一种基于openVPX 的通用信号处理平台设计
2012-03-18许烈华
许烈华
(中国西南电子技术研究所, 成都610036)
1 引 言
基于传统分级共享式并行总线的处理平台(如CPCI、VME 等平台),总线时钟频率和总线接口宽度决定了处理平台的基本性能,为尽可能提高性能,器件厂家推出了一系列的改进,如提高总线时钟频率、拓宽总线接口宽度等。比如PCI 总线速度从33 MHz提高到66 MHz,总线宽度从32 bit变成64 bit。虽然这些改进对性能有一定的改善,但是能力有限,且任意节点间不能自由通信,导致系统设计不够灵活。正因为此,基于共享式并行总线的处理平台的发展已受到瓶颈限制,达到了其极限性能。但是随着通信带宽的越来越宽、雷达和图像处理分辨率的越来越高以及对实时处理性能的需求,对处理平台的性能提出了更高的要求,需要更高的总线传输带宽、更强的运算能力和更灵活的数据交互能力[1]。
针对这种应用需求,本文提出了一种新的处理平台解决方案,重点对该处理平台的总体构架、背板、拓扑网络和处理模块进行了详细的分析设计,给出了处理平台的总线传输带宽指标。
2 openVPX 发展历程
1987 年出现的VME32 总线带宽达到40 Mbit/s,为不断提高带宽,VME 进行了一系列的改进,比如后来的VME64、VME2eSST 和VXS,带宽分别提到了80 Mbit/s、320 Mbit/s和3 Gbit/s。在2007 年加入到ANSI 的VPX,采用串行RapidIO 总线,进一步增加了带宽,同时集成了更多的IO 和扩展了格式布局。VPXREDI 主要对VPX 的结构和制冷等方面进行规定,解决性能大幅提高的同时带来的功耗增加和可靠性降低等问题。
但是在VPX 的推广使用过程中,发现各个厂商的模块与背板的通用性较差,同时VPX 在初期还留有VME 的某些痕迹,比如VITA46.1 专门对VME 进行了定义,再者VPX 自身也缺乏足够的背板互连规范来支持最大化应用自身的优势。为解决这些问题,2010 年VITA(VME 国际贸易协会组织)成员在VPX 的基础上制定了openVPX 标准。openVPX 仍然采用VPX 的机械尺寸、制冷方式、供电方式和通信协议,但它对当前VPX 市场进行了通用化的统一规定,它定义了节点、背板和模块等三大类的标准架构,每一类里面详细描述了各种应用模型。另外,在openVPX 中,完全摒弃了VME 的痕迹,在带宽方面进一步提高,单通道速率达6.25 Gbit/s,同时改变了VPX 中单一交换的网络结构,采用了多交换的网络结构[2]。图1 展示了openVPX 的发展历程。

图1 openVPX 发展历程Fig.1 History of openVPX
3 处理平台硬件设计
3.1 总体设计
笔者在某工程应用中遇到的如下需求:
(1)16 通道采样,实时数据总传输率42 Gbit/s;
(2)同时形成8 个数字波束的运算能力;
(3)具备数据记录、回放及DA 转换的功能。
