基于语境歧义词的句子情感倾向性分析
2012-06-29宋艳雪张绍武林鸿飞
宋艳雪,张绍武,林鸿飞
(大连理工大学 信息检索研究室,辽宁 大连 116024)
1 引言
目前,在分析文本情感倾向性时,出发点通常是情感词。然而自然语言中的多数词汇本身并不带有明显的感情色彩,在应用到实际文本中时,一些词汇会由于具体的语境或不同的搭配关系表达出褒义或者贬义色彩。本文中的“语境歧义词”是指句子中的一些词汇本身没有明显的情感倾向性,但是当它们与上下文中的某些词语搭配后,产生了明显的情感倾向性。例如,下面的两个句子。
句子1:女儿学习成绩突出,被选为班长,我们很高兴,决定给她买一个芭比娃娃。
句子2:长期用电脑工作,老李得了颈椎突出,郁闷的是现在不能正常工作和生活了。
“突出”本身并不能表达明显的情感倾向性,但是当出现“成绩+突出”和“颈椎+突出”搭配后,“突出”表现出两种不同的情感倾向性,我们把类似“突出”这样的词汇称为语境歧义词。语境歧义词不能单纯地通过添加到情感词典中去分析,需要凭借其所处语境来判断其倾向性。
当前,国内外对词语搭配的研究,主要是从语言学角度出发去挖掘词语搭配效果与认知功能的研究。Igor A.Bolshakov[1]通过统计学方法从语料库中抽取正确搭配,构建一个搭配词典,为搭配领域做出了贡献,该词典还没有考虑情感因素。车万翔、刘挺[2]通过计算语料中出现的词对的“搭配强度系数”值来衡量这种搭配关系的强弱。目前的研究,很少有从情感的角度出发,去挖掘语境歧义词搭配方面的情感倾向性问题。然而,搭配是语言修辞的核心,词语搭配的发现对修辞表达以及从文本中挖掘信息等都有积极的意义,而语境歧义词搭配的发现与提取对文本的情感倾向性分析有深刻意义。目前,带有情感的语境歧义词搭配的研究主要是针对某一领域,例如,Xiaowen Ding[3]在研究数码产品评论倾向性时考虑了语境歧义词,其主要是针对数码产品的属性、功能、外观等。针对语境歧义词给文本的情感分析所带来的问题,我们提出了“基于语境歧义词的句子情感倾向性分析”的方法,旨在为情感倾向性的判断提供基础和依据。
首先采用关联规则方法发现种子词的频繁集,通过PMI过滤机制消除无效关联项,剩余即为搭配词典候选集,对候选集进行情感倾向性判断,由有倾向性项构建成语境歧义词搭配词典。在倾向性分析时,句型分为转折句和非转折句,利用语境歧义词搭配词典,用语义分析方法完成情感倾向性判断。实验结果表明使用搭配词典后,准确率、召回率和F-Score都有一定的提高。
