关于词库及其运行原理的一些假设
2011-12-08荣鑫阁
荣鑫阁
(重庆师范大学 外国语学院,重庆 400047)
关于词库及其运行原理的一些假设
荣鑫阁
(重庆师范大学 外国语学院,重庆 400047)
语言学中的词库指人脑、识别、提取以及构造字词的能力。根据以往的假设,可分为无序排列式和有序排列式。但无论是哪一种,都要涉及到词库的基本储存单位、词库的运行原理等问题。生成语法学界以及计算语言学界对这些问题也都提出过一些解释。笔者赞同词库中的词汇是依照语义原则组织起来的一个网络,赞同词典里储存着词、词缀和词干的假设。无论是词、词干或词缀,只要有意义或功能可言,都是语义网络中的成员,与其它结点有这样或那样的联系。这些联系都是语义复合的重要资源。
词库;无序排列式;有序排列式;储存单位;语义网络
一、引 言
语言学中的词库指人脑储存、识别、提取以及构造字词的能力。考虑到字词是如何排列的,关于词库的设想大体上可分为两类:1)无序排列式,即词的排列是任意的,无章法可循;2)有序排列式,即词库是一个有组织的网络系统。但无论是哪种情况,都涉及到诸如“词库的基本储存单位是什么”、“词库如何运行”等问题。关于这些问题,生成语法学界以及计算语言学界都提出过一些假设。本文将在第2、3节中分别介绍词库理论中的无序观和有序观;在第4节中介绍词库储存单位以及规则运行的假设;最后,第5节作评论。
二、无序排列式
生成语法的词库是典型的无序排列式。因为生成语法把焦点放在词内部的结构特征和词与词之间的句法关系上,从而忽略了词汇的网络关系。虽然生成语法对词库的看法也处在不断发展变化之中,词库的地位也从附属到自主显得越来越重要,但基本式样没有变,仍保留了以往的主张:词库是一个无序排列的字/词项的清单,词库中的信息只跟字/词项的特异性有关。(Chomsky 1965:84)词库应提供以下三类信息:类别特征、次类特征、选择限制。它们都是字/词项的特异信息,不能由句法推导出来,因此必须在词库中予以注明。类别特征是句子结构中最基本的元素:[名词]、[动词]、[形容词]等。例如,cat[名词]、see[动词]、good[形容词]、in[介词]。如果不标注,可能出现以下病句:
*Good see.
次类特征包括[及物]、[不及物]、[单宾语]、[双宾语]等。例如come、give,除了给它们标注[动词]之外,还得给come标注[不及物],给give标注[双宾语]。如果不标注,可能出现以下病句:
*John came London.
*John gave me.
选择限制也很重要,它包括动词给主语或宾语设定语义条件。如elapse,除标有[动词]、[不及物],还要求主语是时间名词。又如,frighten除标有[动词]、[及物],还要求宾语名词标有[有灵]特征。以下句子是合格的:
Three months elapsed.(三个月的时间匆匆而过。)
The cat frightened the mouse.(猫吓了老鼠一跳。)
如果不标注可能出现病句:
*Three girls elapsed.
*The cat frightened sincerity.
