增强机构知识库内容发现和利用影响的策略与方法实践
2012-04-29卢利农祝忠明张旺强刘巍姚晓娜
卢利农 祝忠明 张旺强 刘巍 姚晓娜

摘 要:文章以中国科学院机构知识库CAS OpenIR为例,采用基于学术搜索引擎Google Scholar优化的策略和方法,如针对Google Scholar收录原则、Google Scholar元数据体系、sitemaps、Robots协议等策略和方法进行分析和实践,通过提升机构知识库在Google Scholar中的收录比率,进而增强机构知识库中内容被发现引用的机率,以扩大IR利用影响力。
关键词:机构知识库 谷歌学术搜索 学术搜索引擎优化 中科院机构知识库
中图分类号: G252 G255.76文献标识码: A 文章编号: 1003-6938(2012)05-0085-05
1 引言
近年来机构知识库(Institutional Repository,IR)快速稳步增长,已覆盖了大部分知名高校和科研机构。目前在开放获取机构资源库OpenDOAR中注册登记的IR已有2163家[1],除此以外还有相当一部分数量的IR未在OpenDOAR中注册。IR做为支持开放获取的一种重要形式,支持机构实施数字知识资产的长期保存和管理,提高机构及科研人员智力成果的发现几率、传播范围和影响,是吸引机构及科研人员重视和参与IR建设的重要因素。相关的研究也表明,支持开放获取的论文其引用影响可获得25%~250%的提升[2]。 而Arlitsch等人[3]的调查结果显示,当前IR内容被Google Scholar收录的比率总体上维持在10%~30%的水平,甚至有0%的IR(见图1)。也就是说,大部分IR的内容没有得到充分的发现和利用,仍然局限在小范围内进行交流传播。
Google Scholar作为一项针对学者和科研人员的免费学术文献搜索服务,现在已成为学者、研究人员和学生查找专业文献资料的首选工具[4]。其搜索的范围涵盖了几乎所有知识领域的高质量学术研究资料,包括论文、专业书籍以及技术报告等。Google Scholar不但可以过滤普通网络搜索引擎中对学术人士无用的大量信息,通过与众多学术文献出版商的合作,还加入了许多普通搜索引擎无法搜索到的内容。目前,科研用户通过网络来获取资源,第一选择就是通过Google等搜索引擎进行大范围搜索,其次考虑利用专业的学术数据库,最后才会去翻阅学术期刊。这种检索顺序已经形成了一种社会习惯。
因此,如何解决IR被搜索引擎Google Scholar收录,提升IR中学术文章被Google Scholar收录的比率,已成为增强IR内容可发现性和可见性的关键。本文以中国科学院研究所IR平台CAS OpenIR[5]为例,采用学术搜索引擎优化(Academic Search Engine Optimization,ASEO)的策略和方法,通过提升IR在Google Scholar中的索引比率,进而增强IR中内容被发现引用和利用影响力。
2 ASEO策略和目的
ASEO建立在传统的SEO[6]基础之上,是从普通的SEO发展而来。由于学术搜索引擎Google Scholar与普通搜索引擎有着明确的定位区别,因此ASEO与SEO有着明显的不同之处。
SEO指通过采用易于搜索引擎索引的合理技术手段和策略,使网站各项要素适合搜索引擎的检索原则,从而更容易被搜索引擎收录和优先排序。SEO基于网页(Web Page),收录过程较灵活和容易。IR属于学术产出的数据库平台,有着自身的元数据元素集,其中的学术文章属于“Academic Invisible Web”[7],不能被Google Scholar直接访问和索引。因此,在被学术搜索引擎Google Scholar收录前,需要对IR进行ASEO改造,使其符合Google Scholar索引标准,易于被Google Scholar收录爬取。即:
(1) 使IR可以被搜索引擎Google Scholar更好地收录和更新(包括IR的元数据和全文);
(2) 使搜索引擎在规则允许的范围内进行索引,明确IR的哪些页面可以被索引收录,哪些页面不能被索引收录;
(3) 在用户使用Google Scholar搜索时,可以排名靠前的呈现IR中的相关条目,起到推介IR的作用;
(4) 将IR中开放权限的全文纳入Google Scholar的全文检索中,增加IR中论文的可见性,提高论文的被引用率。