2 理论基础
2.1 关联规则在情感分析中的应用
关联规则是数据中蕴涵的一类重要规律,对关联规则进行挖掘是数据挖掘中的一项根本任务。Agrawal等[4]首次给出了两个项目集合(Item)中的元素在事务集合(Transaction)中存在的关联规则、置信度、支持度的定义。关联规则挖掘的经典应用是“购物篮”数据分析,目的是找出顾客在商场或者店铺所选购的商品之间的关联。下面给出一个关联规则的例子:
花生→啤酒 [支持度=40%,置信度=80%]
以上表明40%的客户同时购买花生和啤酒,在购买花生的人中80%的人也购买了啤酒。
本文中,将关联规则应用在“如何发现语境歧义词搭配”问题上。词语的集合看成是两个Item,词语搭配的集合看成是Transaction,找出两个Item中的元素在Transaction上的并发关系。如下:
体重→暴涨 [支持度=20%,置信度=70%]
夺取→生命 [支持度=20%,置信度=70%]
这两个规则表明20%的人同时使用“体重暴涨”和“夺取生命”,在分别使用“体重”和“夺取”的人中有70%的人也分别使用了“暴涨”和“生命”。在“花生→啤酒”例子中没有考虑购买“花生”和“啤酒”的先后问题,在语境歧义词搭配中也是不考虑词语的先后问题,例如,“视觉→对抗”和“对抗→政府”,表达了明显相反的两种情感倾向性,对于“对抗”,和其搭配的“视觉”和“政府”也没有先后的问题。下面给出两个定义,其中X,Y是Item中的两个元素:
定义1 搭配集:形如X→Y的规则如果满足最小支持度[5](α),称X→Y构成的集合{X,Y}是搭配集。
定义2 频繁集:搭配集中满足最小置信度[5](β)的规则X→Y称作频繁集。
本文也采用类似关联规则的方法,在Transaction中先发现搭配集,然后在搭配集中识别频繁集,经过PMI过滤后构成语境歧义词候选搭配集,进而构建语境歧义词搭配词典。
2.2 基于语义分析的句子情感倾向性分析
目前,对于句子情感倾向性的分析,主要包含机器学习[6-7]和语义分析两类方法。
语义分析是用于知识的获取和展示的理论和方法[8],它使用统计方法对语料集进行分析,提取和表示出词的语义,其是词语的上下文信息的总和。这是因为上下文对其中的事物提供了一组相互的联系和制约,这在很大程度上决定了词语之间语义上的相关性[8]。语义分析最初的应用是在信息检索中,解决关键字检索时的同义词和多义词问题。语义分析假设词语在文本中的使用模式存在某种语义结构,同义词之间具有基本相同的语义结构,多义词的使用具有多种不同的语义结构,语义分析的方法可以提取并量化这些语义结构,进而消除语境歧义的影响,克服多义词、同义词和单词依赖的现象,提高文本表示的准确性。故使用语义分析方法进行句子的倾向性分析,这种语义结构蕴涵在语料中词语的上下文使用模式中。
