浅析基于纯XML数据库的存储技术
2012-02-05侯雨姗何先波
侯雨姗,何先波
(西华师范大学计算机学院,四川南充637002)
目前XML数据的存储方式有:文本文件方式、关系数据库方式、对象数据库方式和纯XML数据库方式.在纯XML数据库中,其基本存储单元是XML文档,通过XML相关的标准进行数据库的存储.这种数据库维持原有XML文档的数据结构和相关的元数据,而不关心数据的底层存储格式,只能通过XML特有的相关技术对数据进行存储[1].
与其它的存储方式相比,纯XML数据库可以完整地保留XML文档的信息,存储映射时不需要DTD结构.同时,纯XML数据库采用基于XML的查询界面,如XPath或DOM,适合于XML本身的特点[2].目前,在存储方面,大部分研究人员从索引和查询树这些方面进行了综述和优化,对于基层的物理结构和存储方式的对比分析的较少,本文对此进行了汇总和分析,并给出相关实例的应用,希望用户可以根据应用的需求来选取最合适的存储方式与结构.
1 理想的XML存储结构
存储管理的任务主要就是能够有效地存储数据和有效地支持查询,理想的XML存储结构除了能够支持高效查询和更新还要满足:支持无模式的XML数据存储;高效而精准地还原XML文档;提供针对某种模式的存储和优化;有效地分别存储以文档为中心和以数据为中心的XML文档.
2 纯XML数据库存储技术
2.1 纯XML数据库存储方式
XML数据库的物理存储方式有3种:
(1)将XML数据转变为字节流的文本方式.这种方式主要是先将XML文档转换为字节流,然后将其存储在文件系统的相关文本文件中或相关的数据字段中,并在其上创建一些索引,从而能提供某些数据库的功能.显而易见,当存储或者查找一整篇文档或不间断的文档片段时,这种方式的效率还是很高的;可是,当重新组合整篇文档或者查看文档的结构时效率却很低.
(2)按照某种具体地模型(例如物理模型)来存储XML文档的模型方式.当采用的模型不同时,对应的方案也就不同.事实上,此模型方式可大致分为两种:一是采用关系数据库或面向对象型数据库来作为数据的存储模式;二是为XML数据库专门设计的存储方案.第二种方案能够用一种相对较为自然的方式来存储XML数据,从而避免转换,但这方面的研究较少,故技术不如前一种成就.
(3)混合型.结合前两种方式的特点而成,可细分为冗余型和杂交型.冗余型就是指将数据保存两份,一份采用文本方式,一份采用模型方式.可同时采用这两种方式的优点,但数据更新效率低.而杂交型最常见的这种存储方式为Natix[3].
总之,在实际的纯XML数据库中,基于模型的和杂交的存储方式用的较多.
2.2 记录与结点
对于各种纯XML数据库,虽然它们基于的模型可能不一样,但其基本原理还是相似的,即抽象出一个相对应的树状模型[4].构成该树状模型的结点主要有元素结点、文本结点、属性结点等.
在物理存储中,记录是其存储的最小单位.因此在决定存储方式时,应从以下3个方面考虑:
(1)记录的粒度,即记录与节点之间的对应关系.其中记录的粒度主要有结点级、子树级和文案级这3种.
(2)记录的顺序.记录的存储顺序一般有按深度优先、按广度优先和按同类记录聚集这3种.目前,在大多数的纯XML数据库中,基本上采用的是按深度优先的方法来存储记录的,其主要原因是它存储的顺序可与XML文档顺序保持一致性且较易实现.
(3)记录的内部表现形式,即当一个记录对应多个结点时,结点将如何在记录内部表示出来[5].
3 纯XML数据存储的实例
3.1 Natix中的记录格式
在Natix中记录格式中,图1是某个具体的且很小的子树,而图2就是这个子树作为一个记录存储的格式.

