一种基于SVM的Web信息自动化抽取方法
2012-06-04王亚利李晓静
王亚利 李晓静
(济源职业技术学院,河南济源 459000)
一种基于SVM的Web信息自动化抽取方法
王亚利 李晓静
(济源职业技术学院,河南济源 459000)
针对传统的Web信息抽取方法运算量大、自动化程度低的问题,提出了一种基于SVM的WEB信息自动化抽取方法。利用SVM优秀的分类性能将网页中有用数据和无用数据分类标注,有效地完成Web信息抽取任务,准确地抽取出所需信息,实现数据抽取的自动化。实验结果表明,该方法可以有效地获取网页信息特征,具有较高的召回率和准确率。
支持向量机;信息抽取;分类学习
信息抽取技术是近些年来发展起来的新领域,它是指从自然语言文档中抽取指定的事件、事实信息,并以结构化形式描述信息,以供信息查询、文本深层挖掘、自动回答问题等应用,从而为人们提供强有力的信息获取工具。当前随着互联网技术的迅速发展,Web网已经成为一个巨大的信息源,数据量呈爆炸式的增长,人们更多地开始从网络中获取所需信息。而Web页面中通常含有大量用户并不关心的如动画广告、超链接和网站版权等信息,如何从Web页面中抽取出用户感兴趣的信息已经成为当前信息领域中的研究热点之一。
支持向量机 (Support Vector Machines,SVM)技术作为统计学习理论的一种重要发展成果,因其优秀的分类性能,开始被应用到信息抽取领域中。基于SVM的Web信息抽取方法是一种综合利用网页各种特征的信息抽取方法,它通过对网页各种特征的分析将网页特征向量化,再使用SVM优秀的分类性能将网页中的每个信息片断进行分类标注,最终实现分类抽取。
1 相关理论
1.1 支持向量机
支持向量机方法是建立在统计学习理论的VC维理论和结构风险最小原理基础上的,根据有限的样本信息在模型的复杂性和学习能力之间寻求最佳折衷,以期获得最好的推广能力[1],基于SVM的机器学习方法其主要思想可以描述为:
给定样本点,考虑使用某个特征空间的超平面对给定训练数据集作二值分类问题:
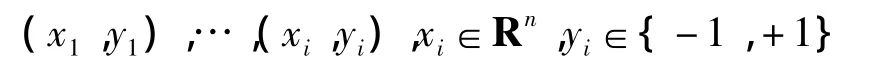
其中向量xi可能是从目标样本集中抽取的某些特征而直接构造的向量,也可能是原始向量通过某个核函数映射到核空间中的映射向量。
在特征空间中求一个分类超平面(w·x)+b=0,关键是求其系数w和b。由于SVM理论要求分离超平面具有良好的分类特性,即必须满足最优分类超平面的条件:
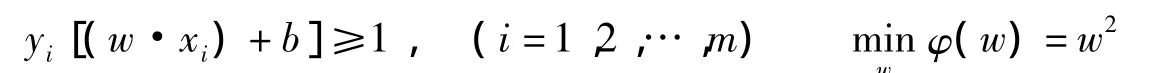
为了找到最优分类超平面,根据最优理论和借助Lagrange函数将原问题转化成为求解标注型二次规划问题:
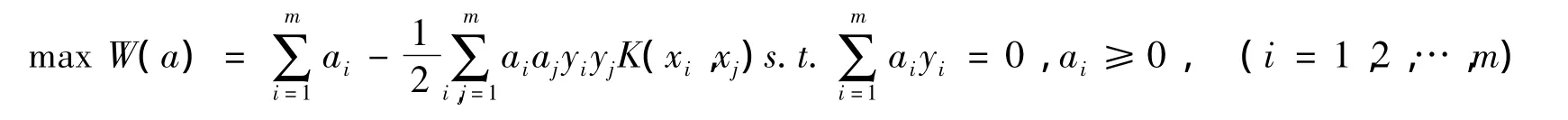
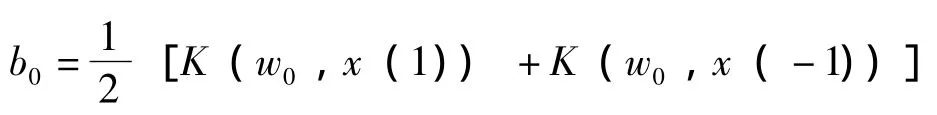
通常ai≥0对应的样本点为支持向量。
1.2 Web结构特征
