基于模拟退火的多标记数据特征选择
2011-09-07张永波游录金陈杰新
张永波, 游录金, 陈杰新
(1.浙江旅游职业学院图书信息中心,浙江杭州311231;2.上海思备计算机有限公司,上海200030;3.宁波城市职业技术学院信息中心,浙江宁波315100)
0 引 言
若一个样本和多个类标相关联,则称这样的数据为多标记数据。在当前的数据分析领域,多标记数据分析任务有很多[1-8]。比如,在网页分类中,不同的网页属于不同的主题,而且有多个类别,一个具有海滩和高山的图片,可以分类为大海、高山、风景等不同的语义类。现在常见的多标记学习算法中,一个个样例与多个类标关联在一起,多标记学习技术要为未知测试样例预测其类标集合,一般情况下,类标集合大小并不知道的。多标记学习所使用的数据通常都是高维数据,由于多标记学习技术的复杂性,其降维和特征选择方法的研究仍然很少。目前多标记学习技术大体可以分为两类[1-2]:转化问题方法,改写算法方法。转化问题方法独立于算法,把多标记学习任务转化为一个或多个但标记分类任务,如单标记学习打分、组合类标、继承学习方法等;改写算法方法通过扩展特定的学习算法(如Boosting,支持向量机,决策树等)来直接处理多标记数据。
对于特征维数高影响学习器效果方面,近年发表的一个特征抽取方法是多标记最大依赖维数约简(MDDM)算法[9-10],这个方法采用希尔伯特-斯密特准则(Hilbert-Schmidt independence criterion,HSIC)作为依赖性的评测准则。这个算法的最大特色在于通过最大化数据集特征集合与类标的依赖性,这样可以监督方式得到低维特征空间,已有的实验结果显示MDDM性能略优于局部投影追踪(LPP),主成份分析(PCA),明显优于多标记线性语义索引(MLSI)。多标记线性降维方法[11]将最小平方损以及其他损失函数如hinge loss和squared hinge loss用于多标记学习问题中,也取得了较好的效果。MDDM和多标记线性降维算法的一个问题就是无法得到低维的原始特征,不利于科学问题的理解。
特征选择旨在去除不相关特征和冗余特征,力求以最少的特征来表达原始信息,并达到最优的预测或分类精度。特征选择能够明显提高分类模型的可理解性并且建立一个能更好的预测未知样本的分类模型,具有重要的现实意义,当前主要的特征选择方法大致可分为3类:过滤式特征选择方法(filter)[12],封装式特征选择方法(wrapper),嵌入式特征选择方法(embedded)[13]。封装式方法依赖于分类器,在封装式方法中,学习算法被“包含”在特征选择中。封装式方法用学习器来评估用潜在的特征子集预测类标时精确度。虽然封装式方法比较费时,但是选择结果是建立在学习算法基础上,所得结果对特定的学习技术是最优的,所以在科学数据分析中应用广泛。在多标记特征选择方面,文献[12]使用了过滤式特征选择技术,文献[13]去年提出的嵌入式特征选择方法(MEFS),并结合到半监督多标记学习的特征选择中[14]。在封装式特征选择中,遗传算法被引入到特征选择中取得了较好效果[15]。
本文将结合多种多标记学习算法,尝试模拟退火的优化技术,提高封装式特征选择的效果,并与已有的多标记数据降维方法进行比较。
1 SAML算法
