面向情感分析的短文本意义串发现及分析算法
2011-09-07刘建波
刘建波
(山东财政学院计算机网络中心,山东 济南 250014)
Web 2.0概念的出现使互联网新媒体的发展进入了新阶段,互联网上出现了大量带有情感色彩的主观性短文本,呈现的形式也多样化[1-2]。通过网络短文本信息,人们记录自己的日常生活及事务,抒发感情、释放情绪。如今的网络已成为史上最大的情感仓库。利用这个情感仓库,并从中挖掘有价值的信息,识别出群体的舆情趋向及演化规律,可以更好地分析人们的情感以及社会舆情热点,具有较大的研究和应用价值,对情感话题的检测与跟踪、网络用户群体极端行为方向的挖掘与思想异常检测等方面有重要的价值。
1 相关研究
当前有关情感分析的研究成果主要集中在英文语种,由于中文语言在词法和句法表达上有别于其他语言,使得许多已有方法并不能直接用于中文处理,因此基于汉语情感词组挖掘算法值得深入研究[3-5]。
TURNEY等提出的基于语义方法的情感分类研究已经具有了初步的应用价值[6];WIEBE等专注于识别文本中能够表达主观情感的特征,为客户情感分析研究提供了方法;除此之外,还有一些学者采用由普林斯顿大学开发的英文词网(WordNet)进行英文语义方法的情感分析,也取得了较好的分析结果。国内相关研究也取得了一定的成果,复旦大学金峰等人提出的基于倾向性文本过滤系统,能够对具有关于某个主题的特定倾向的文本进行过滤;FEI等提出基于短语模式的分类方法,利用机器学习方法,针对sport.yahoo.com英文体育评论开展了情感分析研究[7]。笔者提出一种面向情感分析的网络短文本意义串算法,基于改进FP-树最大频繁模式发现算法得到关键词汇集合后,结合词语局部性原理对词汇集合进一步进行有意义字串挖掘,最后针对挖掘的意义串进行情感分析[8-11]。
2 基于改进FP-树最大频繁模式挖掘算法
针对网络中文短文本的特点,笔者提出一种基于改进的FP-树结构来完成频繁模式的挖掘,改进后的FP-树与传统FP-树相比主要有以下特点:
(1)传统FP-树是双向的,而改进的FP-树是单向的,不存在从树根到树叶的路径,改进的FP-树包含较少的指针,节省大量的存储空间。
(2)改进FP-树的节点用项的序号标记其支持数,项的序号按支持度由大到小排序确定。每个节点包含 4个域:item、count、ahead和 next,其中item为结点名称,count为项目计数,ahead为指向最左子女节点或父节点的指针,next为指向兄弟节点或节点链中下一节点的指针。
2.1 算法概述
基于改进FP-树最大频繁模式挖掘算法如下:
输入FP-树、最小支持度阈值Min_sup;输出最大频繁模式集合MFS;其操作步骤为:

2.2 算法实现
结合以上提出的基于改进FP-树,对表1中的事物集进行最大频繁模式挖掘。
表1中出现频次大于3的各个词语按照支持度计数分别为 5、5、4、4、4、4;根据支持度降序排列可以得到其对应的序号分别为 1、2、3、4、5、6,基于以上内容可以构造改进的FP-树,如图1所示。
基于改进FP-树最大频繁模式挖掘算法过程如下:


表1 短文本事物集
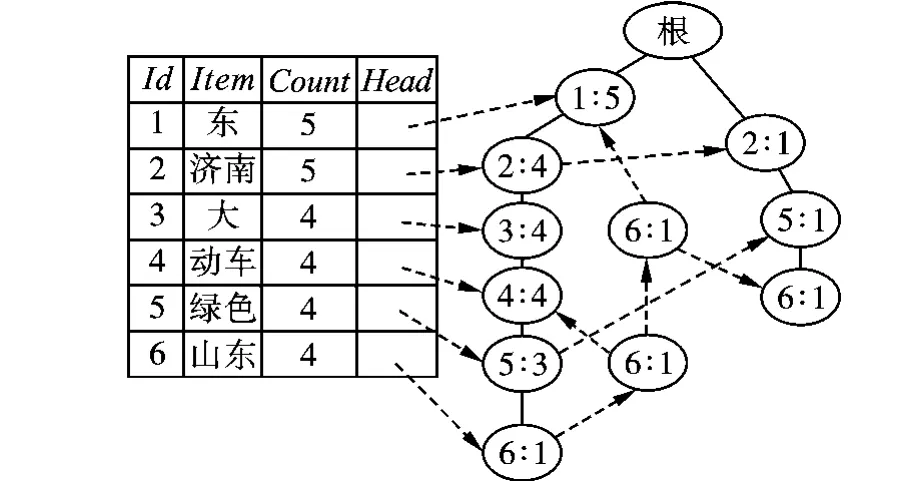
图1 频繁模式FP-树

最后根据序号转换表可得到最大频繁项目集为 MFS={{山东,济南},{山东,东},{绿色,动车,大,济南,东}}。从得到的频繁模式可以看出,按照以上算法得到的短文本最大化重复串在汉语语法中不一定是有意义字串,如“东”和“绿色,动车,大,济南,东”,而“山东济南”才有实际意义。因此,还要基于短文本的最大化重复串挖掘有意义字串。
3 基于局部性原理进行有意义串挖掘