Web页面主要是以HTML页面的形式出现的,HTML语言具有自身的结构特点。用HTML语言写成的源文本由不同含义的标记 (例如<Title>、<Body>、<Div>等),各种超链接、导航条等非主题信息,和文章的正文文本组成。虽然网页数据属于一种半结构化的数据,但从其结构来看通常包含有两大部分信息,即内容信息和格式信息。内容信息即是文章的正文文本,主要是通过浏览器显示给用户的信息,在内容信息中被标记分割开的块称为信息片断。格式信息即是由非主题信息组成,在网页中用于表示和解释内容信息的信息。
2 基于SVM的Web信息自动化抽取
2.1 信息抽取方法
传统的Web信息抽取方法是利用分装器对网页进行模式匹配实现数据抽取,该方法需要用户大量的标记数据进行训练学习,从而导致其自动化程度降低。本文提出以分类的方式来处理Web信息抽取问题,其主要思想是:先将网页中不同的信息片断归纳到不同的类别,然后将网页中有用数据和无用数据正确区分开,再将特征向量化的网页数据作用于SVM学习机中,最后利用SVM优秀的分类性能来实现数据的自动分类抽取。
本文提出的基于SVM的Web信息自动化抽取框架包括三个功能器:网页预处理、特征提取和数据抽取,如图1所示。从图中可以看出,在数据抽取过程中,SVM分类器是通过对样本的学习来产生分类器,进而实现数据的分类抽取。
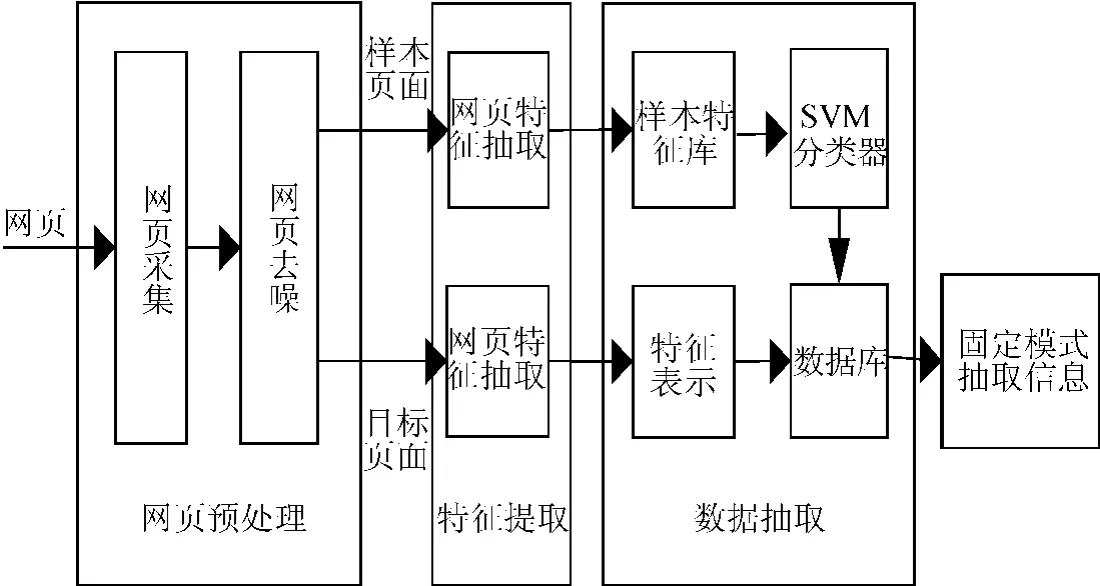
图1 基于SVM的Web信息抽取框架
2.2 网页预处理
网页预处理模块分为网页采集子模块和网页去噪模块,网页采集就是利用一些网页抓取程序如crawler对网络上的原始网页进行抓取,并将获取到的网页存入到本地数据库中;网页去噪的主要作用是规范化解析网页,对所获得的样本网页和目标网页进行修复,并对其中的噪音进行过滤,去除掉网页中的干扰信息,以提高数据抽取的效率。
本模块中的网页去噪操作是一个重要环节,由于Web页面中内容繁多,除了包含主体信息以外,还包括标签以及指向图片、音频和视频文件、与其他网页的链接以及广告信息、版权信息等众多“噪音”内容。这些噪音数据降低了主题信息数据抽取的准确性和效率。另外Web上的数据大多是用HTML编写的,而HTML的规则不严格,它允许网页制作者在使用标记时有太多的自由。例如,网页制作者可以使用段落标识符<P>来标明段落的开始,但是却并不一定要在段落的末尾使用段落结束符</P>。HTML文档中的标签交叉使用也不报错,如<tr><td></tr></td>。所以从这些文档中抽取数据变得比较困难,相当于从非结构化文本中抽取数据。网页去噪模块先将网页中不规范或不完整的HTML文档转换为结构良好的XHTML文档,使用解析函数将其进一步解析成DOM树结构,再对DOM树进行操作,过滤掉网页中包含有噪音信息的节点[2]。它可以简化网页内标签结构,减小网页规模,降低抽取规则的学习和数据抽取所需的时间和空间开销,是系统预处理过程中必不可少的重要环节。
2.3 网页特征提取