图1 XML子树形式Fig.1 XMLSub-tree form

图2 记录的格式Fig.2 The documental format
根据Natix的划分规则可知,Natix是用来记录子树级的且每个记录都一定要有一个根结点,其首部长10 B中有8 B的大小来表示父记录以及用2 B的大小来表示其自身的结点类型[6].记录内的非根结点的首部分别包含了指向父结点的指针、对象的大小以及结点的类型.每个结点都是嵌套存储的,除了首部,还有正文.
3.2 Natix中的物理存储格式
图3为在Natix的基础上将图1的XML文档树所映射为相应的物理树[7].在这种树中一般有3种结点:聚集结点、文字结点和代理结点.图3中的P1、P2、P3为代理结点;值为Lucy的结点则是文字结点.

图3 物理存储结构Fig.3 The Physical Storage Structure
3.3 序列化串表示
3.3.1 NoK模式NoK模式[8]是指把一个树模式查询分解为若干个小的模式片段,每个模式片段中都只包含双亲-孩子关系和左右兄弟关系.每个NoK模式之间是通过后裔(祖先)边相连.当进行查询处理时,先对每个NoK模式采用遍历的方式来处理,然后再将所有的NoK模式的匹配结果进行连接,形成最后的结果.
那么这种利用串表示的新的存储结构就是为了提高NoK模式匹配效率而专门设计的.该存储结构分为值信息存储和结构信息存储,对于值信息可利用ID或关键字来查找.那么所谓的结构信息存储其基本思想就是按照先序遍历次序将结点序列化,为了表示结点的层次关系,在结点标记名之间添入括号.例如,结点a有孩子m和n,则可序列化为(a(m)(n)).经实验表明,这种存储结构的空间开销大约在XML文档的1/20~1/100之间.
3.3.2 串表示实例图4给出了一个简单的XML文档树,该树按照先序遍的次序遍历后的结点串表示如图5所示,由于每个结点都对应一个左括号,故可把所有的左括号都省略掉.该串分页存储,每页的结构如图6所示,其中每页的末尾均会保留一些空间以备用,用以插入新的结点;同时,在页头部都会记录下下一页的指针,用以防止在相邻页之间插入新的页;除此之外,在每一页中会额外存储一个记录(s,l,h),其中s是前一页中最后一个结点的层次,l和h是该页中的最小和最大层次.
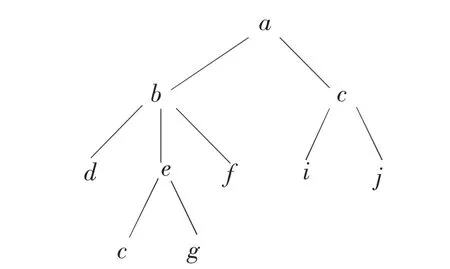
图4 XML文档树Fig.4 XMLDocument Tree

图5 序列化后的串表示Fig.5 The serialized string presentation

图6 页面结构Fig.6 The page structure
4 总结与展望
虽然存储技术在XML数据库研究的早期比较活跃,到后期研究相对比较少.但这并不意味着纯XML数据存储技术已经成熟.由于存储技术与索引技术密切相关,故今后对于XML存储技术需有更深入的认识和研究.
[1] 冯建华,钱乾,廖雨果,等.纯XML数据库研究综述[J].计算机应用研究,2006(6):1-7.
[2] 莫佳.XML数据关系存储技术[J].重庆工学报,2007,21(9):128-137.
[3] 罗道峰,孟小峰,安靖.Orientstore:Native XML存储方法[C]//长沙:第20届全国数据库学术会议论文集,计算机科学,2003(10):105-110.
[4] 夏海静.XML技术浅析[J].太原大学教育学报,2007,25(1):154-155.
[5] 佐丹.基于纯XML数据库Native系统存储技术的研究[D].哈尔滨:哈尔滨工程大学,2010.
[6] 李骥,陈福生.Native一XML数据库综述[J].计算机工程与设计,2004,25(6):932-93.
[7] 徐德智,吴敏,赖同庆.XML模式、查询和存储技术扫描[J].计算机工程与科学,2003(3):22-25.
[8] Zhang N,Kacholia V,Ozsu M T.ASuccinct Physical Storage Scheme for Efficient Evaluation of Path Queries in XML[R].In:Proceedings of the 20th International Conferenceon Data Engineering.Boston,MA,USA.IEEE Computer Society,2004,30March-2April:54-65.
