失重法飞灰测碳仪实测预测组合模型
2012-06-23郑圣鹏解海龙
王 鹏,郑圣鹏,解海龙
(1.东北电力大学能源与动力工程学院,吉林 吉林 210006;2.福建省计量科学研究院,福建 福州 3500033.东北电院开元科技有限公司,吉林 吉林 210006)
1 概 述
利用飞灰含碳量的在线监测数据调节煤粉炉的燃烧,历来是提高电站锅炉运行经济性的重要手段。在众多检测方法中,主要可概括为微波法和失重法这2种类型。微波法误差较大,受变工况的影响大,而失重法是被普遍认可的经典测量方法,基于该方法的在线监测系统,目前已应用于生产,但是,其可靠性和使用寿命问题严重影响了该系统的推广使用。该系统的执行机构需进行采样、灼烧、称量、清灰等一系列反复动作,加之这套系统需在极其恶劣的条件下工作,所以长期可靠的运行是非常困难的;同时,灼烧炉加热元件的氧化,飞灰分离装置的堵塞,机械零部件的磨损,高温多尘环境下对电子称量装置的干扰,也是影响其使用寿命的重要原因。所以整合可靠的软件和硬件控制显得势在必行。现将LVQ神经网络的自适应分类法和BP网络的非线性拟合并结合数据库技术,应用到灼烧失重法飞灰含碳量在线监测系统中,通过采集和积累大量的实测飞灰含碳量数据及其相关运行参数,通过LVQ网络将热力数据划分大类及子类,使用BP网络进行预测与飞灰测碳仪实测相结合的控制模式,仿真结果表明,整套模型预测精度能够满足工程精度要求。在硬件的控制方面,因加入了软件预测系统,能逐渐减少机械系统的动作频率,延长了整个系统的使用寿命。
2 失重法飞灰测碳仪模型