葛雷等采用嵌入式特征选择进行多标记数据选择,提出MEFS,本文算法结构与之类似,所以先给出MEFS算法如图1所示[13]。张敏灵等采用遗传算法对多标记数据进行特征选择分析[15],但是该算法仅仅结合MLNB-Basic算法,并且遗传算法在优化方面有一定局限性,如果尝试不同优化技术,进行特征子集的搜索,或许能进一步提高特征选择效果。本文提出尝试引入变异算子的模拟退火算法,得到最优特征子集,提出了基于模拟退火的多标记特征选择算法,SAML(simulated annealing based feature selection for multi-label data)。如图2所示,算法在特征选择的过程中,以Average Precision结果作为特征子集的适应度函数。也即在训练数据上进行特征选择的过程中,在验证集上通过ML-KNN[16]、MLNB-BASIC[15]等多标记学习技术建模所得测试结果的Average_Precision准则作为评估特征子集的适应度函数。Average_Precision准则详见文献[1]。

图1 MEFS算法

图2 SAML算法
2 数据与实验设置
SAML将与MEFS[5]和MLNB[7]等两个方法在YAHOO页面分类数据集上进行比较。ML-KNN[8]和MLNB-Basic[7]作为多标记分类器,k设置为10[8]。为了比较SAML进行特征选择的效果,用ORI表示原始空间下训练的结果。
Yahoo(http://www.keel.ntt.co.jp/as/members/ueda/yahoo.tar.gz)网页数据集是从“yahoo.com”网站收集的网页面,有11个子数据集。每个数据集包含2000个训练数据文本和3000个测试数据文本。本文使用2个子数据集,它们详细情况如表1所示。这些数据集在先后用到很多的工作中,这些工作都用了这个数据集进行算法评测,所以这些数据都很权威。

表1 Yahoo数据集的描述
3 SAML特征选择结果
选择AveragePrecision作为SAML特征选择的评价指标。选择Yahoo数据集中Arts&Humanities和Business&Economy作为样例,对SAML与MEFS,MLNB的特征选择效果进行分析比较。Arts&Humanities和Business&Economy数据集上的结果分别列在表2-表5中,并用粗体表示最优结果。
从实验结果中,我们可以看出SAML和MLNB稍优于MEFS,明显优于ORI。同时,经过SAML进行特征选择后,Hammingloss,Coverage以及AveragePrecision等指标都明显提高。不同学习器效果略有不同,在ML-kNN上SAML所得结果明显比MLNB有好的结果,而在MLNB-Basic作为分类器时,SAML跟MLNB则效果相当。综合两种分类器上的结果,得出SAML略好或相当于MLNB的结论。
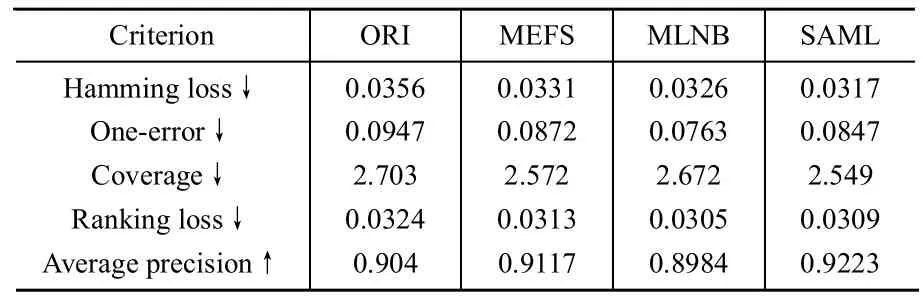
表2 Arts&Humanities上ML-KNN的结果
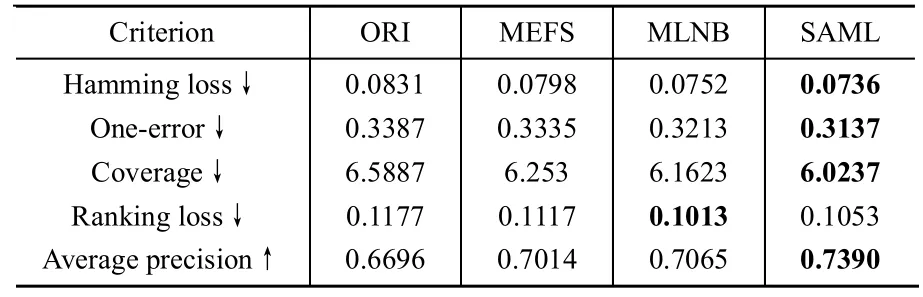
表3 Business&Economy上ML-KNN的结果
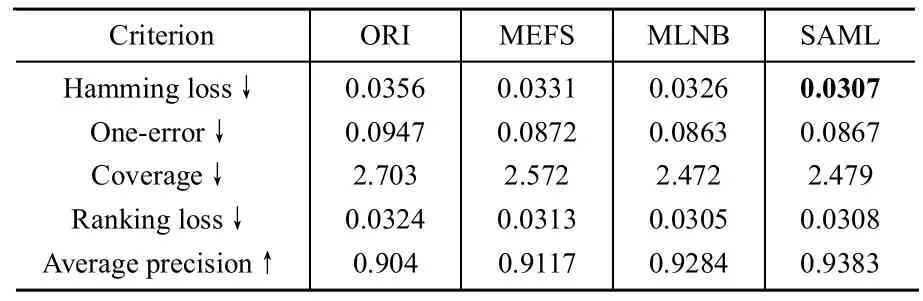
表4 Arts&Humanities上MLNB-Basic的结果

表5 Business&Economy上MLNB-Basic的结果
4 结束语
本文将模拟退火用于多标记数据的特征选择中,用卷积式模型的特征选择技术,这样可以克服有监督的多标记特征选择中的很多问题,比如复杂的多标记交错带来的问题。在Yahoo网页上的实验证明,基于模拟退火的卷积式特征选择方法能够有效提高多标记学习的建模精度。进一步的工作包括如何进行高效的特征选择,如何提高多标记特征选择的速度、如何通过更高级的技术来处理多标记的问题。今后将在更多的多标记学习技术[17-18]和数据集上进行研究,提高算法的适应性和效率。
[1]Tsousmakas G,Zhang M L,Zhou Z H.Learning from multi-label data[C].Bled,Slovenia:ECML/PKDD'09,2009.
