基于VMPSO-BP神经网络的话务量预测
2011-09-13晏新祥贾振红覃锡忠
晏新祥, 贾振红, 覃锡忠, 常 春, 王 浩
(①新疆大学 信息科学与工程学院,新疆 乌鲁木齐 830046; ②中国移动新疆分公司, 新疆 乌鲁木齐 830063)
0 引言
话务量预测,是指先分析和总结历史话务量数据的特点及其影响它的一些因素,然后找到一种恰当的方法对未来的话务量进行预测。其预测的准确性与一些企业和公司的日后发展有很大关系,所以很多移动运营商对话务量的预测非常地在意和关注[1]。目前一些移动公司采用函数拟合预测方法,譬如惯性预测[2],此模型非常简单,不能满足话务量的日益发展的变化需求。时问序列分析预测方法——ARIMA模型[3-4]也经常用来预测话务量,但它所要求的前提是话务量序列必须是平稳的。紧接着用支持向量机理论[5-6]来预测话务量,但是确定它的参数十分困难,而且参数的准确与否直接影响着话务量的预测。针对以上那些模型的缺陷,在粒子群优化算法(PSO, Particle Swarm Optimization)[7]的基础上,提出了把速度变异粒子群算法与 BP网络相结合,形成了速度变异的粒子群—BP(VMPSO-BP)网络算法,用它训练网络,优化了神经网络的参数,得到了基于VMPSO-BP算法的网络模型,最后对移动话务量进行了预测。试验的数据结果表明所研究的方法具有更高的预测精度、更快的收敛速度的优点。
1 速度变异粒子群算法
在PSO算法中,粒子群会朝向全局最小或局部最小的方向收敛,第i个粒子以前到过的最好位置为Pb,粒子群体以前到过的最好位置为 Gb。这时,Pb、Gb和每一个粒子当前位置都会趋向于同一点,这时的每一个粒子的运动速度就几乎趋向于零。此时,最终求解结果就是粒子群收敛到的那个点。速度变异的粒子群优化算法(VMPSO)的核心是:该方法不是对每个粒子在每一个维度上的速度进行变异,而是把具有L个粒子的粒子群的每一维度w上的速度的绝对值∣v1w∣,∣v2w∣…∣vLw∣最小的速度∣vyw∣进行变异。令∣vyw∣=min{∣v1w∣,∣v2w∣…∣vLw∣},y∈{1,2,…L},w∈{1,2,…W}。则有:
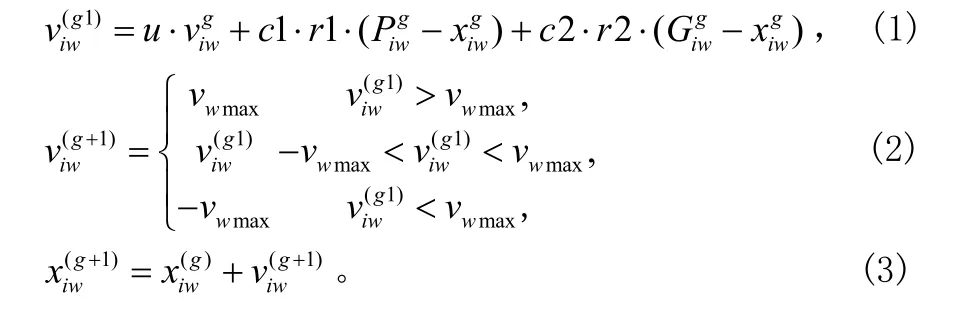
这里提出了式(1)中惯性权重u的线性变化的公式:
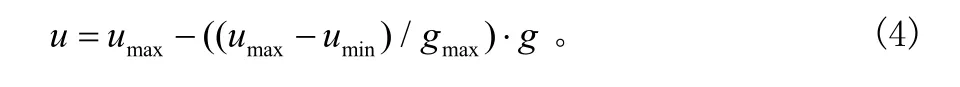
上面的c1和c2是加速系数,是用来逼近于全局最好粒子和个体最好粒子方向,r1、r2是[0,1]之间的随机数,u是惯性因子,是用来控制速度的权重。umax、umin分别为惯性权重u的最大值和最小值,g为当前迭代次数,gmax为最大迭代次数。每一维速度vw都在[-vwmax, vwmax]之中,如果vwmax过大,粒子就会逃离出最好的解;如果 vwmax过小,粒子就会处在局部最优的困境。VMPSO不需要选择变异的时间和机会,它使每一维度的vyw,w∈{1,2,…,W}以一定的概率进行变异,并且使vyw随机地在[-vmax,vmax]上取值,通过公式(3)将集中的粒子群打散。算法如下所示:
①设定一些常数和初始化粒子群;