3 理论基础语境歧义词搭配的识别
3.1 种子词的选择
在COAE2008评测后,分析结果发现判断错误的句子多数为以下两种情况:(1)句子中有语境歧义情感词,无情感词,例如,“最近,章子怡人气暴涨,电影票房直线上升”。(2)句子中不存在情感词也没有语境歧义情感词,但却表达了情感,如“看着这个电影我就想睡觉!”。
为解决第一种类型的句子,我们选择的种子词是20个常见的语境歧义词,通过观察发现其他大部分的语境歧义词可以用HowNet[9]和哈尔滨工业大学的同义词词林对这20个语境歧义词进行扩展得到,这样对以后语境歧义词搭配词典的扩充将会带来方便。
3.2 境歧义词搭配的挖掘
对语料中的句子分词,以种子词为中心词,4为窗口,前后共取8个词。根据汉语语言思维,修饰一个词语的词数在1~6个,人们不倾向用长句,长句会导致相互依存的两个词不再依存,或不再属于同一个意群,出现歧义。窗口取得太小会导致一些搭配未被发现,过大会导致噪音过大,故我们选择4。把这9个词看作是一个序列串,种子词组成的集合构成一个Item,里面的每一个元素为X,其他词组成的集合构成另一个Item,里面的每一个元素为Y。蕴涵关系式X→Y构成了搭配集。事务Transaction中的元素由每一个句子中的种子词分别和上下共8个词组合而成。采用如图1所示的流程挖掘语料中的搭配对。
Step1:找出满足最小支持度α的搭配集;
Step2:在产生的搭配集的基础上,产生满足最小置信度β的频繁集。
设α=0.005%且以0.005%增长,β=0.1%且以0.1%增长,针对每一对参数(αi,βi)训练,取结果最好的一对。
初始值的确定是因为当α<0.005%,β<0.1%时剪枝过程不明显, 搭配集的噪音过大。在参数最优化时,取多褒义的“变革”、多贬义的“暴涨”和褒贬个数相当的“减少”作为测试数据,然后取三组实验的平均值。当两个参数增长时, 挖掘的搭配对逐渐减少,带有情感倾向性的搭配对也随之流失,用γ表示带有情感倾向性的搭配未被发现的比例。具体结果如表1所示:当α=0.000 1,β=0.000 1时,γ最小。
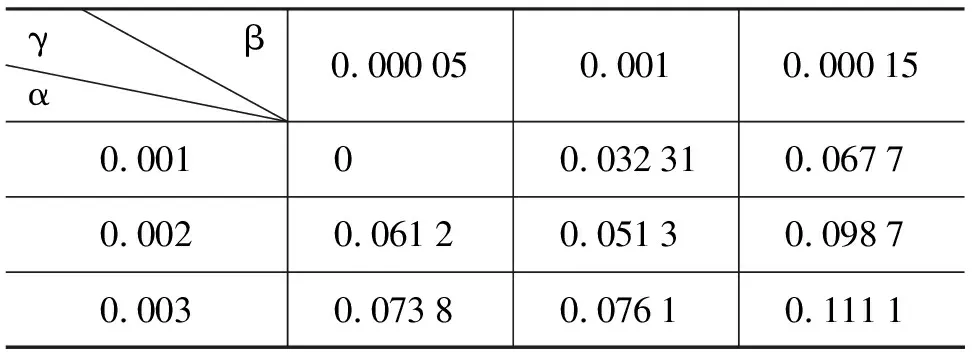
