基于PI数据库系统实现线路负荷转供模拟
2011-09-12陈士俊
陈士俊
(湖州电力局,浙江 湖州 313000)
1 开发背景
1.1 湖州电网配电网管理现状
对配电网运行人员来说,迅速了解辖区内10kV线路的实时负荷情况对合理安排工作、处理紧急故障非常重要;对配电网调度人员来说,安排热倒负荷转供前,要准确了解未来一段时间转供线路负荷的变化情况,这对合理安排热倒负荷方案、有效利用电网资源,避免负荷分配不均有重要的参考作用。
近年来,随着湖州电网不断发展,现有的SCADA/EMS系统已逐渐无法满足工作的需要,而SCADA/EMS系统由于其自身的局限性,仅能提供简单的负荷查询,没有联络拓扑数据,无法实现更高级的数据分析。
1.2 利用PI数据库实现负荷转供模拟
PI(Plant Information)实时数据库系统是一个开放性的平台,除了能提供电网电气量参数实时数据外,还可以按使用者需要的方法加工处理需要的数据,在很大程度上能满足使用者特有的需求,尤其适合进行图形和拓扑操作,在系统中建立网架及负荷数据,从而实现配电网负荷数据的高级分析应用。
由于负荷转供所需的配电线路负荷数据均已进入PI数据库系统,利用PI数据库系统提供的ProcessBook工具及VB编程,可实现配电线路的负荷速查、联络显示和转供模拟功能。
2 设计思路
2.1 主要设计思想
针对现有SCADA/EMS系统查询不便、缺少联络拓扑信息、无法实现高级数据分析的问题,利用PI数据库系统中已接入的配电网线路负荷,对线路在选定时间段内的最大负荷、最小负荷、负荷超限时间占总时间的比例进行计算;显示线路的联络情况;对负荷的转供情况进行模拟,从而有效帮助运行、调度部门及时准确地获取线路负荷情况,对配电线路转供进行预先模拟,实现配电网的精细化管理,提升工作效率。
2.2 主要设计步骤
