一种面向网格资源预留的索引链表研究
2011-09-08吴黎兵于天水何炎祥
吴黎兵,于天水,何炎祥,李 飞
(1.武汉大学计算机学院,湖北武汉 430072;2.武汉大学软件工程国家重点实验室,湖北武汉 430072)
在高性能计算网格环境中,资源分布在各个不同地域和管理域中,由不同的组织拥有和操作,并且在策略和安全机制上各有不同。站点的自治性,资源的动态性和异构性需要一种有效机制来联合分配位于多个站点上的资源。资源预留可以保证任务在开始执行时获得资源,而在网格这种资源动态性很强的环境中,任务能如期执行可大大提高整个网格系统的资源利用率和系统性能。由于资源预留还可以实现网格服务的QoS保证,因而资源预留是网格资源管理中一种普遍采用的机制,也成为网格资源管理的研究热点。
目前网格资源预留机制从理论到实际应用的关键在于提高自身的处理性能,以便用尽可能小的代价,为用户提供更高QoS保证的网格服务。资源预留要求接纳控制的数据结构必须能够快速高效地查询资源的实验情况。实验表明,资源预留中有60%以上的时间用于对数据结构的处理,而这仅仅是提供最简单的预留服务,如果请求全部潜在的高级预留服务(如在扫描探测资源时间间隔时),则与数据结构相关的处理达到总处理时间的90%[1]。可见为了最小化处理时间,对数据结构的改进是最能影响整个处理时间的,对数据结构的优化可以在较大程度上提高资源提前预留服务的处理速度。
1 现有数据结构
现有的数据结构分为基于离散时间(时隙)和基于连续时间两类。时隙是一个固定的时间间隔,它是资源预留的时间单位,其代表是基于时隙的数组,文献[2]中提出了一种基于时隙数组的数据结构,并将这种基于时隙的数组与其他基于时隙的数据结构(如线段树[3]和二叉搜索树[4])相比,结果显示无论是消耗的时间还是消耗的存储空间,基于时隙的数组性能都有优越性。因此,笔者选择时隙数组作为比较对象之一,且仅选择这一种基于时隙的数据结构。文献[5]指出了基于时隙的数据结构有两个比较明显的缺陷,一是时隙的定义是一个挑战,太长的时隙会降低精度,太短的时隙会浪费时间和存储空间;二是将时间分割成时隙会导致可利用带宽的减少。
文献[6]提出了一种基于单链表的数据结构,这种数据结构是基于连续时间的,并且可以动态地回收存储,其实验结果表明,这种基于单链表的数据结构对存储空间的消耗要远少于时隙数组,并且在请求量不是很大时,在时间消耗上也要大大优于时隙数组。因此,笔者选择这种基于单链表的数据结构作为比较对象之一,且针对单链表中请求接纳时间和请求搜索时间性能不理想的问题,提出了一种改进的索引链表。
文献[7]提出一种基于带宽预留的资源树,它是树形数据结构的典型代表。但是文献[6]的仿真结果表明,该数据结构无论在消耗的时间还是消耗的存储空间上与时隙数组或单链表相比,都存在着较大的差距。
2 索引链表
2.1 预留请求定义
一个接纳控制程序必须维护一个合适的数据结构来存储管理区域中的预留资源信息。当请求到达时,需要检查参数,并决定是否有足够的资源用来预留和分配。每一个预留请求都由一系列参数来描述,笔者采用文献[6]中预留请求的定义方法:

其中,bw为预留带宽;ts,te分别为开始时间和结束时间。
2.2 基于单链表的数据结构
文献[6]不仅提出了基于单链表的数据结构,还提出了与该结构配套的预处理及回收等思想,并通过仿真实验来证明该结构有着不错的存储性能和接纳性能。
基于单链表的数据结构为:

