一种基于地址分词的自动地理编码算法
2011-09-19马照亭李志刚
马照亭,李志刚,孙 伟,印 洁
(1.中国测绘科学研究院,北京 100830;2.嘉兴市规划 (测绘)管理局,浙江嘉兴 314000)
一种基于地址分词的自动地理编码算法
马照亭1,李志刚2,孙 伟1,印 洁1
(1.中国测绘科学研究院,北京 100830;2.嘉兴市规划 (测绘)管理局,浙江嘉兴 314000)
针对我国多数城市地名/地址表述的不规范性,基于可伸缩地址模型提出地理编码数据库的构建方案,设计一种基于地址分词的自动地理编码算法。首先根据地理编码库编制地址词典,利用地址词典对地名/地址进行地址分词,形成地址要素及其级别;然后再对地址要素及其级别组合形成查询条件到地理编码库中进行匹配;最后分析影响这种地理编码算法精准度的因素,并提出相应的改进措施。实践证明,该算法匹配准确率高,可以服务于我国数字城市、省区和国家级地理信息化建设。
地址模型;地理编码数据库;地址词典;地址分词;地址匹配;地理编码量化
一、引 言
随着地理信息采集手段的不断普及和 GIS软件的不断成熟,越来越多的政府部门、公司、企事业单位基于地理信息构建本单位的业务应用。一些传统上似乎与地理信息系统关联性较弱的部门或单位,如工商、税务、药监、传媒等,也纷纷提出了借助地理信息管理本部门信息的要求。但是这些部门或单位的专题信息采集时并不直接具备空间坐标,只是具有文字描述的地名/地址信息。只有将这些地名 /地址转换成空间坐标,专题部门才能将专题数据与地理信息叠加,才能利用 GIS软件的可视化和空间分析功能辅助本部门应用。这种将地名/地址信息映射成空间坐标的过程就是地理编码[1]。
二、研究现状
发达国家对地理编码的研究较为成功,美国是地理编码技术应用最早、最广泛的国家。20世纪 70年代美国就建立了全国的地理编码标准,并开发了通用的地理编码软件工具,20世纪 90年代后开始成功地应用于与人口数据相关的全国人口地址编码系统 (TIGER系统),在历次全国人口普查统计中发挥了巨大作用[2]。一些著名的国外 GIS软件都具有地理编码模块,如 Map Info的 MapMarker和ArcGIS的 GeoCoding等,实现了基本的地址编码框架和匹配引擎。由于国情不同,我国的地名/地址体系异常复杂,其管理缺少统一的标准和有效的服务体系,导致国外的地理编码技术和软件在我国并不适用[3]。
近年来,我国在地理编码方面也作出了大量的努力,不少单位在地址模型、地理编码标准以及地址匹配技术方面取得了一些成果。如李军针对北京市地址现状,提出了复杂层次的地址模型[4];在地理编码标准方面,国家测绘局组织编制了国家标准《数字城市地理信息公共平台地名/地址分类、描述及编码规则》(GB/T 23705—2009),提出了城市内部地名 /地址分类、规范描述及编码的规则[5];在地址匹配技术和软件方面,文献提及较多的是早期北京长地计算机公司的“寻址神”和北大方正数码公司的“Map Search”软件,近期并无成熟软件问世。由于没有适合国内应用的地址模型,未能建立标准的地理编码数据库系统,现有地理编码技术仍局限于某个具体的应用系统,难以推广应用[6]。有些部门在对本部门信息空间化时,甚至不惜重金将其逐一在地理信息底图上人工定位,既耗时又费力。
三、关键技术及实现
基于地址分词的自动地理编码是基于地址词典将地名/地址字符串切分为一组记录级别的地址要素或标志物通名,然后利用切分到的一个或多个地址要素或关键词组织成查询条件与规范的地理编码库进行匹配。如果匹配成功,返回地理编码库中相应记录的地理坐标;否则,根据需要,返回地名/地址所在道路、社区或其他行政区划的地理坐标。匹配完成后,再对算法的精准度进行效果量化。基于地址分词的自动地理编码的实现流程如图 1所示。

图 1 算法实现流程
1.地址模型
利用结构化的词组对地名/地址进行表述和交流即地址模型,它反映了一个国家或地区对于地名/地址描述的不同方式。国家标准《数字城市地理信息公共平台地名/地址编码规则》(GB/T 23705—2009)中规定了不同粒度范围地名 /地址的描述规则,可以看作是一种在层次上可伸缩的地名 /地址模型:根据地名 /地址描述粒度的不同描述规则自动伸缩,如图 2所示。

