基于重复数据删除的远程备份系统
2012-05-04刘晓洁
姜 涛,刘晓洁
(四川大学 计算机学院,四川 成都610065)
0 引 言
远程备份作为一种重要的数据保护手段,其通过将应用系统中的数据备份到异地来实现容灾。由于备份数据存储在远端,当本地发生灾难导致数据丢失时可以通过备份的数据可靠地进行恢复。然而研究发现,应用系统所保存的数据中高达60%是冗余的,而且随着时间的推移越来越多[1]。传统的远程备份并没有分析系统全局的数据冗余,如Rsync[2-3]备份只会消除单个文件增量备份不同版本之间的冗余,对于整个备份系统中所有文件之间的数据冗余就无能为力了。这样会导致备份过程中传输大量冗余的数据,并且浪费存储空间。
为了解决上述问题,本文提出了一种基于重复数据删除的远程备份系统。系统对备份文件进行分块,识别相同的数据块,只传输和存储不重复的数据块。由于相同数据块的去重是系统全局的,这样就大大节约了备份中心数据的存储空间,并且有效地减少了网络流量。
1 系统架构
整个系统采用客户/服务器架构,即由备份客户端和备份中心构成。备份客户端存放了需要备份的数据源,同时包括备份系统运行所需的必要组件。而备份中心则是存储备份数据的地方,它同样包含了备份系统相关组件。一个备份中心可以同时服务多个备份客户端。图1为系统的总体架构。
备份客服端包括文件筛选模块,文件分块及指纹计算模块,文件备份模块,通信模块4个部分:
(1)文件筛选模块:筛选出实际需要备份的文件。
(2)文件分块及指纹计算模块:对需要备份的文件进行分块并计算每个数据块的指纹值。
(3)文件备份模块:利用文件的分块及指纹信息,与备份中心通信,找出备份中心已经存在的数据块,并将新增的数据块传输到备份中心。
(4)通信模块:负责处理与备份中心底层通信。
备份中心包括数据块判重模块,数据块存储模块,通信模块3个部分。
(1)数据块判重模块:判断数据块在备份中心是否已经存在。
(2)数据块存储模块:负责存储和管理备份文件的数据块。
(3)通信模块:负责处理与备份客户端底层通信。
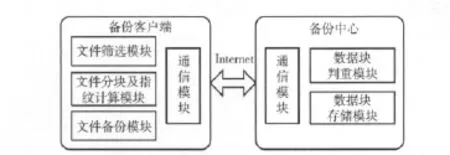
图1 系统总体架构
2 系统设计与实现
2.1 备份文件筛选
在一个备份客户端进行多次备份时,有可能备份的目录中只有少数文件发生了改变。如果不加以区分,在备份文件非常多的时候处理目录中所有的文件显然是不明智的。为了避免这种情况本文系统引入了一种单词查找树[4]的变形来筛选真正需要备份的文件。将该结构命名为目录查找树,参见定义1。
定义1 目录查找树 单词查找树的变形,其存储的是一个目录中文件和子目录的信息,其节点对应文件系统目录树中的一个节点,其中包括路径和时间信息。
在每次备份时生成目录查找树,通过比较待备份文件列表和上次备份的目录查找树可以快速筛选出实际需要备份的文件。目录查找树的结构如图2所示,根节点对应最上层目录,即需要备份的目录。目录查找树的节点包含两项内容:当前节点对应的文件或目录在文件系统中的路径,当前节点对应的文件或目录的修改时间。其中目录的修改时间为它所包含的所有文件和目录中最后修改时间。由此可知,当修改一个文件后,这不仅改变了该文件的修改时间,并且可能影响其上所有父目录的修改时间。利用这一原理就可以在备份的时候比较这次和上次备份的同一文件或目录的修改时间,如果修改时间相同则跳过这一部分文件的后续处理,这样可以快速筛选出真正需要备份的文件。在多次备份大量文件并且其中只有少部分文件改变的情况下,这一处理过程可以大大提高备份的效率。