生成语法的一个基本准则是:词库与句法之间的冗余度越低越好。为保证信息的简洁性,有些特征无需词库提供标注。例如give的补语信息只需标注[NP,PP]就够了,其中NP和PP的排序问题交给句法去处理。换言之,在动词的次类特征中只需说明宾语的性质和数量,无需提供排序信息;句法部门可以处理VP中的排序问题。“中心语前置原则”表明:在英语这样的语言中,中心语位于补语的前面。该原则来自普遍语法中的“居边原则”,即短语中的中心词出现在X杠的边缘。如果词库也标注动-补在VP中的次序,实为多此一举。宾语从句的形式也无须出现在动词的次类特征中,动词的语义已包涵了这类信息,如“认知类和断言类谓语带判断类或陈述类补语”。这样一来,词库的内容得到简化,而普遍语法规则也得到了充分利用。
有人建议词库也应标注题元特征(参见Radford 2000:372)。这个意见后来被广泛接受。较之上面提到的三类信息,题元特征与句法结构的关系更密切。这使得词库承载的句法信息比以往更多也更为复杂。题元理论认为,句子中的主语和补语等成分要获得合法地位,就必须接受动词指派的题元角色。例如,roll有两个次类特征:及物和作格。及物的例子有:
John rolled the ball down the hill.(约翰把球滚下了山。)
其中the ball充当roll的宾语。作格的例子有:
The ball rolled down the hill.(球滚下了山。)
The ball充当roll的主语。这两种情况在传统视角下属不同的语法范畴,其间的联系被忽略。但在题元理论中,无论roll是及物或作格,the ball从roll那里得到的指派相同,即受事(theme)。换言之,尽管以上两个例句结构不同,但动词roll指派给the ball的题元角色相同,都是受事。题元理论指出,为保证句子的合法性,题元信息必须如实投射到句法层面;为保障“如实投射”,相关的规则或原则不可或缺,例如“题元关系准则”(Theta Criterion)、“投射原则”(Projection Principle)以及其它一些普遍原则。在生成语法中还没有提出一个“词项有序排列”的原则。
最近有学者(如Nelson和Toivonen 2000)暗示词库在某些方面可能是有序排列的,例如那些表示数目的词。但不管怎样,这并不影响生成语法的词库被归入无序排列式。时至今日,生成语法的主流学者(如Chomsky)并未觉得非要设立一个有序排列的词库不可。在生成语法框架下从事词法研究的学者同样感觉不到提出“词库有序排列”假设的必要性。
三、有序排列式
词之间存在各种语义联系是词库有序排列式的基本思想。根据语义场理论的描述,词因为语义上的联系形成一个完整的系统,其中某些词因为具有共同的语义特征而形成一个子系统,即语义场。例如,英语中表示亲属关系的词形成一个亲属场:father、mother、uncle、aunt等。其共同特征是[亲属];表示家畜的词形成家畜场:sheep、cow、horse、pig等,共同特征是[家畜]。场之间不一定泾渭分明,更常见的情形是纵横交错、上下重叠。从语义联系来看,很难想象一个词是孤单单的一个点,与其它点没有任何语义联系。所有的点之间应有许多连线,四通八达,构成一个复杂的网络。这些连线即语义关系:同义、反义、上义、下义等。由George A.Miller(1985)主持研发的WordNet可以看作是有序词库的一个实例。它在计算语言学领域具有很大的国际影响。至少有六十几个不同的语言建立了与之对应的词网。根据Wikipedia介绍,WordNet包含155 287个词条,分为117 659个同义组,涵盖206 941个语义配对。虽然不能说这就是大脑词库的实际情况,但较之传统上按字母或笔画排序的词典,查阅更方便,更快捷,而且拥有一个庞大的纵向联系机制,更接近大脑词库的式样。以sheep一词为例,我们可以在WordNet中看到的信息包括:

表1 :sheep一词的部分信息(WordNet 3.0)
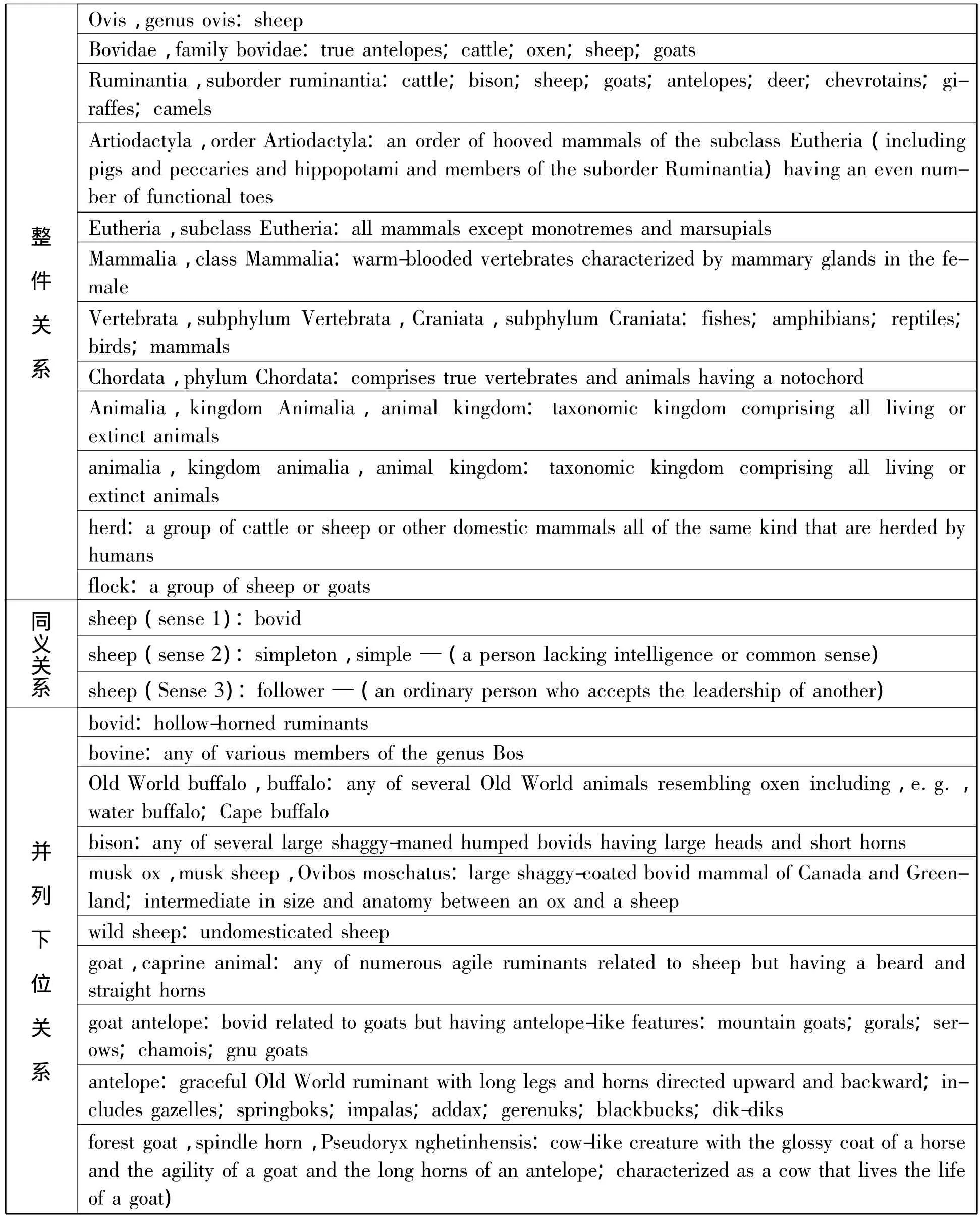
