一种改进的自适应增强-支持向量回归机的故障预测方法
2012-02-23邓森景博周宏亮朱海鹏刘小平
邓森,景博,周宏亮,朱海鹏,刘小平
(1.空军工程大学 工程学院,陕西 西安710038;2.93050 部队,辽宁 丹东118000)
0 引言
故障预测技术是系统预测与健康管理(PHM)中的关键技术,通过分析与判断预测对象的结构特性、参数、环境条件以及历史数据,实现对设备运行状态的监控并预报故障发展的趋势。
支持向量机(SVM)在解决小样本回归问题时具有速度快、精度高以及鲁棒性强等方面的优势。然而当系统发生突变故障时,传统的支持向量回归(SVR)故障预测方法精度较低。自适应增强算法(AdaBoost)可以将弱学习算法提升为强学习算法,采用AdaBoost 算法可以提升SVR 的预测性能。文献[1]提出了基于分类损失函数的AdaBoost-SVR 回归算法,提升了SVR 回归模型的性能。文献[2]提出了基于AdaBoost 算法的组合SVM 模型来改善软测量模型的估计精度与泛化能力。文献[3]提出了基于模糊AdaBoost 算法的SVR 进一步提升了预测模型的精度。
突变故障发生时间短暂、测量困难、出现故障前无明显征兆,通常表现为数据中的奇异点与突变点。标准SVM 算法中结构风险函数具有较好的平滑性对数据具有平滑作用,消除了数据中部分突变点的影响,导致难以精确预测某些突变故障。针对此问题,本文提出了一种改进的AdaBoost-SVR 方法用来提高突变故障的预测精度。该方法采用AdaBoost方法获取突变点的权值,构造加权SVR 回归机来增强对此类突变点的训练,提高AdaBoost-SVR 对突变故障的预测精度。利用自适应权重裁减的AdaBoost算法剔出权重较小的样本点,提高算法的训练速度。最后将本文方法与标准SVR 、AdaBoost-SVR 预测方法进行了对比,进一步验证了该方法的有效性。
1 AdaBoost-SVR 算法原理与分析
AdaBoost 算法可以将弱学习算法提升为强学习算法,其基本思想是加强对容易错误分类样本的学习。近年来通过对标准算法进行改进,出现了许多改进AdaBoost 算法[4-6],使其在分类性能上明显提高。AdaBoost 算法主要解决分类问题,将其运用于回归问题时需要引入损失函数来计算训练样本估计值与真实值的误差。在AdaBoost-SVR[7]算法中,将SVR 作为弱学习算法,在AdaBoost 算法中通过构造损失函数来更新样本的权值,最终得到样本的估计值。算法如下:
定义包含m 个样本数据的训练样本集S ={(x1,y1),…,(xi,yi)},i=1,2,…,m.给定SVR 的参数,以及最大迭代次数T.ωt(i)表示第i 个样本经过SVR 学习t 次后获得的权值。最大允许误差的门限值δ >0.
1)初始时假设所有样本的权值相等,均为ω1(i)=1/m.
2)令t=1,2,…,T.
根据SVR 算法得到回归函数ht(xi),并计算错误率errt=∑ωt(i),其中|yi-ht(xi)| >δ.若errt>1/2,则退出循环。
置αt=log[(1 -errt)/errt]/2,同时通过下式更新样本权值:

至此,循环结束。
3)循环结束后得到最终的回归函数为

2 改进的AdaBoost-SVR 算法
突变故障通常表现为训练数据中的奇异点与突变点,SVR 回归机的结构风险函数具有较好的平滑性,在训练时对样本有平滑作用,剔除了某些奇异点与突变点。AdaBoost-SVR 算法训练样本时,由于突变点被错误分类的概率较大,因此突变点在训练时被赋予较大的权值。新SVR 回归机将重点对此类突变点进行训练,提升回归机对样本中突变点的敏感程度,从而提高了对突变故障的预测程度。
改进的AdaBoost-SVR 算法采用加权SVR 对不同的训练样本赋予相应的权值进行训练,不仅能够提高SVR 的训练精度,同时增强算法的鲁棒性。采用自适应权重裁减的AdaBoost 算法舍去权重较小的样本点,来提高AdaBoost-SVR 训练速度。
2.1 加权支持向量回归机
在标准SVR 中,所有训练数据的权重都是相同的。但是在训练过程中,不同数据的重要性是有所区别的。在研究突变故障时,需要对数据中的突变点赋予较大的权值,从而提高对突变故障数据点的训练精度。
本文采用了加权SVR 方法[8],增加了样本中突变点的惩罚程度,通过非线性映射φ()构建线性回归函数h(x)=wTφ(x)+b.加权SVR 算法如下:

式中:ξi与ξ*i为松弛变量;ε 为线性ε 不敏感损失函数的参数;C 为惩罚参数。加权SVR 的求解方法可参考文献[8].
与传统SVR 回归机不同,加权SVR 对每个训练样本定义一个权系数ω(i),其初始值为1/m.在本文算法中,该权系数通过AdaBoost 算法迭代更新。
2.2 自适应裁剪AdaBoost 算法
AdaBoost-SVR 算法的运算速度较慢,运算耗时主要在每次迭代需对SVR 进行训练上。当训练样本数据量较大时,算法的训练速度很慢,无法满足实时故障预测的要求。
权重裁减方法可以有效解决此问题,裁减系数λ 定义为每次剔除的训练样本权重之和。静态权重裁剪算法[9]中通过减少每次迭代时加权SVR 所采用的训练样本个数来提高算法的速度,但该方法裁剪系数为恒定值,如果选择不当将无法达到训练要求。本文提出了自适应权重裁剪算法来克服上述问题,首先计算当前SVR 的错误率,当训练样本的加权错误率较大时,自适应减小本次迭代的裁剪系数,即增加当前SVR 的训练样本个数,从而增强回归机的训练效果。具体步骤如下:
1)设置初始裁剪系数λ0;
2)利用当前赋权样本集{S,ωt(i)}以权重按大小依次排列并计算回归错误率errt.从权重最小的训练样本开始,将其权重依次相加获得权重和为λ的样本集,从样本集{S,ωt(i)}中剔除这部分样本得到裁剪后的样本集{Scut,ωtcut(i)},将其输入当前SVR 进行训练,获得新的回归函数ht(xi)';
3)将赋权样本集{S,ωt(i)}输入ht(xi)',计算错误率err't= ∑ωt(i),I{|yi-ht(xi)| >δ};
4)当回归错误率err't=0 或者err't≥0.5 且Scut=S时,停止迭代。当err't≥0.5 且Scut≠S 时,采用下式更新裁剪系数λ,
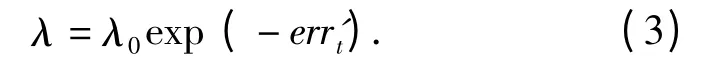
根据负指数函数性质,当err't较大时,裁减系数较小可以增加训练样本个数,提高训练精度。err't较小时,裁减系数较大可以减少训练样本个数提高算法的训练速度。自适应裁减AdaBoost 算法不仅提高了训练速度,也避免了系数选择不当造成的影响。
2.3 算法步骤
基于前述,改进的AdaBoost-SVR 算法的步骤如下:
给定训练样本集S ={(x1,y1),…,(xm,ym)},给定SVR 的参数,以及最大迭代次数T.ωti表示第i个样本经过SVR 学习t 次后获得的权值。最大允许误差的门限值δ >0.
2)令t=1 到t=T.
根据2.1 节所述采用加权SVR 算法得到回归函数ht(xi),计算错误率errt= ∑ωt(i),其中|yi-ht(xi)| >δ.
3)根据2.2 节采用的自适应裁剪算法获得权重裁剪后的赋权样本集{Scut,ωtcut(i)}以及新的回归错误率err't和裁剪系数λ.
置αt=log[(1 -err't)/err't]/2,同时通过下式更新样本权值:
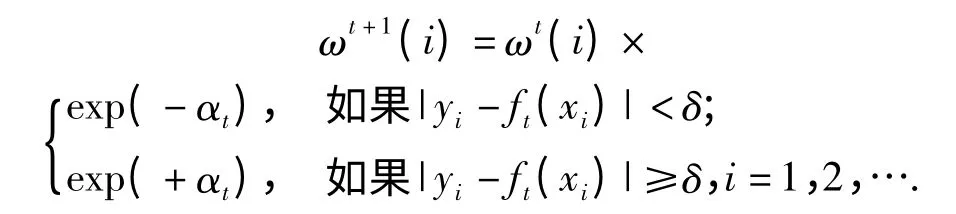
循环结束
4)循环结束后得到最终的回归函数为

