基于情绪词的非监督中文情感分类方法研究
2012-06-29代大明王中卿李寿山李培峰朱巧明
代大明,王中卿,李寿山,李培峰,朱巧明
(1. 苏州大学 计算机科学与技术学院,江苏 苏州 215006;2. 江苏省计算机信息处理技术重点实验室,江苏 苏州 215006)
1 引言
随着Web 2.0的发展,互联网上相继出现了大量关于观点的评论文本,这迫切需要计算机帮助商业公司或用户自动分析和获取这些文本的情感信息。情感分析(sentiment analysis)即为该背景下出现的一个面向文本情感信息处理的新兴研究方向[1]。
情感分类(sentiment classification)是情感分析研究的一个基本任务,该任务旨在将文本按照情感倾向进行褒贬分类。与传统基于主题的文本分类相比,情感分类被认为更具有挑战性[2]。到目前为止,大多数针对情感分类的研究是基于监督学习的,虽然取得了较好的分类效果,但由于这种方法需要大量标注语料使得构建分类器的时间和经济代价比较大。因此,后续研究出现了一些基于少量标注数据的半监督学习方法,并取得了不错的成绩[3]。
由于情感分类是领域相关(domain-specific)的,在牵涉到多个领域的时候,对所有领域都标注少量数据仍然非常费时费力。在这种情况下,无需标注语料的非监督情感分类方法显得非常实用。本文重点研究基于非监督学习的情感分类方法,提出了一种基于情绪词的非监督情感分类方法。值得指出的是,本文所指的情绪词不同于情感词,情感词一般是指具有情感倾向的评价词语,例如,“漂亮”;而情绪词一般是用于描述个人内心感受的词语,例如,“平静”。这两类词不仅存在一定的联系,也有着明显的区别。例如,有些词即是情感词也是情绪词,例如,“高兴”;但是,有些词仅仅是情绪词,并不带任何感情色彩,例如,“惊讶”。本文的方法首先使用情绪词从未标注数据中抽取高正确率的自动标注数据作为训练样本,然后采用半监督学习方法进行情感分类。该方法主要利用了情绪词的两个特点: (1)情绪词数量少,标注情绪词的情感极性工作量非常有限;(2)情绪词表达的情感极性往往是领域独立的,使用情绪词可以有效地在多个领域抽取样本。实验结果显示,我们提出的方法在不同的两个领域中都取得了较好的分类效果。
本文的结构组织如下,第二节介绍相关工作;第三节给出基于情绪词的非监督情感分类方法;第四节是实验结果与分析;第五节给出总结并对下一步工作进行了展望。
2 相关工作
目前,主流的情感分类研究主要集中在基于机器学习的分类方法上面。基于机器学习的分类方法一般可以分为三种类型: 全监督学习方法[4]、半监督学习方法[4-5]、非监督学习方法[5-6]。此外,为了克服领域间分类性能损失问题,领域适应学习方法在情感分类方法研究中得到了充分的发展[7]。