3 Google Scholar收录原则和排名算法
Google Scholar针对学术性数据库内容的收录和索引,有明确的收录原则[8],如:① 被收录文章需要有唯一的URL;②匿名用户可免费地通过原文URL进入阅读被收录文章;③数据库服务的Robots.txt协议正确配置,明确允许及禁止Googlebot爬取的路径及内容范围;④数据记录的Meta标签符合Google Scholar Meta规则,并且必须包含DC.title,DC.creator,DCTERMS.issued三项描述元数据;⑤记录除了题录文摘信息外,被收录记录必须要有全文;⑥全文格式为PDF格式。
Google Scholar检索排名继承了普通Google检索中应用的PageRank算法[9],即主要看某项学术内容、页面被引用的情况,同时还将文章全文、作者和出版物等因素纳入算法,从而保证检索结果的高相关性,提高查准率。学术论文被引述的频度越多,一般判断这篇论文的权威性就越高,它的PageRank值就越高。
4 面向IR的ASEO策略与方法实现
根据学术搜索引擎Google Scholar收录、排名的要约特点,本文中笔者将选取ASEO中的关键环节,就设计思路和实现的过程做一分析说明。
4.1 搜索引擎注册
在传统SEO过程中,网站管理员不用太担心网站的收录情况,在网站运行一定时间后搜索引擎的机器人会自动通过已被索引的外部链接发现该网站。而学术搜索引擎ASEO过程中,往往需要通过管理员在Google Scholar中对相关的服务进行注册,来通知机器人将其纳入爬取对象。有鉴于此,在研究所IR部署完成后:
(1)要求或者帮助研究所尽快在Google Scholar中完成其IR的注册和发布。在Google Scholar注册IR过程中,除了声明Google Scholar要求的收录原则外,还需要声明IR所用软件、论文数量、语种、访问地址。
(2)由于Google Scholar的PageRank算法对网络分类目录尤为重视,如果网站被ODP(http://www.dmoz.org)、Yahoo! Directory(http://dir.yahoo.com)等网络分类目录收录,则可大幅提升其PR值。因此,积极帮助研究所IR在重要网络分类目录中进行注册。
(3)随着OpenROAR(http://www.opendoar.org)、ROAR(http://roar.eprints.org)等开放知识库注册登记服务在知识库服务领域日益产生重要影响和Google Scholar等搜索引擎的合作,我们也应积极引导和帮助研究所IR在这些专门性目录服务中进行注册,以加强和提升IR被搜索引擎发现和索引的几率。
4.2 建立适合Google Scholar发现和索引的描述元标签体系
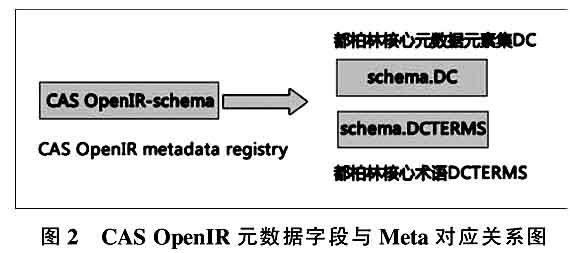
Meta(网页描述元标签)为Google Scholar检索结果的输出格式提供了基于DC元数据标准的标题、作者、出版物名、出版年/期、摘要等内容描述信息。当用户通过Google Scholar进行检索时,Google Scholar自动辨识学术文章的格式与内容,取得描述信息,并针对论文指示的信息建立自动的引用分析。因此,描述元标签及其描述信息十分重要。
要保证IR所有内容为Google Scholar成功索引,就必须为IR所有的记录提供带有Meta描述元标签的页面。为此,在CAS OpenIR中设计Meta标签组为自动生成,不同论文记录页面中的Meta值自动从记录对应的内部元数据字段中读取。由于IR中条目元数据字段为内部元数据存储字段,并不能直接用于Meta标签,因此需要在使用前建立CAS OpenIR元数据字段与Meta之间的映射关系(见图2)[10]。
4.3 构建IR动态网站地图
由于目前大部分搜索引擎只跟踪网站内有限数量的链接,例如Google并不会主动抓取网站的所有页面,尤其是网址里带有“?”的动态链接。因此,当网站较大时,例如IR会随着学术产出的逐年不断增长而页面快速增多,就必须有有效的策略来保证IR中每一条记录目页面都可以被搜索引擎收录。目前来看,通过生成和提供网站地图(sitemap)已成为一种相对可靠的策略和方法。