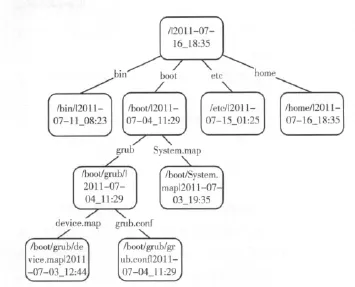
图2 目录查找树结构
2.2 文件的分块及指纹计算
文件分块分为定长分块算法和变长分块算法[5]。定长分块算法计算简单,但对于文件的内容不敏感,相同数据块的识别率较低,而变长分块算法能较好地感知文件间的重复内容。所以本文系统采用了一种基于Rabin指纹[6]的变长分块算法[7]进行文件的分块。该算法对文件应用滑动窗口,计算各个窗口的Rabin值,当其值符合某一特征时,就将该窗口所在的位置定为数据块的边界。根据Rabin函数的特性,该方法能够有效地识别出文件之间的重复内容,因为只有在文件内容不一样的地方,Rabin函数计算出的值才不一样,而其他内容重复的部分则会算出相同的值,从而生成相同的数据块。
文件分块后需要根据数据块的内容计算每个数据块的指纹,该指纹将用于识别已经备份的相同数据块。系统用数据块内容的SHA1值作为其指纹值。SHA1算法[8]是一种广泛应用的散列算法,其抗冲突性较好。SHA1算法对于两个不同的数据块自然产生冲突的概率是非常低的,其能够有效地区分不同的数据块。
2.3 文件备份
根据文件内容对文件分块并计算数据块指纹后,备份客户端需要确定一个文件中哪些数据块是不需要备份的,即这些数据块在备份中心已经存在,这样就能够只传输备份中心不存在的数据块,其步骤如下:
(1)备份客户端将文件的分块信息,即文件中所有数据块的长度和SHA1值发往备份中心。
(2)备份中心收到了该文件数据块的信息后,用这些数据块的SHA1值在索引中查找。如果一个数据块的SHA1值在索引中找到,则说明该数据块已经存在,直接从索引中取得该数据块存储位置,同时标记该数据块是重复的。如果在索引中无法找到该SHA1值,则说明该数据块是备份中心没有的,根据传过来的数据块的长度,为该数据块分配一块新的空间,并将其信息插入索引中,标记该数据块是新增的。
(3)备份中心将数据块是否存在的判断结果发回备份客户端。
(4)备份客户端收到数据块判断结果后,新建一个空的差分文件。遍历数据块判断结果,如果一个数据块在备份中心已经存在,则将其丢弃,否则将该数据块的内容写入差分文件中。
(5)备份客户端将生成好的差分文件发送到备份中心。
(6)备份中心接收差分文件后,将备份文件数据块的元信息写入相应配置文件。同时对于备份文件中每一个新增的数据块,利用传过来的差分文件,将其内容写入相应的备份数据存放位置。
至此一个文件的备份完成。
2.4 数据块判重
SHA1值的长度为20字节,加上数据块的存储信息,一个索引大约需要占用28字节的空间。另外考虑一个数据块的期望大小为8KB,则在备份中心存储4TB的数据至少需要14GB的索引存储空间,无法将索引完全放在内存中,所以需要一个高效的磁盘索引结构来进行数据块判重。本文系统采用了 Google的 Bigtable[9]和 Leveldb[10]的索引算法,并作了一定的简化,加上了布隆过滤器[11]来改善重复数据块的查询效率。