失重法的在线飞灰测碳原理是基于中国电力工业标准《飞灰和炉渣可然物测定方法》和《煤的工业分析方法》。当含有未燃尽碳的飞灰经高温灼烧后,由于灰样中残留的碳被燃尽,使灰样的质量出现了损失,利用灰样的烧失量作为依据,计算出灰样中的含碳量。该装置解决了测量结果受煤质变化影响的问题,也解决了实验室飞灰含碳量化验值无法及时的反映机组运行当前状态的问题[1]。
现设计了飞灰测碳仪模型,如图1所示,上位机与就地控制单元进行通信,就地控制单元将指令发送至执行机构,采用多点无外加动力的自抽式取样器,自动地将烟道中的灰样收集到采样机构的坩埚中,再由灼烧单元(包含灼烧炉和灼烧机构)内部的执行机构,将装有灰样的坩埚送入灼烧炉进行高温灼烧,灼烧结束后,系统将对收灰前、收灰后及灼烧后所称得的重量信号,送入信号分析单元进行数据计算,将处理结果(实时监测值)经过串行通讯电缆送入DCS以及计算机单元,灼烧后的灰样通过系统的排灰装置返回烟道,然后进行下1次飞灰的取样和含碳量的测量。
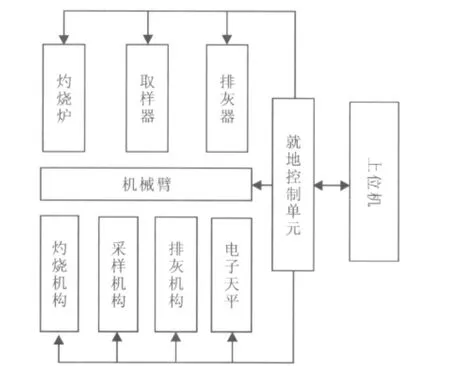
图1 失重法飞灰测碳结构模型
3 神经网络软预测控制模型
3.1 神经网络原理
人工神经网络理论从建立发展至今,主要存在几种网络:(1)基于非线性拟合的数学模型网络;(2)联想网络;(3)竞争网络。其他的神经网络多为这几种网络功能的组合。BP神经网络作为非线性拟合的代表网络,也称误差反向传播算法。它通过神经网络计算输入样本所对应的输出值,再将输出值与期望值进行误差分析,依照误差值来反复修正权值,从而使网络的输出接近所希望的输出值;LMBP算法是BP权值更新算法-牛顿法的变形,它采用了雅克布矩阵来近似逆矩阵,牛顿法的计算复杂且工作量大,同时吸收了最速下降法收敛快的优点,能够应用到在线预测。