表1 γ的选取
实验中通过观察生成的频繁集,我们发现很多生成的规则也是无关紧要的。基于这种问题我们利用信息论中的互信息来进一步挖掘搭配词间的关系。设两个词x与y,出现的概率为P(x)与P(y),它们共同出现的概率为P(x,y),则互信息I(x,y)的定义如下(式1):
(1)
设定一个阈值δ,如果I(x,y)<δ,认为该搭配无效。在式(1)中,通常采用计算词的个数的方法计算概率。我们知道用词的tf-idf值计算互信息更能表达词与词的关联程度,所以把式(1)改写成式(2)。其中tf-idfx为语料集中出现词x的tf-idf值。
(2)
与α,β的确定方法类似,δ<0.02时,实验发现对频繁集的剪枝不明显,故初始δ=0.02且以0.02的速度增长,用三组实验的平均值寻找最优参数。用μ表示带有情感倾向性的搭配流失的比例,最优化过程如表2所示,δ=0.06时实验结果最好。

表2 μ的选取
由目标集中带有情感倾向性的关联项构成语境歧义词搭配词典,采用如下的存储形式:
<种子词 描述对象 情感类别> 或者 <描述对象 种子词 情感类别>
例如,<颈椎 突出 负>,<成绩 突出 正>,<洪水 暴涨 负>,<人气 暴涨 正>。
4 句子的情感倾向性判断
本文在判断句子情感倾向性时采取语义分析方法。先对语料中能够体现情感色彩的词或者短语进行抽取,然后对抽取出来的词或者短语进行倾向性判断,并且赋予一个倾向值,最后将上述所有倾向值累加起来得到一个分值,根据这个分值来判断句子的情感倾向性。
4.1 基于语境歧义词的情感词典
本文采用大连理工大学信息检索实验室的情感词汇本体[10]、情感常识库[11]、基于第三部分建构的语境歧义词搭配词典和从HowNet的评价词表中抽取的评价词,共四部分构成本文的情感词典——基于语境歧义词的情感词典,以下简称“情感词典”。情感词典中词语的数目和正负项的分布如表3所示,其中O表示正、负项,D表示情感词典的组成。
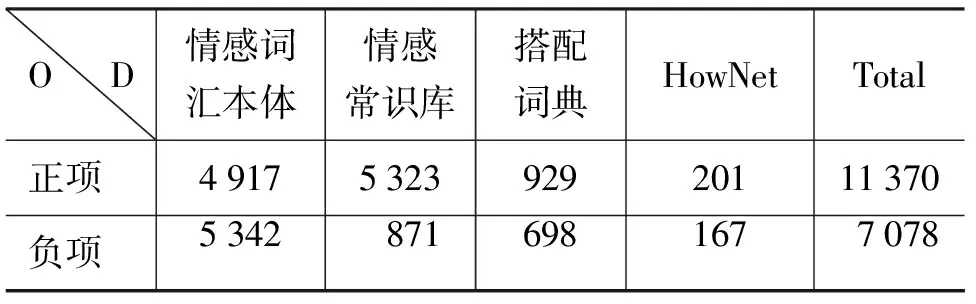
表3 基于语境歧义词的情感词典
如果句子中有否定词,则句子的倾向性可能发生变化。本文为抽取的待判断词设置一个检测窗口winsize,在winsize内出现否定词,就对句子的情感倾向性取反。根据实验测试得到当winsize为6时实验效果最好。相对于传统的否定词和转折词,在否定词表中加入了毫不、没法、难免、不怎么等重要的否定词。在转折词表中加入了不料、偏偏、谁知、岂知等有汉语特色的转折词。
