粗糙本体支持的信息语义检索
2012-05-04黄映辉
樊 皓,黄映辉
(大连海事大学 信息科学技术学院,辽宁 大连116026)
0 引 言
G.Salton作为信息检索领域的先驱,最早提出基于关键字的向量空间检索方法,自此信息检索被默认为是信息语法检索,一般多采用改进匹配算法的方式提高 “串匹配”的效率。语义Web概念的提出为信息语义检索提供了解决方案和技术支持,从而推动信息检索从基于关键字的语法检索迈向基于标注的语义检索[1]。主要的改进为:引入哲学术语 “本体”,期望通过对概念及概念之间关系的定义,实现知识层次的检索,突破传统基于关键字检索时语言表达形式的局限实现语义检索。然而,本体在被引入信息科学领域时就已被界定为 “概念模型的明确规范说明”[2],被默认为是精确本体。该模型的精确性假设与人类认知客观世界过程的不精确性特征并不相符,表现为不精确的信息检索请求 (用户对所要检索的领域知识的不精确认知)与精确的信息表达 (精确本体对概念及概念之间关系的明确性定义)之间存在着矛盾。
S.Ishizu[3]将粗糙集理论引入本体,提出了粗糙本体的概念,使其具有了对不精确信息的表达能力。本文引入粗糙本体支持的信息语义检索,以求在概念匹配的基础上,解决概念表达的不精确影响检索结果的问题。通过分析信息语义检索的过程和特点并结合粗糙本体的定义,确定了粗糙本体的表示形式,建立了粗糙本体支持的信息语义检索模型,探讨了作为该模型最主要环节的语义相似度计算的核心算法,提出了该模型的实现方法并进行了实例验证。
1 信息语义检索
信息语义检索是一种基于概念及其相互关系的检索匹配机制[4],要求从语义理解的角度分析信息对象与检索请求。信息语义检索的一种重要应用是对语义Web上的文档进行的检索。语义Web文档是用语义Web语言描述的可供用户访问的文档[5],对此类信息进行语义检索的关键是找出不同概念之间的相似映射关系,实现基于本体的检索[6]。
信息语义检索相对于信息语法检索的优势主要体现在:
(1)信息组织方面。信息语义检索大多采用基于语义Web信息组织的有序化结构[7],信息之间的关系通过术语来表达,信息资源得到有效整合,易于信息的存取。
(2)信息理解方面。信息语义检索的概念级别匹配机制使机器充分 “理解”检索请求,能够完成在不同语义环境下词语含义与精确概念的匹配。
(3)概念推理方面。通常本体是用某种基于描述逻辑的语言表示的,例如RDF(S)、SHOE、OWL等,一些常用的本体工具如Protégé、Jena等可以据此进行自动推理,满足信息智能检索的需要。
单纯依靠精确本体并不能在有限表达中穷尽词语的语义,即精确本体的知识是不完备的,因此引入粗糙本体的支持。粗糙本体是精确本体在粗糙集理论上的扩充[8],能够基于已有的精确概念衍生出粗糙概念,同时又具有本体的结构可伸缩性的特点,因此可以用来解决粗糙概念的表示问题。粗糙本体与精确本体相比其主要优势在于:
(1)概念分类。粗糙本体引入粗糙集的不可分辨关系,可以在信息不完备的基础上揭示出领域知识的粒状结构,可作为定义其他概念的基础。
(2)概念的含糊性和边界的表示。自然语言使用的概念几乎都是含糊的,例如 “美丽的照片”,照片不能简单地分为 “美丽”或 “不美丽”,因此往往有很多对象会处于粗糙概念的边界上,粗糙本体可将含糊的边界表示出来。