这个索引算法结构如图3所示。当插入一条索引时,操作信息首先写入重做日志中,然后将其存储在一个被称为memtable的内存缓存中。memtable是一颗按索引的键组织的红黑树[12],所以其是按索引的键有序的。当memtable超过一定大小限制后,其被整个刷新到名为sstable的文件中。这样对于索引的插入操作将会有极高的效率,因为在插入操作中无论是写日志文件还是其后将memtable的内容写到sstable文件中都是对磁盘的顺序写。随着sstable文件的增多,它们组织成一个层次结构。内存中有一个sstable的索引可以定位每一层sstable文件的数据范围。在查询操作时,通过sstable索引找到相应的sstable文件,再与当前的mmtable结合以进行数据查询。
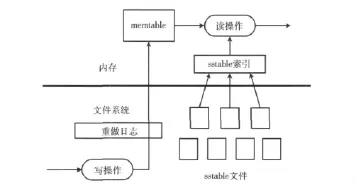
图3 数据块查询索引结构
为了进一步提高查询效率,在该索引结构的上层加入了布隆过滤器。布隆过滤器中记录了所有存在的指纹值,该结构可以极大地节约存储空间,所以可将其全部放入内存中。但布隆过滤器有一定误判率,即一个本来没有的指纹值可能被布隆过滤器判为已经存在。但如果一个指纹值在布隆过滤器中不存在,则它一定不存在。利用此原理在查询指纹值的时候先查询其在布隆过滤器中是否存在,若存在则进一步查询其下层的索引。但如果在布隆过滤器中不存在,则可断定该指纹值一定不存在,从而直接将其插入下层索引中。由于下层索引对于插入操作有很高的效率,这就提高了整个系统查询数据块的效率。另外为了防止宕机事故,布隆过滤器中的内容需要定期写入一个文件中进行持久化。
2.5 数据块存储
备份中心的存储架构如图4所示。
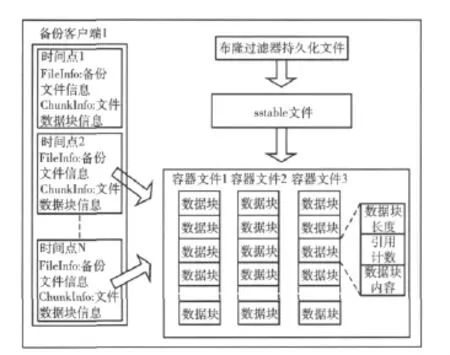
图4 备份中心存储架构
备份中心可以服务于多个备份客户端,所以一个备份客户端对应的备份元信息单独存储在一个目录下。实际备份的数据块则放在一个公共的目录下,其存储在一系列的容器文件中。此外,公共目录下还有持久化的布隆过滤器文件和数据块索引的sstable文件。
存放数据块的容器文件有一定大小限制,当其中的数据超过文件容量时,系统会新建一个容器文件用于存储以后的数据块。在容器文件中,一个数据块包括三项:该数据块的长度,该数据块的引用计数和数据块实际的内容。引入引用计数是为了能够回收数据的存储空间,避免存储空间无限增大。初始插入一个数据块时其引用次数为1,当重复备份一次该数据块时其引用次数加1。当删除一个备份文件时,该文件对应的所有数据块的引用次数都减1。一个后台进程会定期查看每个容器文件,当某个容器文件的每个数据块的引用次数都为0时,则回收该容器文件。
一个备份客户端可以备份多次,这样形成了多个备份时间点。一个备份时间点的备份信息主要由两个文件记录:FileInfo和ChunkInfo。FileInfo中记录了本次所有备份文件信息,包括每个文件的路径,文件的数据块信息在ChunkInfo文件中的偏移,以及文件组成的数据块个数。而ChunkInfo中记录了FileInfo中对应文件的数据块信息,包括每个数据块所在的容器文件序号,数据块在容器文件中的偏移,数据块的大小。这样在恢复备份文件的时候,只需要通过FileInfo找到ChunkInfo中该文件对应的数据块信息,再根据此信息从容器文件中读出相应的数据块,就能完全恢复该文件。
3 实验与分析
实验分别对多个相似的数据集进行完全备份和对一个数据集进行多次增量备份来验证本系统的效能。测试数据集采用解压之后的Linux内核源代码,如表1所示。
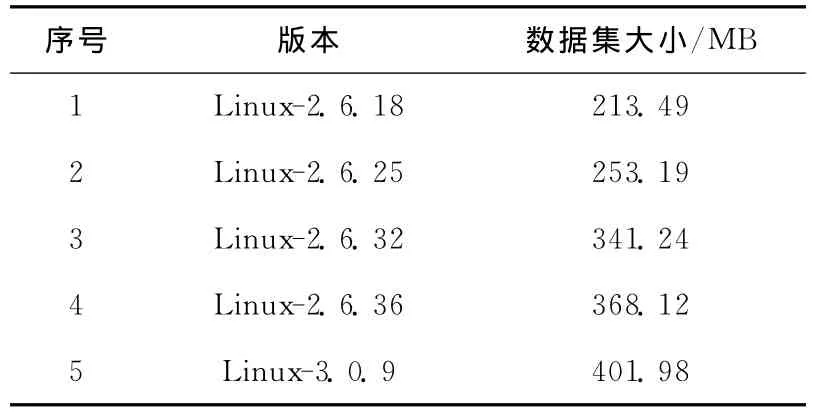
表1 测试数据集