[2]Zhang M-L,Zhou Z-H.Multi-label learning by instance differentiation[C].Vancouver,Canada:Proceedings of the 22nd AAAI Conference on Artificial Intelligence,2007:669-674.
[3]Zhou Z-H,Zhang M-L.Multi-instance multi-label learning with application to scene classification[C].Schölkopf B,Platt J C,Hofmann T,et al.Vancouver,Canada:Advances in Neural Information Processing Systems.Cambridge,MA:MIT Press,2007:1609-1616.
[4]Zhang M-L,Zhou Z-H.A k-nearest neighbor based algorithm for multi-label classification[C].Beijing,China:Proceedings of the 1st IEEE International Conference on Granular Computing,2005:718-721.
[5]Zhang M-L,Zhou Z-H.Multilabel neural networks with applications to functional genomics and text categorization[J].IEEE Transactions on Knowledge and Data Engineering,2006,18(10):1338-1351.
[6]Jin R,Wang S,Zhou Z-H.Learning a distance metric from multiinstance multi-label data[C].Miami,FL:Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition,2009:896-902.
[7]Li Y-X,Ji S,Kumar S,et al.Drosophila gene expression pattern annotation through multi-instance multi-label learningb[J].ACM/IEEE Transactions on Computational Biology and Bioinformatics,2011,4(2):22-35.
[8]Li Y-X,Ji S,Ye J,et al.Drosophila gene expression pattern annota-tion through multi-instance multi-label learning[C].Pasadena,CA:Proceedings of the 21st International Joint Conference on Artificial Intelligence,2009:1445-1450.
[9]Zhang Y,Zhou Z-H.Multi-label dimensionality reduction via dependency maximization[C].Chicago,IL:Proceedings of the 23rd AAAI Conference on Artificial Intelligence,2008:1503-1505.
[10]Zhang Y,Zhou Z H.Multi-label dimensionality reduction via dependence maximization[J].ACM Transactions on Knowledge Discovery from Data,2010,4(3):14-24.
[11]Ji S W,Ye J P.Linear dimensionality reduction for Multi-Label classification[C].Pasadena,CA:Proceedings of the 21st International Conference on Artificial Intelligence,2009:1077-1082.
[12]LiuY-H,Li G-Z,Zhang H-Y,etal.Feature selectionforgenefunction prediction by using multi-label lazy learning[J].International Journal of Functional Informatics and Personalised Medicine,Inderscience,2008,1(3):223-233.
[13]葛雷,李国正,尤鸣宇.多标记学习的嵌入式特征选择[J].南京大学学报,2009,45(5):671-676.
[14]Li G-Z,You M,Ge L,et al.Feature selection for semi-supervised multi-label learning with application to gene function analysis[C].Niagara Falls,NY:Proceedings of The First ACM International Conference On Bioinformatics and Computational Biology,2010:354-357.
[15]Zhang M L,Pena J M,Robles V,et al.Feature selection for multilabel naive Bayes classification[J].Information Sciences,2009,179(19):3218-3229.
[16]Zhang ML,ZhouZ H.ML-KNN:A lazylearning approachto multi-label learning[J].Pattern Recognition,2007,40(7):2038-2048.
[17]Zhang M L,Zhou Z-H.M3MIML:A maximum margin method for multi-instance multi-label learning[C].Pisa,Italy:Proceedings of the 8th IEEE International Conference on Data Mining,2008:688-697.
[18]Sun Y-Y,Zhang Y,Zhou Z-H.Multi-label learning with weak label[C].Atlanta,GA:Proceedings of the 24th AAAI Conference on Artificial Intelligence,2010:593-598.
