基于多DSP的高速通用并行处理系统研究与设计
2012-01-24谢晓霞傅其祥
周 滨,谢晓霞,傅其祥,王 伟
(国防科学技术大学 电子科学与工程学院,湖南 长沙 410073)
目前,高速数字信号处理系统广泛应用于雷达、声纳、无线电等运算量大、实时性要求高的信号处理领域。超高处理能力、突出的数据交互能力、良好的通用性和可扩展性已成为现代数字信号处理系统的特点。传统的信号处理系统大多采用专用硬件结构来完成特定的信号处理任务,但是专用硬件结构的开发成本高、周期长,系统的可扩展性和通用性差。而实际系统日益提高的数据传输速率、可通用性、实时处理需求等对处理系统的性能提出了更高要求。尽管目前数字信号处理器的处理能力已达到了较高水平,但就单片DSP(Digital Signal Processor)芯片而言,仍不能完全满足高速数字信号处理系统的需求。因此,以多片高性能DSP芯片作为系统信号处理器,结合FPGA(Field Programmable Gata Array)内丰富的接口和逻辑控制资源,采用并行处理技术,开放性地构建具有高数据吞吐率、实时高速、通用的并行处理系统具有重要的现实意义。
笔者介绍了由4块信号处理板卡构建的高性能并行处理系统的原理和结构组成。其中,各板卡以4片ADI公司高性能浮点DSP芯片TS201S作为信号处理器,通过共享总线和链路口互连的结构进行实时信号处理;结合Xilinx公司高端V6系列FPGA芯片作为时序逻辑和数据传输控制;同时使用PLX公司PCI9656芯片桥接TS201S和主机。通过利用DSP的无缝连接和FPGA的可重构特性,使系统具有灵活多样的拓扑结构、丰富的数据传输逻辑控制接口和高速通用的特性。
1 并行处理系统总体设计
该并行处理系统以高可靠性CPCI工控机为平台,内置1块系统主板和4块相同硬件组成结构的TS201处理板卡,通过串行连接线把各自的后I/O板相连接,从而使得4块TS201处理板卡可以进行相互间的通信。同时,通过CPCI总线实现系统主板、各TS201处理板卡之间的通信。具体系统硬件组成结构如图1所示。

图1 系统硬件结构图Fig.1 Structure diagram of the system hardware
其中,系统主板作为系统的调度中心,通过与CPCI总线连接的接口完成系统的管理、监控、软件加载等操作。各TS201处理板卡作为系统的处理中心,每块板卡上设计了多个具有不同功能的CPCI接口,通过CPCI总线、CPCI接口和Link链路口完成系统内与主机、与其他TS201处理板卡间的通信,实现实时信号处理。
当主板需要同各TS201处理板卡进行通信时,主板通过发送不同的指令经CPCI总线到达指定的TS201处理板卡,相应TS201处理板卡通过CPCI接口接收指令,并执行该指令的相关处理,之后仍沿原路线把处理结果反馈至主机,从而完成数据和指令的上、下传。在这过程中,同一时刻只能有两块板卡可以利用CPCI总线进行通信。
当各TS201处理板卡之间需要进行通信时,存在两种方式。一种是通过CPCI总线。在单块板卡内,通过数据线使FPGA与CPCI接口连接,利用CPCI总线实现与其他3块处理板卡以并行方式传输数据。另一种是通过Link链路口。在单块板卡内,CPCI接口通过 LVDS(Low Voltage Differential Signaling)与FPGA连接,同时在后I/O板通过串行连接线连接其他后I/O板,利用链路口实现与其他3块板卡以串行方式传输数据。
