基于NMF的SVM故障诊断方法
2012-06-22李建宏姜同敏
李建宏 姜同敏
(北京航空航天大学 可靠性与系统工程学院,北京100191)
何玉珠 蒋觉义
(北京航空航天大学 仪器科学与光电工程学院,北京100191)
支持向量机(SVM,SupportVector Machine)[1-4]在小样本条件下具有良好的学习能力,能较好地实现对线性、非线性样本数据的学习和分类,应用于故障诊断中具有独特优势.实际诊断时,如果故障征兆输入量数目过多,训练复杂度及过拟合度都会大大增加,对于复杂高维特征系统,由于故障特征存在冗余,会影响样本训练和分类诊断的效率,并导致诊断准确率下降,如何从高维状态特征中获得敏感特征成为当前研究的瓶颈之一.文献[5]提出的非负矩阵分解(NMF,Nonnegative Matrix Factorization)是一种新的数据分析和处理方法,倾向于局部特征的抽取,具有存储容量小、迭代简单等特点,已经在图形处理、人类自然语言的处理研究中得到广范应用[6].
本文提出基于NMF的SVM故障诊断方法,通过NMF对SVM的样本数据进行预处理,解决故障诊断中高维特征选取困难和特征降维过程中NMF结果不确定性问题,改善分类效果.
1 支持向量机
1.1 非负矩阵分解
NMF是一种多变量分析方法.实质是对由非负数据构成的矩阵Amn,寻找2个非负矩阵Bmr和Hrn,使Amn可以近似地分解成这2个矩阵的乘积,即

一般(n+m)r<nm,原矩阵中的某一列向量可对应为分解后左矩阵中所有基向量的加权和[7],权重系数为右矩阵中对应列向量中的元素;基于简单迭代计算的NMF具有收敛速度快、矩阵存储空间小的特点,适用于大量数据的表示分解.
1.2 支持向量机
SVM的核心思想是构建一个最大间隔的分类超平面[8],使两类样本分布于分类面两边.
标准SVM是对线性可分的两类样本,寻找一个既能使两类样本正确分开,又保证分类间隔最大的最优分类面.两类样本为

其中,l为训练样本总数;n为样本空间的维数;xi为样本空间向量;yi为样本的类别标志.分类超平面为w·x+b=0如图1所示,其中w为最优超平面的法向量;b为偏置;R1和R2分别为x的第一维和第二维的取值.

图1 最优超平面
对于线性可分的情况,最优超平面的求解问题归结为(2)式的约束优化问题[9]:
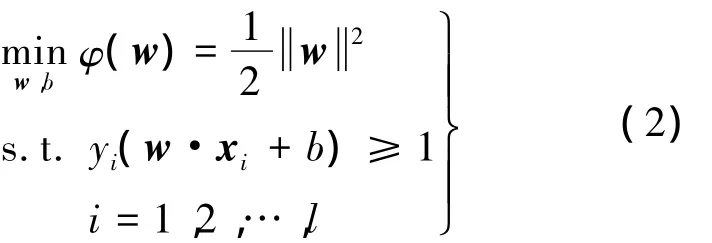
式(2)的求解通过定义Lagrange函数,把构建最优超平面的问题转化为如式(3)对偶二次规划问题:

最终的最优分类面函数表示为
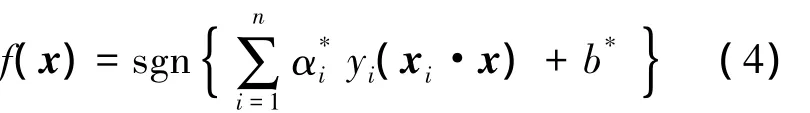
2 基于NMF的SVM故障诊断
基于SVM的故障诊断一般分为样本训练和故障诊断两个阶段[10],上述过程若直接引入高维故障特征,会影响分类器的分类速度和精度.基于NMF的SVM故障诊断通过NMF进行特征提取和数据降维,用降维后的样本特征训练SVM分类器.故障样本诊断时,对故障特征做相同尺度的降维和特征提取,用训练好SVM分类器进行故障辨识.
1)根据诊断对象对故障模式分类,获取不同故障模式的特征,并将故障特征表示成多维特征矩阵的形式.
2)对故障特征进行NMF.设故障特征矩阵为Amn,分解用迭代方法交替求解矩阵 Bmr和Hrn,本文采用如式(5)的目标函数:

其中,Ymn=BmrHrn;aij,yij分别为 Amn,Ymn中的元素,Amn的NMF分解演变为求解矩阵Bmr和Hrn,使得目标函数(5)的离散度最小.按式(6)的规则迭代,可确保Bmr和Hrn局部收敛到最优解.
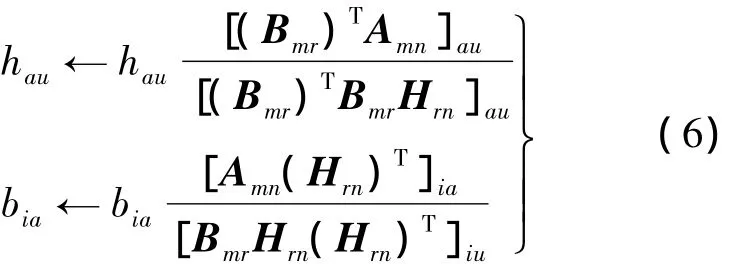
其中,hau,bia分别为迭代过程中的 Bmr和 Hrn元素.
由于r满足条件(n+m)r<nm,Bmr和Hrn所有元素个数小于Amr中元素个数,实现了原始矩阵的降维.
3)样本特征矩阵Bmr中的行向量作为SVM的训练集,选择核函数和惩罚参数训练SVM,得到SVM的分类器.
4)求解待诊断样本的降维特征向量.由于训练样本的NMF分解与故障样本特征降维过程是分开的,而NMF分解时Bmr和Hrn初值的选择具有随机性,即使在相同离散度的条件下,每次分解所得的Bmr和Hrn都不相同,故不能直接将故障样本直接进行r维分解.本文提出利用训练样本系数矩阵求解超定线性方程组的方法得到相同尺度降维的待诊断样本特征.
设待诊断样本为 Q,Q=(q1,q2,…,qn),特征维数与训练样本同为n维,训练样本矩阵Amn=(aij)mn写成m行n列矩阵并分解为Bmr和Hrn表示为

其中
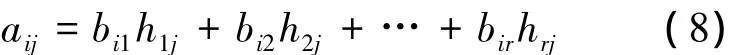
把Q作为第m+1行代入Amn,作为新矩阵A(m+1)n进行r维分解,Hrn保持不变,得到m+1行的降维矩阵 B(m+1)r,A(m+1)n与 B(m+1)r及 Hrn关系表示为

其中

由式(8)、式(10)可知 Amn中的元素只与B(m+1)r的值和Hrn有关,待诊断样本第m+1行的元素只与样本降维后的特征向量(第m+1行)和Hrn有关.
待诊断样本的分解结果表示为
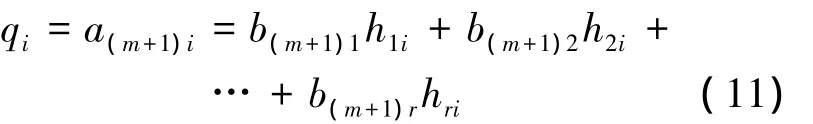
由式(10)、式(11)得到线性方程组:

即

把式(13)写成为H'T=Q',其系数矩阵H'是训练样本的分解后矩阵Hrn的转置,Q'是待诊断样本Q的转置,待诊断样本降维后的特征是线性方程组H'T=Q'的有效解T.方程组的参数n为降维前样本维数,r为降维后样本维数,由于n≥r,该方程组为超定线性方程组,可求得最小二乘解.
5)列向量T转置为行向量,代入训练好的向量机分类器进行诊断,得到分类结果.
3 基于NMF的SVM诊断实例
图2所示为有源带通滤波器,元件标称值分别为 R1=1 kΩ,R2=3 kΩ,R3=2 kΩ,R4=R5=4 kΩ,C1=C2=5 nF.