由于中文语法与西文语法不同,挖掘出来的词有一定的局部性。所谓词语局部性,有两层含义:时间局部性和空间局部性。时间局部性是指不同的时间段出现的有意义词语不同,如新闻热点出现后不一定在短时间内成为人们谈论的焦点;空间局部性是指在不同领域的文档中出现的有意义词语可能不同,如大学校园BBS与财经专业BBS中挖掘出来的有参考价值的词语不同。因此,笔者结合局部性度量策略的约束条件从以下几方面对重复串进行处理:多中心点分簇、抗噪音处理和频次归一化约束。
3.1 对文本库分簇,形成多中心点
字符串在短文本库各出现位置按照一定的策略划分为若干簇,对每个簇分别计算中心点,度量字符串在该簇内分布的局部性,得出字符串在整个文本库中总局部性度量。
3.2 有效处理噪音
在文本中,某个词如果在图1所示的3个部分出现,第2和第3处出现的频次远高于第1处,因此可以将第1处称作孤立点或噪音。噪音对于文本的分簇影响较大,计算方差过程中带有噪音的方差较大,偏离实际。因此在算法中要有效处理噪音。
3.3 词语出现频次归一化约束
中文词语的局部性与其出现的频次(密度)有关系,密度越大,其局部性越高,但是也不能单一比较词语在文本中的某个位置的密度或频次,如在图2和图3中,字符串A在3位置的密度高于字符串B在2的位置,不能说明字符串A的局部性高于B,要对没有噪音的短文本中所有出现重复串的密度作归一化处理,计算其平均局部性,即各个区域局部性的平均值,保证词语局部性的计算不局限于某个特定的区域,而是各区域局部性的综合。

图2 字符串A出现位置
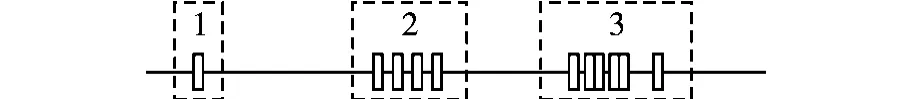
图3 字符串B出现位置
3.4 局部性度量算法
若字符串S在短文本中出现n次,各出现位置分别为 P1,P2,…,Pn,字符串的局部性度量算法主要通过以下几个过程完成。
(1)计算参考距离。用参考距离Distance确定位置点的簇类,使用字符串在文本中各相邻位置之间距离的平均值作为位置点聚类的参考距离,则字符串S的参考距离可由式(1)计算:
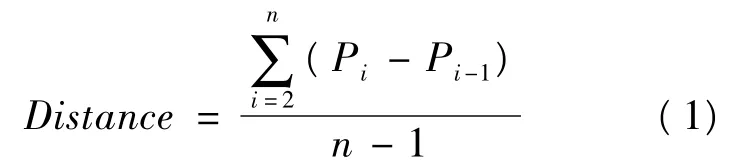
(2)位置点聚类。对于重复串出现的所有位置点按照参考距离进行聚类,基本算法如下:
初始化当前聚类C={P1};
对于1<i<n+1,循环计算 Pi-Pi-1,如果Pi-Pi-1>Distance,将 C加入 R,清空 C;否则将Pi加入C。
通过以上算法,结合式(1)求出的参考距离,对所有最大化重复串位置点分簇,使得同一簇内距离较小,而不同簇间的距离较大,从而得到较好的归一化结果。
(3)字符串的整体局部性。字符串的整体局部性可以通过字符串在各簇局部性的平均值来度量,若根据各字符串出现的位置点最终划分为k个簇{C1,C2,…,Ck},字符串在每个簇 Ci的位置方差为Vi,其局部性的平均值为:
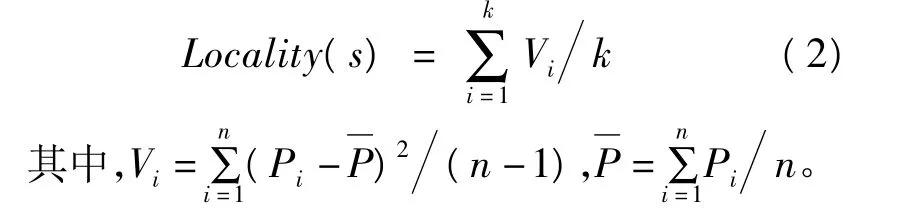
(4)字符串意义指数度量。通过后缀数组的频繁模式发现算法得到最大重复串集合R={S1,S2,…,Sn},并分别计算字符串在整个短文本中的局部性,利用式(3)度量各个字符串的有意义指数:
其中,λ为指数影响因子,其设置为了影响MI的计算数值,可以通过实验数据来分析其取值变化对指数计算的影响,最后确定针对不同词语密度的最佳数值,提高短文本聚类分析的数据结果的准确率。
4 实验结果分析
4.1 指数影响因子的确定
在我校学生论坛系统中,帖子以文本文件格式存放,其格式与短文本的特点一致。因此,选取某一段时间数据做实证分析。通过Visual C++实现以上算法,求出频次大于180的重复串,λ的取值从0变化到1,步长为0.05,对0~1的每一个λ值,按照式(3)计算各字符串的MI值并排序,分别选取排序靠前的200个、400个、800个候选有意义串,统计其准确率如图4所示。