通过CPCI总线、CPCI接口和Link链路口组成不同的连接结构,充分利用每块板卡的丰富结构资源,实现指令和数据的上、下传与相互之间的传输。多种结构的相辅相成,能够适应不同算法的需求,以及可以对任务和数据进行并行处理与分割,以达到资源的最佳利用,从而实现系统的高速、通用性能。
2 单块处理板卡设计
2.1 ADSP-TS201S简介
目前,全球最大的两个DSP芯片生产厂商分别是美国TI公司和ADI公司。就单片DSP性能而言,TI公司的TMS320系列和AD公司的ADSP系列都有高端产品,都可以满足处理速度的要求。但是,在构成多DSP方面,ADSP Tiger-SHARC系列更具有明显的优势。该系列在构成多DSP系统时,每片DSP都提供了片内总线仲裁控制和特有的链路口,可以以松耦合、紧耦合、松紧耦合方式的结构实现DSP间的无缝链接,从而满足一些大运算量、大数据量、高实时性的需求。尽管TI的DSP也可以互连,但是机制比较复杂。因此,选用ADSPTigerSHARC系列可以降低外围设计的复杂度,增强系统的稳定性。
ADSP TS201S芯片的主要性能[1]有:
1)高达600 MHz的运行速度,1.67 ns指令周期,每周期可执行多达4条指令,24个16位定点运算和6个浮点运算;
2)双运算模块,支持的运算类型有:32 bit和40 bit浮点及 8 bit、16 bit、32 bit和 64 bit定点运算;
3)4条128位的数据总线与6个4 Mb的内部RAM相连;32位的地址总线提供4G的统一寻址空间;
4)外部总线DMA传输速率为 1.2 GB/s(双向),4个链路口最高提供1.2 GB/s的传输速率,可同时进行DMA传输;
5)通过共享总线可无缝连接多达8片TigerSHARC DSP,各处理器采用统一寻址的方式访问。
2.2 单块板卡内ADSP-TS201S的拓扑结构
并行处理是采用多个处理单元同时对任务、数据进行处理,从而减少任务的执行时间和数据的处理时间。在该系统中,处理单元为ADSP-TS201S,其相互间的拓扑结构可分为两种:一是流水式松耦合,是指以高速链路口相连组成,结构简单,有很高的数据传输速率,数据传输是串并行方式,适合于流水处理方式,其中各处理单元有各自独立的数据存储器;二是共享总线式紧耦合,是指由通过共享高速外部总线组成,各处理单元共享的外部总线称为簇总线,通过簇总线可以实现簇内各处理单元的资源共享,其数据传输是并行方式,适合于并行分布式处理方式[1]。
目前,雷达信号处理对处理系统提出了必须具备高速的数据传输与运算、巨大的数据吞吐率、实时性高等性能要求。同时,结合松耦合方式的结构简单、容易设计、效率高,但是忽略了空间上并行性的优缺点;紧耦合方式的高速点对点数据传输,但是在每个周期里,只能有两个处理单元可以通过簇总线进行通信,其他处理单元被阻塞的优缺点[2];本文设计了采用两种方式并存的一种并行处理结构,单块处理板卡硬件结构如图2所示。
其中,两片DSP构成一个簇,DSP的外部总线同外部存储器都与簇总线相连,从而使得各DSP的片内存储器和外部存储器作为共享资源都能被簇总线上的DSP访问。同时,4片DSP都采用链路口双向互连的方式,各自利用三组链路资源构成双向网状连接,另外每片DSP还将一组链路资源送至FPGA,用于进一步提高结构的可扩展性。
