基于遗传算法的预应力二次张拉拐点识别研究
2012-05-04刘恒洋黄贤英
刘恒洋,卢 玲,黄贤英
(重庆理工大学 计算机科学与工程学院,重庆400054)
0 引 言
预应力二次张拉过程中产生的拐点数据在路桥施工中有着非常重要的作用,这些作用主要包括对预应力器材的质量检测、自然灾害的动态检测以及工程施工质量的验收等[1]。目前预应力二次张拉拐点的识别方法包括手工识别和软件自动识别,手工识别不仅工作量大效率低(主要集中在根据测量数据绘制曲线过程上),而且拐点结果的正确与否极大地依赖于工作人员的工作经验[2]。软件自动识别一般将拐点的识别过程分为数据预处理和拐点计算两个阶段,在数据预处理阶段主要是过滤异常数据和去除测量过程中由于外界干扰导致的明显的非线性数据;计算拐点阶段是拐点识别的关键过程,这个过程中一个比较主流的做法就是比较测量过程中的点跟第一个点组成的直线以及该点跟最后一个点组成的直线之间的斜率差,如果斜率差最大,则说明该点就是拐点。这种做法的缺点是随着测量曲线的非线性坡度的增大,测量出的拐点位置跟实际拐点位置存在一定的差距。为了解决拐点计算过程中精度不够的问题,本文将遗传算法应用到预应力二次张拉拐点识别的过程中,以达到提高拐点识别精度的目的。
1 预应力二次张拉的物理结构和数学模型
1.1 预应力二次张拉物理结构概述
为了检测钢索质量,或监测工程状况,在实际工程中,常常将钢索进行如图1所示的锚固安装。
在图1中,先将钢索一端固定在A点,在施加指定张力F0使钢索伸张后在B点通过夹持装置固定,记AB段钢索的弹性系数为k1。同时在B点外预留指定长度L2的钢索,以便后续进行二次张拉。

图1 锚索固定与张拉
在对C点进行二次张拉时,若施加的张力小于F0时,仅BC段钢索进行张拉,原始长度记为L2,弹性系数记为k2。当施加的张力大于F0时,B点处的夹持装置松动,AB段钢索与BC段钢索构成整体同时进行张拉,根据胡克定律的串联公式,此时AC段钢索的弹性系数为k1k2/(k1+k2),其张力-伸长量关系如式(1)所示


图2 理想二次张拉曲线及拐点
1.2 预应力二次张拉拐点的定义及其数学模型
根据前面的阐述,可以将预应力二次张拉的拐点定义为[3]:在向预应力锚固系统逐渐施加张力过程中,两段不同弹性系数张拉曲线之间的交界点。根据拐点的定义,可将拐点辨识的本质描述为:找到两条直线方程,使得这两条直线的轨迹在测量范围内与实测数据的轨迹误差最小,则这两条直线的交点即为拐点。该问题的数学描述如下[4-6]:
搜索参数:k1(直线方程1斜率)、k2(直线方程2斜率)、b1(直线方程1截距)、b2(直线方程2截距)、p(xG,yG)(两直线预设交点坐标,即实测数据中的某一点)。
使得实测数据:D={d1,…,di,…,dn},其中 di=(fi,si)为实测数据点,fi为实测张力值,,si为实测伸长量。
与两直线方程:y=k1x+b1,y=k2x+b2的离散采样数据

的绝对误差最小

则满足此条件的p(xG,yG)为最优拐点,k1,k2为两段不同张拉过程的弹性系数。
2 遗传算法及其在预应力二次张拉拐点的应用
2.1 确定拐点中心点
在利用遗传算法进行拐点的优化搜索前,首先需要确定前面所总结的模型中的5个参数(k1,k2,b1,b2,p(xG,yG))的可能取值范围[7]。即根据数据集D的几何特征,计算出参数可能取值范围的中心点idxo(用 下 标idx 来 表 示 拐 点 位 置, 即 p(xG,yG)=didx(fidx,sidx)),其算法步骤如下[8]:
(2)从数据点d1(f1,s1)开始对数据集D进行遍历,记当前数据点为di(fi,si)。
(3)计算候选参数中心点k1,k2,b1,b2,ek
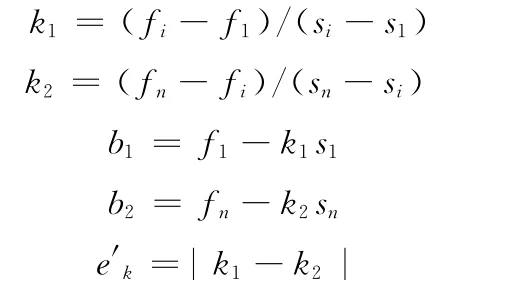
(4) 若e′k>ek则,ek=e′k,idxo=i

