一种融合流形学习的视频人脸性别识别改进算法
2012-06-13张丹
张 丹
(中国西南电子技术研究所,成都 610036)
一种融合流形学习的视频人脸性别识别改进算法
张 丹
(中国西南电子技术研究所,成都 610036)
如何有效利用视频中人脸之间的时空连续性信息来克服人脸分辨率低、图像尺度变化大和姿态、光照变化以及遮挡等问题是视频人脸识别的关键所在。提出了一种基于流形学习的视频人脸性别识别算法。该算法不仅可以通过聚类融合学习来挖掘视频内在的连续性信息,同时能发现人脸数据中内在非线性结构信息而获得低维本质的流形结构。在UCSD/Honda和自采集数据库上与静态的算法比较结果表明,所提算法能够获得更好的识别率。
视频人脸性别识别;流形学习;聚类融合;保局投影;支持向量机
1 引 言
人脸性别识别一直是模式识别和机器学习领域一个长期研究的热点问题,当前已经取得了巨大的发展。在特征提取方面,比较成熟算法有主成分分析法(Principal Component Analysis,PCA[1-2])、线性分类判别(Linear Classification Discriminant,LDA)[2]和保局投影算法(Locality Preserving Projections,LPP)[3]。对于像人脸数据这样的高维非线性数据,如何将高维数据有效地表示在低维空间中,并由此发现其内在流形结构是高维信息处理研究的关键问题[4]。LPP算法是拉普拉斯特征映射(Laplacian Eigenmaps,LE)的线性逼近,在剧烈降维方面有很好的效果,可以发现人脸数据的本质低维流形结构。在分类匹配方面,比较成熟的有最近邻分类器、支持向量机(Support Vector Machine,SVM)[5]和Adaboost[6]分类器。SVM致力于小样本高效分类,Adaboost则侧重实时应用。
由于诸如视频聊天的盛行和摄像头的普遍使用,使得视频成为最主要的媒体介质,因而在近几年来基于视频的人脸识别[7-8]中得到了广泛的关注。视频序列不同于静态图片,是由很多时空连续的图片有机地组合而成的,具有其独特性。如果以静态方法来处理这些视频序列图片,必然会忽略隐藏在视频中的时空连续性信息,而这些信息往往对于提高视频人脸识别效果会有很大影响。作为视频人脸识别的延伸,性别的分类也受到广泛的关注,在很多领域都需要实现其自动化。当前已存在很多基于视频的人脸性别识别算法,如文献[9-10]都试图将一段视频作为一个整体来进行识别。
本文在流形学习的基础上提出了一种视频人脸性别识别算法(Video-based Face Gender Recognition,VG-LPP)。该算法首先对一段视频帧采用聚类方式(Clustering)来构建数据模型以挖掘出视频人脸中的时空连续性信息,再利用保局投影算法通过近邻图来发现低维流形人脸子空间以得到人脸数据的本质低维流形结构,最后用支持向量机进行分类匹配。
2 相关工作
这一部分将介绍保局投影和支持向量机的原理,前者用于人脸数据特征提取,后者用于人脸匹配分类。
2.1 保局投影
保局投影是拉普拉斯特征映射的线性逼近,可以用谱图理论来阐述。
给定如下数据点{x1,x2,…,xm},(m∈xi∈Rn),接着我们用一个权图 G=(V,E)来模拟人脸空间的局部几何结构,图中的边表示其两端的点式满足相邻条件。为了使映射后的点距离足够近,假设这个映射为y={y1,y2,…,ym},找到这个最佳映射的合理办法是使公式(1)所示损失函数值为最小:
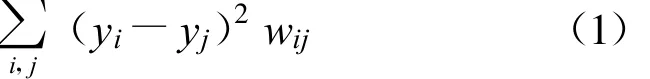
如果将这个映射限定为线性映射yi=α·xi(α为变换矩阵),那么公式(1)就可以转换为

式中,L=D-S为拉普拉斯矩阵,D是对角权矩阵。Dii=∑jwij,同时限定条件:

公式(3)最小值问题用拉格朗日乘数法求解转化为

2.2 支持向量机
支持向量机是基于结构风险最小化的一种方法,有别于传统机器学习的经验风险最小化,因其推广能力较差。支持向量机在解决小样本、非线性及高维模式识别问题中表现出许多独特的优势,并能够推广应用到函数拟合等其他机器学习问题中。
下面以两类分类为例,假设已知数据集D={(x1,y1),…,(xl,yl)},yi∈{-1,1}可以被一个超平面w·x-b=0分开。如果这个向量集合被超平面没有错误地分开,并且离超平面最近的向量与超平面之间的距离是最大的,则认为这个向量集合被这个最优超平面或最大间隔超平面分开。对于一个新数据x,它的类别由公式(5)计算所得:

支持向量机的目标是最大化间隔,损失函数如公式(6)所示:
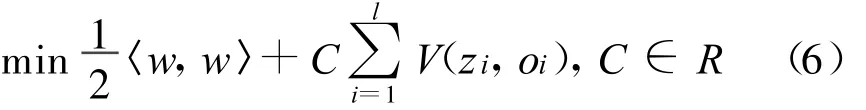
式中,oi=w·xi-b,V(z,o)是一个损失函数,定义如公式(7)所示:

3 视频人脸性别识别算法设计
如果在视频人脸性别识别中采用传统静态图片的方法,如每段视频截取 N幅图片构成视频数据库,则组成了一个无序图片组成的图片数据库,检索对比时,也分别与每幅图片进行比较。这种方法忽略了视频的完整性信息,因此视频本身的时空连续性信息就没有很好地利用。
对于传统的图片检索系统应用于视频人脸性别识别时的不足,研究人员现已在挖掘视频特有信息上做了很多工作。他们都将一段视频视为一个整体进行处理,如对视频聚类矢量化,通过比较矩阵相似度来判别和动态及概率模型等。
VG-LPP算法首先对视频数据构建数据模型来挖掘视频人脸中的时空连续性信息,再利用保局投影算法通过近邻图来构建低维流形人脸子空间,从而发现人脸数据的本质低维流形结构。下面是VG-LPP算法的详细步骤。
Step 1:视频数据建模
这一步中使用k-均值聚类算法使得同一段视频的人脸聚类,获得一个特征向量。对于一段视频,提取各个图片帧的向量数据{v1,v2,…,vn},n为视频帧数,接着使用k-均值聚类算法,对一段视频聚类分析,求得k个类别{s1,s2,…,sk}各类的均值为{μ1,μ2,…,μk}。根据各个类别的数目,对其赋予不同的权值{γ1,γ2,…,γk},这样就可以是类别多的占据这段视频的主导。最后求得这段视频的特征向量
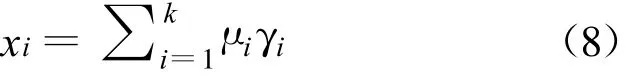
因此,整个视频库就可以获得序列{x1,x2,…,xm},m是视频总数。
使用k-均值聚类是因为每一段视频中都存在正面、侧面等不同属性的人脸,而往往正面人脸居多,侧面人脸居少。k均值聚类之后使得正面和侧面等人脸各自聚集,然后再根据数量赋权值,如此正面人脸数据将会在这段视频的特征向量中起决定作用。
Step 2:人脸特征提取
(1)创建邻接图
建立一个具有M个顶点的权图G。如果训练集已经标有类别信息的数据,xi和xj属于一个类别,那么就用一条边将这两个点连接起来,否则就用k近邻关系去寻找近邻,再用边连接起来。
(2)确定权重
这里用一种简单的方法来定义权值矩阵S,如果 xi和xj相连,则 sij=1,否则 sij=0。
(3)完成特征映射
假设公式(4)有d个特征值,按特征值 λ1>λ2>…>λd排列,对应的特征向量为 α={α1,α2,…,αd},因此低维线性嵌入可以表示为