实验环境如下:备份客户端操作系统为Ubuntu 10.04 Desktop,配置为CPU Intel(R)Core(TM)Duo E7500,内存2GB。备份中心操作系统为CentOS 5.5,配置为CPU Intel(R)Core(TM)i5-2300,内存4GB。100Mb/s网络环境。
3.1 相似数据集完全备份
实验方法:用本文系统分别备份表1中5个相似的数据集,查看每次备份的网络流量和增加的存储空间。
表2为以上5次备份实验结果。通过图5可以清楚地看出本文系统对于多个相似的数据集的完全备份,可以有效地删除其中的重复数据,从而减少备份的网络流量和存储空间。
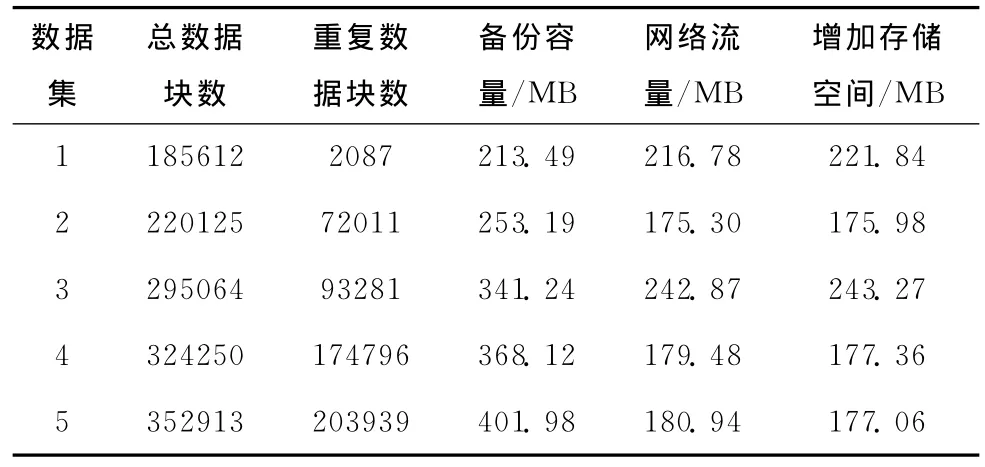
表2 5个数据集完全备份实验结果
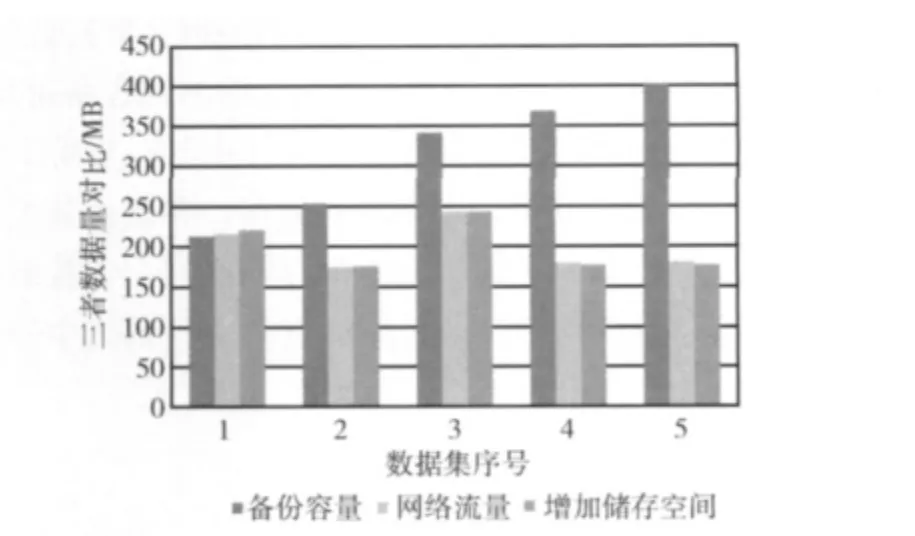
图5 每次备份容量,网络流量及增加存储空间对比
3.2 数据集增量备份
实验方法:分别用本文系统和Rsync备份表1中的数据集3,而后随机修改该备份集下少量文件,再用本文系统和Rsync备份该数据集,比较此次增量备份的网络流量。
表3是修改数据集中不同文件个数下本文系统和Rsync备份的实验结果。通过图6可知,在对同一数据集进行增量备份时,当每次增量变化较小时,本文系统比起Rsync备份网络流量更少。这是由于本文系统相对于Rsync传输的备份元信息较少。但本文系统数据块的判重粒度比Rsync大,当增量备份变化较大时,传输较少的备份元信息不足以补偿增多的增量备份数据。因此用本文系统进行变化较大的增量备份时,效率就不如Rsync了。

表3 本文系统和Rsync增量备份实验结果
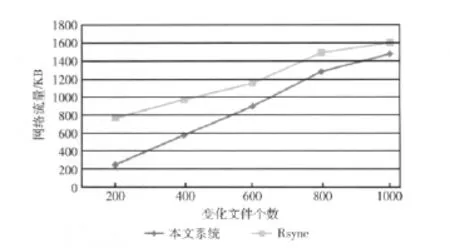
图6 本文系统和Rsync增量备份网络流量对比
4 结束语
在传统远程备份中,应用系统中的大量冗余数据会导致备份效率低下,浪费大量带宽和存储空间。针对此问题,本文设计并实现了一个基于重复数据删除的远程备份系统。该系统在备份文件的时候能够找出文件中已经备份了的重复数据,从而只备份文件中新增的数据,有效地减少了备份网络流量并且节约了备份数据的存储空间。实验结果表明采用本文系统进行远程备份能够有效去除系统中的重复数据,从而提高备份效率。
[1]McKnight J,Asaro T,Babineau B.Digital archiving:end-user survey & market forecast 2006-2010 [EB/OL].http://www.enterprisestrategygroup.com/2006/03/digital-archiving-end-user-survey-market-forecast-2006-2010/,2006.
[2]HAO Yan,Irmak U,Suel T.Algorithms for low-latency remote file synchronization[C].The 27th Conference on Computer Communications,Phoenix,AZ,2008:156-160.
[3]Ghobadi A,Mahdizadeh E H,Yong L K,et al.Pre-processing directory structure for improved RSYNC transfer performance[C].13th International Conference on Advanced Communication Technology,2011:1043-1048.