(1)从线路双重命名到PI数据库系统“Tag名”的映射:目前PI数据库系统的测点均用Tag名作为唯一标识,如“FZ.SJ.SCADA_18415714.YC”,相对于日常使用的线路双重命名来说不便于记忆和应用,无形中提高了PI应用的门槛。因此考虑利用PI数据库系统提供的VB工具,将Tag名与工作中常用的线路双重命名进行自动关联,实现线路双重命名与Tag名的无缝转换。应用人员可以使用熟悉的线路双重命名进行操作,而不必记忆繁琐的Tag名,减少工作量、降低了使用难度。
(2)线路联络拓扑关系导入:目前PI数据库系统中仅有各配电线路负荷测点的实时及历史数据,而对于配电网来说,还必须在系统中导入线路间的联络拓扑关系并自动显示,以减少人工记忆难度,同时避免差错。
(3)线路负荷分析及负荷转供模拟:对线路负荷的最大值、最小值、平均值及超限时间进行计算;通过PI数据库中数据集的应用对转供的线路负荷曲线进行叠加,模拟转供后的情况,供运行单位监测及调度决策使用。
程序流程见图1。
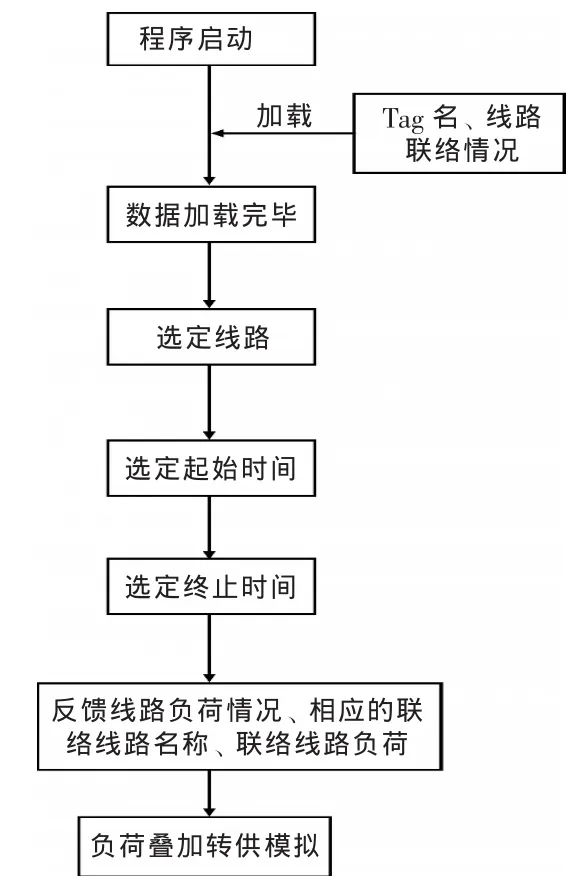
图1 程序流程图
3 主要功能和界面
通过设计应用实现了线路负荷速查分析、联络情况显示、负荷模拟转供等功能。线路负荷转供模拟主界面见图2。
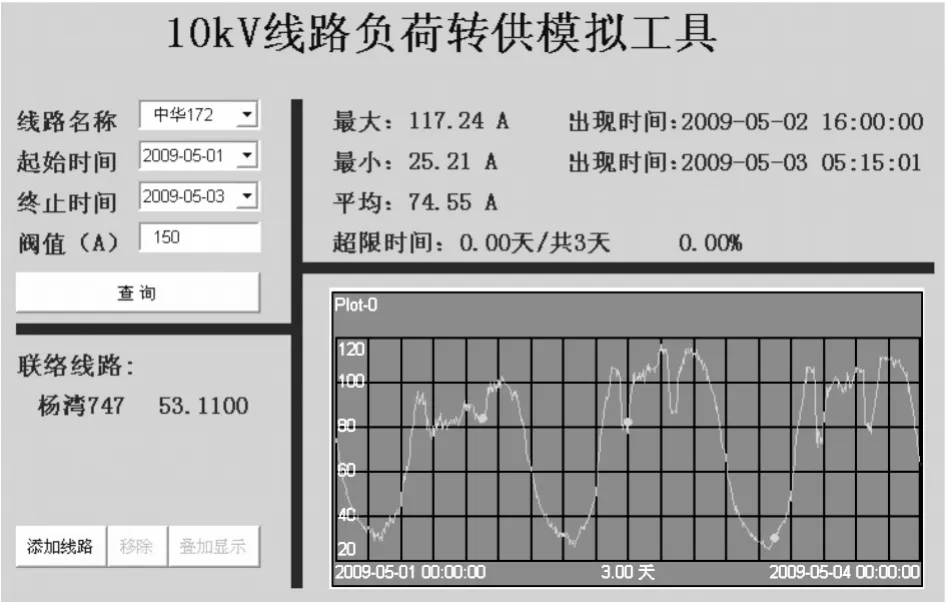
图210kV线路负荷转供模拟主界面
3.1 线路负荷速查分析及联络情况显示
现有SCADA/EMS系统提供的配电线路负荷查询功能简单,操作繁琐,不能跨月、跨年选择时间段,影响了使用人员的工作效率。本系统的负荷速查功能提供了线路下拉列表,可通过鼠标选择和首字符定位两种方式快速选择配电线路,通过点击日历控件工具确定查询的时间段(起始时间、终止时间)。在结果中反馈线路的联络情况、负荷曲线及线路的负荷分析情况,包括最大负荷、最小负荷、超限时间占总时间段的比例等。