LVQ网络是1种混合网络,通过有监督和无监督的学习来形成分类[2]。LVQ网络分为2层,第1层神经元将指定某个类,用于学习原型向量,对输入空间的区域进行分类,传来的分类信息在第2层中转变成使用者所定义的类别。LVQ神经网络的优势在于:它不仅能够对线性输入数据进行分类,而且还能处理多维的、甚至是含噪、含干扰的数据。实验证明,只要在各个隐层存在足够的神经元,那么目标输出的分类量将会得到相应的增加。
3.2 硬件控制方法
基于预测控制的硬件模型,如图2所示。
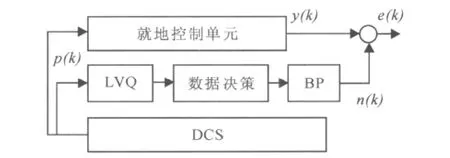
图2 硬件控制方法
上位机将电厂热力参数数据p(k)从DCS中调出并将飞灰测碳仪实测数据传输至上位机中的软件预测模型(LVQ-数据决策-BP)中,软件预测模型将数据进行分类筛选并进行预测,转换成多个不同工况下的BP神经网络预测模型,通过控制模型中输出的预测值n(k)和实测值y(k)的偏差e(k),使之逐渐停止飞灰测碳仪的动作,如实测与预测偏差e(k)较大,则重新启动飞灰测碳仪的实测,对模型进行校正,提高预测精度。
3.3 软件预测模型
文献[3]用BP网络进行了离线训练,但由于BP网络本身有着学习新样本遗忘旧样本的现象 ,加之建立BP模型所需样本数并不能无限大,数据量的增多导致其速度和精度的明显降低,小范围的数据量所建立的模型,必然不适用于飞灰含碳量的预测,所以其并不完全适用于在线预测的控制,现提出1种BP神经网络辅以LVQ网络进行预测的方法,其软件模型和运算步骤如下:
(1)通过DCS和飞灰测碳仪获得电厂热力参数以及飞灰含碳量样本集P = {p1,p2,...pq}。
