多模式匹配及其改进算法在协议识别中的应用
2012-06-25朱姣姣
朱姣姣,叶 猛
(1.光纤通信技术和网络国家重点实验室,湖北 武汉 430074;2.武汉邮电科学研究院通信与信息系统,湖北 武汉 430074;3.武汉虹旭信息技术有限责任公司安全产品部,湖北 武汉 430074)
随着互联网的飞速发展,网络信息安全[1]与对抗已经成为网络信息时代的一个至关重要的问题。为了能够准确地对网络上的内容进行监控,就需要搞清楚网络上传输的数据包协议类型,但在目前,TCP/IP协议体系下的网络中,若要弄清楚数据包的协议类型,就必须要能够准确地识别数据包的应用层协议类型。而传统的采用端口的协议识别[2]对于采用动态端口进行通信却力所不能及,由于模式匹配算法检测原理简单易实现、实时性好、准确率高而备受广大软件爱好者喜爱,且技术上已经相对成熟,在协议识别领域得到了广泛应用,基于以上分析,本文重点讨论多模式匹配算法,以及其改进算法在协议识别中的应用,并分析模式匹配算法的今后研究方向。
1 模式匹配算法
单模式匹配算法是指在文本串中一次只对一个模式进行匹配;多模式匹配算法则可同时对多个模式进行匹配,在很大程度上提高了匹配效率,且多模式匹配算法同样也适用于单模式的情况。
1.1 单模式匹配算法
常用的单模式匹配算法有BF算法、KMP算法、BM算法[3],下面简要分析这几种算法。
BF算法是最早最简单的单模匹配算法,其特点是直观、简单,但涉及多次回溯,算法效率极低。
无需回溯指示文本串的指针是KMP算法的最大优势,其充分利用部分已匹配字符,将模式串尽可能向右滑动一段距离。但KMP算法存在着重复比较的缺陷。
BM算法基本思想是先对模式串进行预处理,当存在不匹配时,通过采用坏字符规则和好后缀规则,来计算模式串的偏移值,取两者中的较大值,实现跳跃式的遍历匹配。BM算法在单模式匹配中效率很高,但BM算法使用了两个数组,预处理开销大,计算两个偏移量的过程也很复杂。
针对单模式匹配算法,假如要匹配多个模式,则有几个模式,那么就需要进行几趟遍历,在效率上是很低的。而多模式匹配算法一次遍历则可匹配出多个模式,因此,根据多模式匹配算法所占有的优势,将其应用于协议识别中。
1.2 AC多模式匹配算法
AC算法[4]是基于应用层报文内容实时分析的核心算法。这种简单有效的算法用来在一串文本中确定给定的一组关键字在文本中发生的频度,它具有匹配速度快、占用CPU少、适合海量数据的网络环境等优点。
AC算法的基本思想是在处理阶段分别建立3个函数,即转向函数(goto)、失效函数(fail)以及输出函数(output),由此形成一个树型有限自动机;在搜索查找阶段,互相交叉使用以上3个函数,然后进行扫描文本,可定位出关键字在文本中的所有出现位置。
算法描述:构造P={P1,P2,…,Pk}对应的 k树。首先,从唯一的根节点开始;然后,通过添加一条从根节点出发的路径的方式,依次插入每一个模式Pi。新的节点和边被插入到K树中,以致产生了一条能拼写出关键字Pi的路径。在路径的终点存储Pi的标识i,关键字Pi会被添加到输出函数中。
1.2.1 生成树型有限自动机
例如,模式集{at,ater,eat,a&e}的树型有限自动机,转向函数goto如图1所示。
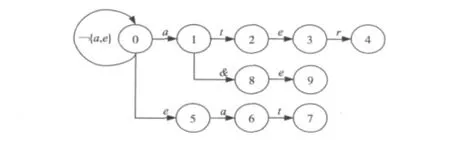
图1 转向函数goto示意图
失效函数fail和输出函数output如表1所示。
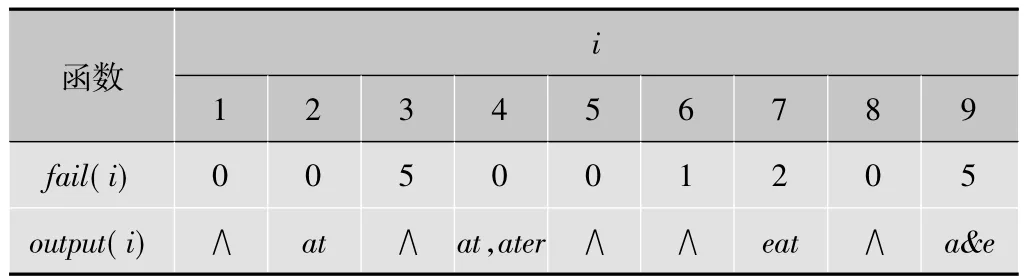
表1 失效函数fail和输出函数output