式中,yi就是获得的低维嵌入,其维数远小于xi。
Step 3:分类匹配
这一步使用支持向量机理论来对人脸子空间的数据进行分类和预测。首先支持向量机通过训练数据获得一个分类器,其次对测试数据进行测试,完成识别功能。
4 实验分析
这部分将通过在自采集数据库上的对比试验来证明本文提出的视频性别识别算法的有效性,实验主要与静态算法(LPP、LPP-SVM)进行对比。LPP将视频帧以静态图片的形式进行处理,通过LPP进行特征提取,然后用最近邻分类器识别匹配;LPPSVM将视频帧以静态图片的形式进行处理,通过LPP进行特征提取,然后用支持向量机进行分类识别。而本文的算法首先将同一视频的人脸进行聚类处理,获得视频特征,然后用LPP进行特征提取获得低维数据,最后用支持向量机进行分类匹配。实验在UCSD/Honda和自采集视频人脸数据库上进行。
UCSD/Honda视频人脸数据库只有5位女性,为了实验的可靠性,我们从自采集数据库中加入3位女性数据,男性数据由UCSD/Honda随机取5位以及自采集的3位组成,如图1和图2所示。因此整个实验数据库有16个人,男女各半,每人有16段视频,每段视频5幅图片,实验中,每人随机取8段作为训练集,8段作为测试集,如此随机取5次构成5组实验结果,视频算法就以8×16个视频数据作为训练输入,静态算法就以5×8×16个图片数据作为训练输入。实验结果如图3所示。