本文关注于非监督的情感分类方法,由于无需标注语料,非监督情感分类方法一直受到许多研究者的青睐。Turney[6]首次提出基于种子词(excellent,poor)的非监督学习方法,使用“excellent”和“poor”两个种子词与未知词在搜索网页中的互信息来计算未知词的情感极性,并用以计算整个文本的情感极性。后续的非监督情感分类方法大都是基于生成或已有的情感词典或者相关资源进行情感分类。例如,Kennedy 和Inkpen[8]考虑文本中词的极性转移关系并基于种子词集合进行词计数决定情感倾向。朱嫣岚等人[9]将一组已知极性的词语集合作为种子,基于HowNet对未知词语与种子词进行语义计算,从而判别未知词的极性。Zagibalov 和Carroll[10]提出种子词选择方法和种子词的统计方法对中文情感分类。与以上文章不同的是,本文提出的非监督情感分类方法仅使用少量的情绪词(具有很好的领域独立性),而非大规模的情感词典或其他资源。Dasgupta 和Ng[5]也提出了用谱聚类把文本按照情感维度聚类,其中需要人工判别情感维度的极性。Lin et al.[11]采用LSM模型、JST模型、Reverse-JST模型构建了三种无监督的情感分类系统。
3 基于情绪词的非监督情感分类方法
3.1 概述
情绪一般是指人的内心反应与感受,例如,喜、怒、哀、乐等。人们在表达观点、态度时,往往伴随着情绪的表达。因此,可以考虑通过情绪来推测人们对事物的情感倾向。本文设定情感倾向与情绪的关系。当人们表达出对某事物的正面评价,往往会表现出正面的情绪;反之,当人们表达出对某事物的负面评价,往往表现出负面的情绪。
情绪词是指描述情绪的词语,是情绪表现最明显的特征形式。情感词是具有情感倾向的词语。情绪词与情感词间存在差异又存在联系,例如,“漂亮”,它体现出对某事物的正面的情感倾向,认为是情感词,因不是关于人的内心活动的描述,所以不是情绪词;而“平静”描述了人的情绪,但没有体现明显的情感倾向,只是情绪词。“高兴”即表达了人的情绪,同时也具有明显的情感倾向,即正面。所以可认为即是情绪词,也是情感词。情绪词一般是少量的,并且大都领域独立,即其情感倾向一般不随领域的不同而改变。所以本文提出了基于情绪词的情感分类方法。
本文的方法首先使用情绪词从未标注数据中抽取高正确率的自动标注数据作为训练样本,然后采用半监督学习方法进行情感分类。图1给出了本文方法的系统框架图。严格意义上讲,由于不需要任何标注样本, 本文的方法可以认为是一种非监督情感分类方法。
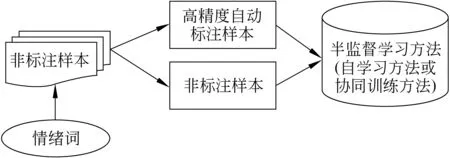
图1 基于情绪词的非监督情感分类方法系统框架图
3.2 情绪词的收集和标注
本文使用的情绪词来源于许小颖等人[12]收集的情绪词集,然后通过人工识别情感倾向,把情绪词划分为正负两类。