特征提取模块的主要作用是获取DOM树中信息片断的特征,以此将网页特征向量化。按照网页中各种字符的不同作用,我们可以从网页中获取四类不同的特征:前后文特征,即网页中信息片断的前后信息,通常对信息片断具有提示作用 (包括前引导词和后引导词)。布局特征,即信息片断在网页中的位置布局是相对确定的,DOM树中的层次结构路径即可作为信息片断的“坐标”[3]。视觉特征,即用于表示信息片断的大小、颜色、文本长短等特征。普通特征,即信息片断自身之间所存在的区别。
上述四类特征可以将网页中的信息片断特征向量化,其获取方法难易程度不同,视觉特征和普通特征只需检测网页即可获得;前后文特征需要定位前后引导词来获取;布局特征的获得相对来说比较复杂,算法可以描述为:首先检查页面的当前标记,若当前标记是头标记,并且该头标记的前一个标记是头标记,将该头标记加入到路径标记中;若该头标记的前一个标记是尾标记,修改其路径序号值;若当前标记是尾标记,移除末端标记。判断尾标记的前一个标记是否是尾标记,若是,移除末端标记,并且重置前一个标记。
2.4 数据抽取
数据抽取就是从目标网页中抽取出用户所需要的信息,该模块是整个方法的核心部分。为了实现有效抽取,需要通过多种算法对网页文档中的前后文特征、普通特征、视觉特征和布局特征进行训练,以至达到将网页中的信息片断进行分类标注的目的。当网页中的信息用特征来表示的时候,通常比普通的文集更多,采用传统分类算法时容易产生“过学习”问题[4];同时,系统需要用户提供一定数量的学习样本,而这些样本所能提供的特征信息有限,不能够很好的刻画出数据的总体分布特征,从而导致在使用传统分类算法时容易出现误差较大的情况。基于上述原因,本文采用SVM作为分类方法的核心部分。
数据抽取模块又具体划分为分类抽取学习阶段和数据抽取阶段两部分。在方法的分类抽取学习阶段,特征向量化的样本网页被不断训练并生成一个分类决策函数,即SVM分类器;在方法的数据抽取阶段,SVM分类器对已到达的具有特征向量化的目标网页中的信息片断进行分类标注,并将已标注好类别的信息片断存储到本地数据库中。
在SVM分类待抽取数据时,为提高数据抽取效率,它会试图寻找最优分类超平面。其中SVM的有效学习也很重要,具体的学习过程如下:
先假设训练样本T为:
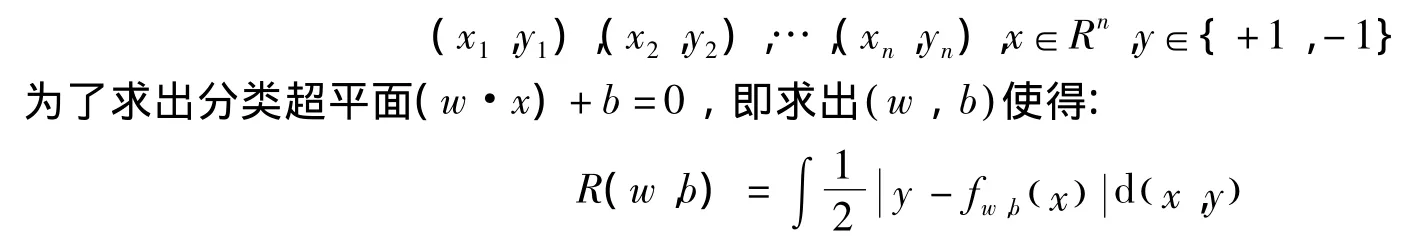
达到最小值,本算法最终将转化成为一个二次型寻优问题。
1)对于线性可分的情况,即求
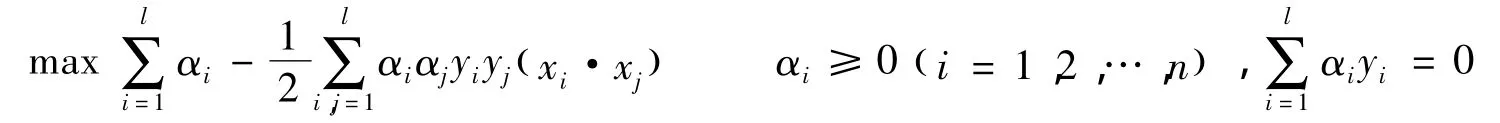
2)对于线性不可分的情况,引入错误惩罚系数C,即求
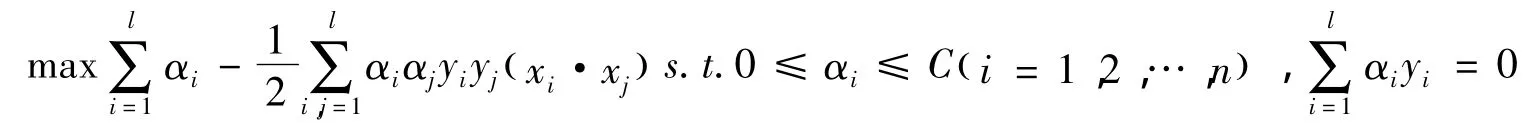
3)对于非线性的情况,用核函数K( xi,xj)代替上式中 ( xi·xj),即求
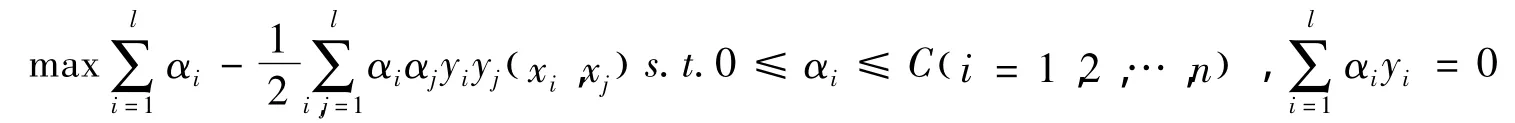
