基于机器学习方法的英文事件代词消解研究
2012-06-29李培峰周国栋朱巧明
张 宁,孔 芳,李培峰,周国栋,朱巧明
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)(江苏省计算机信息处理技术重点实验室,江苏 苏州 215006)
1 引言
指代(Anaphora)广泛存在于自然语言的各种表达中,是自然语言中常见的语言现象,其中相照应的词语称为照应语(Anaphor),所指的对象或内容称为先行词(Antecedent)。指代消解就是确定照应语与先行词之间的关系,从而明确照应语指代的是什么。指代消解是自然语言处理的关键和热点问题之一,在自然语言的篇章理解、信息抽取、机器翻译、文本摘要和问答系统等应用中起非常关键的作用。
指代大体可以分作两类: (1)实体指代,指代的先行词和照应语都是客观存在的具体实体,例如,例①中Microsoft Corp.和Microsoft都是客观存在的实体;(2)事件指代,照应语指向事件、事实、命题等事件性、抽象性对象,例如,例②中The strong growth指向的是一个事件,又如例③中代词it指代前面“take the train”事件。近年来,实体指代消解已经获得了大量的关注并已经取得较好的研究成果,但是事件指代消解却还有很多工作要做,本文将研究事件指代消解。
例① [Microsoft Corp.] announced its new CEO yesterday. [Microsoft] said...
例② Sales of passenger cars [grew]22%. [The strong growth] followed year-to-year increases.
例③ I [take] the train because [it] is a lot sane than flying.
2 相关工作
目前针对事件指代消解的工作主要有两类。
(1) 是ACE的一个子任务,即找出文档中所有共指的事件,将其归类。典型的工作有: Zhang Chen等[1]把整个事件共指消解过程看作是一个聚类任务,通过比对每一对事件,利用最大熵模型判断每一个活动事件与前面的事件是否归并为一类,最终达到共指消解目的。Bejan等[2]提出了两种无参贝叶斯模型来实现无监督的事件共指消解。
(2) 处理照应语与事件间的指代关系,其中照应语通常是名词性的(包含名词短语,如例②;也可以是代词,如例③)。Chen等[3]首次系统地阐述了事件代词消解,该文利用Soon等人的基于机器学习的指代消解模型,提出了一个事件代词指代消解系统,它综合使用了平面特征和结构化的句法特征,利用卷积树核来抽取标志性、结构化的句法知识,还用了双候选先行词来提高指代消解系统的性能。Chen等[4]在前面工作的基础上补充了照应语为普通名词短语状况下的事件指代消解,进一步完善了消解系统。Kong和Zhou[5]在Chen等工作的基础上探讨了与指代词和先行事件候选具有竞争关系的信息对事件指代消歧的影响。
本文主要针对第二类事件指代进行消歧,考虑到代词蕴含了极少的自身信息,更具有挑战性,本文主要研究代词与事件间指代关系的消解,但文本提出的基本框架和方法也适用于普通名词短语与事件间的指代消解。
3 基于机器学习方法的事件代词消解
本文参照Soon等[6]给出的基于机器学习方法的实体指代消解平台,构建了一个基于机器学习方法的事件代词消解平台,重点探索了句法特征和语义特征对事件代词消解的影响。
3.1 实例的生成
训练时,若存在指代链V- P1- P2…Pn,先行词V和照应语P1组成的实例对