3 故障预测模型与步骤
3.1 故障预测模型
故障数据可以采用时间序列分析的方法进行研究,SVR 方法是非线性系统时间序列预测的重要方法。利用本文算法进行故障预测的关键是建立历史量测数据与未来时刻数据之间的映射关系。即基于加权支持向量回归建立预测值x(k +1)与历史数据x(k)=[x(k),x(k-1),…,x(k -p +1)]之间的时间序列映射f:Rp→R,其中p 为嵌入维数。已知n 个故障历史数据构造改进AdaBoost-SVR 算法的学习样本如下,其中输入样本为
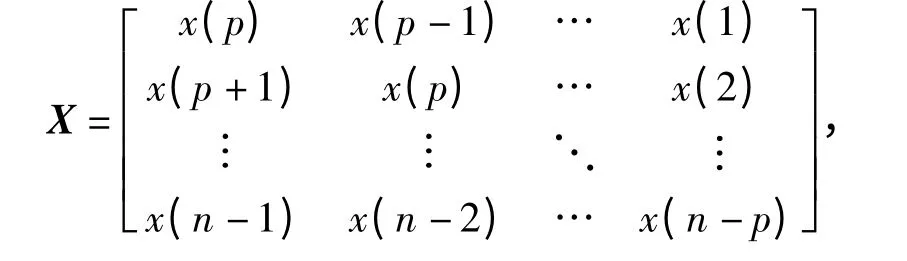
输出样本为
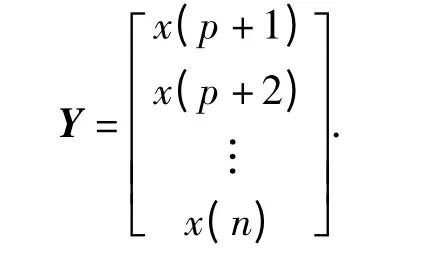
根据2.1、2.2 节方法对学习样本进行训练并获得预测函数F(x),通过预测函数计算单步预测值

3.2 预测步骤
基于改进AdaBoost-SVR 算法的故障预测步骤如下:
1)从故障历史数据中提取时间序列,将故障数据分为训练样本集与测试样本集,并选取嵌入维数。
2)选择SVR 的核函数与核参数,初始化自适应裁剪系数λ0,算法迭代次数T.
3)根据2.1 节构造加权SVR 对训练样本集进行训练,得到训练样本的估计值。
4)根据2.2 节自适应权重裁剪AdaBoost 算法更新样本权重与计算加权错误率,如需更新裁剪系数则根据(3)式计算。判断是否满足训练停止条件,如不满足,以当前裁剪系数返回步骤3,否则训练完毕。
5)将测试样本集输入训练好的T 个加权SVR回归机,根据(1)式计算改进Adaboost-SVR 算法的预测值,并根据3.1 节方法计算测试样本的单步与多步故障预测值。
由上述步骤得到预测算法流程图如图1所示。
4 故障预测实例与分析
SVR 已成功应用于航空发动机金属含量的时间序列预测中。但由于历史数据中存在突变点,对网络进行训练时,这些点被SVR 网络平滑,造成预测精度不高,难以对某些突发性金属含量超标故障进行预测。为验证本文算法的有效性,在某发动机一次换油到另一次换油之间的完整工作阶段内,选取等时间间隔采样得到的66 个外场滑油光谱分析数据。因发动机滑油监控主要以Fe 元素为对象,因此对Fe 元素含量的时间序列进行预测。当Fe 元素的含量超标时认为发动机部件磨损严重,出现故障。通常情况下,Fe 的含量达到1 μg/g 以上时为告警值,达到1.4 μg/g 时以上时为故障值。

图1 故障预测算法流程图Fig.1 The flow chart of fault prognostic algorithm
采用文献[10]中的方法对Fe 元素光谱分析数据序列进行预处理,得到Fe 金属含量的时间序列{x(k)}如图2所示。

图2 Fe 元素含量的时间序列Fig.2 The time series of Fe iron content
取时间序列中的前33 个样本作为训练样本,后33 个为测试样本。根据3.1 节方法构造时间序列,其中嵌入维数p=5,采用标准SVR 方法对样本进行训练,其中参数C =100,ε =0.01,核函数取高斯核函数,其参数σ 为0.5.将测试样本输入训练好的回归网络,得到其一步预测结果如图3。
从图3可以看出,测试样本中5、22 采样点的金属含量达到故障值,标准SVR 回归机的预测值为警告值,2、17 采样点的金属含量达到告警值,标准SVR 回归机未能预测。由于时间序列中含有多个突变点,标准SVR 回归机对训练样本的平滑作用减小了训练样本中的突变数据对当前预测值的影响,导致对突变点的预测精度不高。

图3 标准SVR 算法得到的一步预测结果Fig.3 The results of one step forecast using standard SVR
采用本文的改进AdaBoost-SVR 算法对样本进行训练,设初始裁减系数λ0=0.3,算法迭代次数T=20,误差门限δ =0.01,加权SVR 的参数与以上标准SVR 算法的参数相同。将测试样本输入训练好的回归网络,得到本文算法的一步预测如图4所示。分别计算标准SVR、AdaBoost-SVR 与本文预测模型的1~3 步预测值,根据文献[7]计算两种算法各步预测的相对误差值,如表1所示。

图4 改进Adaboost-SVR 算法得到的一步预测结果Fig.4 The results of one step forecast using Adaboost-SVR