②计算粒子的适应度,Pb和Gb;
③按迭代公式(1)、公式(2)和公式(4)来更新viw。如果viw>vmax,就使 viw=vmax;如果 viw<-vmax,就使 viw=-vmax;找到 vyw,使∣vyw∣=min{∣v1w∣,∣v2w∣…∣vLw∣}。如果 r3<r4,就使 vyw在[-vmax,vmax]上随机取值,按迭代公式(3)来更新xiw。如果 xiw>xmax,就使 xiw= xmax;如果 xiw<-xmax,就使xiw=-xmax;
④输出Gb及相对应的目标函数值。
其中r3是(0,1)上的随机数,r4代表变异率,其中变异率的取值要恰当,取值过大或取值过小都会使算法不能得到最好的结果。
2 VMPSO-BP神经网络混合优化算法
2.1 VMPSO-BP神经网络
BP网络实际输出值or(r=1,2,…,n);n是神经网络输入输出的样本对数。用L个粒子组成一个粒子群,其中每个粒子都是W维向量。该向量表示神经网络的所有权值,并且随机产生权值的初始值,取值范围为[0,1]。每个粒子的适应度函数值如式(5)所示:

其中or是神经网络的输出,ts是目标输出,n1是输出节点数,n2是训练集样本数。
2.2 VMPSO-BP神经网络算法
①按式(1)、式(3)初始化粒子的速度viw及位置xiw,确定粒子个数L、最大允许迭代步数gmax、系数c1和c2、初始化Piw和Giw;
②用f来计算每个粒子的适应度值,找出其中最好的即为全局极值Giw;
③计算每一个粒子的适应度值 f,若比该粒子当前值要好,则把Piw作为该粒子的位置,接着对个体极值进行更新。如果在所有粒子的个体极值中最好的值比当前全局极值要好,则把Giw作为该粒子的位置,记录该粒子的序号,对全局极值进行更新;
④根据式(4)更新惯性权重;
⑤根据式(1)、式(2)、式(3)、式(4)更新速度和位置;
⑥当迭代到最大次数或最小误差时停止,该全局极值对应权值是最好解。否则转向步骤②继续进行。
网络权值训练完毕,然后将该最好的权值作为 BP网络的权值,进行话务量预测。
3 基于VMPSO-BP神经网络的话务量预测及实验结果
3.1 预测模型的网络结构
神经网络采用三层BP网络,它的构成:输入量是7个,是一个完整7天的话务量的数据,输出量是1个,对应于第八天的话务量的预测值。隐含层的数目根据经验公式以及反复的实验确定为14。
3.2 学习样本的选择
训练数据选择乌鲁木齐市2005年8月1日至2006年7月30日整整52个星期(7×52=364天)的移动话务量的数据。训练样本取为42个星期(7×42=294天)的话务量数据,测试样本取为10个星期(7×10=70天)的话务量数据。并对2006年7月31日至2006年8月27日整整7×4=28天的话务量进行了预测。
3.3 输入变量的处理
对所有输入数据进行归一化处理。利用如下公式:

A(i,j)为原输入数据,An(i,j)为归一化后的数据,归一化后的数据都是0-1之间,这样有利于BP网络的训练和预测。
3.4 话务量的预测结果与分析