4.2 句子倾向性判断
根据句法规则,本文将句子分为转折句和非转折句。分词后判断句子中是否有转折词,根据汉语思维习惯,如果有,认为句子要表达的中心思想在转折词后。首先为情感词汇表中情感词赋权重,正项情感词+1,负项情感词-1。对句子分词,判断是否为情感词典里面的词,然后在winsize内检测是否有否定词出现,最后用式(3)计算句子的情感分值。
(3)
其中pi=1代表正项情感词权重,nj=-1代表负向情感词权重,当正项词或者负项词的前面存在否定词时,dj=-1。m和n分别代表句子中情感词存在的个数。当score大于0时句子的情感倾向性即为正项,当分值小于0时句子的情感倾向性即为负项。
5 实验结果与分析
首先我们用第四节中提到的方法对句子进行情感倾向性分析,为了证明语境歧义词搭配词典的重要性,我们把情感词典分成两部分:一部分不含有语境歧义词搭配词典;另一部分含有语境歧义词搭配词典。
我们首先选择的是COAE2008的语料。因为COAE2008语料涵盖的内容比较全面,其中包括科技、财经、体育、电影影评、新闻等各个方面的内容,较具有空间跨度,覆盖面比较广,不单一。为了验证所建立的情感歧义词搭配词典是否有通用性,即不只是对COAE语料有提高,我们又在大连理工大学信息检索实验室的情感语料库[12]上做了对比试验,情感语料库中包含250 021个句子,句子覆盖小学教材、电影剧本、童话故事、文学期刊。从时间、空间、学科、风格和构成上看覆盖面大。其中包含本文所选的种子词但不包含情感词汇本体中的词的句子占5.8%。
5.1 语料选取与预处理
首先将两个语料中的短篇文章进行分句,检索出其中带有种子词的句子,每个种子词取出其中的主观句子500条作为实验语料。在选择实验语料时要剔除存在以下三种情况的句子:
(1) 经过分词后不再包含种子词的句子;
(2) 不成句,不能表达完整意思的句子;
(3) 与同一种子词的已有句子表达意思相同的句子。
其中,条件(1)和(2)用来保证所选语料真正包含所选词汇并且符合汉语语法的完整句子,这个问题的产生是由于在语料中存在大量的网络上关于电影、体育的评论,而网评信息的一个特点就是语法不规范,存在较多的语病,这会影响本文对语境歧义词的研究;条件(3)是为了排除语料中大量重复信息带来的干扰。句子中存在部分相同的成分时,我们视为是该词汇的不同句法或者正常的语用重现,直接保留不予剔除。句子数500条是人工观察选定的,因为超出500后所获取的重复句子明显增加,很少能获得新的实例。