1.2.2 生成确定有限自动机
由以上3个函数生成的状态树为不确定有限状态机(NFA),当发现匹配失败后,需要通过fail函数来完成状态跳转,使用确定有限状态机(DFA),通过合并fail函数和goto函数,生成新DFA。利用这个确定的有穷自动机可以减少状态转移的次数,使得效率得到一定的提高。例如在状态1下输入字符e:NFA中,首先跳转至状态0,再在0状态下输入字符e,跳转至状态5,需查询2次状态表;DFA中,直接跳转至状态5,仅需查询1次状态表即可。
2 AC多模式匹配算法的改进
由于AC算法不能实现跳跃式搜索,研究者据此提出了多种基于AC的改进算法。Commentz-Walter提出一种结合AC和BM的算法(简称CW算法[5]),该算法将BM算法跳跃思想应用于多模式匹配中,匹配效率较高。Jang-Jong Fan和Keh-Yih SuCrochemore结合RF算法给出的 Dawg-Match 算法性能更优(简称 Dawg 算法[6]),王永成通过反向构建goto函数来实现模式匹配,该算法从右到左进行模式串比较,采取连续跳跃的思想,在匹配过程中尽可能跳过多的字符(简称Wang算法[7])。
另外针对AC算法对内存需求大的问题,研究者们也提出了多种快速和高效存储的优化算法,Norton[8]等提出了 Banded-Row Forma(带状行格式)和Sparse-Row Format(稀疏行格式)的稀疏存储格式。Tuck等采用位图压缩和路径压缩方法来减小自动机内存消耗,改善了储存性能。但均可能不同程度地引起匹配性能的下降。
在存在短模式串的情况下,CW算法、Dawg算法以及Wang算法的匹配性能会急剧下降,平均每字符检查的次数骤然增加,比不上AC算法的效率。
针对这一问题,本文提出一种基于AC的多模式匹配改进算法,其关键技术在于它不仅利用匹配过程中的“坏字符”信息,尽可能跳跃更多的字符,还利用模式匹配的信息,增加跳跃的步长。本文的算法基于这样一个前提,短模式串比长模式串匹配概率更高,且以更高的概率优先命中。
2.1 预处理阶段
算法的预处理阶段包括构建模式串集合的AC状态机,以及跳跃表shift。
AC状态机是一个有限状态自动机(DFSA),可描述为(Q,δ,f,s0,T)。其中Q表示状态机中状态的有限集合,δ表示状态转移函数,f表示失配状态转移函数,s0表示初始状态,T表示匹配的状态。在具体实现中,可以通过消除”坏字符”回溯取消f,使得δ对任何输入的字符转移到非空状态(包括s0)。这样AC状态机简化为(Q,δ,s0,T),图 2 表示了一个模式集合 P={aabbaa,bbaabb,abb,aa}对应的状态机,状态上方表示输出的模式集合output。
构建模式子集的shift表之前,首先按照模式串的长度将所有的模式分为L个相交的子集。给定P=p1,p2,…,pm,计算集合 SL={distinct|pi|,1≤i≤m},有SL=L,则 SL 可进一步记为 SL={l1,l2,…,lL}。令 SL={pi,|pi|=l,1≤i≤m},显然有 ∀pi∈SL,≡l,且在预处理阶段pi的状态均是未匹配的。
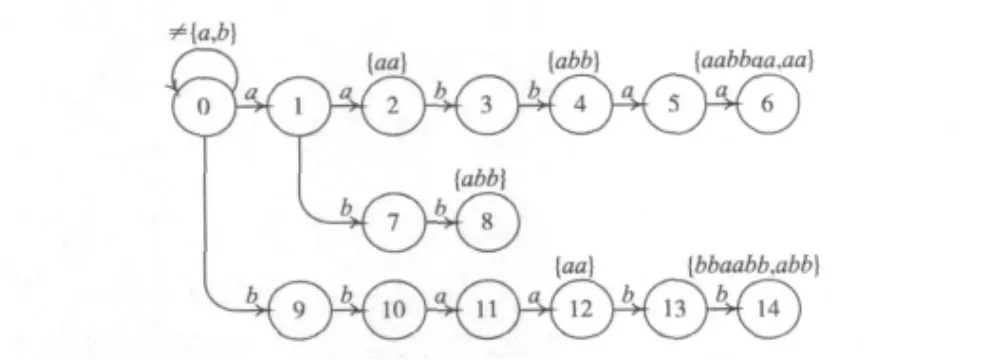
图2 模式集合P的AC自动机
令集合 Setj={pi,|pi|≥lj,1≤i≤m},1≤j≤L,这样就得到了L个相交模式集合的子集,且Setj-Set1={|pi|=lj-1},2≤j≤L。从QS算法的描述可知坏字符qsBc表定义为
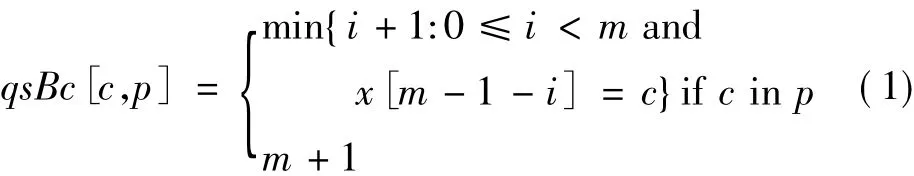