为解决上述二次型寻优问题,采用序贯最小优化算法 (Sequential Minimal Optimization,简称SMO),关于SMO算法收敛的理论分析在文献 [5]中有详尽的证明。然后利用关系式:
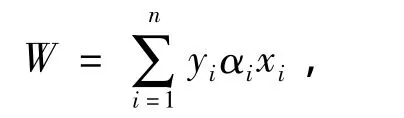
最后,为了判别够格样本t是否属于类a,还需要通过以下两个步骤:
1)计算x=φ(t);
如果 ()f x=1,则t属于类a,否则就不属于。
当SVM终止学习后,目标网页中的信息片断就已经被正确的分类标注。SVM在学习的过程中,能够利用少量样本所提供的有限信息更好的刻画出数据的总体分布特征,使用该方法在Web数据抽取时抽取的信息精度会进一步提高。
3 实验结果和分析
3.1 评价指标
Web信息抽取领域内的主要评价指标是召回率 (#Recall)和准确率 (#Precision),公式为:
召回率=被正确抽取出来的数据 (#Real)/应该抽取出来的正确数据 (#True);
准确率=被正确抽取出来的数据 (#Real)/所有被抽出的数据总数 (#Total)。
召回率和准确率的取值范围都在 [0,1]之间,两者之间存在着反比关系,不同的数据抽取系统对Precision和Recall的侧重有所不同。为了综合评价抽取系统的性能,提出了各种综合评价指标,如:F-度量 (F-measure),该指标可以计算Recall和Precision的加权几何平均值,其计算公式如下[6]:
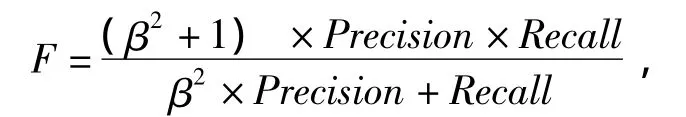
β为召回率和准确率的相对权重。β大于1时,准确率比召回率更重要;β小于1时,召回率比准确率更重要;β为1时,二者同样重要。
3.2 实验结果及分析
利用基于XML的Web信息抽取方法,以.NET为开发平台,采用C#工具开发了信息抽取模型系统。系统通过网页抓取程序从网站获取页面,经过页面清洗,实现去噪操作;根据样本页面学习获取到信息片断的特征,采用SVM分类器对各个信息片断进行分类标注,将结果存储到XML文档中,最后将抽取结果以页面形式显示。
本文利用抽取系统进行4个网站某项专题的信息抽取,将搜狐、新浪、网易和腾讯作为数据来源,对网站上有关2011年金融危机的新闻进行抽取测试,实验的目的是验证SVM在Web信息抽取中的可行性和数据抽取的召回率和准确率情况。按照3.1节中的评价标准,当取β=1时所得的抽取测试结果如表1所示。

表1 四个网站2011年金融危机新闻抽取测试结果
实验数据结果表明,使用SVM分类器可以很好地获取网页信息特征,该方法可以有效地完成信息抽取任务,准确的抽取出所需信息,实现数据抽取的自动化。
4 结语
如何能高效抽取出网页有效信息一直以来是人们研究的热点之一,本文给出一种基于SVM的Web信息自动化抽取方法,将信息抽取技术和机器学习中的分类方法相结合,通过SVM将网页中的信息片断进行分类标注,用户只需要提供少量的信息就可以完成抽取任务。实验结果表明:该方法召回率和准确率较高,对于结构复杂的网页具有良好的健壮性和适应性。