为了保证情绪词的质量,我们剔除了以下三种类型的情绪词。(1)没有强烈的情感倾向,例如,“怀疑”;(2)不同语境下存在情感倾向变化,例如,“奇怪”,“紧张”;(3)存在歧义的情绪词,例如,“不快”,“不满”。表1给出剔除前后情绪词的统计情况。
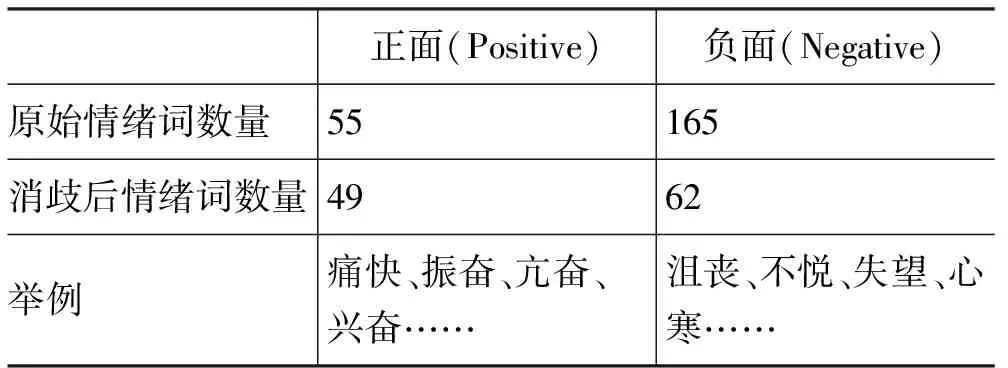
表1 剔除前后情绪词的统计
3.3 获取初始自动标注语料
由于上下文的关系, 情绪词表达的情感不一定同整个文本表达的情感一致。所以通过情绪词直接标注的部分样本可能存在错误。因此,本文采取一些规则帮助抽取高精确度的样本。使用的规则主要针对情感文本中普遍存在的否定现象。例如,
颜色 和 图片 基本 一致 , 做工 也 很 好 。 很 漂亮 , 挺 实用 的, 没 让 我失望。 (产品领域)
一 进 房间 就 有 一 股 霉 味 , 后来 发现 马桶 水箱 出 不 了 水 , 两 次 让 服务员 来 修理 , 还是 不 太放心。 (酒店领域)
本文的规则主要是针对否定现象,具体来讲,规则是当一个情绪词的上下文中出现否定词时,那么它的情感极性将发生反转。考虑的否定词如下: 不、不是、不用、非、否、无、无法、没、没有、没法、没什么、难以、毫无、决不、未、绝不。
3.4 半监督学习方法
由于本文使用的情绪词有限,导致收集到的自动标注数据规模比较小。本文使用收集的样本作为初始样本借助半监督学习方法进一步扩充样本,从而提高系统的分类性能。本文使用了两种半监督学习方法: 自学习(self-training)和协同训练(co-training)方法。
自学习就是先通过已标注的训练数据集训练一个分类器,然后用该分类器标注未标注的数据;并从结果中选择置信度最大的或者符合规定阈值的一部分数据,作为标记数据添加到训练集中,迭代重复这个过程直到未标记数据被添加达到某一条件为止[13]。
协同训练算法[14]使用两个或多个视图(views)分别构建两个或者多个分类器,使用它们对大量未标注的数据标注来增加标注数据集,从中选取置信度最高的部分数据添加到标注集中。该算法执行多次迭代以到达足够的数据集。在本文的方法中,将特征集划分为两个子空间用以构建两个不同的视图,划分方法采用对等随机形式,即以随机的形式把全部特征集合划分为特征数量相等的两个子特征集。由于两个子特征集的特征是完全不相同的,可以认为这样生成的两个视图近似比较独立,比较好的满足Co-training成功的两个基本条件之一: 两个视图要统计独立[14]。下面给出了本文提出的协同训练算法描述。
初始条件:
-特征子集F1,F2
-自动标注训练数据L
-未标注数据U
-添加数据的正面或负面个数P
算法流程:
迭代直到满足结束条件:
1. 使用基于特征集F1的训练集L学习第一个分类器C1,然后使用分类器C1对基于特征集F1的数据集U中的数据标注;
2. 从结果中选取置信度最大的部分数据L′,其包含数量为P的正面评论与数量为P的负面评论;