其中,ts为预留请求的开始时间,bw为当前节点的时间段内已经被预留的带宽。因此一个节点所覆盖的时间段是从p1->ts到 p2->ts。p2为p1的下一个节点。链表最后一个节点的next为空。它表示最后一个节点p所覆盖的时间段是从p->ts到结束。通常最后一个节点的bw值为0,因为在p所覆盖的时间段内没有带宽被预留。
文献[6]还描述了插入、预处理与回收的思想。首先,链表中仅有一个头节点 head(0,0,null)。当预留请求 req(ts,te,bw)到达,且请求被允许(判断剩余的带宽是否足够预留),1个或2个新节点将被加入链表中。他们在链表中的位置由其开始时间决定。检查和插入工作需要在每一次请求到达后完成。
为了避免每一次都从头节点开始寻找合适的位置,利用一个“local”指针来标识前一次请求搜索到的开始节点。为了实现它,需要搜集一个给定时段内的所有预留请求,并按它们的开始时间排序,然后再一起对它们进行接纳控制。同时,可以通过释放过期的节点来回收内存。过期节点是指所覆盖的时间段远远早于当前时间的节点。
笔者分别对上述的算法思想进行了实现。其中预处理只是排序问题,这里不再叙述。对于回收,选择每隔一个固定的时间进行(在实验中这个时间是100 s),因为回收得太过频繁会降低整个数据结构的性能。
资源回收算法中empty函数的功能是清空链表,即将一个链表完全释放掉,实现较容易,这里不再叙述。
单链表资源回收算法描述如下:

单链表的插入算法是比较繁琐的,它涉及到多种情况,在这里提供一种实现方法如下:


下面讨论结束节点的情况:

生成新节点,插入到两节点之间。
上面只是描述了插入算法的实现过程,具体实现中还涉及带宽bw的修改,local指针的指向等问题,限于篇幅,在这里不再描述。
2.3 索引链表数据结构
以上对单链表的算法思想进行了描述并给出了实现的关键算法,但该结构还存在很多弊端。首先,即使经过了预处理,每次在移动节点的过程中还是不能迅速定位,在检查与插入阶段都要浪费很多时间;其次,资源预留的其他模块对该链表进行搜索时,必须从头节点开始查找,搜索效率较低。
针对单链表存在的上述问题,笔者提出了一种改进的数据结构,称为索引链表。其核心思想如下:
定义一个额外的索引数组,为保证查找速度,这个数组要尽量短小(如在实验中,所定义的索引数组是indexs[101])。该数组中的每一个元素都指向单链表中的一个节点,这种指向符合某种散列函数。
例如indexs[1]指向 ts=10的节点,它符合i=ts/10的散列函数,同样,ts=550的节点由indexs[55]指向。如果在单链表中并没有ts=55的这个节点,那么此时索引数组中indexs[55]指向头节点head。这是因为在初始化过程中,索引数组的所有元素都被指向头节点head。
在插入过程中,如果某一预留请求req,有req(ts)%10==0,则这个请求形成的新节点就由索引数组indexs[ts/10]指向。图1示意了这种索引链表的结构[8]。
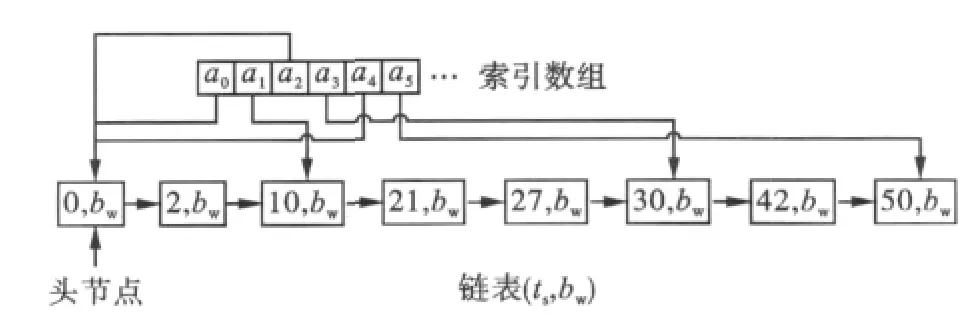
图1 索引链表示意图
在定位或查询过程中,首先按散列式i=ts/10来查询索引数组 indexs[i],如果该元素指向head,则向前移动一个(i-1),直至找到一个合适的元素,或者搜索失败。例如定位ts=555的节点,有散列式 i=ts/10,可查询数组元素 indexs[55],该元素指向 ts=550的节点。如果 indexs[55]指向head,则依次向前查找,搜索最近的可用节点(指针指向链表中其他节点,而不是指向head节点);如果找不到,直至搜索失败。
搜索失败有两种情况,当没有local指针时,一直搜索到索引数组的最小元素(关于最小元素后面会有说明,它不总是 indexs[0]);当有 local指针时,搜索到local指针前的最后一个元素时就应该停止。
随着时间的推移,ts的值会越来越大,总会有超过索引数组边界的时候。为了防止这种溢出,必须将索引数组设计为环形,以循环利用数组的存储空间。
数组的循环是这样实现的:定义一个值min,该值为数组的最小值,很显然初始时min=0。当资源回收时(每隔100 s),也同时对索引链表进行资源回收。其实现方法如下:

由于每过100 s,索引数组相应有10个元素已经过期,因此,回收这10个元素,同时将最小值min加10。为了使索引数组循环起来,在定位与插入的时候也要相应地判断ts是否已大于门限值1000,其实现方法如下:
变量说明:x,sign都是int型变量,而local是文献[6]中提到的local指针。

这里忽略了节点合并的问题,插入过程中可能会出现这种情况,时间相邻的两个节点p1,p2;原本p1->bw!=p2->bw,但某次插入后可能会出现p1->bw==p2->bw。这时两个节点中有一个是冗余的,应该合并。但笔者舍弃了这种操作,一方面是这种情况出现的概率较低;另一方面是合并必须在插入过程中加入额外的检查和操作,这样就大大影响了插入操作的性能。
3 测试与评估
3.1 发送端环境
发送端由一组随机数发生器来实现,其产生一系列的资源提前预留请求。请求的数据结构中带宽(bw)遵循(100,1000)范围内的均匀分布,单位为kB。开始时间(ts)遵循(20,80)范围内的均匀分布,单位为s。持续时间(td)遵循参数为0.01的指数分布,单位为s。随机发生时间遵循参数为1的泊松分布,单位为s。实际测试过程中可以同时模拟多个发送端(测试环境为Linux操作系统,同时开多个shell窗口运行多个发送端),以增加资源请求的发生速度[9-10]。
3.2 评估指标
所采取的评估指标主要有3个:内存需求,请求接纳时间和请求搜索时间。其中内存需求是指数据在运行过程中所消耗的内存;请求接纳时间是指数据结构的检查与插入时间;请求搜索时间是指其他程序在扫描和搜索数据结构时所耗费的时间。
内存需求与请求接纳时间通过实际的测试,按照真实的数据来评估各个数据结构的性能。而请求搜索时间无需测试,从数据结构本身的特点即可说明各个数据结构间的差异。
3.3 测试结果
图2所示为在两倍速率环境下(同时开两个发送端),4种数据结构的请求接纳时间。由图2可见,索引链表有比较明显的优势,单链表和双链表紧随其后,二者的性能比较接近。