(3)将参数pi输入进LVQ网络进行训练,对相似度判断:=--,对任意ni有≥;j≠i,则输出pi,进入第2层线性网络,利用Kohonen规则对LVQ网络竞争层进行训练,若==1则用下式训练:i*w1(q)=i*w1(q-1)+α(p(q)-i*w1(q-1)))若=1≠tk* =0,则用下式训练[4]:i*w1(q)=i*w1(q-1)-α(p(q)-i*w1(q-1)))。
(4)对于训练完成的子类将其数据输入至BP神经网络进行训练,得到各子类下的BP预测模型。对于预测值和实测值误差超出设定范围的类,转步骤5。
4 模型仿真
(1)子分类数的选取
为了确定每个类下子类的数据量,用数学手段进行了仿真,根据现场飞灰含碳量数据的变动,将输出选取了式(1)作为目标模型:
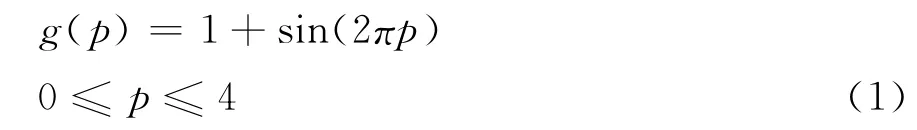
该模型曲线的变化能够满足锅炉飞灰含碳量频繁的变化,其中p为输入向量,g(p)为目标输出向量,分别选择了25和50的样本数作为检验,神经元的数量根据误差要求可自适应调节,结果如图3、图4所示。
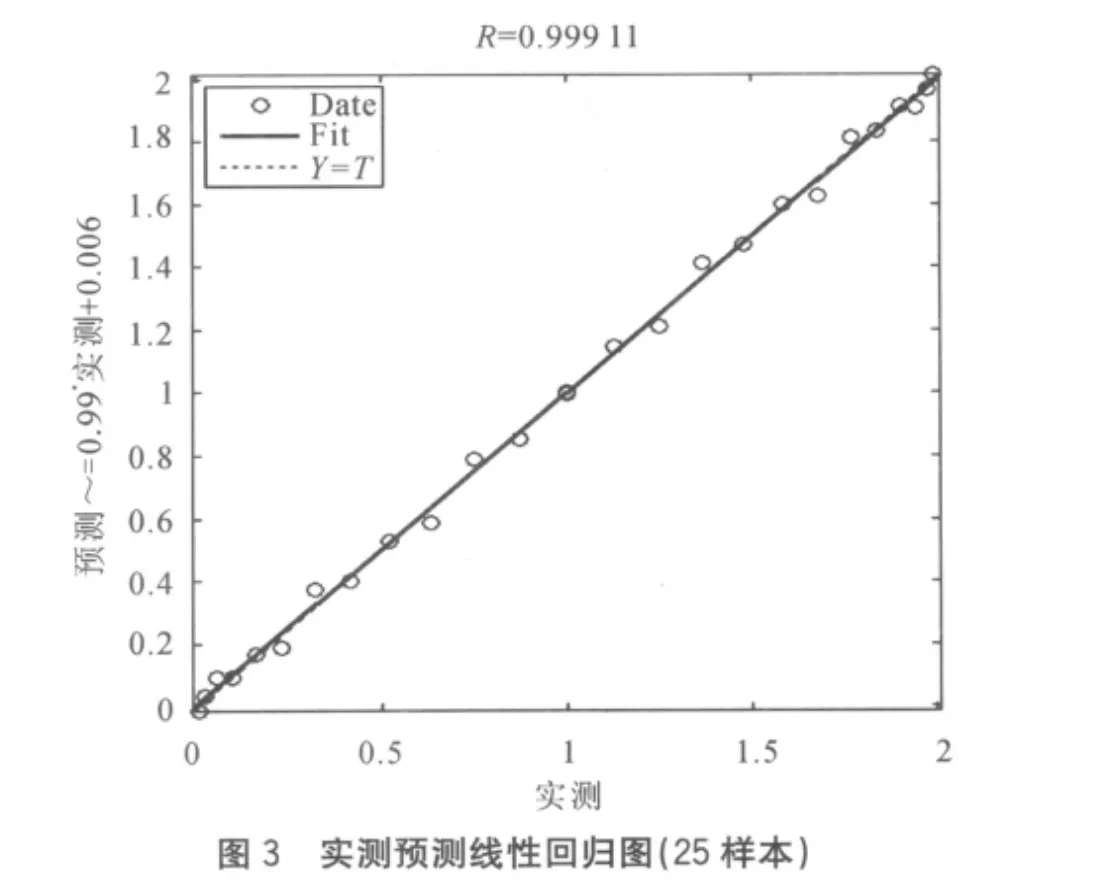
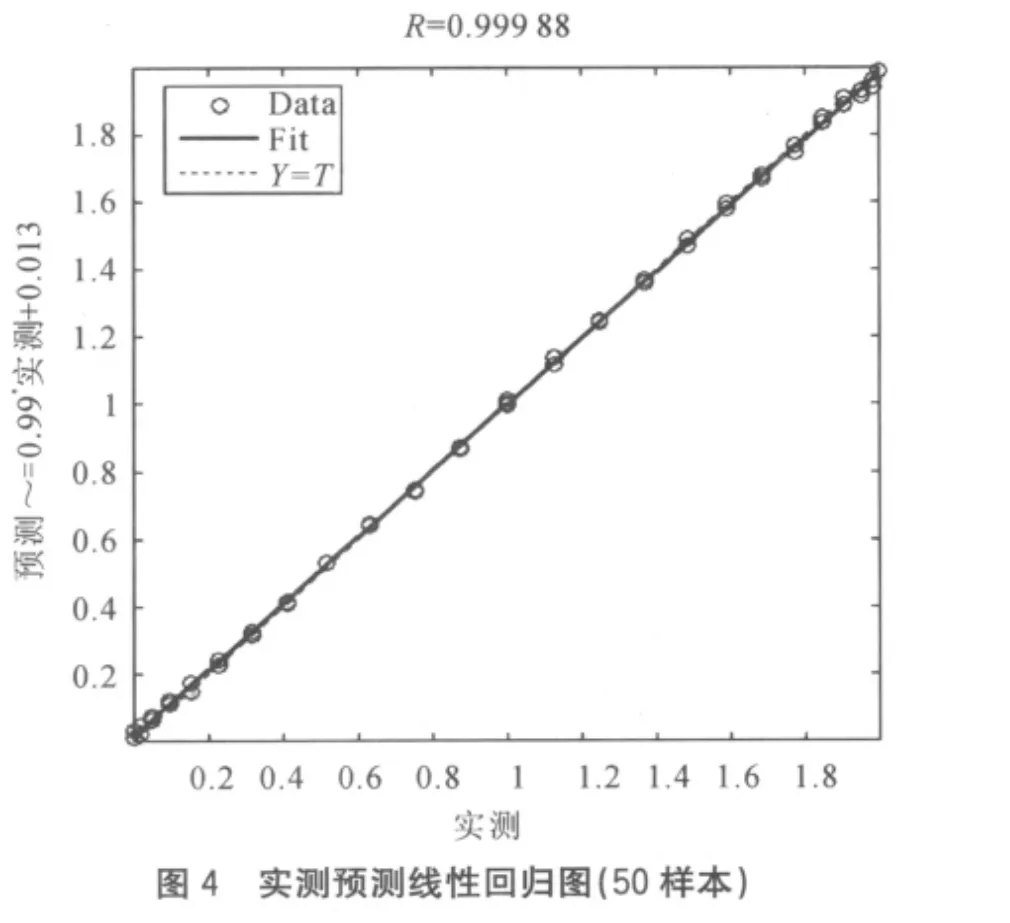
训练所用的神经元结构经调校后均为1-10-1,50个样本相对于25样本的预测结果,在神经元数量足够多的情况下总体误差相差不大,但是个别数据误差较大,最小相对误差分别为0.045%和0.069%,最大相对误差分别为20.81%和87.6%。而最大相对误差通常发生基数较低的区域,当数据量提高到200时,预测最大相对误差为5%,这表明在图形的复杂程度一定,数据分布较为均匀的的情况下,预测精度和数据量成正比。