(3)不确定性问题。某概念是否符合检索请求是属于不确定性问题的研究范畴,粗糙本体可定义所需概念的近似边界,将粗糙概念边界域明确化,把结果的不确定性问题变成边界的确定性问题,将粗糙性与不确定性联系起来。
2 粗糙本体
2.1 粗糙本体
粗糙本体可用三元组O=<C,P,R>表示,其中C为粗糙概念集,P为属性集,R为粗糙概念之间关系集。为刻画概念的粗糙性,引入了粗糙集理论中的上近似、下近似来进行概念边界的粗糙性表示,由此弥补了精确本体对不精确信息描述的缺失。粗糙概念c是一个三元组,其形式为c= (U,L,Y),含义为,对于给定的内涵Y,“可能”被Y中所有属性涵盖的对象组成的集合U为此内涵对应概念的上近似外延,“肯定”被Y中所有属性涵盖的对象所组成的集合L为此内涵对应概念的下近似外延。
粗糙概念c的近似精度定义为aR(c)=card (R*(c))/card (R*(c)),用来表示概念的不精确程度,以反映人们了解概念c的完全程度。其中,c≠,card (X)表示X的基数。R*(c)为概念c关于Y的下近似,R*(c)为概念c关于Y的上近似。当近似精度为1时,说明此概念的上近似和下近似基数相同,可将其视为精确概念,由此可知精确本体是粗糙本体的子集。由于继承了粗糙集的不精确信息表示和决策支持的特性,使粗糙本体具有了对不精确概念的形式表示和语义挖掘的能力,所以,它不仅能完成精确概念对现实世界中的精确信息的表示,同时也可以从中挖掘出隐含的不精确信息。
粗糙关系R是粗糙元组的有穷集合,它是叉集P (D1)×P (D2)×…×P (Dm)的一个子集。其中,Di是属性域,P(Di)表示Di的幂集。
目前的研究已经实现了粗糙本体的构建,实施路径主要分为两种:一是基于粗糙集理论,二是基于现有的本体构建方法。现多采用属于第二种路径的形式概念分析法[9],这种方法的实现主要依靠粗糙集近似[10]或属性集幂集[11],前者需要用到粗糙集理论中下近似、上近似和不可分辨的原理,能够较好地实现粗糙概念的边界描述,后者重点关注面向计算机的程序实现,能够方便地完成粗糙概念的抽取。
2.2 粗糙本体的表示
要将粗糙本体引入信息语义检索,首先需要解决其形式化表示的问题。粗糙本体是精确本体在粗糙集上的扩充,由于粗糙本体的特殊性,利用OWL[12]代码化粗糙本体时需在对象属性中加入粗糙性描述语句,即上近似外延和下近似外延,与此同时,为便于区分精确本体与粗糙本体、表示粗糙概念的不精确程度,还需引入近似精度的概念(其定义见2.1节)。粗糙本体的OWL表示为:定义PreciseClass为精确类、RoughClass为粗糙类;定义accuracy为该对象的近似精度;定义subClassOf为粗糙概念之间的继承关系表示基于内涵的包含关系;定义low_extent为粗糙概念的下近似外延、up_extent为粗糙概念的上近似外延,定义域为粗糙类,值域为精确类。表示模型如图1所示。
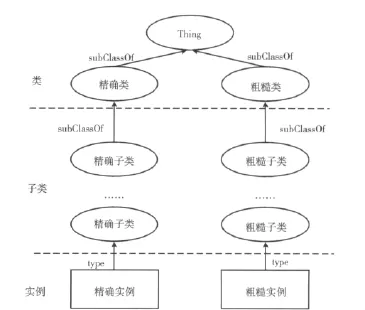
图1 粗糙本体的OWL表示