在Google官方指南中可看到,网站生成SiteMap文件将有利于搜索引擎机器人的索引,会大大提高索引网站内容的效率和准确度。SiteMap主要有以下作用[11]:
*为搜索引擎机器人提供可以浏览整个网站的链接;
*为搜索引擎机器人提供一些链接,指向动态页面或者采用其他方法比较难以到达的页面;
*作为一种潜在的着陆页面,可以为搜索流量进行优化;
*如果访问者试图访问网站所在域内并不存在的URL,那么这个访问者就会被转到“无法找到文件”的错误页面,而网站地图可以作为该页面的“准”内容。
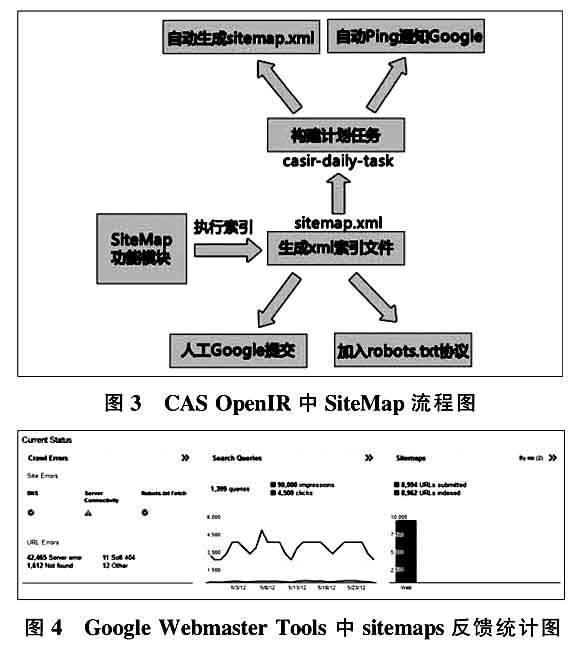
目前sitemap地图在网站应用中越来越受重视,但是人工制作sitemap地图的难度随着网站网页数目的增多也变得越来越困难。因此,CAS OpenIR系统中设计增加了自动生成和发布SiteMap的功能,系统自动索引内部所有记录页面生成索引文件(SiteMap),不限制数量和深度。CAS OpenIR中SiteMap流程图(见图3)如下:
①SiteMap模块触发索引机制后生成sitemaps文件,一般会根据系统内页面链接的数量生成1个主索引文件(索引文件的索引文件)和10~50个二级索引文件。
②在创建好站点地图后,需要主动将其提交给搜索引擎,节省收录时间。使用Google Webmaster Tools工具提交sitemaps后,会生成相应报表(见图4),显示已提交URLs数量、被收录URLs数量、被搜索信息、URL错误信息等。
③使用rebots.txt文件中添加sitemap地址的来自动提交sitemap。
④编写批处理脚本文件,以触发时间节点的定时执行sitemap索引任务。
⑤通过Ping请求向google提示。Ping是基于XML_RPC标准协议的更新通告服务,用于内容更新快速通知给搜索引擎,以便搜索引擎及时进行抓取和更新。因此当IR中内容发生了改变,会生成不同的sitemap索引文件,此时需要通过Ping请求通知搜索引擎进行重新收录。
4.4 其他ASEO策略和方法
在CAS OpenIR支持ASEO优化过程中,同时采用了以下多种辅助性的策略和方法来进一步丰富和完善其整体ASEO方法框架。
(1) 优化配置Robots协议文件。通过界定Robots搜索引擎收录规则,告知Google Scholar机器人哪些页面可以收录,哪些页面不能收录。同时使用 Robots协议告知搜索引擎有关站点地图SiteMap的信息。在robots.txt 文件中包含SiteMap链接的好处是,开发人员不用到搜索引擎的站点管理员页面去提交自己的sitemap文件,搜索引擎的机器人会主动抓取robots.txt,读取其中的sitemap路径,接着进行相关页面的抓取和索引。
(2) 动态URL优化。IR的一些页面使用动态的URL,往往附带有很多参数,并比较长,会不利于搜索引擎收录和提升排名。因此,这对这一问题,主要通过URL重写的方法[12]进行了优化调整,以获得伪静态和简洁友好的URL网址。如IR动态生成的URL地址http://[IR域名]/profile?action=eperson-profile&unique_id=0-000343,通过重写和优化后将成为 http://[IR域名]/ unique_id=0-000343。
(3) 英文场景SEO优化。解决英文场景下的Google Scholar对IR的收录和索引。CAS OpenIR目前通过定制中英文字符集,提供中文、英文两种字符描述,在英文环境下,栏目分类、导航、指引文字均为英文描述,并且页面Meta标签组包含有英文题名、英文关键词、英文摘要,可以被搜索引擎英文状态所搜索收录。
5 ASEO实践效果
CAS OpenIR在ASEO前,学术内容在Google、Google Scholar中被索引的情况较不理想。本文选择未进行ASEO功能优化的中科院遥感所IR(http://ir.irsa.ac.cn)为例, 其中内容2906条,Google Scholar中被索引率为0(见图5)。
经过ASEO技术全面改进后,在Google Scholar中,笔者以中科院国家科学图书馆机构知识库(http://ir.las.ac.cn)为例进行搜索,显示“About 516 results (0.14 seconds)”。意即这516篇论文不仅题录信息,其全文也纳入了Google Scholar的全文检索。