[1]许建华,张学工.统计学理论基础[M].北京:电子工业出版社,2004.
[2]袁明轩,张选平,蒋宇,等.一种基于同层网页相似性去除网页噪音的方法[J].计算机工程,2006(12):61-63.
[3]李文立,王乐超,宋春雷.基于HTML树和模板的文献信息提取方法研究[J].计算机应用研究,2010(12):4615-4617.
[4]李文杰,李方方,魏红.基于支持向量机的位置相关计算[J].计算机仿真,2008(2):124-126.
[5]Keerthi S S.Convergence of a Generalized SMO Algorithm for SVM Classifier Design TR CD -00-01Control Division Dept of Mecha And Prod[D].Singapore:Engineering National University of Singapore,2000.
[6]李保利,陈玉忠,俞士汶.信息抽取研究综述[J].计算机工程与应用,2003(10):1-5.
Web Information Automatic Extraction Method Based on SVM
WANG Ya-liLI Xiao-jing
(Jiyuan Vocational and Technical College,Jiyuan 459000,China)
Given the problems of heavy computation and low automatic level existed in traditional Web information extraction method,this paper proposes a kind of web information automatic extraction method based on SVM,effectively completing the task of Web information extraction and precisely extracting information so as to realize automation of data extraction.The results show that SVM can be used in web information extraction and it has higher rates of recall and precision.
support vector machine;web information extraction;classification learning
TP311
A
1009-0312(2012)05-0053-05
2012-09-01
王亚利 (1974—),女,河南济源人,副教授,硕士,主要从事计算机网络、信息系统研究。