Ovis,genus ovis: goats Ruminantia,suborder ruminantia:cattle;bison;sheep;goats;antelopes;deer;chevrotains;giraffes; sheep Bovidae,family bovidae:true antelopes;cattle;oxen;sheep; camels Artiodactyla,order Artiodactyla:an order of hooved mammals of the subclass Eutheria(including pigs and peccaries and hippopotami and members of the suborder Ruminantia)having an even num-整件关系ber of functional toes Eutheria,subclass Eutheria:all mammals except monotremes and marsupials Mammalia,class Mammalia:warm-blooded vertebrates characterized by mammary glands in the female Vertebrata,subphylum Vertebrata,Craniata,subphylum Craniata:fishes;amphibians;reptiles; birds;mammals Chordata,phylum Chordata:comprises true vertebrates and animals having a notochord Animalia,kingdom Animalia,animal kingdom:taxonomic kingdom comprising all living or extinct animals animalia,kingdom animalia,animal kingdom:taxonomic kingdom comprising all living or extinct animals herd:a group of cattle or sheep or other domestic mammals all of the same kind that are herded by humans flock:a group of sheep or goats同义关系sheep(sense 1):bovid sheep(sense 2):simpleton,simple—(a person lacking intelligence or common sense) sheep(Sense 3):follower—(an ordinary person who accepts the leadership of another) bovid:hollow-horned ruminants bovine:any of various members of the genus Bos Old World buffalo,buffalo:any of several Old World animals resembling oxen including,e.g.,water buffalo;并列下位关系Cape buffalo bison:any of several large shaggy-maned humped bovi ds having large heads and short horns musk ox,musk sheep,Ovibos moschatus:large shaggy-coated bovid mammal of Canada and Greenland;intermediate in size and anatomy between an ox and a sheep wild sheep:undomesticated sheep goat,caprine animal:any of numerous agile ruminants related to sheep but