6 结语
增强IR内容发现和利用影响非朝夕工作,是一项系统工程,需要大量的积累和尝试。其中ASEO过程已不仅是技术,而是一种思想,一种策略,许多技巧的组合。通过ASEO策略可以将机构知识库收录入学术搜索引擎中,在科研人员和学生使用搜索引擎科研过程中,无缝推介和曝光IR内容。下一步,我们会继续提高CAS OpenIR学术内容在搜索引擎中的索引收录率,使IR和其中的论文得以充分可见,积极提高IR内容发现和利用影响力。本文中基于SEO策略的增强知识内容发现和利用影响的实践过程,对其他数字图书馆服务系统也有着积极的借鉴作用和意义。
参考文献:
[1]OpenDOAR chart[EB/OL].[2012-06-18].http://opendoar.
org/find.php?format=charts.
[2]Brody, T. and Harnad,S. Comparing the Impact of Open Access (OA) vs. Non-OA Articles in the Same Journals[J/OL].[2012-07-10].http://eprints.ecs.soton.ac.uk/10207/.
[3]Arlitsch,K.and O'Brien P.Invisible institutional repositories: Addressing the low indexing ratios of IRs in Google Scholar [J].Library Hi Tech, 2012, 30(1):60-81.
[4]苏悦,张文德.Google Scholar与现代图书馆[J].情报探索,2007,(11):10-12.
[5]祝忠明.中国科学院机构知识库建设软件[R].Post-Co
nference of Berlin 8 Open Access Conference,2010.
[6]Search Engine Optimization(SEO)[EB/OL].[2012-05-25].http://zh.wikipedia.org/wiki/SEO.
[7]Dirk Lewandowski,Philipp Mayr.Exploring the Academic Invisible Web[J].Library Hi Tech. 2006,24(4):529539.
[8]Google.Inclusion Guidelines for Webmasters[EB/OL]. [2012-06-18].http://scholar.google.com/intl/en/scholar/inclusion.html.
[9]Page,L.,Brin,S.,Motwani,R.andet al.The PageRank Citation Ranking: Bringing Order to the Web[EB/OL].[2012-06-18].http://citeseerxist psu.edu/viewdoc/summary?doi=10.1.1.31.1768.
[10]Dublin Core Collection Description Application Profile[EB/OL].[2012-05-10]. http://www.ukoln.ac.uk/meta
data/dcmi/collection-application-profile/.
[11]Sitemap[EB/OL].[2012-05-18].http://zh.wikipedia.org
/wiki/Sitemap.
[12]Rewrite engine[EB/OL].[2012-02-25].http://en.wikpe
dia.org/wiki/Mod_rewrite.
作者简介:卢利农(1985-),男,中科院国家科学图书馆兰州分馆馆员;祝忠明(1968-),男,中科院国家科学图书馆兰州分馆研究员;张旺强(1985-), 男,中科院国家科学图书馆兰州分馆馆员;刘巍(1980-),男,中科院国家科学图书馆兰州分馆馆员;姚晓娜(1985-),女,中科院国家科学图书馆兰州分馆馆员。