(5)若已遍历完De中所有数据,则转第6步,否则转第2步。
2.2 利用遗传算法搜索最优拐点参数
在3.1节计算得到了优化参数的可行取值范围的中心点,现以该中心点进行扩展得到可行区域如下

式中:α,β∈(0,1),γ ∈ [1,idxo]——搜索区域扩展系数,取值越大则搜索到全局最优解的可能性就愈大,但所耗时间就越长,收敛速度也越慢;反之,取值越小则得到全局最优解的可能性就越小,但收敛速度会更快,耗时更短。
式(4)中的5个待优化参数:k1,k2,b1,b2,idx分别为遗传算法中的5个基因(gene),5个参数以实数编码的方式组合构成染色体(chromosome),如图3所示。

图3 染色体/个体组成
多个染色体构成种群(population),如图4所示。

图4 种群构成
而种群的从父代向子代的逐代进化过程则构成了遗传算法的参数优化过程,如图5所示。

图5 种群进化过程
整个遗传算法的程序流程图如图6所示,主要包括交叉、变异、选择等操作,下面将对程序流程中的各个环节逐一阐述。
(1)初始化种群
采用统计学中的田口正交实验方法[9],进行种群的初始化操作,以便保证所有的个体能均匀分布在式(4)所确定的可行解超空间中。本处水平数为10(levels,即基因的取值范围被分为几个等级),因素个数为5(factors,即基因个数或参数个数),则正交表记为L100(10,5)。种群的初始化算法如式(5)所示


图6 遗传算法程序流程
式中:gij——种群中第j个染色体的第i个基因的取值,inf(gi)——第i个基因的取值下界,sup(gi)——第i个基因的取值上界,L100[i][j]——正交表的第j行i列个元素。
种群大小设定为100,即初始化生成的染色体个数为100,以后每次经过进化后生成的下一代种群染色体数也是100。
(2)计算适应度
在遗传算法中采用适应度函数来计算个体(染色体)的适应度值,从而评价个体的适应性(优劣程度),以便模拟 “优胜劣汰”的自然进化法则。本处所选取的适应度函数如式(6)所示

(3)交 叉
交+叉环节包含两个步骤:基于海明距离[10]的配对操作和可变精度的交叉操作。
基于海明距离的配对操作[11]:为避免近亲繁殖,在进行交叉操作前,先计算个体之间的海明距离,只有个体间距离大于给定值时才能进行配对。两个染色体(x={g1x,g2x,g3x,g4x,g5x},y={g1y,g2y,g3y,g4y,g5y})间 的 海 明距离定义如下


当两个个体间的海明距离大于等于2时才能进行配对。
可变精度的交叉操作:两个染色体(x={g1x,g2x,g3x,g4x,g5x},y={g1y,g2y,g3y,g4y,g5y})的可变精度交叉操作算法如下:
首先随机生产交叉点位置:i=rand(1,5),i∈ [1,5]。
假设i=3交叉后的新个体如下

其中:g′3x=g3x+μ(g3y-g3x),g′3y=inf(g3)+μ(sup(g3)-inf(g3)),μ∈ {0.0,0.1,0.2,…,1.0}为随机加权数,inf(g3)表示基因g3的取值下界,sup(g3)表示基因g3的取值上界。为了避免由于基因的多次选择而导致算法收敛减速,被多次选择的基因的精度会逐次增加。
设定交叉率为0.8,即要进行40次交叉配对,生成80个新的染色体。
(4)变 异
为避免算法早熟收敛,算法中采用了管理学中的凸集理论—多点变异,即随机选择单个染色体的多个基因进行凸组合变异,同时将两点变异和多点点变异以概率的方式随机进行,这就极大地增强了变异环节的精细调节能力,若染色体x={g1x,g2x,g3x,g4x,g5x}的第2和第4个基因被选择进行变异,变异生成新的染色体x'={g1x,g′2x,g3x,g′4x,g5x},其中

其中,μ∈ {0.0,0.1,0.2,…,1.0}
(5)选 择
采用轮盘赌的方式进行选择[12],让适应度较低的个体也有被选择的机会,以维护种群基因的多样性。待选择的范围为父代的100个染色体和交叉操作生成的80个染色体,即从180个染色体中选择出100个染色体作为下一代种群。其中这180个染色体的最高适应度个体被无条件保留进入下一代,即只需要选择出99个染色体。算法如下:

生成随机数:rnd ∈(0.0,1.0),若rnd ≤P[i]则第i个染色体被选中,重复执行该操作直到选中99个染色体。
(6)终止条件
经过前面所采用的交叉、变异、选择操作进行逐代进化,当达到性能指标(即两直线方程轨迹与实测数据吻合度达到指定要求)或进化代数达到指定值(200代)时退出遗传算法。
3 算法测试
根据前面对遗传算法的应用过程,本文采用C#语言编程实现了基于遗传算法的拐点识别功能(如图7所示)。