根据这一需求,经过大量论证和反复方案比较,最终选取了基于openVPX 标准的处理平台方案。该处理平台主要完成16 通道的中频信号采样、数字波束预合成、合成、校正及数据记录等功能,处理平台的组成框图如图2 所示。其中,主控模块完成处理平台的初始化、交换网络动态管理、状态监测和对外接口;AD 模块共2 个,每个完成8 通道的模拟信号的采样以及数据的预处理;处理模块共3 个,各种算法在其上实现,一个完成左边8 路信号的预合成,另一个完成右边8 路信号的预合成,在第三个处理模块上完成和、差数字波束合成及校正的运算;存储模块完成数据的固态存储,以便于事后分析;DA 模块实现数字信号到模拟信号的转换,产生校正信号;交换模块为在同一数据网络上的各种模块提供数据交换,根据路由表信息完成不同模块间的数据通信。
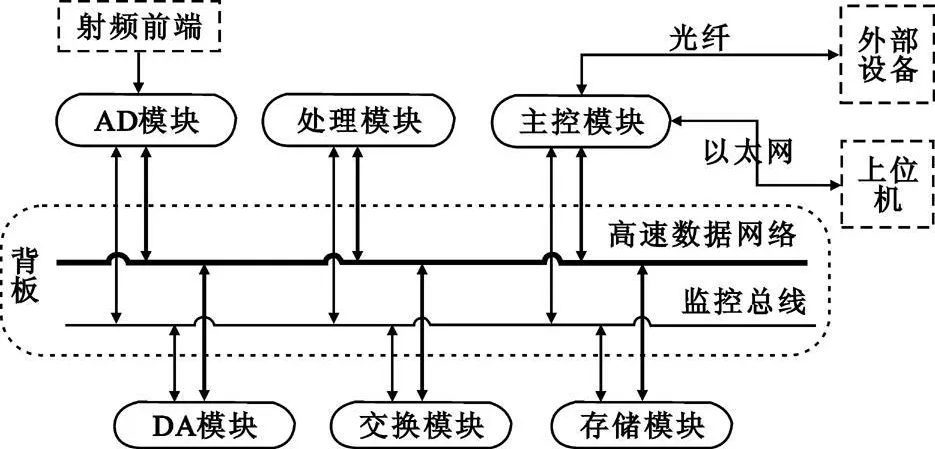
图2 处理平台组成框图Fig.2 Composition diagram of processing platform
模块间数据通信采用串行RapidIO 总线[3]。本方案中使用RapidIO Level Ⅱ协议, 单通道速率6.25 Gbit/s。本来RapidIO 只支持点对点的通信方式,但是处理平台中有交换模块,且交换模块为全交换结构,则可实现任意节点间多点对多点的通信。比如,处理平台中,可实现AD 模块与处理模块间的通信,在同一时刻,也能实现存储模块与DA 模块间的通信,前后两组间的通信完全独立同时进行。通过重新配置交换模块的路由表信息,不需要改变任何硬件,很容易实现把从AD 模块与处理模块间的通信切换到AD 模块与存储模块间的通信。图3 为处理平台的RapidIO 网络示意图。
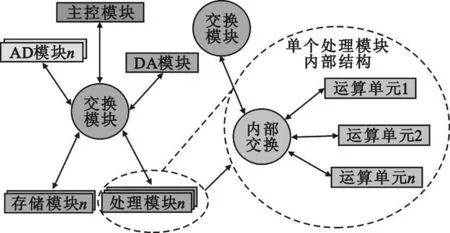
图3 RapidIO 网络示意图Fig.3 Diagram of RapidIO network
同样,处理模块内部也采用串行RapidIO 交换结构,模块内不同的运算单元(比如DSP 或FPGA)挂在同一RapidIO 网络上,任意运算单元可实现多点对多点的通信。采用这种架构明显的优点在于:系统对各运算单元的忙闲情况动态监测,根据监测情况,动态分配路由表,从而改变数据流的方向,最终实现动态分配运算单元的功能,使各运算单元的忙闲相对平衡。通过动态监测与分配,很容易实现并行处理,达到提高系统处理能力和效率的目的。
3.2 背板及拓扑网络
处理平台采用openVPX 中定义的标准背板形式,背板拓扑标准为BKP6-CEN10-11.2.4-3。背板中共定义了5 个层,分别是扩展层、数据层、控制层、管理层和电源层[2]。扩展层为相邻槽位间数据传输,数据层分为两种,一种是与交换槽位的连接,另一种是相邻槽位间的连接。控制层只与交换槽位有连接。管理层定义了两对差分线,每个槽位的差分线物理上连在一起。电源层用于给各模块供电。