语料收集完成后,人工对语料进行标注,若句子表达的是褒义则标注为“正”项,若句子表达的是贬义则标注为“负”项。20个种子词语在语料中的“正”项、“负”项以及每个种子词中所包含的隐式情感句的个数分布情况如图2所示,其中724个隐式情感句子中,正项隐式情感句有“289”个,负项隐式情感句有“435”个。
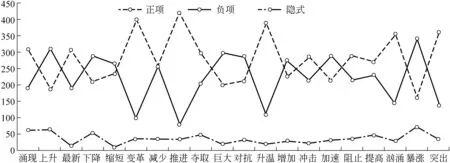
图2 语料分布情况
5.2 实验结果与分析
在COAE2008中以20个种子词为类别的实验结果总体上都有一定的提高,从表4中可以看到“暴涨”、“上升”、“涌现”的准确率、召回率和F值相对提高的多,而“最新”、“缩短”、“升温”、“巨大”的准确率、召回率和F值相对提高的少。
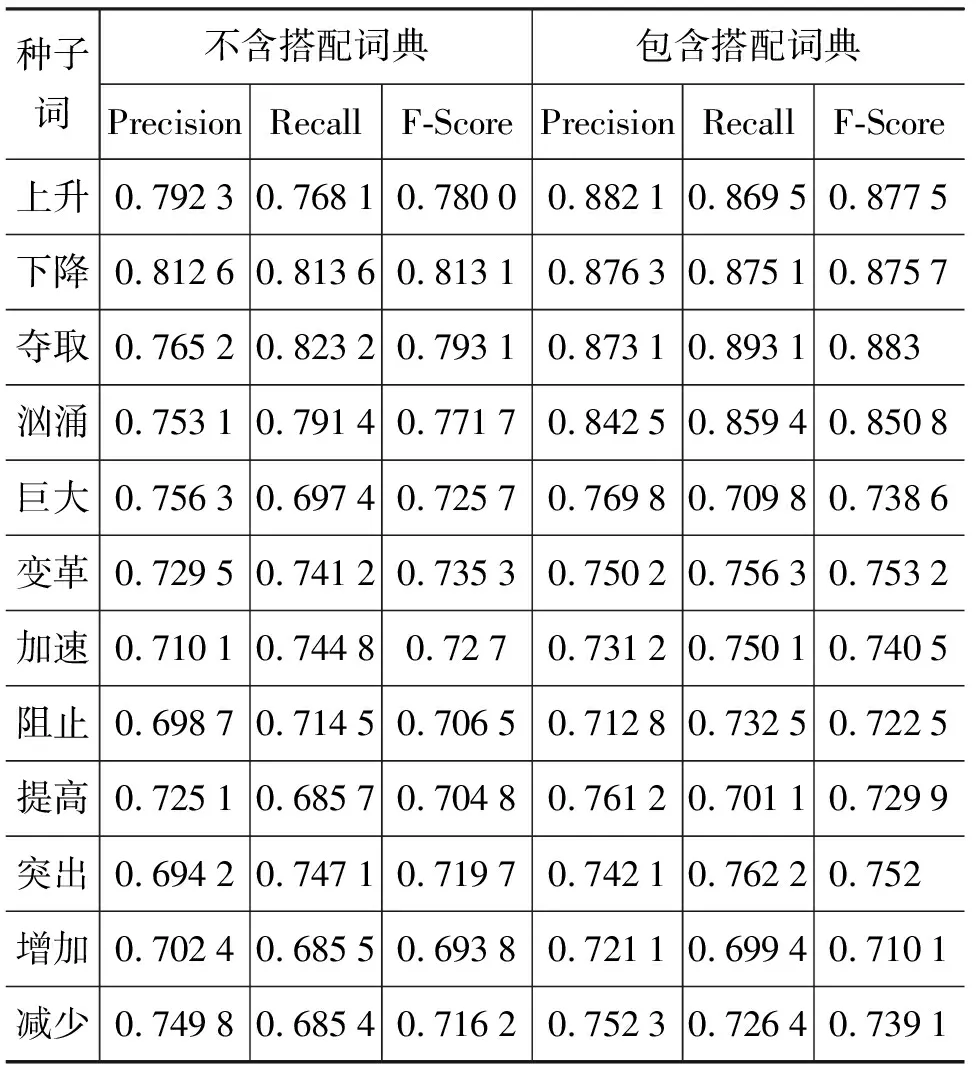
表4 20个种子词的实验结果
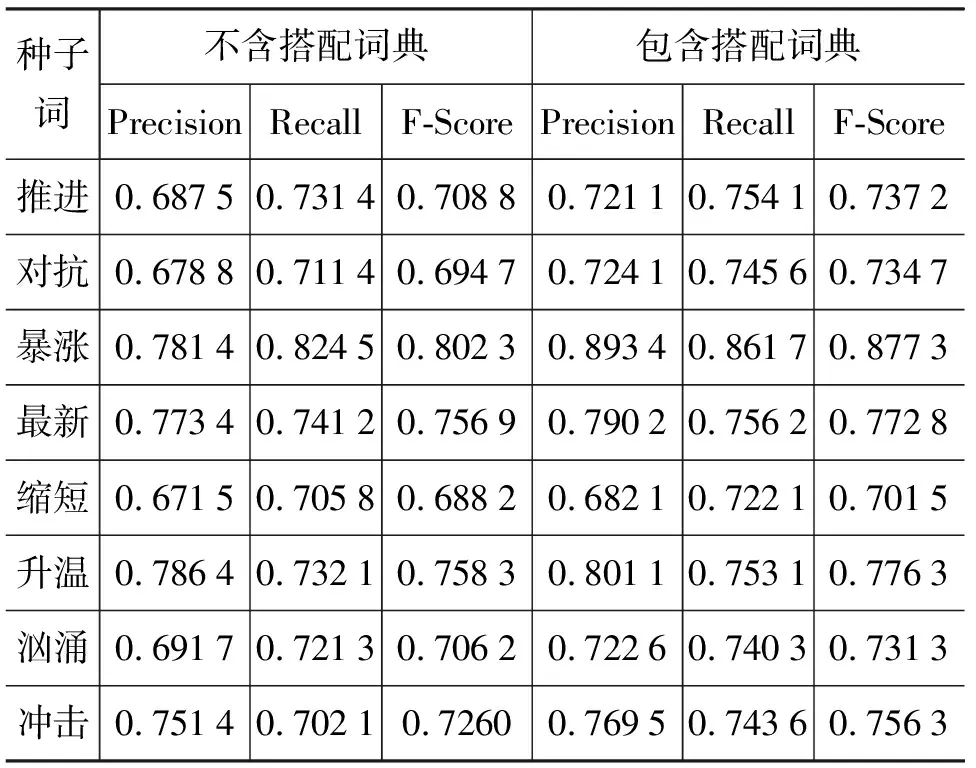
续表
通过观察语料,发现提高得多的种子词在语境歧义词搭配词典中所占的比例要比其他的种子词所占的比例大,这类词在语料中存在语境歧义的情况较明显。两个形容词性的种子词的百分率都提高的不多,这也正符合我们的汉语语言习惯。我们知道当形容词修饰名词时,情感的倾向性或者体现在名词上面或者体现在形容词上面,看下面的两个例子。(1)“美丽的女孩”和“悲伤的事情”的情感倾向性主要体现在形容词“美丽”和“悲伤”上。(2)“巨大的灾难”、“最新疫情”的情感倾向性体现在名词“灾难”和“疫情”上,而类似“灾难”和“疫情”这些带有情感倾向性的名词已经收录在我们的情感词汇本体中,所以提高地不多。由此我们也得出,带有情感倾向性的语境歧义词主要是动词。
我们又分别对COAE2008语料中的正、负例情感分别做了对比试验,试验结果如表5所示。
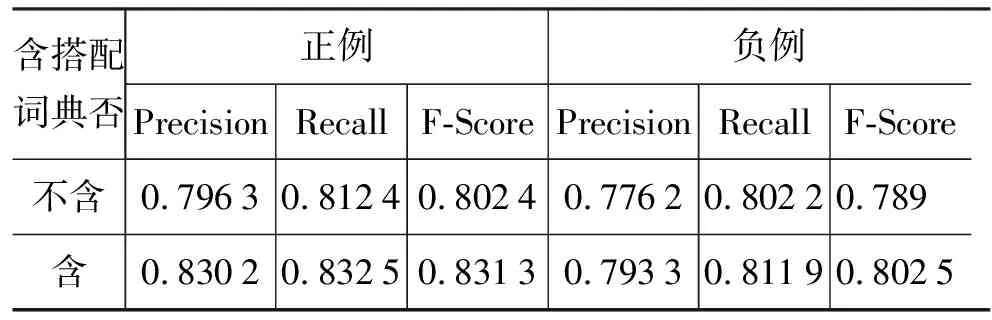
表5 COAE2008语料中正、负例的实验结果
我们发现正类的分类效果优于负类,仔细阅读语料发现,负类中隐性情感的比例要多于正类,并且负类中对于情感的表达方式比较复杂,结构也比较多样化。观察正负例分类出错的句子,出错原因主要有以下几点:(1) 长句占据的比例比较多,并且这类句子一般含有多个情感主题,没有一个主要的情感倾向性; (2)由于用支持度、置信度、PMI过滤导致一小部分的带有情感倾向性的搭配对流失,使得判断错误,但是由流失的搭配引起的分错类别的句子占极少数;(3) 对于句子中不存在情感词也没有语境歧义情感词,但是却表达了一定的情感的问题,如“看着这个电影我就想睡觉!”,这种句子我们还没有很好的解决,而这也一直是句子情感倾向性判断的一大难题。