现举例说明:对海事领域粗糙本体进行OWL描述。对粗糙概念 “载驳船”而言,其下近似外延为 {货船,母船}、上近似外延为 {货船,母船,驳船},OWL描述片段如图2所示。

图2 粗糙本体的OWL文档 (片段)
粗糙概念到精确概念的联系由上近似外延、下近似外延表示。在利用粗糙集理论对精确本体信息构成的形式背景抽取规则后,获得的置信度为1的规则为精确规则,对应着该粗糙概念节点的下近似外延;其余置信度大于阈值且小于1的规则,对应着该粗糙概念节点的上近似外延,由此完成精确本体到粗糙本体的联系。当精确概念的结构越来越复杂,精确概念之间关系越来越多,粗糙概念就可以很好地成为实际距离较远的两个精确概念的 “捷径”。由此,在信息语义检索中对概念集扩展的过程有了根本的变化,引入粗糙本体的信息语义检索充分挖掘出了精确概念之间关系的隐含信息,而并不只是关注精确本体概念的单一结构特性 (如层次结构、二元关系等)。
3 粗糙本体支持的信息语义检索
3.1 理论模型
粗糙本体支持的信息语义检索模型如图3所示。用户通过人机交互接口提交检索请求,经过语法分析、格式转换得到检索语句的规范化逻辑表示,提取出关键字的集合,得到初始概念集。通过粗糙本体支持的语义相似度计算,找到满足阈值的相关精确概念和粗糙概念以对初始概念集进行语义扩展,得到扩展概念集。已扩展的概念集与索引库中已经标注的文档进行匹配,对结果排序后将结果文档集返回给用户。
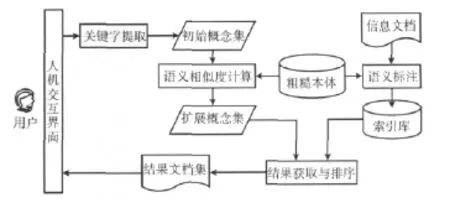
图3 粗糙本体支持的信息语义检索模型
图3所示模型共有4个关键性操作:
(1)关键字提取。关键字提取是对用户所提交检索请求的处理模块,主要完成对检索语句的处理使其转化成能够完成机器推理的形式化语法格式,如OWL-QL等。提取过程需要进行语法分析、句法分析、格式转换等操作,最后获得满足检索请求的初始概念集。
(2)语义标注。语义标注过程是将需要检索的文档中涉及的实例与抽象的本体中的概念相关联的过程。从本体构建的角度看,语义标注是将文本信息转化为本体数据并存储到索引库的过程。基于粗糙本体的语义标注需要同时以精确本体和粗糙本体的实例为切入点,将文档形式化为一系列本体实例的向量,并对其进行索引。
(3)语义相似度计算。语义相似度计算是用来完成对概念集扩展的过程,是区别于精确本体支持的信息语义检索的关键,它主要是通过初始概念集借助本体推理得到相关概念,通过对扩展概念的语义相似度计算,选择概念之间语义相似度大于阈值的作为扩展概念加入概念的扩展集合,使检索结果更符合用户需求。
(4)结果获取与排序。获取包含扩展所得的概念集中的本体实例的文档,并根据文档中所有实例相对于概念集的相似度向量和权重对结果文档集排序。
3.2 语义相似度计算
基于本体的信息语义检索是利用本体中的精确概念来表达用户的检索请求,而对检索请求的分析则要求尽可能准确地判断其与本体中概念的相似程度,这就需要分析概念之间的语义相似度。语义相似度的计算决定概念匹配的精确度,是区别于语法检索的基础和关键。目前对精确本体支持的语义相似度的研究通常分为3类[13]。基于概念名称,即根据英语词法构造,认为两个相近的词在词义上是相似的,代表算法有编辑距离法、基于词典处理法。这种算法简单快捷,但是没有考虑使用环境对概念的语义信息的影响因素。基于概念实例,即基于统计概率计算概念之间共有实例的联合分布,代表算法有GLUE法、Jaccard法。这种算法对特定系统适应度高,只是过分依赖训练集的质量。基于概念结构,即抽取概念的属性与规则关系图,分配权重,计算语义距离,代表算法有Rada法、Sycara法。这种算法面向概念的联通性,应用广泛,但是未涉及与现实世界粗糙概念的隐含联系。由于概念节点层次关系中有大量的语义信息,基于概念结构的语义相似度算法被广为关注并设法改进。