having a beard and straight horns goat antelope:bovid related to goats but having antelope-like features:mountain goats;gorals;serows;chamois;gnu goats antelope:graceful Old World ruminant with long legs and horns directed upward and backward;includes gazelles;springboks;impalas;addax;gerenuks;blackbucks;dik-diks forest goat,spindle horn,Pseudoryx nghetinhensis:cow-like creature with the glossy coat of a horse and the agility of a goat and the long horns of an antelope;characterized as a cow that lives the life of a goat )
WordNet的优点在于为每一个词标注了丰富的纵向信息,而这些信息正是生成语法的词库中所缺乏的。人工智能研究者热衷于把这两种词库结合起来,甚至想把更多的百科知识也收录进来,从而建立一个功能更强大、自动化程度更高的词库。但遇到的问题之复杂是可想而知的。
四、储存单位和运行原理
语言中最小的意义单位是语素,最小的自由形式是词。语素可分为自由语素和黏着语素,词可分为简单词和复杂词。词库里储存的东西是什么呢?不同的学者有不同的意见。Bloomfield说:“要充分描写一个语言就得罗列出每一个不由结构或标记决定其形态的形式;这将包括一个词库,或语素清单,其中每一个语素都标明了属于哪个词类,同时还包括一个清单,上面全是形态上不遵守规则的复杂词。”(1955:269)简言之,词库储存两样东西:语素和无规则可言的复杂词。Chomsky(1965:170-174)也认为词库里不应储存那些可由规则生成的复杂词,他不赞同语素清单说,他主张现词清单,即词库里储存的是现成的词。Halle(1973)的想法似乎略有不同。他是生成语法学派中第一个提出构词规则自主运行的人。构词任务以前是句法部门的事。他认为词库中的基础单位是语素。

图1 Halle(1973)的词库模型
在这个模型中,语素清单中罗列着某一特定语言的全部语素;无论是自由语素、黏着语素还是派生词缀或屈折词缀,都处在同一层面上;除了词缀没有标注类别,其它语素都标注类别。动词标注V:[write]V;名词标注N:[home]N。同时还标注其它语法特征,以[write]V为例,它是一个根词[根词],非拉丁语源[-拉丁源](因而拒绝某些词缀黏附);它还是一个强动词[强动词],即屈折变化不规则,过去时是wrote而非writed。如果是词缀,只标注Pref(前缀)或Suf(后缀),不标注类别:[-ity]Suf.。Halle认为只有那些遵守构词规则并被过滤器认可的复杂词才能进入词典。词典中的词获得了可插入句子的资格:[+可入句]。Halle注意到英语中有许多词不遵守构词规则,它们在语音、语义或词位上表现出某些特异性。

星号表示组合空缺。虽然(1)和(2)都是构词规则的产物,但两者不相同。(2a)在语义上呈现特异性;(2b)在语音上呈现特异性;(2c)在组合上呈现特异性。为了避免例外情况太多,Halle建议,构词规则可自由运行于语素清单,而特异性问题交过滤器处理。换言之,由构词规则生成的词不都是语言中现实的词(actual words);有不少是可能的词(possible words)。这些“可能的词”在接受过滤器的审查时被贴上[-可入句]标签,因而不能出现在句中。具体拿(2c)中的两个词来说,过滤器不认可它们。也就是说,虽然构词规则生成了这两个词,但过滤器认定它们不具有任何现实性,即不可插入句子。故被挡在词典之外。这样一来,如图2所示,词典就只包括那些符合规则、无需过滤器修改的词以及那些被过滤器赋予额外特征的、具有特异性的词。