确定了每个类下的子分类数,按某600MW机组的运行特性,将测试数据按负荷区间段分为5个类进行训练,分别为 BMCR,75%BMCR,50%BMCR,最低负荷,高加切除;各负荷区间段为一类,前述仿真试验表明,选择200的子类数进行预测能够满足工程误差精度要求。根据子类数设定好预定分类权值并输入LVQ网络进行训练,结果如图5所示,为LVQ网络分类的ROC性能曲线,其中横坐标为误判率,即为实际分类为假值判定为真值的概率,纵坐标为灵敏度,表示实际分类为真值判定为真值的概率,曲线下方与横坐标轴的所包围的面积表示变量对因变量的判定效果,面积越大,表示分类效果越好,图5中所包围的面积接近于1,说明训练后的模型对于按负荷范围分类的效果较好,几乎很少存在误判,这表明对于多维变化且较为复杂的输入,按负荷范围对其分类是可行的。
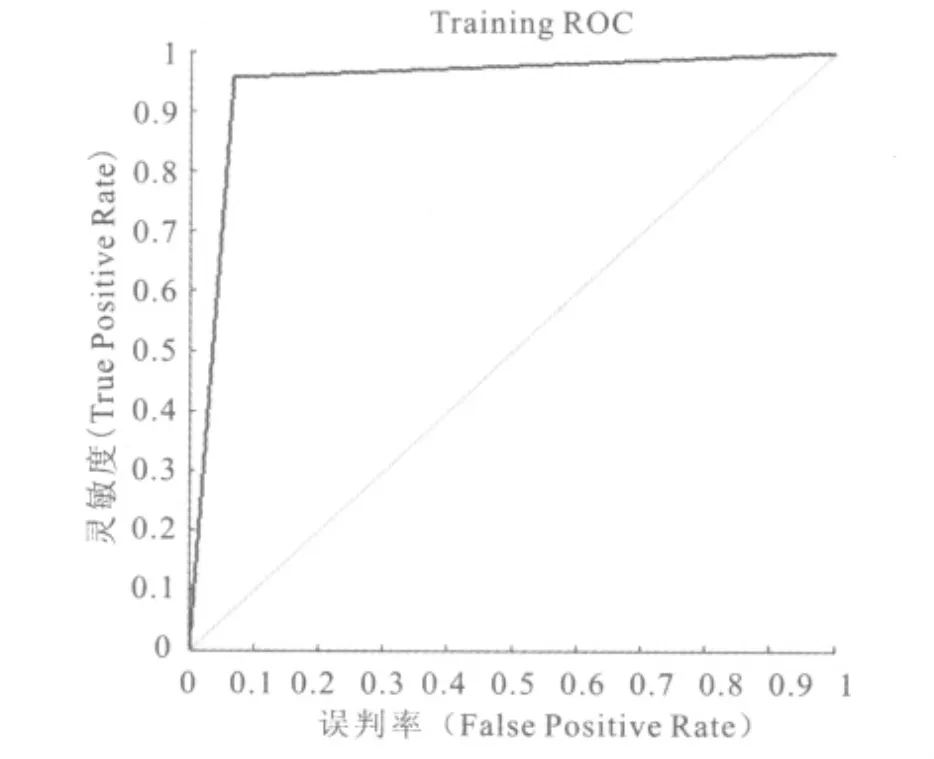
图5 LVQ ROC性能曲线
表1是选取了经过LVQ分类以及BP网络预测后的实测与预测部分数据,共10组,前5组以及后5组分别代表了BMCR和75%BMCR工况,ΔC/%表示了当前样本在各组工况下实测和预测的相对误差,分析数据可得全局预测,BMCR负荷和75%BMCR负荷的数据预测,具有更高精度,最大相对误差分别为36.93%和2.36%。对于相同工况点的预测,如样本8和样本10所示,其相对误差分别为36.93和0.92%以及13.12%和2.36%,同时还可以看出75%BMCR的平均相对误差比100%BMCR的平均相对误差稍高,表1数据充分表明了现使用模型的预测精度较高,数据稳定,个别不稳定点如样本10,需要不断地学习以提高数据稳定性和精度。