然而,三类算法都无法适用于引入粗糙概念后的语义相似度计算,已有的语义相似度计算归根结底还是基于精确概念和精确实例的。例如,海事领域精确本体的日趋完善为海事领域信息检索提供有效支持,三类算法都可以完成海事领域精确的概念 (如货船、港口、航线等)的语义相似度计算,然而用户对检索关键词的描述和分类往往并不能从海事领域的专业术语出发,从而会产生许多海事领域的粗糙概念,比如 “拥挤港口”、“热门航线”、“事故海域”等,它们的外延的不精确性致使海事领域精确本体无法对其进行显式地描述,更无法通过精确概念到粗糙概念的内在联系实现包含概念之间隐含关系的相似度计算。以第2.2节给出的粗糙本体的表示为基础,探讨粗糙本体支持的语义相似度计算方法,根据概念节点的类型应分为三种情况处理:粗糙—精确、粗糙—粗糙、精确—精确,通过调节因子确定3种情况下语义相似度的比重。具体计算方法如下:
(1)粗糙—精确:粗糙概念X与精确概念x之间的语义相似度simrp计算主要考虑的是精确概念隶属于粗糙概念的确定程度

(2)粗糙—粗糙:两个粗糙概念X1、X2的语义相似度simrr需要同时考虑到它们的下近似和上近似的相似程度。对于给定粗糙概念X1(U1,L1,Y1)和X2(U2,L2,Y2),定义下近似相似度siml(X1,X2)和上近似相似度simu(X1,X2),相似度是两者之和,β为调节因子
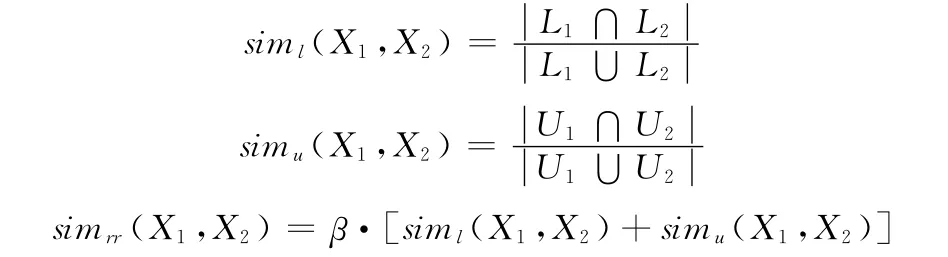
(3)精确—精确:精确概念x1、x2之间的语义相似度需要考虑到粗糙本体进行扩展后两个概念的距离,因此在语义距离的基础上,考虑到边的方向问题,给出表1所示的距离权重。其中Φ代表空操作,G为泛化操作,包括子节点向父节点的边和由精确规则连接的精确概念向粗糙概念的边;S为细化操作包括父节点指向子节点的边和有下近似外延连接的粗糙概念到精确概念的边;P为正联系,用来表示同位关系的边;Gr和Sr分别表示由不精确规则和上近似外延联系的精确概念之间的边;“—”代表无意义操作。比如对于路径G→S→P→Gr→Sr,其语义距离为2+3.5+4+5=14.5。
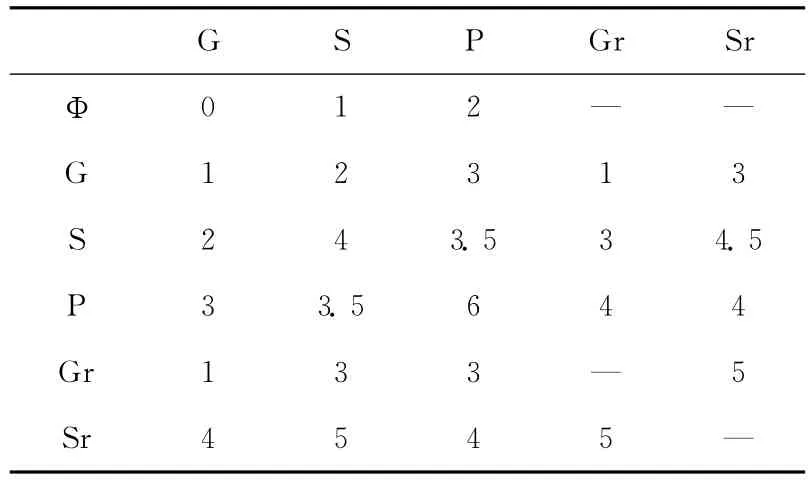
表1 扩展后的语义距离权重表
引入最低共同祖先后,给出语义距离计算方法和语义相似度计算方法
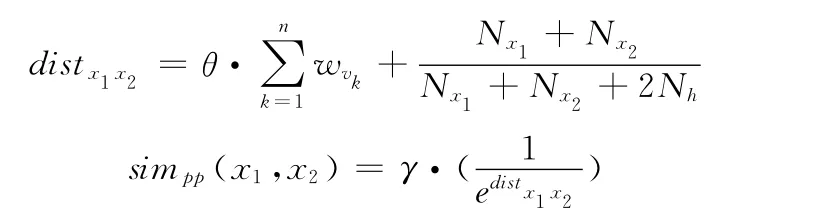
语义距离distx1x2中为概念之间各边的加权距离之和,Nxi代表节点i到最低共同祖先的距离,Nh代表最低共同祖先到根节点的距离,θ和γ是调节因子。
3.3 实现方法
根据对现有工具的比较,给出图3所示模型在技术上的实现方法。