图7 拐点识别曲线
图7(a)中为通过传统的拐点识别方法(比较测量过程中的点跟第一个点组成的直线以及该点跟最后一个点组成的直线之间的斜率差的方法)识别出来的拐点数据图。图7(b)中为通过本文中描述的遗传算法计算得到的拐点图,图7(b)的数据表明,不论是从拐点数据还是拟合出来的直线,都比图7(a)中的数据有所提高。因此,本文描述的将遗传算法应用到预应力二次张拉拐点的识别过程中能够提升显著提升拐点识别的精度,提高工程施工质量。
4 结束语
本文通过分析预应力二次张拉的物理结构,建立了预应力二次张拉拐点的数学模型;同时通过分析预应力二次张拉拐点的定义,在拐点识别过程中引入了遗传算法,并分别在遗传算法的初始化、适应度计算、交叉、变异和选择过程中进行优化搜索。通过实验表明,跟传统的拐点识别方法相比,通过遗传算法进行搜索后得到的两条拐点直线,能够与原来的测量曲线进行很好的逼近,进而大大提高了这两条曲线的交点(即拐点)的精度。
[1]SHAO Xudong,LI Xianchao,ZHOU Yadong.Application of twice-prestressed composite structure to high-speed railway bridges [J].Journal of Railway Science and Engineering,2006,3(6):3-5(in Chinese). [邵旭东,李显潮,周亚栋.二次预应力组合结构在高速铁路桥梁上的应用研究 [J].铁道科学与工程学报,2006,3(6):3-5.]
[2]WU Xiaolu,XU Bin.Analyses of second tension steel strand vertical pre-stressed system [J].New Technologies and Products,2010,18(16):90-91(in Chinese).[吴小陆,许斌.浅析二次张拉钢绞线竖向预应力锚固系统 [J].中国新技术新产品,2010,18(16):90-91.]
[3]CHEN Yu.The common errors in proof of sufficient conditions of judging inflection point [J].College Mathematics,2010,26(4):187-190(in Chinese).[陈玉.曲线拐点充分条件证明中的常见错误 [J].大学数学,2010,26(4):187-190.]
[4]CAI Z X,WANG Y.A multiobjective optimization-based evolutionary algorithm for constrained optimization [J].IEEE Trans on Evolutionary Computation,2006,10(6):658-675.
[5]WANG Y P,DANG C Y.An evolutionary algorithm for global optimization based on level-set evolution and Latin squares [J].IEEE Trans on Evolutionary Computation,2007,11(5):579-595.
[6]GUO Qingsheng,HUANG Yuanlin,ZHANG Liping.The method of curve bend recognition [J].Geomatics and Information Science of Wuhan University,2008,33(6):596-599(in Chinese). [郭庆胜,黄远林,章莉萍.曲线的弯曲识别方法研究 [J].武汉大学学报信息科学版,2008,33(6):596-599.]
[7]QANG Yanping,YUAN Jie,SU Xiangfang.Corner invariant and its application to pattern recognition [J].Journal of Image and Graphics,2006,4A(10):854-858(in Chinese).[王延平,袁杰,苏祥芳.几种拐点不变量及其在目标识别中的应用[J].中国图像图形学报,2006,4A(10):854-858.]
[8]XU Jin,KE Yinglin,QU Weiwei.B-spline vurve approximation based on feature points automatic recognition [J].Journal of Mechanical Engineering,2009,45(11):212-216(in Chinese).[徐进,柯映林,曲嵬崴.基于特征点自动识别的B样条曲线逼近技术 [J].机械工程学报,2009,45(11):212-216.]
[9]JIANG Zhongyang,CAI Zixing,WANG Yong,Hybridself-adaptive orthogonal genetic algorithm for solving global optimization problems [J].Journal of Software,2010,21(6):1297-1302(in Chinese).[江中央,蔡自兴,王勇.求解全局优化问题的混合自适应正交遗传算法 [J].软件学报,2010,21(6):1297-1302.]
[10]TIAN Feng,YAO Aimin,SUN Xiaoping.Dual population genetic algorithm based on individual similarity [J].Computer Engineering and Design,2011,32(5):1789-1791(in Chinese).[田丰,姚爱民,孙小平等.基于个体相似度的双种群遗传算法 [J].计算机工程与设计2011,32(5):1789-1791.]
[11]ZHANG Lei.The influence of hamming distance parameter on genetic algorithm based on hamming distance [J].Journal of Beihua University,2010,11(3):286-288(in Chinese).[张雷.海明距离参数对基于海明距离遗传算法的影响 [J].北华大学学报(自然科学版),2010,11(3):286-288.]
[12]GU Feng,WU Yong.The improvement of genetic algorithm[J].Microcomputer Development,2006,13(6):80-86(in Chinese).[古峰,吴勇,唐俊.遗传算法的改进 [J].微机发展,2006,13(6):80-86.]