从图4可以看出,λ的最佳取值随着候选有意义串的数量增大而增大。当候选有意义串数量为200时,λ的最佳取值为0.3;当候选有意义串数量为400时,λ的最佳取值为0.4;当候选有意义串的数量超过800时,λ的最佳取值为0.5。
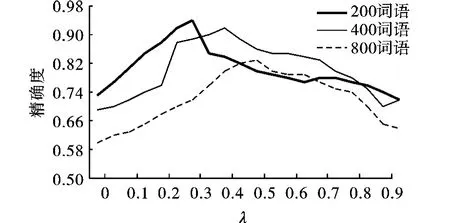
图4 影响因子阈值及其精确度
4.2 基于有意义串挖掘结果的情感分析
确定不同数量字符串对应最佳影响因子阈值之后,可以对论坛中的短文本数据重新进行聚类分析。缩小时间范围,试验中得到2010年上半年论坛文本数据的挖掘结果,如表2所示,在表2中列出了出现频次排名比较靠前的有意义字串,如“山东财经大学”排在第一,说明学校用户对我校整合其他院校以及更改校名事件比较敏感,以及合校之前新校长的上任比较关心;“非诚勿扰”单身交友节目是适龄大学生们的情感聚集;“酒后驾车”、“富二代”是社会的关注热点。
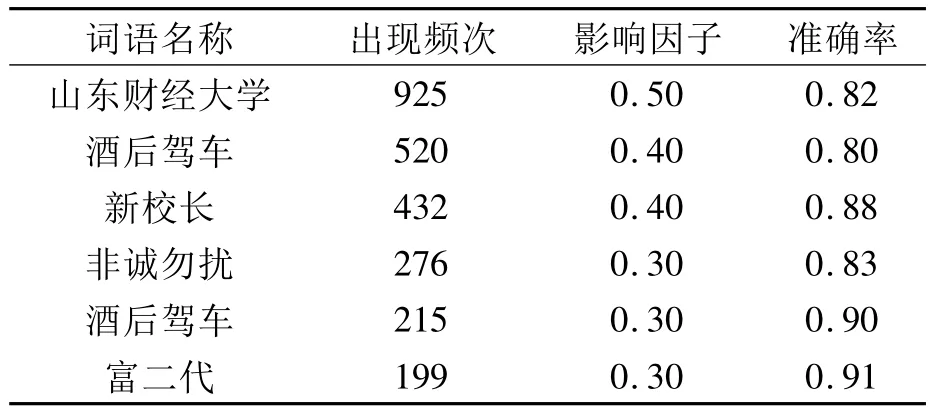
表2 字符串聚类结果
5 结论
通过以上的分析,笔者提出的面向情感分析的短文本意义串发现及分析算法,实现简洁,执行效率高。但是,相比传统的英文文本分类,中文文本情感分析有先天的困难和挑战,主要表现在汉语语言表达方式的多样化,算法需要考虑更多的影响因子以及对应的阈值,以便提高其有效性。
[1]周立柱,贺宇凯.情感分析研究综述[J].计算机应用研究,2008,28(11):2726-2727.
[2]胡佳妮,郭军,邓伟洪.基于短文本的独立语义特征抽取算法[J].通信学报,2007,28(12):121-122.
[3]蔡月红,朱倩,孙萍.基于属性选择的半监督短文本分类算法[J].计算机应用,2010,30(4):1015-1017.
[4]龚才春.短文本语言计算的关键技术研究[D].北京:中国科学院计算技术研究所,2008.
[5]柴春梅.互联网短文本信息分类关键技术研究[D].上海:上海交通大学图书馆,2009.
[6]TURNEY P D.Thumbs up or thumbs down?semantic orientation applied to unsupervised classification of reviews[C]//Proceeding of Association for Computational Linguistics 40th Anniversary Meeting.[S.l.]:[s.n.],2002:417-424.
[7]FEI Z C ,LIU J,WU G F.Sentiment classification using phrase patterns[C]//Proceedings of the Fourth International Conference on Computer and Information Technology(CIT'04).[S.l.]:[s.n.],2004:2-5.
[8]林森媚,谢伙生,白清源.基于合并FP-树的频繁模式挖掘算法[J].广西师范大学学报,2009,25(4):254-255.
[9]秦亮曦,史忠植.SFP-Max:基于排序FP-树的最大频繁模式挖掘算法[J].计算机研究与发展,2005,42(2):217-223.
[10]杨君锐,赵群礼.基于FP-Tree的最大频繁项目集更新挖掘算法[J].华中科技大学学报:自然科学版,2004,32(11):88-90.
[11]GEORGE A M.WordNet:a lexical database for English[J].Communications of the ACM,1995,38(11):39-41.