图 2 可伸缩的地名 /地址层次模型结构图
由于一个城市内的道路名和小区名是唯一的,因此利用“道路名 (小区名)+门 (楼)牌号”可以精确定位一个地址,利用“行政区划 +标志物名”一般也可以准确定位一个地址,而道路名、小区名、街道名也可以大致定位一个地址范围。即当存在门(楼 )牌号时 ,仅使用“道路名 (小区名 )+门 (楼 )牌号”来表述一个地址;当存在标志物时,使用“行政区划 +标志物名”进行表述;当此表述的标志物多于一个时,对行政区划的粒度进行延伸,直至唯一确定此地址。例如,中国测绘创新基地的地址是“北京市海淀区莲花池西路 28号中国测绘创新基地”,在北京市的应用中可以简化为“莲花池西路 28号”而不会造成任何歧义;再如,将“北京市石景山区华联商厦”使用“北京市华联商厦”进行描述可能定位到多个标志物,这时就需要延伸区级乃至街道级的区划对其进行描述。
2.地理编码库
根据可伸缩地址模型对地名/地址描述的规则,笔者在地理编码库中分别设计了地名、标志物和门 (楼)牌三个数据表分别框架地名 (行政区划、道路、小区)、标志物和门 (楼)牌及其地理坐标,并定义了各数据表的结构。按库表结构依次录入全市所有区县、街道、道路、小区、标志物、门 (楼)牌的名称 (简称、别名)和地理坐标即可构建一个城市的地理编码库。地理编码库检查无误后,分别选取框架地名数据表中的“城市名称、城市别称、区县名称、区县别称、街道办名称、道路名称、小区名称、小区别称”、标志物数据表中的“标志物名称、标志物别称”以及门 (楼)牌数据表中的“门 (楼)牌 ”字段值作为地名/地址词条,连同相应的地址级别记录在地址词典中。当地名别称作为一个词条时,还需记录与本词条相对应的标准名称,以便在地址分词时实现地址要素的规范化。
3.地址分词及标准化
借助地址词典和中文自动分词算法,将一串文字描述形式的地名/地址切分、转化为计算机能够理解的、结构化的多个地址要素或标志物通名 (如酒店、大厦等),这一过程即地址分词,它是实现地址标准化的重要途径。地址分词与中文自动分词的不同在于词典的内容和结构:在内容上,前者需在后者词库内容的基础上扩充《中国地名用词库》中的通用地名词条和一个城市中的专用地名/地址词条;在结构上,地址词典需要为地址要素挂接“标准名称”和“地址级别”两个属性字段。有关中文自动分词算法的技术细节,请参考文献[7]。
表 1是可伸缩地址模型中地址要素采用的地址级别。这样,当地址分词切分出“北京市”、“西城区”、“华联商厦”三个地址要素时,根据地址词条中记录的级别,我们可以准备定位到北京市西城区的“华联商厦”,而不是北京市石景山区的“华联商厦”,也不是沈阳市西城区的“华联商厦”。

表 1 可伸缩地址模型中地址要素采用的地址级别
地址分词后,需要对切分出来的地址要素进行标准化处理,如将城市、区县、小区、标志物的别称标准化为规范名称。这一过程可通过关于地址词典中词条的“标准名称”属性实现。
4.地址匹配
将地址分词切分出的地址要素或通用词按可伸缩地址模型恢复成计算机可以识别的地址,并在地理编码库中比对出地理坐标的过程即地址匹配。由于切分出来的地址要素中具有可伸缩地址模型的地址级别,按如下流程可以在地理编码库中进行快速匹配。
1)切分出来的一组地址要素中含有门 (楼)牌号码时 (如果门 (楼)牌地址要素前无道路名或小区名地址要素,视同门 (楼)牌),利用门 (楼)牌号码可以在门 (楼)牌数据表中精确匹配。
2)当切分出来的一组地址要素中不含门 (楼)牌号码,但包含标志物时,为了避免同名标志物的出现,结合地址模型中的行政区划进行地址匹配。
3)当切分出来的地址要素中不含门 (楼)牌号码和标志物,但包含标志物通用词时,可以按标志物通用词进行模糊查询,将满足条件的一条或多条记录返回给用户,供用户交互甄别。
4)当切分出来的地址要素中不含任何门 (楼)牌号码、标志物和标志物通用词时,用最高地址级别地址要素进行匹配,返回道路、小区或行政区划的地理坐标。
5.匹配结果量化
为了验证算法的有效性,笔者提出了可信度作为地理编码确定性评价的量化指标。当一个地名/地址经本算法能精确转换为地理坐标时可信度为100%,完全不能定位时为可信度为 0。从算法流程上可以看出,本地理编码算法的可信度与地址分词的地址切分准确度、匹配准确度正相关。在地理编码库和地址词典相同的情况下,可信度只取决于匹配准确度。根据可伸缩地址模型,定义匹配准确度的计算方法如下