3. 使用基于特征集F2的训练集L学习第二个分类器C2,然后使用分类器C2对基于特征集F2的数据集U中的数据标注;
4. 从结果中选取置信度最大的部分数据F″,其包含数量为P的正面评论与数量为P的负面评论;
5. 添加L′∪L″到l中,l=l+L′∪L″;
6. 从U中移除L′∪L″,更新U=U-(L′∪L″)。
4 实验设计与分析
4.1 实验设置
实验使用的语料来自两个领域,分别是卓越网关于产品(Product)的中文评论语料和谭松波收集的关于酒店(Hotel)的中文情感评论语料*http://www.searchforum.org.cn/tansongbo/corpus-senti.htm。分别从这两个语料中选取正负评论各1 600篇作为实验的未标注数据,选择正负各400篇作为测试数据。
实验采用的分类算法是基于Mallet4*http://mallet.cs.umass.edu/工具包的最大熵分类方法。在进行分类之前,首先采用中国科学院计算技术研究所的分词软件ICTCLAS*http://ictclas.org/对文本分词,然后选取词的Unigram作为分类特征,并以正确率作为衡量分类性能的标准。
在算法实现中,置信度的大小是通过最大熵分类器提供的分类结果(样本属于每个类别的后验概率的大小)来决定的。整个特征集合以随机的方式被划分为特征数量相等的两个子特征集。
4.2 初始自动标注语料结果
本小结分析和讨论使用情绪词抽取初始样本的实验结果。表2给出否定消歧前后抽取标注样本数量的变化。表3显示了初始自动标注样本的正确率。从这两个表格可以看出, 虽然选取的样本数量在消歧前后并未发生明显变化,但是在正确率上差别明显。消歧后的样本正确率要远远好于消歧前,此结果验证了处理否定的规则的有效性。

表2 消歧前后抽取标注样本数量
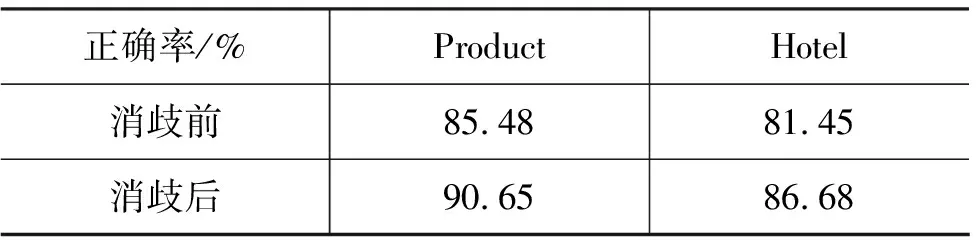
表3 消歧前后抽取的标注样本的正确率
虽然消歧后,样本正确率已经比较高,但是离正确率100%还有一定距离。我们进行了错误分析,发现错误判别的样本主要由以下原因造成。
(1) 评论中既存在正面又存在负面的评价;
例句: 做工 精细 , 手感 优良 , 感觉 也 很 好 现在 用 了 两 个 多 月 了 , 发现 字 会 掉 … …郁闷了 好 一阵子
(2) 情绪词与评价对象无关,即表达的情绪针对的评价对象已发生改变;
例句: 香水 味 很 适合讨厌浓香 男士 。 很 好 我 喜欢
(3) 除了否定现象外,还存在各种其他形式的极性转移现象。
例句: 刚 收到 货 很惊喜, 金色 真的 很 漂亮, 打开 一 看 , 里面 能 装 9 张 卡 , 心里 觉得 还 行 吧 , 可是 当 拿 出 卡 的 时候 , 却 怎么 也 塞 不 进
4.3 分类结果