以乌鲁木齐市2005年8月1日至2006年7月30日的移动话务量数据为依据,进行了网络训练和话务量预测。在网络训练过程中,采用VMPSO和BP相结合的方法,VMPSO-BP的初始参数分别为:惯性因子umax=0.9,umin=0.2,vmax=0.6,最小误差emin=0.005,c1=2,c2=2,r1、r2的范围是[0,1],L=40,隐含层神经元数目为14,最大迭代次数1 000。为了评估VMPSO-BP神经网络模型的预测效果,采用BP神经网络、PSO-BP网络和VMPSO-BP网络分别进行预测,其模型训练结果见表1。
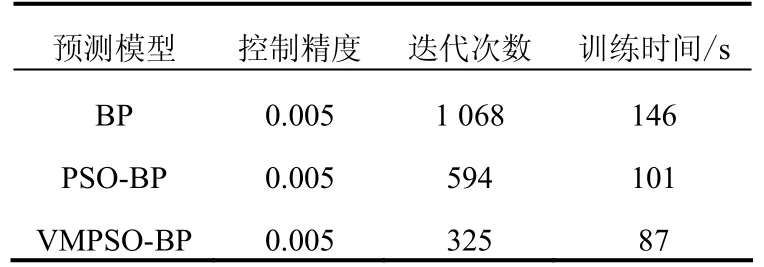
表1 BP、PSO-BP和VMPSO-BP模型训练性能对比表
通过VMPSO来优化BP网络的权值和阈值,通过网络的训练和检测,然后对未来28天的移动话务量进行预测,并将预测出来的结果与BP神经网络,PSO-BP神经网络的预测结果进行对比。其实验最后的话务量预测曲线如图1所示。
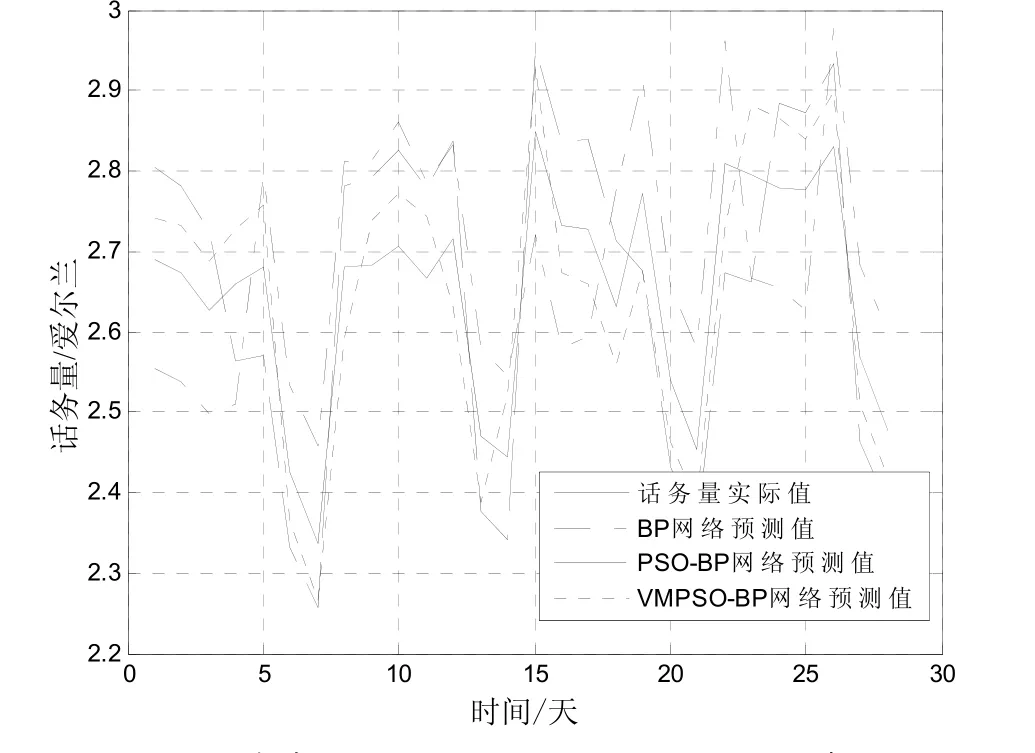
图1 未来四周(28天)实际和预测的话务量(纵轴话务量的数量级为×105)
通过实验图,可以比较用 BP网络,PSO-BP网络和VMPSO-BP网络来进行预测时产生的误差,其具体结果如下表2所示。

表2 未来28天移动话务量的预测结果的误差比较
4 结语
提出的一种速度变异粒子群—BP神经网络的移动话务量预测方法,经实验表明:与BP方法和PSO-BP网络方法相比,首先是它克服了 BP网络容易陷入局部极小值点和粒子群优化方法的缺陷,其次更重要的是它具有更高的预测精度和更快的收敛性。
[1] 黄海辉.一种周期时间序列的预测算法[J].计算机工程与应用,2006,42(05):71-73.
[2] 刘童,孙吉贵,张永刚.用周期模型和近邻算法预测话务量时间序列[J].吉林大学学报:信息科学版,2007,25(03):239-245.
[3] 吴家兵,叶临湘,尤尔科.ARIMA模型在传染病发病率预测中的应用[J].数理医药学杂志,2007,20(1):90-92.
[4] YU GUO QIANG,ZHANG CHANG SHUI.Switching ARIMA Model based Forecasting for Traffic Flow[J].Acoustics,Speech and Signal Processing,2004(02):429.
[5] XIAO JIAN HUA,LIN JIAN,LIU JIN.Short-term Forecasting Model of Regional Economy based on SVR[J].Journal of System Simulation, 2005,17(12):2849-2851.
[6] 牛晓东,谷志红,王会青,等.基于灰色支持向量机的季节型负荷预测方法[J].华东电力,2007,35(06):1-5.
[7] EBERHART R,KENNEDY J.A New Optimizer Using Particle Swarm Theory[C].Nagoya:Machine and Human Science,1995:39-43.