3.2 特征选择
我们从三个方面来选取有效的特征用于事件指代消解,选择的基本原则是易于获取且对该任务有效,具体的特征情况参见表1。
(1) 平面特征: 主要从语法角度描述照应语及先行词自身的某些信息,以及它们在上下文中的语法角色信息等。
传统指代消解的研究已经确定了一些非常有效的平面特征,但大多数这类特征都不适用于事件指代消解任务。例如,别名特征,Soon等[6]的研究表明,仅别名一个特征对传统实体指代消解F1值的贡献度在MUC-6语料中就达到了38.4,但在事件指代消解任务中,因为先行词是动词,与照应语(NP)属于完全不同的语义分类体系,别名就不再适用了。就事件指代消解任务而言,选择适合该任务的特征集是一个很重要的环节。在Chen等研究的基础上,本文给出了一组适于事件指代消解任务的平面特征,具体如表1中的第一行所示。
(2) 结构化特征: 主要用于补足平面特征,减轻特征工程的负担。
寻找适合事件指代消解的平面特征集属于特征工程,需要一定的篇章构成等相关的语言学基础。近年来,结构化句法特征在实体指代消解领域得到了广泛的关注,并取得了较好的结果,例如,Yang 等[8],Zhou等[9]。与平面特征相比,其最大的优势在于: 一方面,结构化句法树能更加直接的描述一些有效的平面特征,例如,语法角色信息。另一方面,一些未知的有利于事件指代消解的特征也蕴含在了结构化特征中,减轻了特征工程的负担。本文在Yang等[8]工作的基础上,将性能最佳的最小扩展树应用到了事件指代消解中。所谓最小扩展树,是指仅保留先行词候选及照应语之间的一条最短路径形成的结构化句法树。由于照应语和先行语可能不在同一个句法树上,可以通过增加一个虚结点TOP,把两棵句法树链接起来,形成篇章树,再在篇章树上选取最小扩展树。图1给出了一个最小扩展树的获取实例。
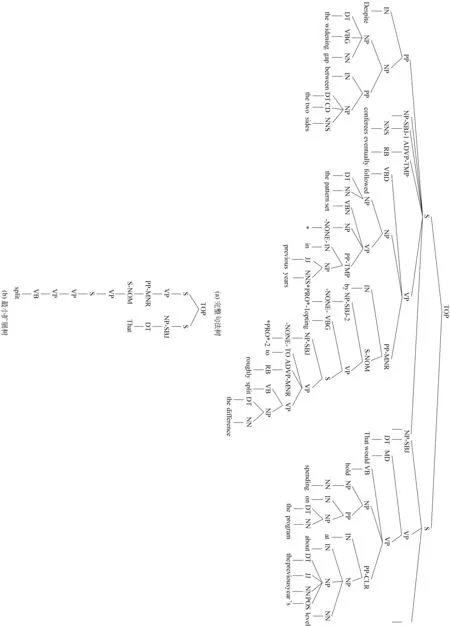
图1 最小扩展树(MET-Min Expand Tree)的生成实例

表1 特征及相关说明
(3) 语义特征: 主要针对事件指代中照应语和先行词蕴含的语义信息不足这一问题展开,通过对照应语和先行词所处上下文的语义信息的描述来确定两者间的语义相容度。
事件指代消解处理的是事件,只通过词法或句法结构很难理解一个完整的事件。根据中心理论[10]语篇的话语中心应该是连贯的或平稳转移的,因此我们认为当前要处理的事件和照应语所在上下文的语义应该具有很高的语义相容度。本文选取照应语和先行词候选所在语句的前后各5个单词来描述照应语和先行词候选的上下文,并通过计算上下文间的语义相似度来描述两者间的语义相容度。语义特征的获取算法如图2所示。

图2 语义特征的获取算法
3.3 机器学习算法
从理论上讲,任何一种用于分类的机器学习方法均适用于指代消解任务,例如,Soon[4]采用了决策树算法(C5);Ng 等[11]采用了决策树算法的同时也尝试了 RIPPER 方法; Yang[8]则选择了支持向量机(SVM)。本文使用的是支持向量机方法,并使用SVMLight*http://svmlight.joachims.org/作为分类器。要解决一个非线性分类问题时,支持向量机的基本思想是通过非线性变换,将其转化为某个高维空间中的线性问题,在变换空间中求最优分类面。但这种变换可能比较复杂,一般情况下不易实现。因此支持向量机为这种映射提供了简单有效的途径,被称为“核(Kernel)”方法。下面我们就简单介绍一下我们所用到的核函数。
(1) 多项式核函数
处理平面特征我们使用了多项式核函数(Polynomial Kernel),具体表示为式(1):