首先,参照相关领域的术语标准完成精确概念、精确概念属性和精确概念之间关系的提取,粗糙概念可以由精确概念实例离散化后所生成的形式背景通过粗糙形式概念抽取的方式直接获得;其次,利用本体编辑工具Protégé进行粗糙本体的创建和维护,完成OWL粗糙本体在关系数据库中的结构化存储[14];再次,利用Jena API完成概念之间关系的推理,获得相关概念和属性,计算语义相似度;然后,使用标注工具对检索资源文档完成半自动标注,利用Lucene开源工具包中IndexWriter建立索引库,以实现扩展概念集与标注文档的匹配和排序;最后,通过Java和Eclipse搭建软件开发平台和人机交互界面,完成模型在技术上的具体实现。
3.4 验证实例
基于 《交通汉语主题词表》与 《中国分类主题词表》中 “水路运输”类目下的概念及概念关系,构建海事领域精确本体并进行扩充,同时通过粗糙形式概念抽取方法获得粗糙概念,添加适当的类和属性。选择中国国际海运网(http://www.shippingchina.com/)的信息为数据源,由于数据量巨大,只抽取其中10129条网页新闻信息 (截至到2011年12月)中的2000条与 “港口”有关的网页作为验证数据,将网页信息转化为文本文档,采用半自动机器辅助标注方式,并将实例和文档的关系存入索引库,完成被检信息的语义标注和索引。
将粗糙本体支持的信息语义检索与未进行粗糙扩展前的精确本体支持的信息语义检索和基于关键字的信息语法检索进行效果比较。考虑到比较条件的一致性原则,用户输入采用相同关键词,结果发现在用户可接受的检索时间范围内,粗糙本体支持的信息语义检索的查全率和查准率都有很大程度上的提高。例如检索 “拥挤港口”,语法检索、精确本体支持的语义检索、粗糙本体支持的语义检索所获得的前5条结果见表2。

表2 验证实例:“拥挤港口”的检索结果
可以明显看出,语法检索时由于被检信息中没有 “拥挤”只能部分匹配到带有 “港口”的信息,而精确本体支持的信息语义检索可以将 “拥挤”与 “港口”拆分, “拥挤”同义于 “拥堵”,并由 “港口”联系到 “散货港口”、“航运”和 “船舶”等,完成概念级别的匹配;而只有引入粗糙本体后,才能在精确本体概念匹配的基础上将用户检索请求中所真正关注的 “拥挤港口”(如上海港、美东线港口、广西防城港)的信息检索出来。
4 结束语
信息语义检索是信息智能化检索领域一个重要应用方向,在知识不完备的条件下实现信息的语义检索是研究立足点。将粗糙本体应用于信息语义检索,提出了粗糙本体支持的信息语义检索模型,探讨了具体的技术实现方案。下一步工作将从两个方面展开:由于粗糙本体的标注主要采取的是半自动方法,还需完成从文档中识别出粗糙本体中类的实例,实现准确的全自动标注;由于粗糙本体支持的语义扩展有可能造成检索结果的急速膨胀,语义相似度阈值及其他参数的选取规则需要从领域专家获得并在试用中进行调整。
[1]Cathal G,Yulan H,Gabriella K,et al.Recent developments in information retrieval[C].Milton Keynes:Proceedings of 32nd European Conference on IR Research,2010:1-9.