其中线路超限时间主要针对原SCADA/EMS系统缺乏对线路最大负荷统计功能的不足而设计。通过对超限时间的分析,可有效过滤因数据毛刺、短时转供造成的线路负荷偏高,从而导致无法获取准确的线路负荷信息。线路快速定位、联络及负荷曲线反馈等显示页面示例见图3-5。
3.2 负荷转供模拟
目前,判断转供后的最高负荷时,一般要先在SCADA/EMS系统中找到需转供的线路及其联络线路的最大负荷,将二者相加后才能得到结果。由于实际运行中线路的最大负荷值一般不会同时出现,上述方法就显得不够科学,计算结果会大于实际转供的线路负荷,造成线路设备投资不必要的增加。如果对负荷曲线作精确叠加,则需要进行大量的计算工作。然而由于SCADA/EMS系统未提供此项功能,只能采取人工计算的方法,使准确性和精度都受到很大影响,还将消耗巨大的人力成本。

图3 线路快速定位
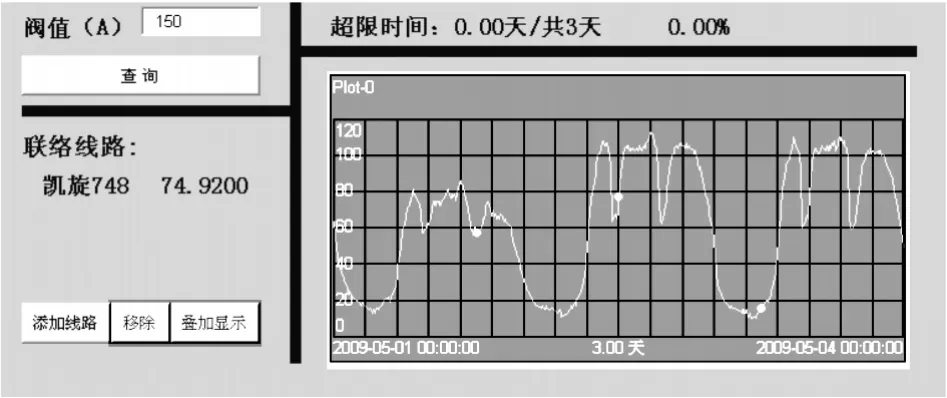
图4 联络及负荷曲线反馈界面
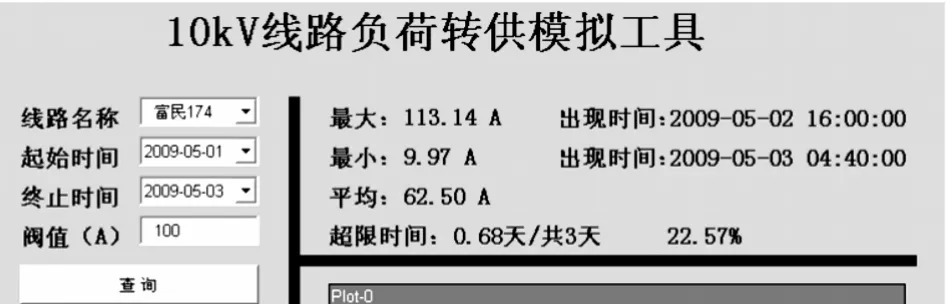
图5 线路负荷分析结果反馈界面
应用本设计的负荷转供模拟功能后,可以调用PI数据库系统的数据集功能,利用配电线路历史负荷数据,对两条联络线路的负荷曲线进行叠加计算,从而精确模拟转供后的线路负荷情况,为运行监控、调度决策提供重要的参考依据。线路负荷叠加、模拟转供后的负荷显示界面示例见图6、图7。
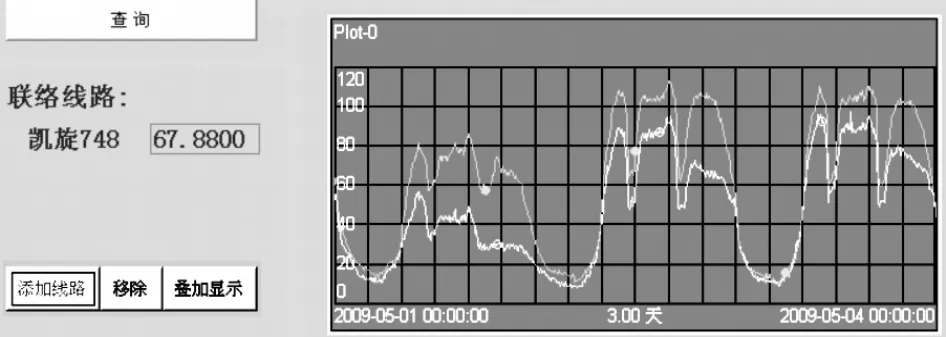
图6 联络线路负荷的同屏显示
4 实现方法
4.1 系统开发环境
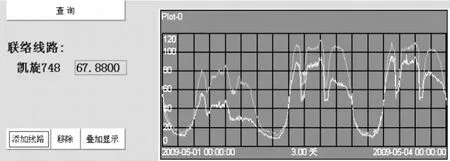
图7 线路负荷叠加、模拟转供后的负荷情况