综上所述,该模型对数据进行实时分类,并结合飞灰测碳仪实时获取飞灰含碳量,及时地对模型进行训练,保证了模型的实时性和准确性,模型对飞灰含碳量预测所产生的数据文件存储于上位机中,在飞灰测碳仪运行时,通过labview调用dll文件接口与上行DCS以及下行就地控制单元进行通讯,主程序隔5 min访问1次DCS,以便实时地获取电厂热力参数,得到较为精准的飞灰含碳量预测值,从而逐渐减少了飞灰测碳仪的动作次数,延长了其使用寿命。
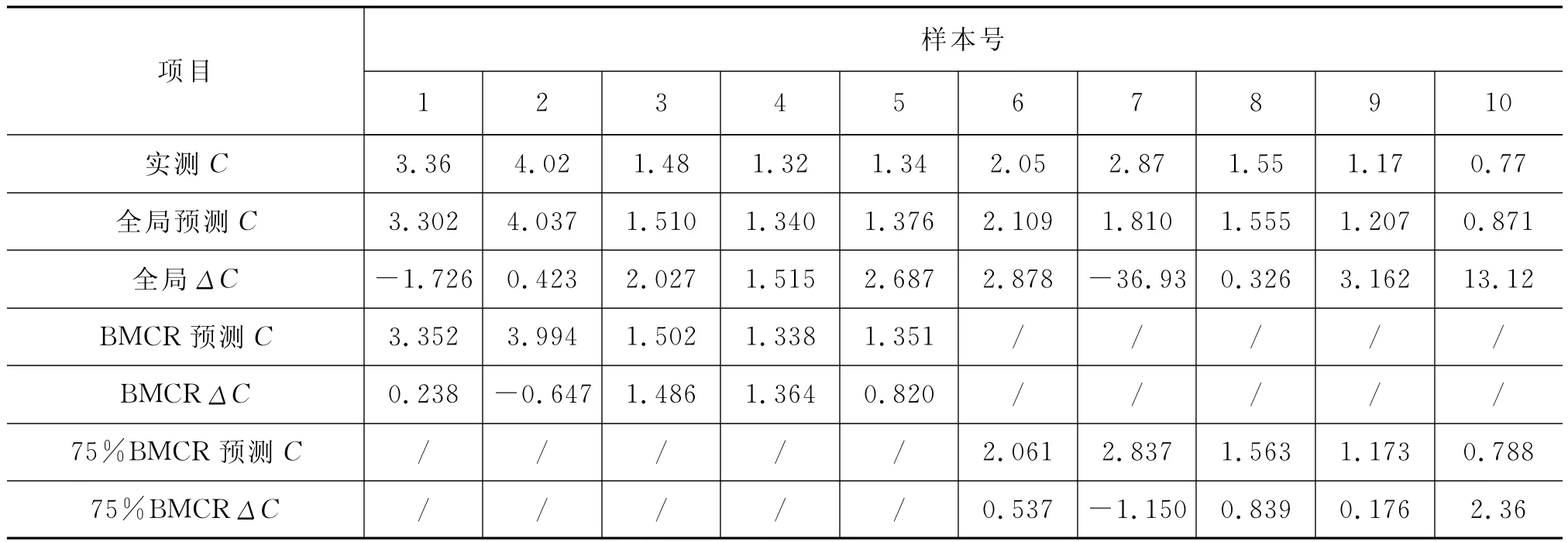
表1 各工况实测和预测飞灰含碳量数值比较
5 结 语
分析了影响飞灰测碳仪使用寿命的因素,设计了预测与实测相结合的软、硬件控制模型,并用仿真法确定了数据分类后各大类中子类的数据量。仿真结果表明,相较于传统BP全局预测模型,该模型的分类效果好,预测精度较高,能够逐渐训练并逐步替代飞灰测碳仪的实测,减少其动作次数,为失重法飞灰测碳仪的可靠稳定运行提供了保证。
[1]刘鸿,周克毅.锅炉飞灰测碳仪的技术现状和发展趋势[J].锅炉技术,2004,35(2):65-68.
[2]Martin T.Hagan,Howard B.Demuth,Mark H.Beale:Neural Network Design[M],PWS Publish Company.1996.
[3]周昊,朱洪波,曾庭华,岑可法,等.基于人工神经网络大型电厂飞灰含碳量建模[J].中国电机工程学报,2002(6):96-100.
[4]Hechi Nielsen R.Theory of the back propagation neural network[M].Proc of IJCNN,1989,593-603.