图1 UCSD/Honda人脸样本Fig.1 UCSD/Honda face samples

图2 自采集人脸样本Fig.2 User-Collected face samples

图3 测试集样本存在于训练集中的实验结果Fig.3 Experiment result when test samples exist in database
实验结果表明,基于视频的算法比两个静态算法大约要高出9个百分点,说明了通过对视频人脸数据合理的数据建模,将一段视频作为一个整体进行聚类融合,能更好地保留视频信息中时空连续性语义特征,提高识别准确率。另外,由图3可发现,支持向量机做分类器较最近邻分类器有更高的识别准确率。
实验中所用的两个数据库都有正脸和侧脸,以及不同角度的光照环境,同时存在面部表情刻意变化,如此可以更好地模拟真实视频的各种环境。然而实验中训练集和测试集存在相同的人,在实际应用中待识别的人未必被收录在数据库中,因此为了更好地契合现实应用,取极端情况,即测试集数据完全不存在于训练集中。
实验随机选取男女各6人为训练库,剩下2人为测试集,如此视频方法训练集有16×12个视频数据,16×4个测试视频,静态方法就有16×12×5幅图片的训练集,16×4×5幅测试集图片。由于训练库随机选5组,因此实验结果有5组对比数据,如图4所示。
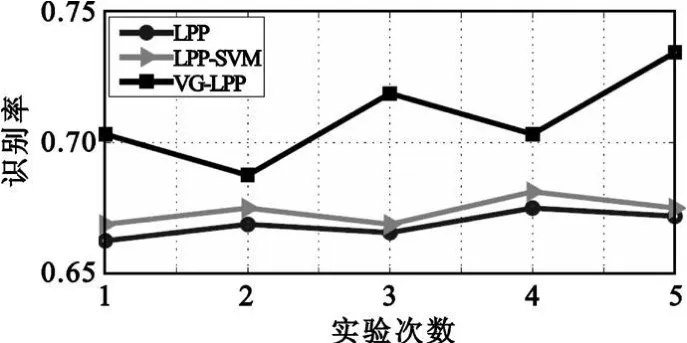
图4 训练集中不存在测试集样本的实验结果Fig.4 Experiment result when there exists no test sample in database
实验结果显示,相较于上面实验,识别准确率有所下降,这是由于训练集中不存在测试集样本,导致可获取信息降低,但基于视频的方法仍然要比静态的方法高出5个百分点,因为本算法将来自一段视频的数据看成一个整体,而不是以单独图片来处理,可以更好地保存视频内的时空连续性信息,获得更好的准确率;而LPP是以静态方式来处理视频数据,这样就破坏了视频语义信息,因此,通过合理的数据建模可以更好地实现基于视频的人脸性别识别,能更好地契合当前的发展应用。
5 结束语
对于视频人脸性别识别,本文提出了一种融合流形学习的算法,该算法不仅可以发现视频人脸序列的时空连续性语义信息并进行聚类融合,还能挖掘视频人脸数据的本质低维流形结构。与已发表过的相关研究工作相比较,作者更侧重于寻找一种合理的数据建模方法,尽量保留视频整体的语义属性。实验表明该算法较一般的静态算法能够有效地提高视频人脸的识别准确率。
这里仍然存在一些问题留待将来继续努力。比如,k-近邻法中的k值如何确定尚未解决;如何更好地构建视频人脸数据模型;这些都将是下一个阶段要继续研究的问题。
[1]Turk M,Pentland A.Face recognition using eigenfaces[C]//Proceedings of 1991 IEEE Conference on Computer Vision and Pattern Recognition.Los Alamitos,CA:IEEE,1991:586-591.
[2]Belhumeur P N,Hespanha J P,Kriegman D J.Eigenfacesvs Fisherfaces:recognition using class specific linear projection[J].IEEE Transactions on PatternAnalysis and Machine Intelligence,1997,19(7):711-720.
[3]He Xiaofei,Niyogi P.Locality Preserving Projections[C]//Proceedings of International Conference on Advances in Neural Information Processing Systems.MA:Cambridge,MIT,2004:153-160.
[4]尚晓清,宋宜美.一种基于扩散映射的非线性降维算法[J].西安电子科技大学学报,2010,37(1):30-135.
SHANG Xiao-qing,SONG Yi-mei.Nonlinear dimensionality reduction of manifolds by diffusion maps[J].Journal of Xidian University,2010,37(1):30-135.(in Chinese)
[5]Moghaddam B,Yang M H.Learning gender with support faces[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2002,24(5):707-711.
[6]Baluja Shumeet,Rowley Henry A.Boosting sex identification performance[J].International Journal of Computer Vision,2007,71(1):111-119.
[7]严严,章毓晋.基于视频的人脸识别研究进展[J].计算机学报,2009,32(5):878-884.
YAN Yan,ZHANG Yu-jin.State-of-the-Art on Video-Based Face Recognition[J].Chinese Journal of Computers,2009,32(5):878-884.(in Chinese)
[8]Wang Huafeng,Wang Yunhong,Cao Yuan.Video-based face recognition:A survey[J].World Academy of Science,Engineering and Technology,2009,60:293-302.
[9]Hadid Abdenour,Pietikäinen Matti.Manifold learning for gender classification from face sequences[C]//Proceedings of the 3rd IAPR/IEEE International Conference on Biometrics.Alghero,Italy:IEEE,2009:82-91.
[10]Demirkus Meltem,Toews Matthew,Clark James J,et al.Gender classification from unconstrained video sequences[C]//Proceedings of 2010 IEEE Conference on Computer Vision and Pattern Recognition.San Francisco,CA,USA:IEEE,2010:55-62.
ZHANG Dan was born in Shanghai,in 1984.She received the B.S.degrees and the M.S.degree in2006 and 2010,respectively.She is now an assistant engineer.
Email:8767306@qq.com
An Improved Manifold-based Face Gender Recognition Algorithm for Video
ZHANGDan
(Southwest China Institute of Electronic Technology,Chengdu 610036,China)
How to fully utilize both spatial and temporal information in video to overcome the difficulties existing in the video-based face recognition,such as low resolution of face images in video,large variations of face scale,radical changes of illumination and pose as well as occasionally occlusion of different parts of faces,has become the research focus.In this paper,a novel manifold-based face gender recognition algorithm for video(VG-LPP)using clustering is proposed,which can discover more special semantic information hidden in video face sequence,simultaneously well utilize the intrinsic nonlinear structure information to extract discriminative manifold features.Comparison of VG-LPP with other algorithms on UCSD/Honda and the author′s own video databases shows that the proposed approach can perform better for video-based face gender recognition.
video-based face gender recognition;manifold;clustering;locality preserving projection;support vector machine
TN919;TP391.41
A
10.3969/j.issn.1001-893x.2012.06.041
1001-893X(2012)06-1031-04
2012-02-28;
2011-04-17
张 丹(1984—),女,上海人,2006年获工学学位和经济学学位,2010年获软件工程硕士学位,现为助理工程师。