[4]Tanbeer S K,Ahmed C F,Jeong B S,et al.Efficient singlepass frequent pattern mining using aprefix-tree[J].Information Sciences,2009,179 (5):559-583.
[5]Bobbarjung D R,Jagannathan S,Dubnicki C.Improving duplicate elimination in storage systems[J].ACM Transactions on Storage(TOS),2006,2 (4):424-448.
[6]LIANG Zhengyou,ZHANG Lincai,Duplicated URL detection based on Rabin s fingerprint method [J].Journal of Computer Applications,2008,28 (z2):185-186 (in Chinese).[梁正友,张林才.基于Rabin指纹方法的URL去重算法 [J].计算机应用,2008,28 (z2):185-186.]
[7]AO Li,SHU Jiwu,LI Mingqiang.Data deduplication techniques [J].Journal of Software,2010,21 (5):916-929 (in Chinese).[敖莉,舒继武,李明强.重复数据删除技术 [J].软件学报,2010,21 (5):916-929.]
[8]ZHAO Yu,ZHOU Yujie.IP design and speed optimization of SHA1[J].Information Security and Communications Privacy,2006 (12):125-127 (in Chinese). [赵宇,周玉洁.SHA1IP的设计及速度优化 [J].信息安全与通信保密,2006(12):125-127.]
[9]CHANG F,Dean J,Ghemawat S,et al.Bigtable:A distributed storage system for structured data[J].ACM Transactions on Computer Systems(TOCS),2008,26 (2):4:1-4:26.
[10]Dean J,Ghemawat S.Leveldb:A fast and lightweight key/value database library [EB/OL].http://code.google.com/p/leveldb/,2011.
[11]Kirsch A,Mitzenmacher M.Less hashing,same performance:Building a better bloom filter[J].Random Structures & Algorithms,2008,33 (2):187-218.
[12]Cormen T H,Leiserson C E,Rivest R L,et al.introduction to algorithms [M].3rd ed.The MIT Press,2009.
