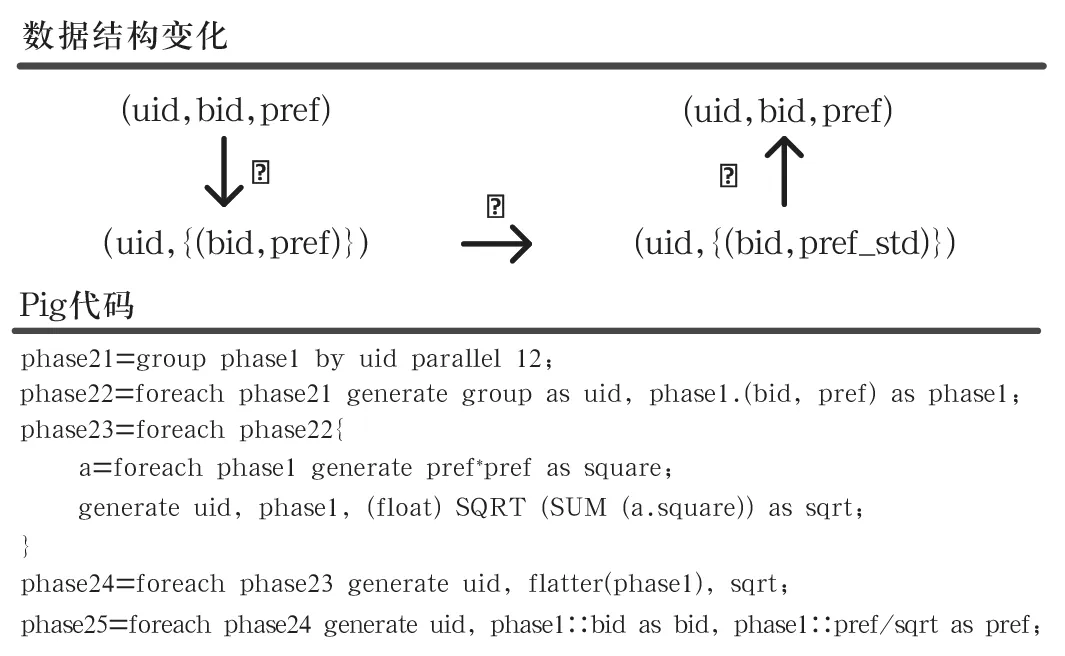
图3 偏好值标准化-数据结构变化及Pig代码
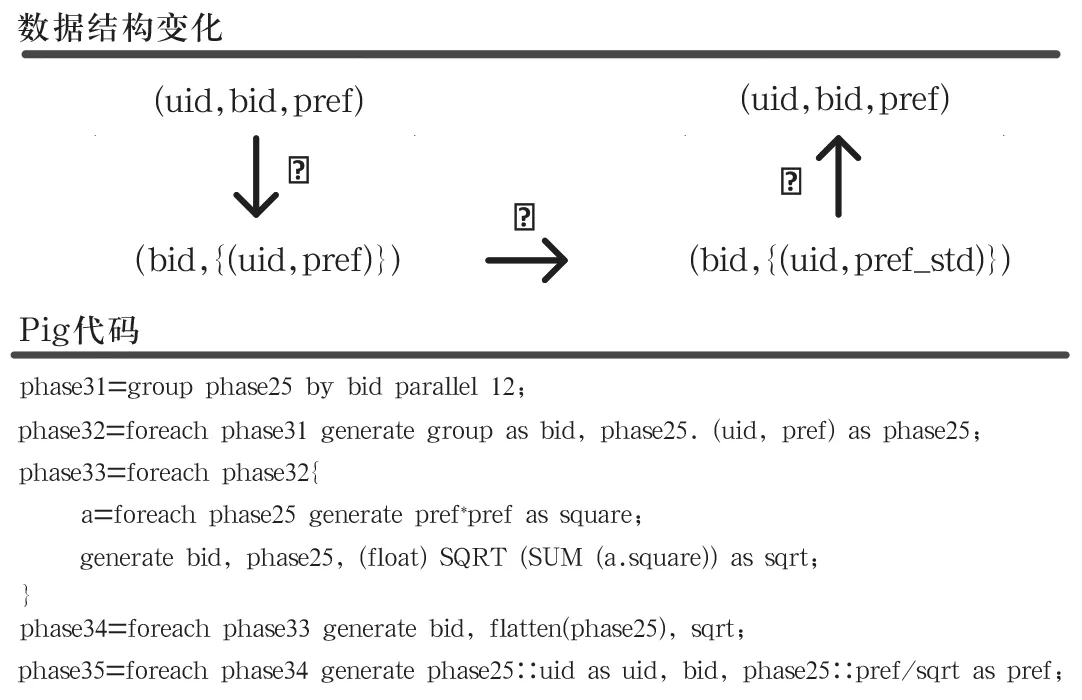
图4 计算相似度矩阵-分母处理
(1) 从“用户-物品”关系矩阵中获取用户特征向量。
(2) Pig使用group by语句实现了这一步骤(phase21),将分散存储在集群中不同节点上的具有相同uid的用户记录汇聚到同一个节点(聚合结点);parallel指定了聚合结点的个数;
(4) 恢复“用户-物品”关系矩阵。flatten语句可以将已经聚合的数据展开,相当于group by的逆操作(phase24)。phase22的作用是保证上下文列名的一致性,后面的步骤中还会出现相同类型的语句,将不再进行解释。
3 计算物品间相似度矩阵
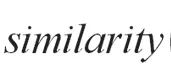
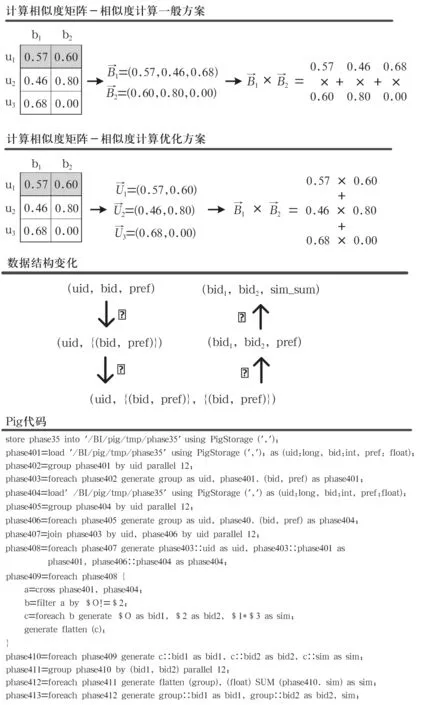
图5 计算相似度矩阵-相似度计算
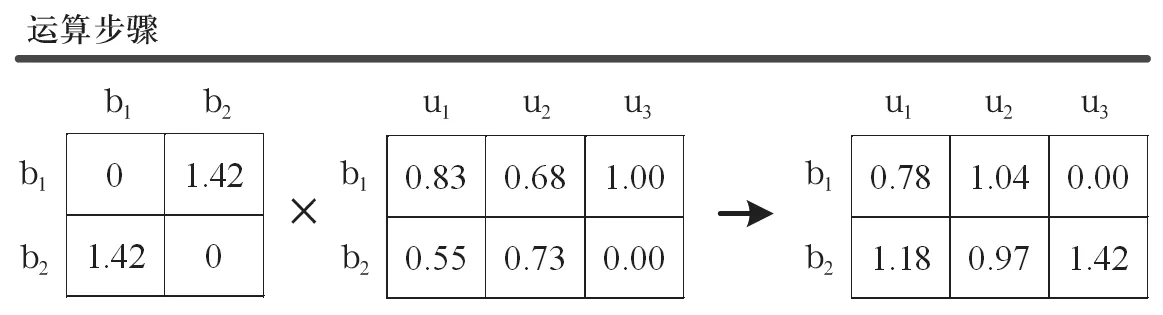
图6 生成推荐结果-运算步骤
3.1 分母处理
3.2 相似度计算
(2) 将分散在各个结点上的(bid1, bid2, sim)按照(bid1, bid2)进行聚合(phase411, phase412),并在各个聚合节点上计算相同(bid1, bid2)组合的sim和。
可见,通过简单的公式变换,整个相似度计算过程充分利用了分布式计环境的性能。
4 生成推荐结果

图7 生成推荐结果-数据结构变化及Pig代码
将物品间相似度矩阵乘以“用户-物品”矩阵,即可得到用户对物品的推荐偏好值(预测用户对某个物品的喜好程度),具体处理步骤如下(如图6和图7所示):
(1) 将分散存储的矩阵元素(bid1, bid2, sim)按照bid1进行聚合(phase501);
(2) 将用户偏好记录中的偏好值pref乘以记录中所指定的物品bidi与其他物品之间的相似度,这个过程分散在用户偏好记录所在的结点执行(phase503~phase507);
(3) 将(uid, bid)相同的记录的pref* sim值进行加权(phase508~phase509);
(4) 过滤推荐结果中用户已打过分的物品(phase511~phase513),cogroup by根据指定的主键对多个关系表进行聚合;