图2 有源带通滤波电路
设电阻、电容具有5%的容差,元件值在容差范围内变化,电路为正常状态.电路为带通滤波器,中心频率为25 kHz,带宽50 kHz.电路幅频响应如图3所示.

图3 滤波电路幅频响应曲线
电路响应与输入信号频率有关,故把不同频率的交流响应作为故障特征.分别以R1=1 Ω代表R1短路硬故障,R1=0.5 kΩ代表R1向下偏移标准值50%的软故障,R2=1 Ω代表R2短路硬故障,R2=4.5 kΩ代表R2向上偏移标准值50%的软故障,R3=1 kΩ代表R3向下偏移标准值50%的软故障,R3=100 MΩ代表R3断路硬故障,分别以 b,c,d,e,f,g 表示,电路正常状态以 a 表示.通过Multisim对电路分别进行100次Monte Carlo仿真获得每个状态的响应曲线,从1 kHz到1 MHz频段上依次非等分的选取 1,1.25,1.5,2,2.5,3.1,4 kHz等31个频率响应点作为诊断的原始特征值,如表1所示.
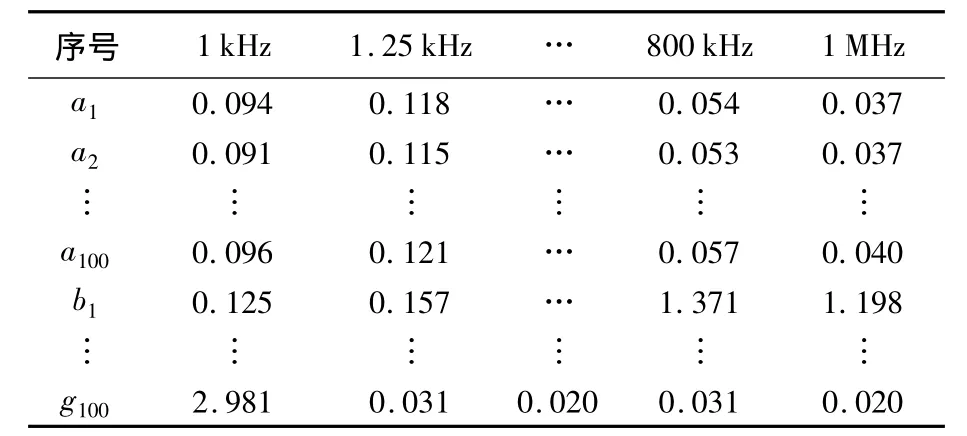
表1 原始特征数据表
把上述数据以不同频率的响应值为行向量,建立故障特征矩阵,选择合适的维数r进行NMF分解,当r=9时得到Bmr和Hrn,对应的故障类型如表2.Bmr各行向量作为特征代入SVM进行训练,得到分类器,本文选用线性核函数,惩罚参数C选为10.
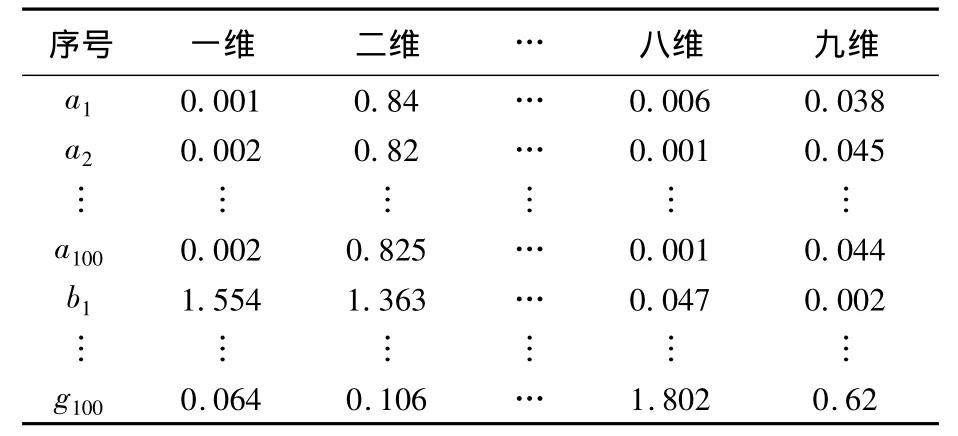
表2 降维后特征数据表
对电路所选故障类型重新进行Monte Carlo仿真得到Q,求解线性方程组H'T=Q,获得待诊断样本的降维特征.
把降维后的特征向量带入训练好的向量机分类器进行分类诊断,得到分类结果.该方法与普通SVM诊断结果比较如表3.