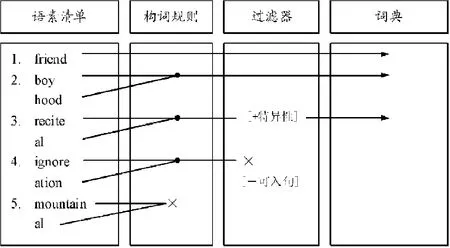
图2 :Halle(1973)构词模型(Scalise 1986:31)
图2表示friend具有独立成词的特征,故直接进入了词典;boyhood符合构词规则并不带有任何特异性,故进入了词典;recital符合构词规则,在过滤器中获得语义上的特异性之后进入了词典;ignoration符合构词规则,但过滤器将它定性为“可能的但不现实的词”,故没有进入词典;mountainal不符合构词规则,属于“既不可能也不现实的”词,故不能进入词典。不难看出,构词规则是在语素的层面上运行的,词典里的词是构词规则和过滤器共同作用的结果。在Halle的模型中,词库实际上被分为两个部分:语素清单和词典。词库的冗余度太高,例如,所有进入词典的简单词(如friend、boy)同时也保留在语素清单中,因为构词规则仍需要它们合成新的复杂词。
Chomsky(1970)和Postal(1969)为了照顾句法,主张词库里最小的储存单位是词而不是语素。Aronoff(1976)指出,即使从词法角度来看,这一主张也是正确的。他不否认语素的存在,但强调很多语素离开了合成词也就失去了意义。例如cranberry和blackberry,其中cran-就很难说有什么意义;black虽有独立的意义,但与blackberry的词义没有必然的联系。“黑莓”不一定是黑色的,有可能是蓝色或红色的。也就是说,即使合成词的部件具有独立的意义,在很多情况下也难以断定部件之间以及部件与整体之间是何种关系。在面对拉丁词干和词缀时,问题会变得更加棘手。例如:

表2 :词缀或词干都缺乏共通义

ad- admit assume adduce per- permit perceive
Aronoff认为,试图给表2任何一列中的词根提供一个共通义,那将是徒劳的。例如fer,看不出在七个例词中有何共通义。词缀的情况也是一样,我们无法从任何一行中找出一个共通义。例如re-,虽然其基本意思是‘倒回来’,但这并不是表2中五个例词的共通义。Aronoff由此得出结论:如果语素缺乏明确的意义,构词规则也就无法在语素层面上运行。他不仅否认语素是屈折构词的基础,也否认语素是派生构词的基础。在他看来,构词规则是将有意义的成分组合成有意义的词的一组规则,只有现成的词才能充当这样的成分。换言之,词库只能以词为基本层面。其原理大致如下:

图3 :Aronoff(1976)的词库模型
图3表示,词汇部门是一个独立自主的模块,包括词典和构词规则;词典中储存的是词;构词规则包括词缀与组合规则;构词规则能够辨认出词的句法、语义、形态以及语音的各种属性,但从不诉诸句法、语义和语音规则。词汇部门的运作无需其它部门介入。词和词缀分开储存意味着两者具有本质的差别:现词携带了类别信息,词缀只携带“关系”信息,例如boy:名词;-able:词缀,只能黏附在动词右边使之变成形容词(可表示为V→A)。由于词典里只有词,构词规则只在词的层面上运行,即选择符合条件的词充当新词的成分。
不少学者对Aronoff的观点提出异议(如Booij 1977、Botha 1980、Lieber 1980、Williams 1981、Selkirk 1982、Scalise 1986)。他们指出Aronoff的模型仅适合英语这类语言,不具普遍性。如果词典里的词必须是自由语素,那么瑞典语中的单数名词ros(玫瑰花)可以进入词典,而flik-(女孩)则不能进入词典,因为其复数形式是flikor,单数形式是flika,词干flik-不是一个自由语素。这类非自由词干在其他语言中亦不少见,如德语:pater-(父亲);拉丁语lup-(狼);罗马尼亚语:munt-(山);意大利语:can-(狗)。可想而知,如果词典中没有这些词干,又如何生成相应的单数名词和复数名词呢?可见词典中只有词的思路过于狭窄。根据批评者的设想,词典中应既有词也有词干,词缀也应放入词典。这样一来,词典的内容变得丰富起来,有自由形式(词),有黏着形式:词干、派生词缀、屈折词缀。也就是说,构词规则同时在两个层面上运行:一个是词,一个是不能独立成词的语素。