FPGA是整个系统的控制中心,既负责DSP对外的接口,也负责DSP的内部控制、簇与簇之间的数据交换、DSP与DSP之间的数据交换、以及DSP与PCI9656之间的数据交换。
SDARM分别挂在两个簇总线上,用于存放中间数据,供簇内两片DSP共享使用。Flash也分别挂在两个簇总线上,分别固化了两个簇内各DSP的初始化和处理程序。当系统上电或RESTE时,程序从Flash中写入DSP的内部RAM区。
PCI9656作为DSP和CPCI总线之间的PCI-Loca1Bus桥接芯片,用于实现DSP和主机之间的数据交换。LVDS为单块处理板卡与其他板卡间提供高速数据接口,以高速串行的LVDS实现板级间数据交换。
2.3 FPGA内功能模块设计
为了使单块板卡具备高速、通用功能,FPGA的模块主要划分为4大部分。
2.3.1 DSP通信模块
在单块处理板卡内,由于ADSP-TS201S采用了松紧耦合方式。因此,FPGA可以通过外部总线和Link链路口两种方式与DSP进行通信。
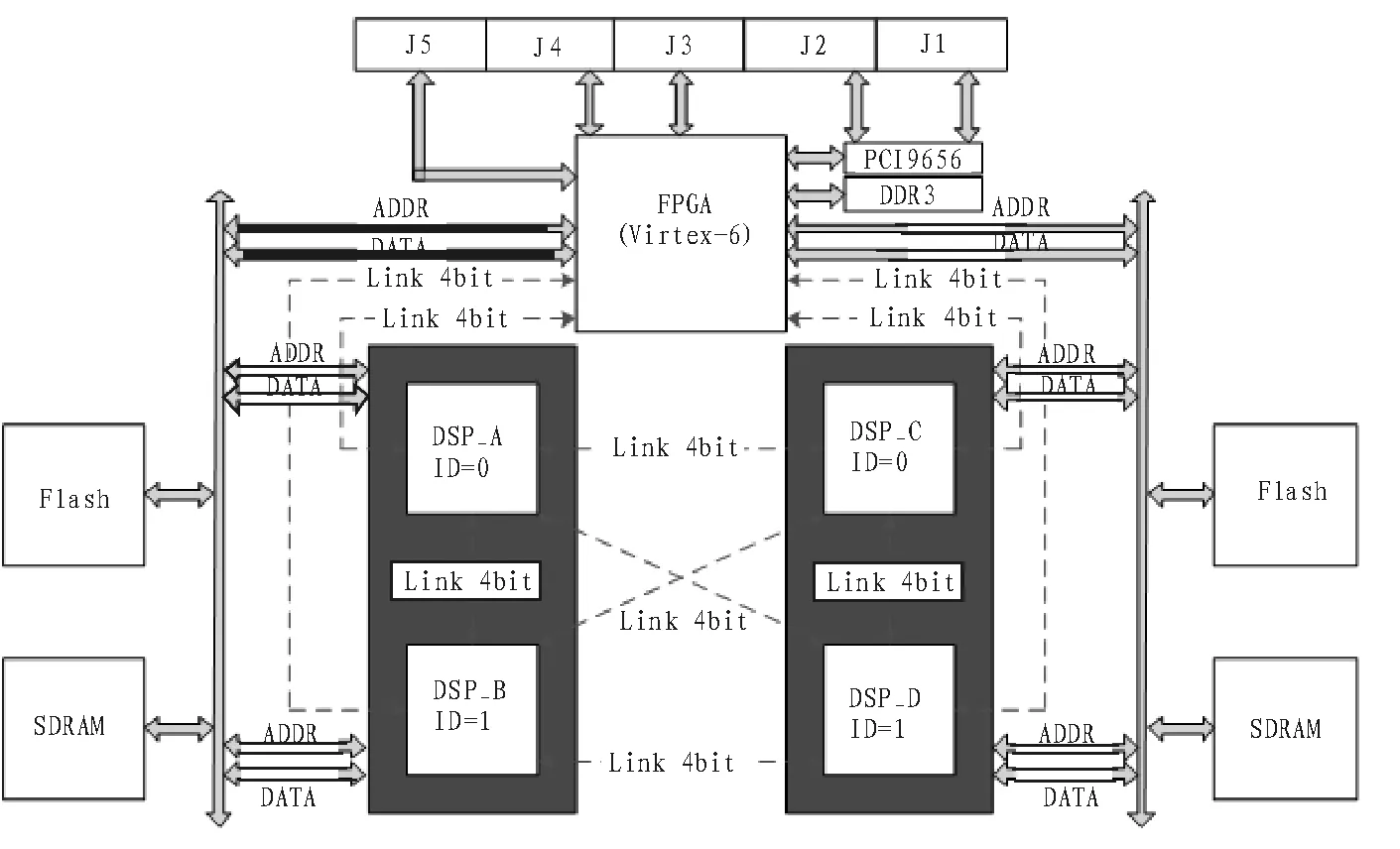
图2 单块处理板卡硬件结构图Fig.2 Structure diagram of the hardware of one processing board
1)控制通过外部总线与DSP的通信
ADSP-TS201S外部总线支持各种不同的协议,包括流水线协议、SDRAM协议和慢速设备协议,并且可以通过编程进行配置。由于FPGA连接在TS201的外部总线上,TS20l可以采用流水线协议,从FPGA的存储模块中读取/写入数据,速度非常快。
同时,ADSP-TS201S对于共享总线的访问提供了完整的总线仲裁机制。在FPGA内设计一个总线控制模块,通过利用共享总线的主机接口参与总线仲裁并获得控制权,完成总线仲裁机制,实现FPGA对共享总线的访问[3]。
2)控制通过Link链路口与DSP的通信
由于ADSP-TS201S的Link链路口采用的是独立的发送和接收通道,此时FPGA也应采用相对应的接收电路和发送电路。FPGA的接收和发送电路都主要由两部分组成:接收模块/发送模块和接收缓冲/发送缓冲。接收模块用来与DSP的Link链路口发送通道进行连接和数据拆包处理,发送模块用来与DSP的Link链路口接收通道进行连接和数据打包处理;接收缓冲用来配合接收模块进行数据传输时作为数据缓存,同样,发送缓冲作为发送模块的数据缓存,同时两者还可以实现与其他接口或者FPGA其他模块接口的数据传输功能[4]。
2.3.2 数据传输逻辑模块
由于ADSP-TS201S的控制总线都连接在FPGA上,FPGA作为单块板卡的控制中心,完成数据在各DSP之间的分配和DSP处理结果的收拢。其中,对于数据分配和结果收拢,有两种并行处理方式,一种是同步处理。FPGA把任务和数据通过分别与4片DSP相连的Link链路口并行发送至各个DSP,之后各DSP相互独立的处理任务和数据,处理完成后把处理结果分别汇总至FPGA,最终被发送至主机。
另一个方法是“乒乓式”处理。这种方法是采用由两个DSP簇内主控DSP交替接收数据。在一个时间段内,只有一个DSP簇在接收数据,该簇中的2片DSP同时处理任务,处理完成后将处理结果传输该簇主控DSP,最终汇总至FPGA并被发送到主机,与此同时,另一个簇在接收数据。当两个簇当前任务都完成后,两个簇互换接收数据与处理数据[5]。
2.3.3 数据缓存区模块