表3 两种方法诊断结果比较
从表3可以看出,与普通SVM诊断结果相比,通过NMF降维后的诊断缩短了样本训练和分类时间,提高诊断效率,也取得更好的诊断效果.
4 实验结果
实验选取某型反舰导弹常见的17种故障作为样本,每种故障有45个主要特征,训练样本集为300个45维的向量.SVM采用一对一的策略进行多类模式分类,核函数选为径向基函数:

参数 σ=1.98,惩罚因子 C=150,SVM 采用分解训练算法.
分别用 SVM、基于粗糙集的 SVM(RSSVM)[11]以及基于NMF的SVM 3种方法对样本进行分类诊断,结果如表4.
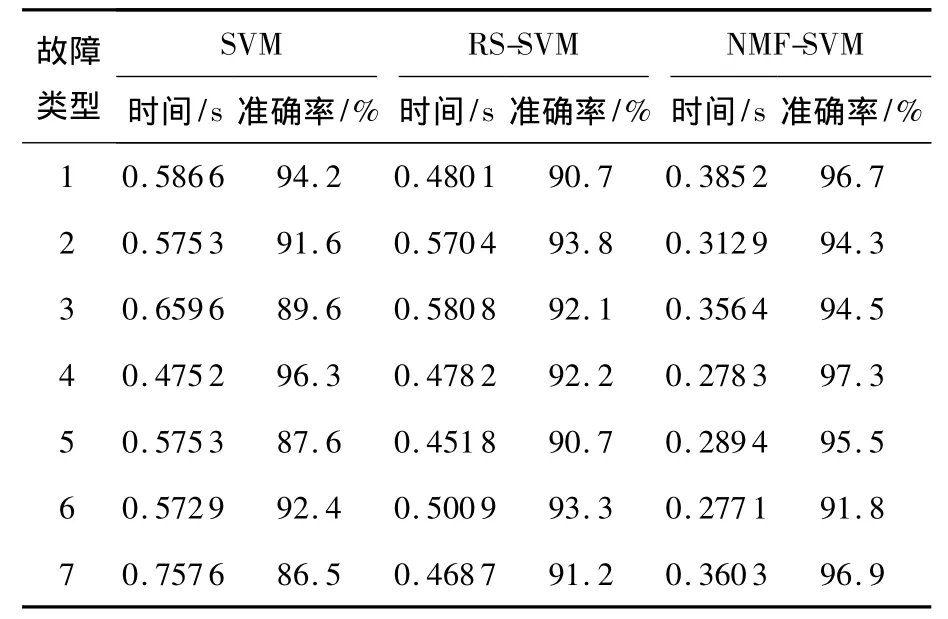
表4 故障诊断方法比较
表4给出了3种故障诊断方法对前7种故障模式的诊断比较结果,可以看出NMF-SVM方法具有更快的诊断分类速度,准确率也要好于其他两种方法.
5 结论
NMF和SVM的理论及应用都是当前研究的热点,基于NMF的SVM故障诊断方法,利用NMF迭代简单、容易收敛的特性,实现特征抽取,降低了计算复杂度,并克服诊断样本NMF分解不确定性问题.应用于某型反舰导弹的故障诊断中,降低了训练及诊断样本故障特征维数,缩短训练和诊断时间,简化了诊断过程,相对其他诊断方法具有较高的诊断准确率,证明应用该方法对高维特征系统进行降维诊断的有效性.
References)
[1]Vapnik V N.统计学习理论的本质[M].北京:电子工业出版社,2009 Vapnik V N.The nature of statistical learning theory[M].Beijing:Electronic Manufacture Press,2009(in Chinese)
[2]Yang Chanyun,Yang Jrsyu,Wang Jianjun.Margin calibration in SVM class-imbalanced learning[J].Neurocomputing,2009,73(13):397-411
[3]Yeom Honggi,Jang Inhun,Sim Kweebo.Variance considered machines:modification of optimal hyperplanes in support vector machines[C]//IEEE International Symposium on Industrial E-lectronics.Seoul:IEEE,2009:1144-1147
[4]Fung G,Mangasarian O L.Proximal support vector machine classifiers[C]//Proceedings of the Seventh ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York:ACM,2001:77-86
[5]曹胜玉,刘来福.非负矩阵分解及其在基因表达数据分析中的应用[J].北京师范大学学报:自然科学版,2007,43(1):30-33