式中,Mi为地址要素在地理编码库中的匹配准确度,匹配成功时为 1,匹配失败时为 0;Wi为各地址要素在可伸缩地址模型中所占的权重,取值介于0.0和 1.0之间。可伸缩地址模型中各地址要素在本算法中量化计算时的权重如表 2所示。

表 2 可伸缩地址模型中地址要素采用的权重值
在本算法中,由于地理编码库中的所有地址要素均包含在地址词典中,匹配准确度完全取决于地址分词切分的地址要素,取决于地址词典 (地理编码库)的丰富性和全面程度。当地址词典中缺少“石景山医院”时,匹配地址“北京市石景山医院”时只能分解出“北京市”、“石景山”、“医院”三个词条,只能通过模糊搜索,得到北京市石景山区内包含“医院”的所有标志物的空间坐标,供用户确认。如“北京市石景山区中医医院”、“北京市石景山医院”、“北京市石景山同心医院”、“北京市石景山区五里坨医院”等都在结果之列。如果在地址词典中扩充“石景山医院”一词,可以直接到“北京市石景山医院”的空间坐标。可见,提高本算法可信度的关键是按照可伸缩地址模型的规范不断更新与完善地理编码库。
四、试验效果
基于上述设计思想和算法,通过改造开源的中文分词代码包,笔者开发了利用地理编码库编制地址词典的工具,搭建了基于地址分词的地名/地址批量匹配工具。图 3是地名 /地址批量匹配工具的操作界面,用户选择一个 Access或 Excel格式的表格,就可以按表格中指定的地名/地址字段进行批量地址匹配。对于有多个可能结果的地名/地址,由用户根据返回的结果在地图窗口中予以确认。

图 3 自动地理编码批量处理工具界面
依托国家测绘局开展的数字城市地理信息公共平台建设项目,分别针对多个城市不同部门的专题数据进行地理编码试验,结果表明,匹配成功率均在 90%以上,如图 4所示。
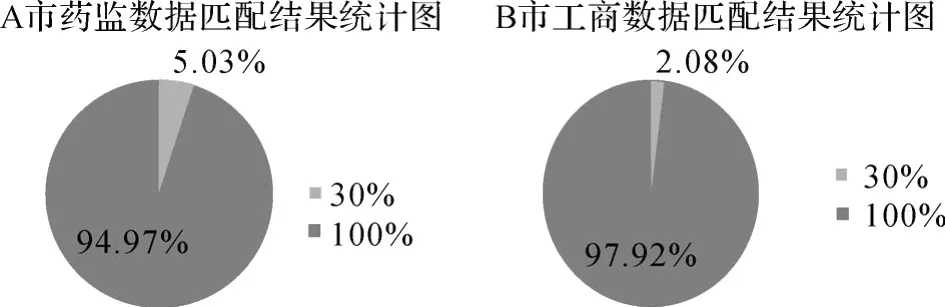
图 4 不同城市不同部门地理编码结果统计图
五、结束语
本文提出了一种基于地址分词的自动地理编码算法,在深刻剖析实现所需关键技术的基础上,在数字城市地理信息公共平台软件 NewMap GIS中实现了适用于我国城市地名/地址的地理编码功能。试验表明,本算法正确、有效,不但适应于城市级地名/地址的地理编码,而且适用于省级和国家级地名信息向空间坐标的转换。但是,由于地理编码库中未考虑诸如地址中存在错别字、同音字等地址笔误的情况,算法在此方面的兼容性还有待加强。
[1]江洲,李琦.地理编码 (Geocoding)的应用研究 [J].地理与地理信息科学,2003,19(3):22-25.
[2]U.S.Census Bureau.TIGERµ,TIGER/Lineµ and TIGERµ-Related Products[EB/OL].[2010-01-20].http:∥www.census.gov/geo/www/tiger/,2008-12/2009-10-1.
[3]王凌云、李琦、江洲.国内地理编码数据库系统开发与研究[J].计算机工程与应用,2004(21):167-168,212.
[4]李军,李琦,毛东军,等.北京市地理编码数据库的研究[J].计算机工程与应用,2004(2):1-3,6.
[5]国家质量监督检验检疫总局.GB/T 23705—2009数字城市地理信息公共平台地名/地址编码规则 [S].北京:中国标准出版社,2009.
[6]江洲,李小林,刘碧松.地理信息系统地址编码技术标准化研究[J].标准化研究,2007(5):22-25.
[7]刘开瑛.中文文本自动分词和标注 [M].北京:商务印书馆,2000.
An Automatic Geocoding Algorithm Based on Address Segmentation
MA Zhaoting,L I Zhigang,SUN Wei,YIN Jie
0494-0911(2011)02-0059-04
P208
B
2010-05-17
马照亭 (1976—),男,河南睢县人,助理研究员,主要研究方向为数字城市、GIS应用和三维 GIS。