数据缓冲区模块主要包括双口RAM、FIFO。其中,双口RAM主要作为与DSP数据传输时的缓存,而FIFO主要作为与CPCI接口、与PCI9656、与DDR3数据传输时的缓存。由于FPGA连接了各片DSP、CPCI接口、PCI9656和DDR3,因此在设计各缓存区模块时,特别需要注意各端口的数据位数和时钟频率。
2.3.4 CPCI接口模块
CPCI接口模块主要是实现CPCI总线协议。设计一个FIFO控制逻辑,实现与PCI9656的逻辑控制,完成CPCI总线的Local端与PCI端数据传输。当Local端读写CPCI总线时,只需要对该模块中的FIFO进行读写操作。该模块主要完成与PCI9656的逻辑控制、CPCI总线对目标设备的读写、缓存CPCI总线传送的数据、控制FIFO的读写。
3 应用实例
该系统成功应用于分布式雷达组网航迹融合。航迹融合领域对系统提出了高速、实时处理的性能要求,需要在较短时间内对不同雷达探测到的不同目标航迹进行坐标转换、时间校正或对准、航迹关联、对来自同一目标的航迹进行航迹融合[6],并返回融合结果,具体流程如图3所示。由前面的介绍可知,本文设计的多DSP并行处理系统具有高数据传输速率、运算处理速度快、可扩展性和通用性高,能够基本满足航迹融合需求。
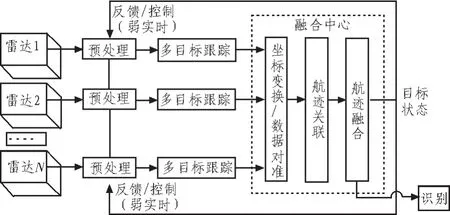
图3 分布式雷达组网结构图Fig.3 Structure diagram of distributed radar netted
在分布式雷达组网模式下,设计由3部分布在不同地域的雷达(A、B、C)组成对多目标的跟踪与状态估计。通过该系统,分别完成雷达A和B、A和C、B和C、A和B和C的组合中对不同雷达分别获取的目标航迹进行融合处理。由于每块处理板卡的结构相同,采用的是同一种航迹融合算法,因此该系统的软件算法部分主要是每块处理板卡中4片ADSPTS201S和Virtex-6内的控制处理程序,大致的系统软件设计流程如图4所示。
当4片DSP并行工作时,总线仲裁机制指定DSP_A(ID=0)和DSP_C(ID=0)为各自DSP簇中的主控处理器,完成系统的初始化、数据程序配置,并参与融合工作。当系统采用“乒乓式”接收到数据时,两个DSP簇开始融合处理,融合完成后将融合结果汇总到DSP_A和DSP_C,最后将融合结果汇总至DSP_A内,并由DSP_A将此融合结果传输到主机。
其中,Virtex-6接收完一帧数据后会给DSP_A或DSP_C输出中断;接着DSP_A或DSP_C发送中断申请,DSP选择模块令DSP_A或DSP_C读取数据并转存至公共存储区;然后DSP_A或DSP_C通过LINK口与其他DSP通信,进行坐标转换、时间校正或对准、航迹关联和航迹融合处理,并将融合结果汇总至DSP_A;最后由DSP_A传输至PCI9656,完成这一批航迹的融合。
3.1 航迹融合结果

图4 系统软件设计流程图Fig.4 Flow chart of the system software design
在C环境下对系统中每块处理板卡进行算法设计,把3部不同雷达上传的大量航迹数据进行航迹融合处理,并在融合中心的主机上,把各航迹以及其融合结果显示在主机界面。主机航迹融合结果效果如图5所示,在图中分布式组网分系统航迹融合结果窗口内显示的是雷达A和B的航迹及其融合结果(航迹 1:雷达A:□— —□;雷达B:■‐‐‐‐■;融合结果:□—□。航迹2:雷达 A:■— —■;雷达B:□‐‐‐‐□;融合结果:■—■)。
3.2 性能对比