(5) 对推荐结果进行降序排列,以及推荐物品个数的限制。order by desc语句表示降序排列,limit的作用为指定输出记录的数量。
5 结论
互联网的飞速发展,将我们带入了信息爆炸时代,用户面对海量信息,往往会眼花缭乱。个性化推荐系统通过分析用户行为,为用户推荐有价值的信息,实现了信息的过滤,很好的解决了上述问题。同时,由于用户行为记录的数据量通常都非常大,这就要求推荐系统具有较高的存储能力和计算能力。
本文设计并实现了一种轻量级的分布式推荐系统,其使用类SQL语言的编程方式,调用底层的Hadoop分布式处理能力,从海量数据中为用户选择其感兴趣的内容,代码量少,开发效率高,具有较好的可维护性。
[1] 许海玲. 互联网推荐系统比较研究[J]. 软件学报, 2009,(2):350-362.
[2] Apache Foundation. Apache Pig[EB/OL]. http://pig.apache.org,2012-07-24.
[3] 项亮. 推荐系统实践[M]. 北京: 人民邮电出版社, 2012.
[4] Sarwar B. et al. Item-based collaborative filtering recommendation algorithms[A]. The 10th International Conference on World Wide Web[C],2001,285-295.
[5] Linden G, Smith B, York J, Amazon. com recommendations: itemto-item collaborative filtering[J]. Internet Computing, IEEE, 2003, (1):76-80.
[6] Ni P. et al. Web information recommendation based on user behaviors[A].Computer Science and Information Engineering, 2009 WRI World Congress on[C], 2009.
[7] Schelter S. Distributed itembased collaborative filtering with apache mahout [EB/OL].http://isabel-drost.de/hadoop/slides/collabMahout. pdf,2010-10-07.
Distributed recommendation system based on SQL-like language
XUE Yu1,2, LI Wei1,2, SHEN Qi-wei1,2
(1 State Key Laboratory of Networking and Switching Technology, Beijing University of Posts and Telecommunications, Beijing 100876, China; 2 EBUPT Information Technology Co., Ltd., Beijing 100191, China)
Hadoop is an open source distributed computing platform, it’s suitable to the large data processing, but we must learning distributed programming skills before developing Hadoop applications. Apache Pig provides a lightweight development way, it allows us to make use of distributed processing capacity of Hadoop by using SQL (Structured Query Language) language. In this paper we will design and implements a lightweight and high maintainability distributed recommendation system through the combination between Apache Pig and item-based collaborative fi ltering algorithm.
recommendation system; distributed; hadoop; SQL; collaborative fi ltering
TN929.5
A
1008-5599(2012)11-0084-05
2012-10-10
国家自然科学基金(No. 61072057,61101119,61121001,61271019,60902051);长江学者和创新团队发展计划资助(No. IRT1049);国家科技重大专项(No. 2011ZX03002-001-01,移动互联网总体架构研究)。