K(x,xi)=(
(1)
其中θ∈R,d∈N。
(2) 卷积树核
Collins等[12]提出的卷积树核函数是卷积核函数的一个特例,它通过列举两棵树之间的公共子树数目来计算相似度,如式(2)所示:
其中Ci代表树Ti中的节点集合,而 Δ(c1,c2)用来计算以c1和c2为根节点的子树的相似度。
(3) 复合核
为了充分利用结构化信息同时又能利用平面特征,我们使用复合核来结合卷积树核与多项式核,本文使用了SVMLight中提供的 K1+K2的复合核,其中K1表示处理结构化信息的卷积核,而 K2表示处理平面特征的多项式核,新的复合核为两个核的和。
4 实验结果及分析
4.1 实验配置
我们使用规模更大,涉及领域更广的Onte-Notes3.0语料来评测我们的事件指代消解平台,表2、表3和表4分别给出了语料的规模及照应语的数量及距离分布情况。

表2 OntoNotes 3.0的基本构成

表3 OntoNotes3.0 中各种照应语的分布情况

表4 先行词和事件代词之间距离的分布情况
从表2、表3、表4可以看到:
(1) OntoNotes语料库规模大、领域广。该工程是由BBN公司、布拉迪斯大学、科罗拉多大学、宾夕法尼亚大学、 南加州大学信息科学研究所合作发起、创建的一个跨学科、跨领域的巨大的文本语料库,这个语料库包括三种语言(英语、中文、阿拉伯语)的来自各个领域的新闻、广播、Web、脱口秀节目等,它详细标注了词法、句法、语义等信息,尤其是其标注的事件指代关系可以很好的为我们的消解平台所使用。我们的实验将使用其新闻语料中的英语部分(约500K,WSJ300K,广播新闻200K)。
(2) 事件代词所占比例较低(约占代词总数的4%,占代词性的指代词的比例约为14%),再加上代词本身蕴涵的自身信息较少,所以事件代词消解较其他事件名词短语消解或实体指代消解更困难。与实体指代消解类似,事件指代消解也应该由事件指代词识别和事件指代词的先行语识别两个子任务构成,本文重点探讨事件指代词的先行语识别任务,为了不受事件指代词识别性能的影响,在这里我们假设事件指代词已知且完全正确。
(3) 事件代词和其先行词之间的距离,不论以句子为单位衡量,还是以中心动词数来衡量,我们发现距离都不大,因此本文将先行词的搜索空间限定在当前句和前两句。此外,根据中心理论,相邻两个话语的焦点应该是平稳过渡的,指代词和先行词所在句在语义上也应该存在较高的相似性或相关性。
我们的事件指代消解平台采用了类似实体指代消解的预处理系统来进行词性标注、命名实体识别、句法分析等预处理工作,各类平面特征和结构化特征的获取都是经预处理后在自动结果上提取的。实验采用MUC评测方法,该方法不但反映了系统的性能,同时也标注了错误类型,为错误分析和进一步研究提供了基础。MUC对指代消解结果的技术评估有三个重要标准,召回率R(Recall)、准确率P(Precision)和F值。其中: 召回率R是指代消解结果中正确消解的对象数目占消解系统应消解对象总数的百分比,它反映的是指代消解系统的完备性;准确率P是指代消解结果中正确消解的对象数目占实际消解的对象数目的百分比,它反映的是指代消解系统的准确程度。比较两个不同系统的性能时,一般使用F值,F值是召回率和准确率这两个指标的综合值,定义如下:
其中P为准确率,R为召回率,β为召回率和准确率的相对权重,一般取1,因此F值可以表示为:
因为涉及的事件指代的实例数量较小,为了保证结果的稳定性,我们使用了10倍交叉验证法,取平均值作为最终结果。
4.2 实验结果及分析
实验一:负例向下随机采样实验