式中:c∈Σ,p为任意模式串。而在多模式匹配算法情况下shift表可定义为
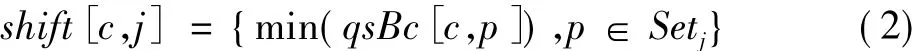
式中:c∈Σ,1≤j≤L。
设 P={aabbaa,bbaabb,abb,aa},将 P 划分为{aabbaa,bbaabb},{aabbaa,bbaabb,abb,aa},{aabbaa,bbaabb,abb}3个子集,且最大跳跃值分别为3,4和7。
此外还需要将每一个存在output输出的状态做一个标记j,决定模式串属于哪一个Setj可以加快跳跃的判断。形式描述为{j,max(|output|)=lj},其中output为节点输出的模式串集合,如果使用链表存储的话,则output指向第一个模式串,output->next指向下一个模式串,直到next域指向NULL。具体实现可以规定|output|≥|output->next|≥…≥|ε|,则有 max(|output|)=|output|。
设置所有存在output输出的节点所属的集合下标的算法采用了深度优先的遍历方式,其中δ为构建状态机后得到的状态转移函数。算法描述如下:

2.2 搜索阶段
搜索算法结合了AC算法和QS算法的技术。在QS算法中,比较窗口内比较次序可以是任意的,一旦发生了失配的情况,可根据左邻比较窗口的第一个字符决定下一个比较窗口跳跃的距离。本算法采用了由左往右的方式比较模式串,并依次读入字符实现AC状态的转移。
算法在比较的过程中,如果某个短模式的集合匹配成功,则使用在预处理中计算的新的shift表,可以预期字符跳跃距离将动态增加,并能以更高的匹配速度处理余下的文本串。算法描述如下,其中T表示目标文本串,size表示目标文本串的长度。

下面举例说明,如模式集合P={aabbaa,bbaabb,abb,aa},目标文本串T=aabbaxxxaabbaa。
第一个比较窗口初始大小为2,如图3所示。
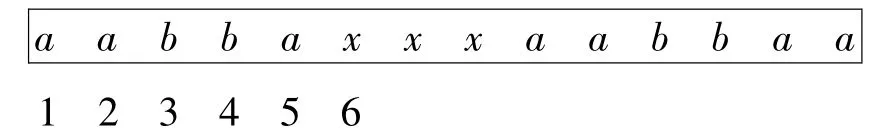
图3 比较窗口
直到遇到字符x,此时已匹配了{abb,aa},尚未匹配的模式集合为{aabbaa,bbaabb},窗口滑动 shift[x,2]=8,且窗口动态增加到6,如图4所示。
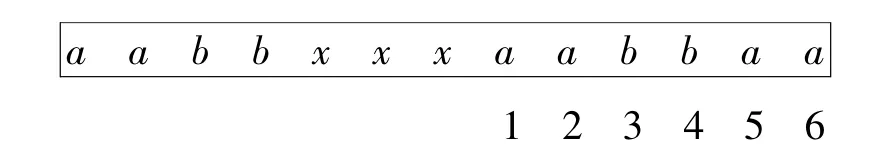
图4 比较窗口
比较一直到文本T结束,模式{aabbaa}被匹配。算法总共比较了12个字符。
3 实验分析
测试环境是编译器gcc version 4.1.2,优化开关全部打开,CPU Pentium III 800 MHz,内存为256 Mbyte,操作系统为Linux 2.6.40,测试文本T为30 Mbyte文本串。选取AC算法、去掉fail的AC算法、Wang算法、CW算法作为比较对象。
1)模式数量一定,模式长度的变化对匹配速度的影响如图5所示,图5中给出的模式数量固定为100个,可预先在模式集合中设置一些短模式串。
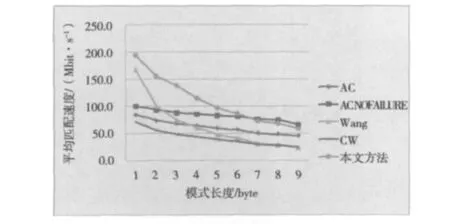
图5 不同模式长度下算法的匹配速度
2)模式长度一定,模式个数的变化对匹配速度的影响如图6所示,图6中给出的模式长度固定为10 byte。
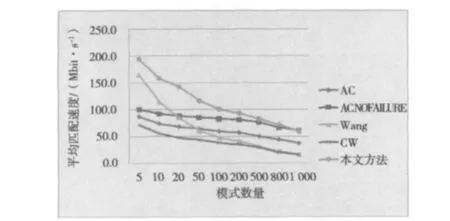
图6 不同模式数量下算法的匹配速度