在该处理平台中,扩展层设计为相邻槽位间FPGA 的高速收发器(GTX)的数据传输,GTX 通道数为8 个,每通道速率5 Gbit/s。数据层设计为3 个4×的串行RapidIO 接口,每通道速率6.25 Gbit/s,与交换槽位2 个接口,相邻槽位间1 个接口。控制层设计为2 个1×的串行RapidIO 接口,每通道速率为1.25 Gbit/s。管理层设计为低速控制和监视总线用的CAN 总线。图4 为处理平台中高速数据通道的拓扑网络图,图中4 个交换芯片位于交换模块上,交换模块标准为SLT6-SWH-20U19F-10.4.1。VPX1 为主控模块,VPX2、9 为存储模块,VPX3、8 为AD 模块,VPX4、5、7 为处理模块,VPX10 为DA 模块。

图4 数据通道拓扑网络图Fig.4 Network topology of data channel
该处理平台采用双星型网络拓扑。双星型网络拓扑有两个优点,一是解决单个交换芯片端口数量不够问题,二是提高了网络的可靠性,当一个网络出现问题时,另一网络可以作为备份。图4 中上半部分为数据层的拓扑,采用4×的RapidIO 接口,每个节点模块分别有一个接口与交换芯片1 和2 相连。下半部分为控制层的拓扑,采用1×的RapidIO 接口,每个节点模块分别有一个接口与交换芯片3 和4 相连。另外,相邻模块间,还有一个4×的RapidIO接口和8 通道的GTX 接口。
3.3 处理模块设计
处理模块为处理平台中的重要模块,模块符合openVPX 中的SLT6-PAY-4F1Q2U2T -10.2.1 标准。处理模块原理框图如图5 所示。
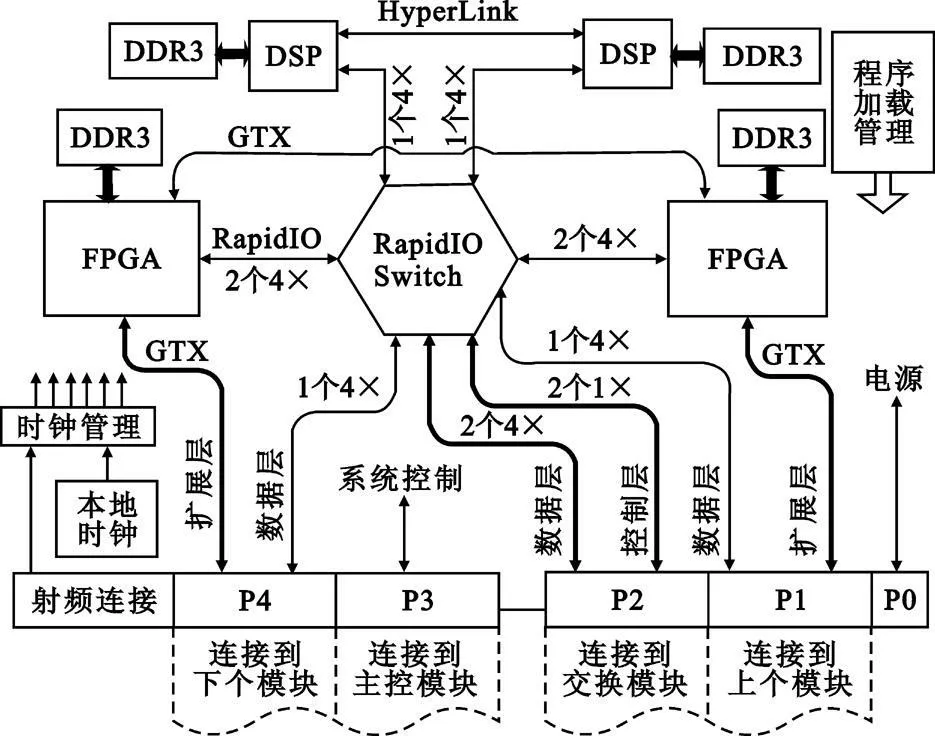
图5 处理模块框图Fig.5 Block diagram of processing module
模块主要由高性能的DSP 和FPGA 器件、交换芯片和DDR3 存储器构成, DSP 选用TI 公司的C6678 芯片,FPGA 选用Xilinx 公司virtex6 系列的SX315T,交换芯片选用IDT 公司的CPS1848 芯片,连接器采用tyco 公司VPX RT2 连接器。模块内部及对外均采用RapidIO 接口,单通道6.25 Gbit/s。模块支持通过RapidIO 网络动态加载程序。
3.4 信号完整性设计与测试
在本方案中, 板内及板间的传输速率为6.25 Gbit/s,信号的上升时间在1 ns以内,信号完整性问题,诸如串扰、阻抗匹配、EMI、抖动等不容忽视。在本设计中,主要从高速印制板设计和高速信号测试等方面来分析与解决信号完整性问题。
在印制板设计方面,采用安捷伦的ADS 仿真工具,对高速传输线、关键器件、关键接插件等进行仿真和建模。通过前仿真解决走线的阻抗连续性、过孔效应、走线间耦合等问题。在电路板已经制作后,根据测试结果,对电路板进行建模并后仿真,进而分析测试结果,指导电路板改进。
在高速信号测试方面,采用高性能的数字示波器、逻辑分析仪、误码率分析仪等对实际的信号进行测试分析,包括波形参数测量、眼图/抖动测量、一致性测量、协议分析和误码率测量等。通过测试,一方面检测系统是否满足规范和设计要求;另一方面在测试过程中,为每个器件的预加重、去加重、预均衡、均衡等参数的最佳选择提供依据。
4 性能分析