Cao Shengyu,Liu Laifu.Non-negative matrix factorization and its applications to gene expression data analysis[J].Journal of Beijing Normal University:Natural Science,2007,43(1):30-33(in Chinese)
[6]陈清华,陈六君,郑涛,等.基于非负矩阵分解方法的汉字基本部件识别[J].计算机工程与应用,2008,44(29):76-78
Chen Qinghua,Chen Liujun,Zheng Tao,et al.Base component discovery from Chinese characters by NMF methods[J].Computer Engineering and Applications 2008,44(29):76-78(in Chinese)
[7]张磊,冯晓森,项学智.基于非负矩阵分解的中文文本主题分类[J].计算机工程,2009,35(13):26-27
Zhang Lei,Feng Xiaosen,Xiang Xuezhi.Topic classification of Chinese document based on NMF[J].Computer Engineering,2009,35(13):26-27(in Chinese)
[8]邓乃扬,田英杰.数据挖掘中的新方法——支持向量机[M].北京:科学出版社,2004
Deng Naiyang,Tian Yingjie.A new method of data mining:SVM[M].Beijing:Science Press,2004(in Chinese)
[9]孙永奎.基于支持向量机的模拟电路故障诊断方法研究[D].成都:电子科技大学自动化工程学院,2009
Sun Yongkui.Study on fault diagnosis in analog circuits based on support sector machine[D].Chengdu:School of Automation Engineering,University of Electronic Science and Technology of China,2009(in Chinese)
[10]胡国胜,钱玲,张国红.支持向量机的多分类算法[J].系统工程与电子技术,2006,28(1):127-132
Hu Guosheng,Qian Ling,Zhang Guohong.Survey of multiclassification algorithms based on support vector machine[J].Systems Engineering and Electronics,2006,28(1):127-132(in Chinese)
[11]张建明,曾建武,谢磊,等.基于粗糙集的支持向量机故障诊断[J].清华大学学报:自然科学版,2007,47(S2):1774-1777
Zhang Jianming,Zeng Jianwu,Xie Lei,et al.Fault diagnosis based on RS and SVM[J].Journal of Tsinghua University:Sience and Technology,2007,47(S2):1774-1777(in Chinese)