实体指代消解中,我们可以根据照应语和先行词候选自身的词、数及选所属的语义类别是否一致进行过滤,从而确保参与机器学习的正负例比例合理,能够训练得到高性能的分类器模型。然而在事件代词的消歧中,照应语是this、that或者it这样的中性代词,包含了极少的词、数以及语义信息。另外,先行词候选是一个事件的描述,通常我们都选择该事件的驱动动词来表示,它与照应语(代词)具有完全不同的语义分类系统,我们无法通过词、数和语义类别是否一致来约束我们的实例配对。这种情况下,在OntoNotes语料上,我们构造生成的正负例比例达到了1∶10,即使经过各种规则的过滤约束,比例仍然高于1∶3。因此,我们首先通过负例向下随机采样实验来说明,就事件代词的消解任务而言,正负例比例在1∶1时可以得到较好的性能。实验中,我们使用了文献[7]中的方法对负例进行了采样。表5给出了负例随机采样前后的性能,图3给出了向下随机采样时,不同正负例比例下事件代词消解的性能情况。

表5 随机采样前后事件代词消解的性能

图3 不同正负例比例下事件代词的消解性能
从表5所示的结果可以看到,利用向下采样方法将正负例调成1∶1后,事件代词消解的召回率提升了39.76,正确率由未采样前的61.31降成了43.41,系统的F值提升了21.76,可见在正负例失衡的情况下,采样方法有利于构造更有效的分类器模型,因此文章后续给出的实验结果,若无特别说明,均为使用随机采样方法将正负例比例调整至1∶1水平后的结果。
图3给出了利用随机采样方法将正负例比例调整至不同值时事件代词消解的性能变化曲线。其中横坐标为负例与正例的比例值,从中我们可以看到,随着负例比例的不断增大,事件代词消解的准确率不断提高,同时召回率不断提升。平衡准确率和召回率后,正负例比例为1∶1时,系统获得了最佳的F值。
实验2:三组特征的组合及贡献度实验
我们对结构化句法特征与平面特征分别做了实验,实验结果如表4和表5所示。
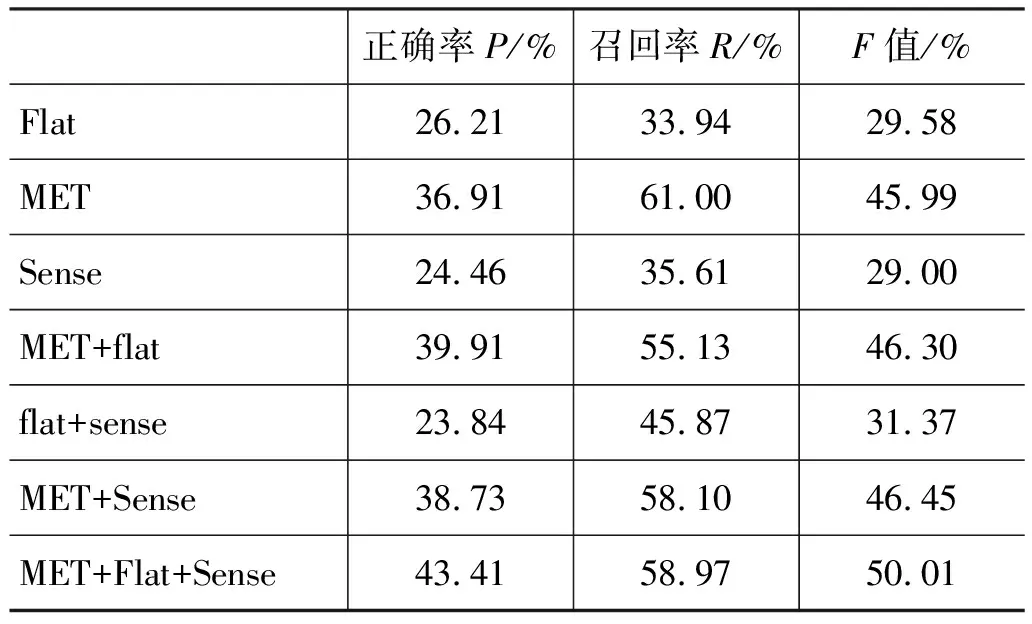
表6 三组特征的组合实验
表6给出了三组特征的组合实验结果。从表中可以看到:
(1) 分别独立地仅使用三组特征中的一组,结构化特征可以获得最佳的召回率和准确率。平面特征和语义信息对事件代词的消解也非常有效,但不如结构化特征明显。
(2) 结构化特征与平面特征的组合能有效地提升事件代词消解的准确率,召回率较独立使用结构化特征时略有下降,系统的整体性能较独立使用结构化特征提升较小,约为0.3%。
(3) 平面特征与语义特征的组合能极大地提升事件代词消解的召回率,系统总体性能相比独立使用语义或平面特征提升了约为2%。
(4) 结构化特征与语义特征的组合也能有效地提升事件代词消解的准确率,系统整体性能略有提升,F值达到了46.45。
(5) 将三组特征组合后,系统获得了最佳的准确率(43.41%),召回率较独立使用结构化特征略有下降(1.03%),系统的整体性能达到了最佳状态,F值为50.01%。
5 总结与展望
本文讨论了给出了一个基于机器学习方法的事件代词消解平台,并探讨了平面特征、结构化特征以及语义特征对事件代词消解的贡献度。下一步的工作是考虑其他更有效的句法树剪裁策略,以及如何在事件代词消解中更充分利用语义信息来提升事件代词消解的性能。
[1] Zheng Chen, Heng Ji. Event Coreference Resolution: Algorithm, Feature Impact and Evaluation[C]//Proceedings of ACL,2009,W09-4303.