表1 预测相对误差比较Tab.1 The comparison of relative error in prediction
从图4、表1的预测结果可以看出,采用本文算法对样本进行训练,每次迭代时都对样本数据中回归误差较大的突变点赋予了较大的权值,在下一次迭代中增加对突变点训练,从而对突变故障取得了较好的预测效果,但同时剔除了训练样本中权值较小的样本点,使其预测精度略低于Adaboost-SVR 算法。
将Adaboost-SVR 与本文预测算法对样本的训练时间与故障预测总时间进行比较。本文的所有实验均在英特尔双核E2140,内存1 GB,windows XP和Matlab 7.1 环境下在完成。结果如表2所示。

表2 预测性能比较Tab.2 The comparison of performance in prediction
本文算法由于采用了自适应权重裁剪的Ada-Boost 算法,通过减少每次迭代时SVR 所采用的训练样本个数,降低加权SVR 输入样本的维数,从而提高算法的速度。能够在满足精度的同时实现飞机发动机的实时监控与故障预测。
5 结论
本文提出了一种改进的自适应增强算法提升SVR 的对突变故障的预测性能。将AdaBoost 算法与加权支持向量机相结合,通过AdaBoost 算法获得突变点的权重,采用加权SVR 增强对其训练,有效地提高了算法对突变故障的预测精度。利用自适应权重裁减的AdaBoost 算法舍去权重较小的样本点,减少加权SVR 的训练样本来提高本文算法的训练速度。结合航空发动机金属含量的时间序列预测,验证了算法的有效性与快速性。
References)
[1] Lin G,Peng K,Feng G,et al.Adaboost regression algorithm based on classification type loss[C]∥Proceedings of the 8th Wolrd Congress on Intelligent Control and Automation,Jinan:School of Control Science and Engineering,Shandong University,2010:978 -982.
[2] 杨慧中,邓玉俊.基于自适应增强算法的支持向量机组合模型[J].控制与决策,2011,26(2):316 -319.YANG Hui-zhong,DENG Yu-jun.Compositional model of SVM based on AdaBoosting algorithm[J].Control and Decision,2011,26(2):316 -319.(in Chinese)
[3] 牛艳庆,胡宝清.基于模糊Adaboost 算法的支持向量回归机[J].模糊系统与数学,2006,20(4):140 -142.NIU Yan-qing,HU Bao-qing.Support vector machines based on fuzzy Adaboost algorithm[J].Fuzzy Systems and Mathematics,2006,20(4):140 -142.(in Chinese)
[4] 蒋焰,丁晓青.基于多步校正的改进AdaBoost 算法[J].清华大学学报:自然科学版,2008,48(10):1613 -1616.JIANG Yan,DING Xiao-qing.AdaBoost algorithm using multistep correction[J].Journal of Tsinghua University:Science and Technology,2008,48(10):1613 -1616.(in Chinese)
[5] 付忠良,赵向辉,苗青.AdaBoost 算法的推广——一组集成学习算法[J].四川大学学报:工程科学版,2010,42(6):91 -98.FU Zhong-liang,ZHAO Xiang-hui,MIAO Qing.Ensemble learning algorithms:generalization of AdaBoost[J].Journal of Sichuan University:Engineering Science Edition,2010,42(6):91 -98.(in Chinese)
[6] 方义秋,卢道兵,葛君伟.一种改进AdaBoost 算法的方法[J].微电子学与计算机,2010,27(7):40 -48.FANG Yi-qiu,LU Dao-bing,GE Jun-wei.One improved method for adaboost algorithm[J].Microelectronics & Computer,2010,27(7):40 -48.(in Chinese)
[7] Guo S H,Feng F Z.Study of integrating Adaboost and weight support vector regression model[C]∥International Coference on Artificial Intelligence and Computational Intelligence.Shanghai:Shanghai University of Electric Power,2009:258 -262.
[8] 刁翔,李奇.基于加权支持向量机的在线训练算法及应用[J].系统仿真学报,2007,19(9):3970 -3973.DIAO Xiang,LI Qi.On-line training algorithm and its application based on weighted SVR[J].Journal of System Simulation,2007,19(9):3970 -3973.(in Chinese)
[9] Freund Y,Schapire R E.A decision-theoretic generation of online learning and an application to boosting[J].Journal of Computer and System Science,1997,55(1):119 -139.
[10] 尉询楷,李应红,王硕,等.基于支持向量机的航空发动机滑油监控分析[J].航空动力学报,2004,19(6):392 -397.WEI Xun-kai,LI Ying-hong,WANG Shuo,et al.Aeroengine lubrication monitoring analysis via support vector machines[J].Journal of Aerospace Power,2004,19(6):392 -397.(in Chinese)