为证明语境歧义词搭配词典的通用性,我们在COAE2008和情感语料库上分别做了对比试验,分别如图3、4所示,从图中看到两者的实验结果都有一定提高。分析所有的实验结果,我们认为,提高的原因在于:基于语境歧义词搭配词典的实验不仅考虑了句式,句法规则,而且还充分考虑了语境歧义词、否定副词和转折词对语言情感倾向性的影响。

图3 COAE2008语料集的实验结果
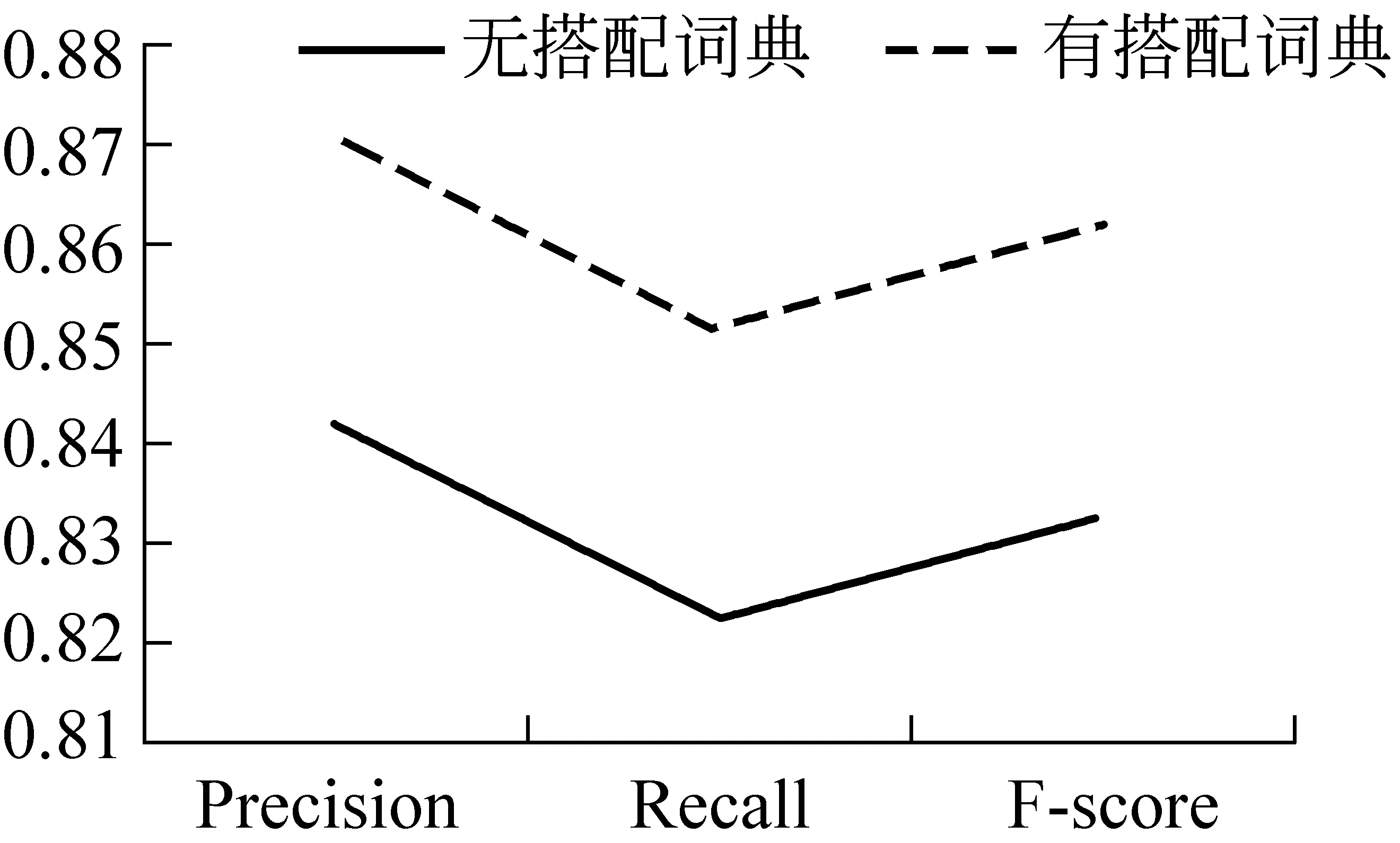
图4 情感语料库的实验结果
6 结语
本文给出了一种基于关联规则挖掘语境歧义词搭配频繁集,构建语境歧义词搭配词典的方法。从语义搭配的角度出发,把句子分为两大类,设计了两种观点倾向性分析策略。对语料的测试表明,基于语境歧义词的句子倾向性分析有重要的意义,我们从汉语语义上的修饰关系入手,挖掘情感评价对象和评价词之间的深层联系。通过在COAE2008语料上和情感语料库上的实验,我们发现了语境歧义词搭配词典在文本倾向性分析中的重要性。
目前语境歧义搭配词典的建设工作还在进行中,其中只含有与种子词和与种子词意思相近或者相反的搭配。我们计划加入更多的语义资源来丰富语境歧义词搭配词典,根据实际的需要增加语境歧义词搭配词典的规模,使语境歧义搭配词典更加的全面和完善。
[1] Bolshakov IA,Gelbukh A. Heuristics-Based Replenishment of Collocation Databases[J]. E.M.Ranchhod and N.J.Mamede(Eds.),2002,2389:25-32.
[2] 车万翔,刘挺,秦兵.面向依存文法分析的搭配抽取方法研究[C]//全国第六届计算语言学联合学术会议论文集.太原:全国第六届计算语言学联合学术会议,2001:102-107.
[3] Ding XW,Liu B,Yu PS.A Holistic Lexicon-Based Approach To Opinion Mining[C]//Proceedings of The Conference on Web Search And Web Data Mining (WSDM).New York:ACM,2008:231-240.