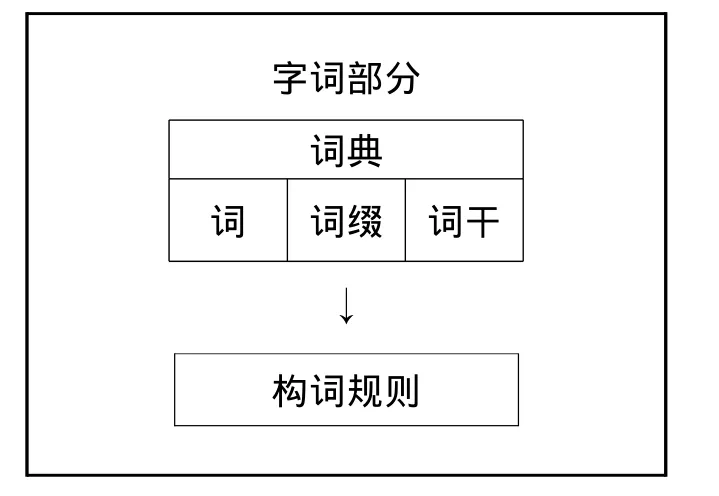
图4 :Scalise(1986)的词库模型
五、评 论
生成语法理论关注词库应该为词项标注哪些句法信息,以便插入句子。对于这一理论来说,词库是否有序排列丝毫不影响短语或合成词的生成,至少目前还没有足够的理由非得为词库中的词项设计出一种次序。然而无序清单的设想并不符合词汇联想测验的结果,也不能解释某些口误现象。笔者赞同词库中的词汇是依照语义原则组织起来的一个系统。WordNet可以看作有序排列的词库。它以语义关系为线索将词汇组织起来,形成一个纵向关系网。不过要建立一个完善的词汇网络,需要考虑的事情相当多,例如联想义或比喻义等。WordNet中这类信息时有时无。若把世界知识也纳入进来,势必要解决度的问题:多少才合适?除此之外,和其它有序排列的词库模型一样,WordNet没有把词义网络与语义复合联系起来。当然,它的目的不在于此,其出发点也不是语义复合。但反过来看,如果语义复合的理论看不到词汇网络对语义复合的作用,那肯定是一个非常严重的、需要纠正的错误。
句子的特点是即生即灭,而字词需要预制并长期保存。一个人可以不相信世界上有神仙鬼怪,但无法阻止大脑中的词库储存“神”、“仙”、“鬼”、“怪”这些词,也无法将这些词从词库中随意删除。正常情况下,词一旦被词库收录便不能删除。句子的储存不具备类似的强制性。尽管句子由词组成,但常见的情形是:李四对张三说了一段话,张三记住了这段话的意思,忘了这段话的形式(即李四的原话)。可谓得其意,忘其形。原因并不在于张三的记性如何差,而在于“得意忘形”是语言交流中的普遍规律。除非有特殊的目的,人们不会刻意记住他人的原话。因此,句库不具有普遍性,头脑中能够储存或储存了许多现成句子(如经典名句)的人毕竟是少数。词库具有普遍性。它涉及每一个人的字词储存能力以及字词判断能力。
Bloomfield的说法显得过于笼统。当后来的学者真想给所有的语素标注词类的时候,问题便接踵而至。正如Aronoff所说的那样,不是每一个语素都有明确的意义或句法特征。特别是在处理拉丁语源或希腊语源的词干时,意义不清或句法特征不明的情况更为常见。这对于生成词法是致命的,因为词库中必须标注句法特征,它们是生成合成词的必要条件。这也是Chomsky坚持词库必须以现词为基本储存单位的一个重要原因。然而词库仅储存现词的观点却使得其它语言中不自由词干(如瑞典语flik-)无立足之地。有趣的是,很多学者对Halle的模型进行了一顿批评之后,却又回到了他的思路:词库里有词缀、词干和词。不同的是减少了冗余度。笔者赞同词典里储存着词、词缀和词干的假设。尤其汉语中不自由词干比比皆是:模、机、版。如果不在词典中,又如何参与构词呢?我们也没有理由否认,无论是词、词干或词缀,只要有意义或功能可言,都是语义网络中的成员,与其它结点有这样或那样的联系。这些联系都是语义复合的重要资源。
[1] Chomsky,N.1965.Aspects of the Theory of Syntax.Cambridge.MIT Press.
[2] Bloomfield,L.1955.Language.George Allen&Unwin.
[3] Halle.M.1973.Prolegomena to a theory of word formation.Linguistic Inquiry.1973(4).
[4] Scalise,S.1986.Generative Morphology.Dordrecht:Foris Publications Holland.
[5] Aronoff,M.1976.Word Formation in Generative Grammar.Cambridge;Mass:MIT Press.
[6] Booij,G.1977.Dutch Morphology:a study of word formation in generative grammar.
[7] Botha,R.1984.Morphological Mechanisms.Oxford;New York;Paris;etc.:Pergamon Press.