[2]Fensel D,Facca F M,Simperl E,et al.semantic web services[M].Berlin:Springer,2011:87-102.
[3]Ishizu S,Gehrmann A,Nagai Y.Rough ontology:Extension of ontologies by rough sets [J].Human Interface,2007,45(57):56-62.
[4]Egozi O,Markovitch S,Gabrilovich E.Concept-based information retrieval using explicit semantic analysis [J].ACM Transactions on Information Systems,2011,29 (2):1-34.
[5]DAI Weimin.Semantic web information organization technology and method [M].Shanghai:Academia Press,2008:38-41 (in Chinese).[戴维民.语义网信息组织技术与方法 [M].上海:学林出版社,2008:38-41.]
[6]Vallet D,Fernández M,Castells P.An ontology based information retrieval model[C].Heraklion:Proceedings of the Second European Semantic Web Conference,2005:455-470.
[7]WANG Zhihua,ZHAO Wei.Research on semantic web retrieval model based on ontology and key technologies [J].Computer Engineering and Design,2011,32 (1):145-148 (in Chinese).[王志华,赵伟.基于本体的语义网检索模型及关键技术研究 [J].计算机工程与设计,2011,32 (1):145-148.]
[8] WANG Dongyan.A method for building semantic web rough ontology [D].Dalian:Dalian Maritime University,2011 (in Chinese).[王栋艳.语义网粗糙本体的构建方法 [D].大连:大连海事大学,2011.]
[9]ZHANG Yunzhong,XU Baoxiang.Research on the optimization of domain ontology construction method based on FCA [J].Library and Information Service,2009,54 (8):112-115 (in Chinese).[张云中,徐宝祥.基于形式概念分析的领域本体构建方法优化研究[J].图书情报工作,2009,54 (8):112-115.]
[10]YANG Xiaoping,LU Xianqing.Comparing rough approximation of formal concept [J].Journal of Guangxi Normal University,2008,26 (3):96-99 (in Chinese). [杨晓平,卢献庆.形式概念粗糙近似比较研究 [J].广西师范大学学报,2008,26 (3):96-99.]
[11]HUANG Dongmei,ZHU Hui.The application of rough formal concept analysis in ocean ontology construction [J].Computer Science,2008,35 (4):6-8 (in Chinese).[黄冬梅,朱慧.粗糙形式概念分析在海洋本体构建中的应用 [J].计算机科学,2008,35 (4):6-8.]
[12]HUANG Yinghui,LI Guanyu.Imprecise semantic web ontology:Meaning,model and representation [J].Computer Engineering and Design,2011,32 (3):1103-1107 (in Chinese).[黄映辉,李冠宇.不精确性语义网本体:语义、模型与表示 [J].计算机工程与设计,2011,32 (3):1103-1107.]
[13]SONG Ling.Research on semantic similarity computation and application[D].Jinan:Shandong University,2010 (in Chinese).[宋玲.语义相似度计算及其应用研究 [D].济南:山东大学,2010.]
[14]CHANG Wanjun,REN Guangwei.Study on storage technique of OWL ontology [J].Computer Engineering and Design,2011,32 (8):2893-2896 (in Chinese). [常万军,任广伟.OWL本体存储技术研究 [J].计算机工程与设计,2011,32(8):2893-2896.]