[4] Agrawal R,Imielinski T,Swami AN.- Mining Association Rules Between Sets of Items In Large Data Bases[C]//Proceedings of The ACM SIGMOD Intl Conference on Management of Data. Washington:1993:207-216.
[5] Agrawal R,Srikant R.Fast Algorithms For Mining Association Rules[C]//The Proceedings of Intel Conference on Very Large Data Bases.Santiago:1994:487-499.
[6] Kim SM, Hovy E. Automatic Detection of Opinion Bearing Words And Sentences[C]//The Proceedings of IJCNLP-2005.JeJu Island:2005:61-66.
[7] Zhao J, Liu K. Adding redundant features for crfs-based sentence sentiment classification[C]//The Proceedings of The 2008 Conference on Empirical Methods In Natural Language Processing. Honolulu:2008:117-126.
[8] Landauer TK, Foltz PW,Laham D.Introduction to Latent Semantic Analysis Discourse Processes[M],1998,25:259-284.
[9] Zhen Dong. Dong.http://www.keenage.com/zhiwang/e_zhiwang.html[EB/OL].
[10] 徐琳宏,林鸿飞,潘宇.情感词汇本体的构造[J].情报学报,2008,27:180-185.
[11] 陈建美,林鸿飞,中文情感常识知识库的构建[J].情报学报,2009,28:492-498.
[12] 徐琳宏,林鸿飞,赵晶.情感语料库的构建和分析[J].中文信息学报,2008,22(1):116-122.