在实验中,采用自学习(self-training)与协同训练(co-training)的方法。将4.2节中自动标注的数据作为已标注的训练集。我们把每次迭代添加到训练集中的数量设定为2,即P=2。迭代结束条件规定为直到所有的未标注样本加入到训练集中。图2和图3分别显示了Product、Hotel两个领域训练的分类器性能随着迭代次数变化情况。
从图2和图3可以看出使用半监督学习方法加入非标注样本是有效的,分类效果有着明显的提高。在两个领域里,自学习方法平均提高了2.86%,协同训练方法平均提高了5.06%。
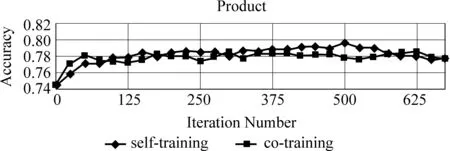
图2 Product领域的情感分类
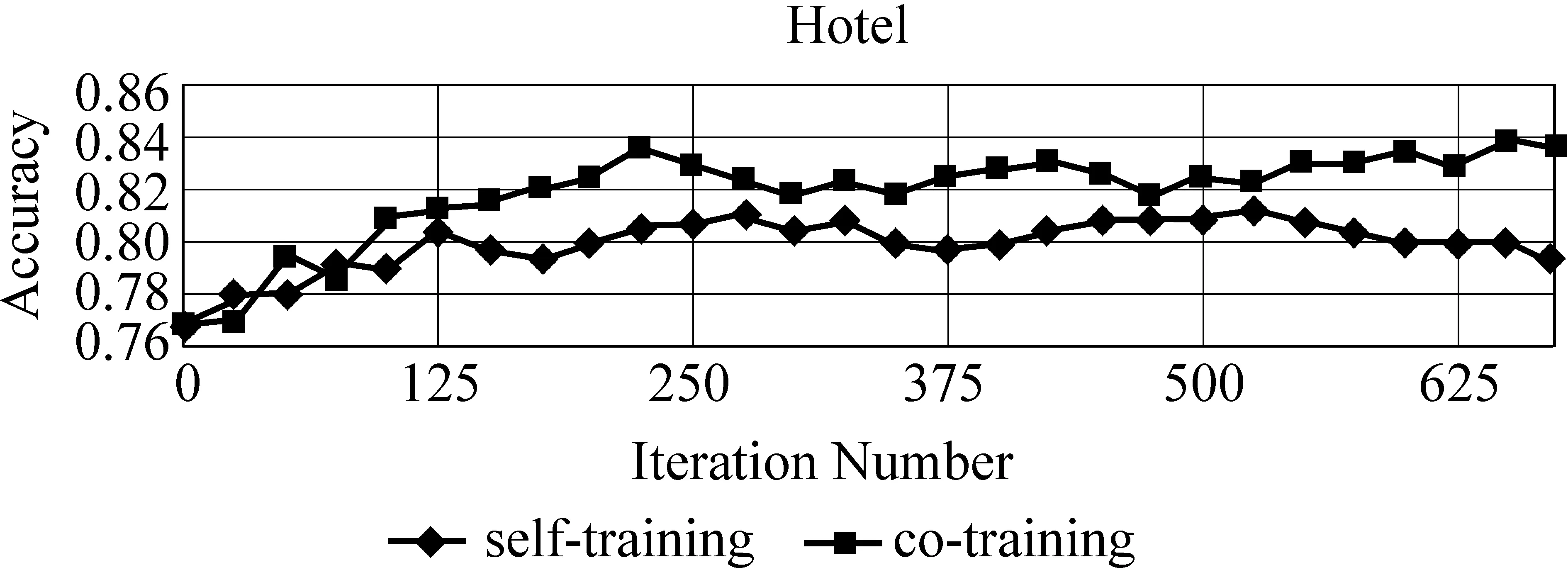
图3 Hotel领域的情感分类结果
除了本文提出的情感分类方法外,我们还实现了两种基准系统。
1)PMI-IR: 采用文献[5]中提到的PMI-IR方法,我们选取“很好”、“很坏”两个种子词;
2)Emotion-TC: 通过文本中的情绪词的情感倾向计算文本的情感倾向,正面的情绪词,权值设定为1,负面的情绪词设定为-1,然后对所有情绪词的权值累加,如果累加结果大于0,则文本的情感极性为正,否则为负;没有情绪词的文本随机赋予情感类别。
表4给出了基准系统与我们方法的分类结果比较。对于PMI-IR,我们使用yahoo搜索引擎(提供了Near查询功能),我们发现虽然该方法在英文情感语料上取得了较好的分类性能,但是在中文语料上分类性能非常不理想。Emotion-TC的分类性能仅仅略微好于随机的水平。产生这种结果的主要原因是测试样本中含有情绪词的样本非常少,导致大多数的文档的情感极性无法判别。我们的方法在Product和Hotel领域分别取得了77.94%和83.75%的分类效果,充分显示了我们方法的有效性。

表4 基准系统与我们的方法在两个领域里的分类性能
5 总结与展望
本文提出一种基于情绪词的非监督情感分类方法。该方法不依赖于任何人工标注的语料数据。首先使用情绪词抽取高正确率的自动标注样本数据,然后将其作为初始“伪”标注样本用于半监督的情感分类。实验结果表明本文的方法在两个领域都获得较好的分类性能,分别达到了77.94%和83.75%。
本文中,在获得高精度的初始样本时,仅仅考虑了否定现象的情感转移。我们希望在下一步工作中,考虑更多的情感转移现象(例如,转折词等)以及情感副词对情感程度的影响,使得获得的初始样本正确率更佳。此外,我们使用的非标注样本规模还不够大,在下一步的工作中,我们将加入更多的非标注样本,使得获得的初始“伪”标注样本规模更大,从而进一步提高分类性能。
[1] 姚天昉,程希文,徐飞玉,等. 文本意见挖掘综述[J]. 中文信息学报,2008,22(3): 71-80.