在配置性能为P4,2.66G双核处理,1G内存的电脑内建立VC++仿真系统,完成对大批量航迹数据的处理工作。与此同时,同批次航迹数据在并行处理系统内进行处理。这样使通信时延等因素对测试结果影响较小,从而较真实的对比2个系统的性能。
经过测试表明,在数据量较大的情况下(每部雷达稳定跟踪10条以上的航迹),单片DSP处理数据的速度是电脑处理速度的6~7倍。主要是因为:1)单片DSP的运行速度非常高,处理能力很强,内核工作时钟达600MHz,基本上利用了所有内核处理资源;2)电脑内有许多系统进程,使电脑不能将CPU全部处理资源用于数据处理。
在相同的测试条件下,分别对并行处理系统和VC++仿真系统的总处理时间进行计算。其处理时间如表1和表2所示。
通过对比分析,可以看出并行处理系统的处理速度是VC++仿真系统的4~5倍。同时,整个系统的运行性能与仿真系统的对比,不如单片DSP与电脑的对比效果,主要是在并行处理系统中存在模块间数据传输时延。针对这种时延,可以考虑通过优化FPGA设计和DSP内算法设计,达到进一步减少总处理时间的目的。

图5 航迹融合结果效果图Fig.5 Rendering of the results of track fusion

表1 并行处理系统的总处理时间Tab.1 W hole processing tim e of the parallel processing system

表2 VC++仿真系统的总处理时间Tab.2 W hole processing time of VC++sim ulation system
4 结束语
文中设计并实现了一种基于多ADSP-TS201S的并行处理系统方案。在该多DSP并行处理系统的设计中,以高可靠CPCI工控机为平台,内置4块硬件结构相同的并行处理板卡,每块板卡设计采用了流水式松耦合和共享总线式紧耦合并存的一种并行处理结构,分别用于实现不同功能。实际应用表明,该多DSP并行处理系统应用于航迹融合中,基本满足了航迹融合中实时性、高数据传输率与运算速度的性能需求。
[1]刘书明,罗勇江.ADSPTS201XS系列DSP原理与应用设计[M].北京:电子工业出版社,2007.
[2]黄瑞,皮兴宇.基于ADSP_TS201的多DSP并行系统[J].现代电子技术,2006,236(21):37-39.HUANG Rui,PI Xing-yu.Multi-DSP parallel system based on ADSPTS201[J].Modern Electronics Technique,2006,236(21):37-39.
[3]李云志.并行信号处理算法的硬件实现研究 [D].成都:电子科技大学,2009.
[4]李蛟,杨进,邱兆坤.基于ADSP-TS201S的多DSP并行系统设计[J].现代电子技术,2010,330(19):42-46.LI Jiao,YANG Jin,QIU Zhao-kun.Design of Multi-DSP parallel system based on ADSP-TS201[J].Modern Electronics Technique,2010,330(19):42-46.
[5]周志煜.基于多片ADSP-TS201S的并行雷达信号处理器的设计与实现[D].南京:南京理工大学,2006.
[6]罗琳玲.航迹融合系统的研究与实现[D].成都:电子科技大学,2006.