处理平台的性能主要从两方面进行分析,一是传输带宽的计算,二是运算能力的分析。传输带宽的计算分两种情况,一种是任意模块间,另一种是相邻模块间,如表1 和表2 所示。RapidIO 为8B/10B 编码,因此编码效率为0.8,且RapidIO 基于包传输方式,除去包头开销,有效载荷数据效率只有0.9 左右[3]。
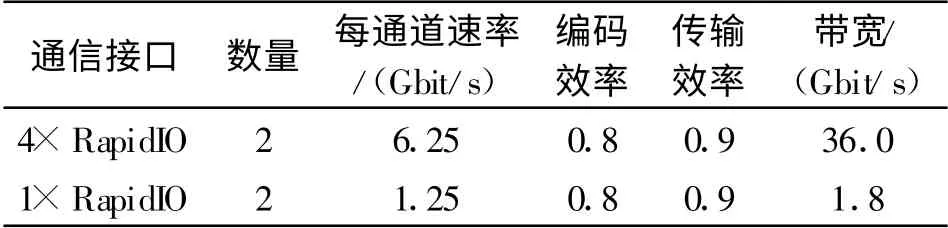
表1 任意模块间传输带宽Table1 Bandwidth between any module
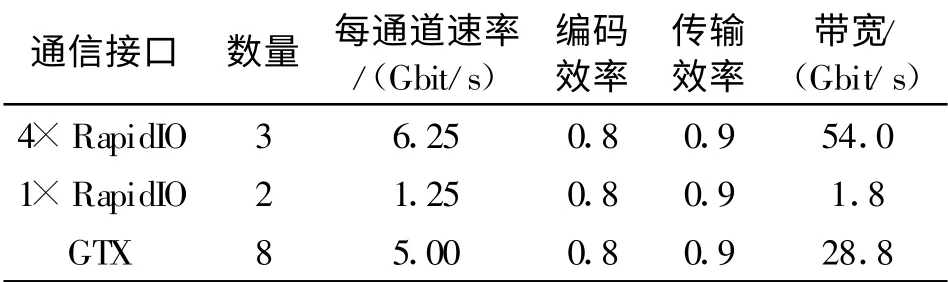
表2 相邻模块间传输带宽Table2 Bandwidth between adjacent module
由表得知, 任意模块间的传输带宽为37.8 Gbit/s,相邻模块间的传输带宽为84.6 Gbit/s。基于共享式并行总线的处理平台的带宽约为4 Gbit/s,相比之下,带宽有数量级的提升,显著提高了处理平台的传输带宽。
在运算能力方面,处理平台采用高性能的DSP和FPGA 芯片, 运算能力大大提高。FPGA 采用40 nm技术的virtex6 系列的SX315T,相比65 nm技术的virtex5 系列的SX95T,在逻辑资源、接口支持的速度、系统运行速度等方面都有较大的提升,同时功耗有所降低。
5 结 论
本文在openVPX 标准体系下,构建了一种新型的高性能处理平台,平台采用高速串行RapidIO 总线作为模块之间和模块内节点间的高速数据通道,采用双星型的交换网络结构,既能保证高的传输带宽,又具有高的可靠性,通过软件动态改变路由,从而改变数据流路径,可大大提高系统设计的灵活性。处理平台的总体架构与模块接口定义满足openVPX 标准,具有较强的通用性,可应用于总线带宽和实时性要求高的宽带通信、对抗、雷达或图像处理等领域。
[1] 杨小牛, 楼才义,徐建良.软件无线电技术与应用[M] .北京:北京理工大学出版社, 2010:251-252.
YANG Xiao-niu,LOU Cai-yi,XU Jian-liang.Software Defined Radio Technology and Application[M] .Beijing:Beijing Institute of Technology Press, 2010:251-252.(in Chinese)
[2] ANSI/VITA65-2010,Open VPX System Specification[ S] .
[3] Sam Fuller.Rapid IO 嵌入式系统互连[M] .王勇, 译.北京:电子工业出版社,2006:202-255.
Sam Fuller.RapidIO:The Embedded system Interconnect[M] .Translated by WANG Yong.Beijing:Publishing House of Electronics Industry, 2006:202-255.(in Chinese)