(1)硬件开发环境。局域网内可连接至PI服务器的个人计算机推荐配置为:中央处理器P4 2.6GHz及以上,内存512M及以上,硬盘40G及以上,显示器分辨率不低于1024×768。
(2)软件开发环境:使用WindowsXP操作系统,安装PI ProcessBook和PI DataLink并连接PI服务器,安装2003版本的Excel软件(需安装完整版)并安装日历控件。
4.2 数据说明
本案例中的配电线路负荷数据从PI数据库中取得,但由于PI数据库使用Tag名作为数据点的标识,与常用的线路双重命名不同,因而需要建立线路双重命名与PI Tag名的映射关系;同时线路间的联络情况也需要从PI数据库外导入,故使用配置文件config.xls对上述二者进行描述。
程序在启动阶段加载配置文件config.xls中如表1所示的Tag关系表和联络关系表,配置文件可以手动调整,以方便线路联络变化后进行及时更新,也为程序在不同单位间移植提供方便。图8为配置文件数据结构,其中线路名称与Tag名称一一对应,包括所有联络线路的线路名和Tag名也要一一对应。
表1 配置文件数据结构
5 结语
基于PI数据库实现的线路负荷转供模拟系统在湖州电力局应用已有两年多的时间,为热倒负荷转供安排提供了重要的参考数据,有助于调度管理、运行管理、故障抢修管理水平的进一步提高。
随着智能电网技术的不断发展,供电企业精益化管理要求的不断提高,对配电网的负荷分析管理也将向着更深化、细化、实时化的方向发展,本文介绍的PI数据库的深化应用无疑能对配电网管理起到一定的参考作用。
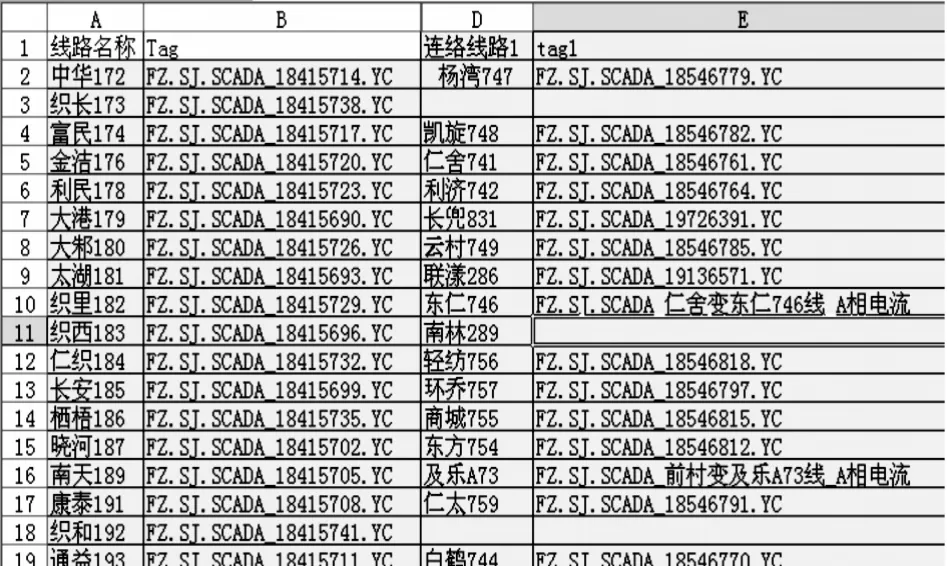
图8 配置文件数据结构
[1]夏远福.PI实时数据库在输变电设施可靠性统计分析中的应用[J].浙江电力,2007,26(S1)∶26-29.
[2]王华慧.PI实时数据库在电网负荷统计中的应用[J].浙江电力,2007(S1)∶23-25.