图2 请求接纳时间比较图
其中,单链表和双链表的曲线呈锯齿形,这与回收间隔时间有关,每次回收之后,速度会有所提高。而时隙数组的性能比较稳定,这是由于它没有不确定因素。索引链表的性能呈不规则状,是由于每次用索引定位成功的几率所导致的差异,但是其总体性能要明显优于其他数据结构。
图3所示为在两倍速率环境下,4种数据结构的内存需求。笔者对于3种链表(单链表、双链表和索引链表)只测试了其中单链表的内存消耗,由于双链表和索引链表的内存消耗是在单链表的基础上增加一个定值,因此不需要重复测试,而时隙数组保持一个固定值。由图3可见,单链表的内存需求略优于索引链表和双链表。
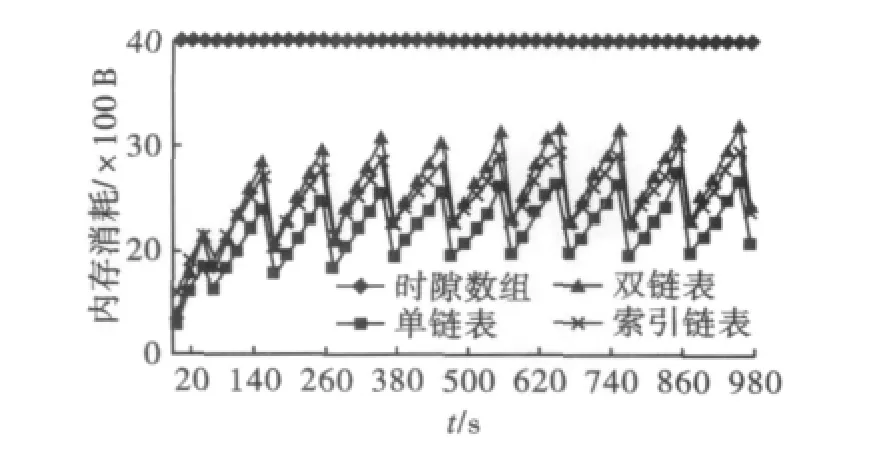
图3 内存需求比较图
3种链表的锯齿形曲线是由回收函数造成的,索引链表比单链表增加了索引数组的内存需求(404 B),而双链表比单链表每个节点增加了4 B(前向指针)。因此在节点数目大于101个时,索引链表的内存需求要优于双链表,而在实验中的大部分时间节点数目都大于101个。
至于请求搜索时间,从数据结构的特性就可以分析出,不需要进行测试。时隙数组是随机搜索,可在非常短的时间内完成。由于目标地址由数组起始地址+偏移量所得,通过基址寻址可直接得到,因此它的搜索效率是最优的。而单链表和双链表只支持顺序搜索,因此比索引链表效率要低。这一点在测试接纳时间时就已得到验证,因为索引链表比单链表改进的就是搜索定位的速度。单链表和双链表两者的搜索速度几乎一样。
4 结论
一个性能优良的数据结构对资源预留有着至关重要的意义,笔者挑选了3种比较有代表性的数据结构(时隙数组、单链表和双链表)作为比较对象,并提出了一种新的数据结构,即索引链表,在Linux平台采用C语言进行了完整的实现。测试结果表明:
(1)索引链表表现出了良好的性能,它在各方面都有出色的表现,接纳时间是最优的,内存需求仅次于单链表,搜索时间仅次于时隙数组。
(2)单链表和双链表表现基本持平,处于中上游水平,单链表在内存需求上是最节省的。
(3)时隙数组在搜索时间上性能最好,它受发送端的影响较大,时隙的确定和数组的长度,都与发送端请求产生的密度和速度有关。
[1]ZHANG H,KEAHEY K,ALLCOCK W.Providing data transfer with QoS as agreement-based service[C]//Proceeding of the IEEE International Conference on Services Computing.[S.l.]:IEEE Computer Society,2004:344-353.
[2]BURCHARD L O,HEISS H U.Performance evaluation of data structures for admission control in bandwidth brokers[R].Berlin:Communications and Operating Systems Group,Technical University of Berlin,2002.
[3]NILSSON A,CHEN J,CARLSSON S.An efficient data structure for advance bandwidth reservation on the internet[R].CSEE:Lulea University of Technology,2008.
[4]SIM K M.Grid resource negotiation:survey and new directions[C]//IEEE Transactions on Systems,Man,and Cybernetics.[S.l.]:[s.n.],2010:1-13.
[5]BURCHARD L,HEISS H U.Performance issues of bandwidth reservation for grid computing[C]//Proceedings of the 15th Symposium on Computer Archetecture and High Performance Computing(SBACPAD'03).[S.l.]:[s.n.],2003:25-29.
[6]XIONG Q,WU C L,XING J B,et al.A linked-list data structure for advance reservation admission control[C]//ICCNMC 2005,LNCS 3619.[S.l.]:[s.n.],2005:901–910.
[7]WANG T,CHEN J E.Bandwidth tree:a data structure for routing in networks with advanced reservations[C]//Performance,Computing,and Communications Conference,21st IEEE International.[S.l.]:[s.n.],2002:37-44.
[8]QU M C.Storage resource reservation method for data grid[J].Journal of Harbin Institute of Technology,2010,42(3):432-436.
[9]CUCINAOTTA T,KONSTANTELI K,VARVARIGOU T.Advance reservations for distributed real-time workflows with probabilistic service guarantees[C]//Proceedings of 2009 IEEE International Conference on Service-Oriented Computing and Applications(SOCA,2009).[S.l.]:[s.n.],2009:1-8.
[10]RAJAH K,RANKA S,YE X.Advance reservations and scheduling for bulk transfers in research networks[J].IEEE Transactions on Parallel and Distributed Systems,2009,20(8):1682-1697.