测试结果证明图5在模式集合中存在长度较短的模式情况时,本文的算法能够显著抵抗由此引起的性能衰减。图6验证了本算法随着模式个数的增加,匹配速度不会出现陡然恶化的情况。综合实验的结果,可以得出在大多数情况下本文的算法相比其他算法有最好的匹配速度,匹配效果不受模式数目的限制,抗短模式影响比较好。
4 多模式匹配在协议识别中的应用
通过对常见网络协议的特征进行分析或者查阅某应用层协议公开的RFC文档,提取出协议的特征信息,作为鉴别应用层协议网络数据流的标识。每种应用的分组中都携带有特定的报文信息,一般是几个字节长的固定字段,例如,SMTP协议报文中含有RCPT TO,MAIL等特征信息,根据此特征进行模式匹配,由此判断出该报文是属于哪种网络协议的应用。根据多模式匹配算法,对某种协议所具有的关键字建立一棵模式树,一个规则表示一个协议,一个规则对应一个模式集合,在文本串中通过模式匹配进行协议识别,当某个规则中的所有模式都被找到时,再继续检查报文是否满足其他如IP限制、端口限制等条件,只有这些都满足,才说明这个报文完全匹配这个规则。
5 小结
随着新的应用协议不断出现,需要不断改进模式匹配算法以提高其在协议识别中的准确性和高效性。本文主要提出了一种基于AC的多模式匹配改进算法,利用匹配过程中“坏字符”信息,尽可能跳跃更多的字符和模式匹配信息,动态增加跳跃的步长。这种算法能较好地抵抗短模式引起的性能衰减。本文的算法可以继续分析空间的复杂性,以及压缩状态转移表对性能的影响。
网络带宽的不断增加给网络安全技术带来巨大的挑战。协议识别作为网络安全技术的一个重点,提出了更高的要求。虽然协议识别可以采用很多技术,但模式匹配算法仍然是目前的主流协议识别技术。因此如何继续改进模式匹配来提高匹配速度,成为今后研究协议识别技术的一个关键,这里可以从以下几个方面着手:一是将各种模式匹配算法相结合;二是模式匹配算法与其他智能方法的结合;三是对模糊匹配的深入研究。
[1]杨明,孙洪峰.信息与因特网络安全防范技术[J].电视技术,2003,27(1):30-32.
[2]陈亮,龚俭,徐选.应用层协议识别算法[J].计算机科学,2007,34(7):73-75.
[3]冉占军,姚全珠,王晓峰,等.模式匹配算法在入侵检测中的应用[J].现代电子技术,2009(2):63-67.
[4]AHO A C,CORASICK M J.Efficient string matching:an aid to bibliographic search[J].Communications of the ACM,1975,18(6):330-343.
[5]COMMENTZ-WALTER B.A string matching algorithm fast on the average[C]//Proc.6th ICALP.[S.l.]:IEEE Press,1979:118-132.
[6]FAN J J,SU K Y.An efficient algorithm for matching multiple patterns[J].IEEE Transactions on Knowledge and Data Engineering,1993,5(2):339-351.
[7]王永成,沈州,许一震.改进的多模式匹配算法[J].计算机研究与发展,2002,39(1):55-60.
[8]NORTON M.Optimizing pattern matching for intrusion detection[EB/OL].[2006-05-11].http://docs.idsresearch.org./Optimizing Pattern-MatchingForIDS.pdf.