[2] Pang B.,L. Lee. Opinion Mining and Sentiment Analysis[J]. Foundations and Trends in Information Retrieval, 2008, 2(1-2): 1-135.
[3] 周立柱,贺宇凯,王建勇. 情感分析研究综述[J]. 计算机应用,2008,28(11): 2725-2728.
[4] Li S., Huang C., Zhou G., et al.. Employing Personal/Impersonal Views in Supervised and Semi-supervised Sentiment Classification[C]//Proceedings of Annual Meeting on Association for Computational Linguistics (ACL-10). 2010: 414-423.
[5] Dasgupta S., V. Ng. Mine the Easy and Classify the Hard: Experiments with Automatic Sentiment Classification[C]//Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP (ACL-IJCNLP-09). 2009.
[6] Turney P. Thumbs up or thumbs down? Semantic Orientation Applied to Unsupervised Classification of Reviews[C]//Proceedings of Annual Meeting on Association for Computational Linguistics (ACL-02), 2002.
[7] Blitzer J., Dredze M., F. Pereira. Biographies, Bollywood, Boom-boxes and Blenders: Domain Adaptation for Sentiment Classification[C]//Proceedings of Annual Meeting on Association for Computational Linguistics (ACL-07). 2007: 440-447.
[8] Kennedy A., D. Inkpen. Sentiment Classification of Movie Reviews using Contextual Valence Shifters[C]//Proceedings of Computational Intelligence. Publisher: John Wiley & Sons, 2006: 110-125.
[9] 朱嫣岚,闵锦,周雅倩,等. 基于HowNet的词汇语义倾向计算[J]. 中文信息学报,2006,20(1): 14-20.
[10] Zagibalov T., J. Carroll. Automatic Seed Word Selection for Unsupervised Sentiment Classification of Chinese Test[C]//Proceedings of the 22rd International Conference on Computational Linguistics (COLING-08). 2008.
[11] Lin C., He Y., R. Everson. A Comparative Study of Bayesian Models for Unsupervised Sentiment Detection[C]//Proceeding of Annual Meeting on Association for Computational Linguistics(ACL-10). 2010: 144-152.
[12] 许小颖,陶建华. 汉语情感系统中情感划分的研究[C]//第一届中国情感计算及智能交互学术会议. 2003.
[13] Clark S., Curran J., M. Osborne. Bootstrapping POS Taggers Using Unlabelled Data[C]//Proceedings of the 7th Conference on Natural Language Learning at the Human Language Technologies and North American Association for Computational Linguistics (HLT-NAACL). 2003: 49-55.
[14] Blum A., Mitchell T. Combining Labeled and Unlabeled Data with Co-training[C]//Proceedings of the Workshop on Computational Learning Theory. 1998: 92-100.
[15] Pang B., Lee L., S. Vaithyanathan. Thumbs up? Sentiment Classification using Machine Learning techniques[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP-02). 2002.
[16] Cui H., Mittal V., M. Datar. Comparative Experiments on Sentiment Classification for Online Product Reviews[C]//Proceedings of the 21st National Conference on Artificial Intelligence. Menlo Park: AAAI Press. 2006: 1265-1270.
[17] 唐慧丰,谭松波,程学旗. 基于监督学习的中文情感分类技术比较研究[J]. 中文信息学报,2007,21(6): 88-94.
[18] Wan X. Co-Training for Cross-Lingual Sentiment Classification[C]//Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP (ACL-IJCNLP-09). 2009.
[19] Bollegala D., Weir D., J. Carroll. Using multiple sources to construct a sentiment sensitive thesaurus for cross-domain sentiment classification[C]//Proceedings of Annual Meeting on Association for Computational Linguistics (ACL-11). 2011: 132-141.