[8] Chomsky,N.1970.Remarks on nominalizations.Readings in English Transformational.
[9] Lieber,R.1980.On the Organization of the Lexicon,unpublished doctoral dissertation,MIT.Cambridge(Mass.).
[10] Nelson,D&Toivonen,I.2000.Counting and the grammar:case and numerals in Inari Sami.Leeds working Papers in Linguistics 2000(8):ed.,by D.Nelson&P.
[11] Postal,M.1969.Anaphoric Islands.Papers from the Fifth Regional Meeting,Chicago Linguistic Society.
[12] Radford,A.2000.Transformational Grammar:a first course.Beijing:Foreign Language Teaching and Research Press.
[13] Selkirk,E.1982.The Syntax of Words.Cambridge(MA),MIT Press.
[14] Williams,E.1981a.On the Notions‘Lexically Related’and‘Head of a Word’.Linguistic Inquiry 12.
The Hypotheses about the Lexicon and its Operational Principles
Rong Xinge
(School of Foreign Languages and Literature,Chongqing Normal University.Chongqing 400047,China)
The lexicon refers to the mental ability of word-keeping.According to the hypotheses ever made,words are kept orderly or casually in the lexicon.No matter in which state the lexicon is,the following questions need to be answered:what are the basic units stored in the lexicon?How does the lexicon work?etc.Generative grammar and computer linguistics have offered some assumptions.The author agrees with the idea that the lexicon is a semantically-organized network,which contains words,suffixes and stems as its elements.No matter whether it is a word,suffix or stem,it is a node in the semantic network,a node relating to other nodes in some way.The relations among the nodes are important resources for semantic combination.
the lexicon;the casual-list model;the well-ordered model;lexical units; the semantic network
H03
A
1673-0429(2011)02-0084-09
2011-01-20
荣鑫阁(1959—),男,重庆师范大学外国语学院,副教授。