[2] Cosmin Adrian Bejan, Sanda Harabagiu. Unsupervised Event Coreference Resolution with Rich Linguistic Features[C]//Proceedings of ACL2010,2010: 1412-1422.
[3] Chen Bin, Su Jian, Tan Chew Lim. A Twin-Candidate Based Approach for Event Pronoun Resolution using Composite Kernel[C]//Proceedings of COLING,2010: 188-196.
[4] Chen Bin, Su Jian, Tan Chew Lim. Resolving Event Noun Phrase to Their Verbal Mentions[C]//Proceedings of EMNLP,2010: 872-881.
[5] Kong Fang, Zhou Guodong. Improving Tree Kernel-based Event Pronoun Resolution with Competitive Information[C]//Proceedings of IJCAI’2011.
[6] Soon W.M., Ng H.T., Lim D. A machine learning approach to coreference resolution of noun phrase[C]//Proceedings of Computational Linguistics, 2001, 27(4):521-544.
[7] Kubat M, Matwin S.. Addressing the curse of imbalanced data set: one sided sampling[C]//Proceedings of the 14 International Conference on Machine Learning, 1997:179-186.
[8] Yang X.F., Su J., Tan C.L. Kernel-based pronoun resolution with structured syntactic knowledge[C]//Proceedings of COLING-ACL’2006: 41-48.
[9] Zhou G.D., Kong F., Zhu Q.M. Context-sensitive convolution tree kernel for pronoun resolution[C]//Proceedings of IJCNLP’2008.
[10] Grosz B.J., Sidner C.L.. Attention, intentions and the structure of discourse[C]//Proceedings of Computational Linguistics. 1986, 12(3): 175- 204.
[11] Ng V, Cardie C. Improving machine learning approaches to Coreference Resolution[C]//Proceedings of ACL, 2002: 104-111.
[12] Collins M., Duffy N.. Covolution kernels for natural language [C]//Proceedings of NIPS’2001, 2001: 625-632.
[13] M. Lesk. Automatic sense disambiguation using machine readable dictionaries: How to tell a pine cone from a ice cream cone[C]//Proceedings of SIGDOC ’86, 1986.
[14] Satanjeev Banerjee, Ted Pedersen. An Adapted Lesk Algorithm for Word Sense Disambiguation Using WordNet[C]//Proceedings of CICLing 2002, LNCS 2276, 136-145.
[15] Ted Pedersen ,Siddharth Patwardhan, Jason Michelizzi .WordNet::Similarity - Measuring the Relatedness of Concepts[C]//Proceedings of American Association for Artificial Intelligence (www.aaai.org). 2004.
[16] 王海东,胡乃全,孔芳,等. 指代消解中语义角色特征的研究[J].中文信息学报,2009,(1):23-29.
[17] 陈九昌,孔芳,朱巧明,等.基于树核函数的it待消解项识别研究[J].中文信息学报,2010,(5):24-30.
[18] 王海东,谭魏璇,李艳翠,等.基于树核函数的英文代词消解研究[J].中文信息学报,2009,23(5):33-39.
