DB2数据库索引
2011-08-30孙锟
孙 锟
同济大学软件学院,上海 201804
0 引言
数据库对于银行的业务来说无疑有着至关重要的作用,核心数据全部保存于数据库中。每天银行都有着成千上万笔交易,其中查询功能占据着业务的很大一部分比例。如何在现有的数据基础上大幅提升性能,如何提升效率从而降低企业成本,是每个银行需要面对的问题。本文从数据库索引的特征方面入手简单介绍一下在IBM大型机平台上的大型关系数据库db2索引的特征和简单用法。
1 大型关系数据库DB2简介
1970 年IBM公司的研究员E.F.Codd 发表了业界第一篇关于关系数据库理论的论文"A Relational Model of Data for Large Shared Data Banks",首次提出了关系模型的概念。这篇论文是计算机科学史上最重要的论文之一,奠定了Codd博士"关系数据库之父"的地位,同时也为DB2数据库打下了坚实的理论基础。1983年,IBM推出了这款大型数据库软件, DATABASE 2(DB2)for MVS(内部代号为"Eagle")。
经历25年的发展,DB2现在除了应用于IBM的OS/390、z/OS大型机平台之外,还可以应用于中型机AS/400以及OS/2、windows2000等pc机上,平台具有非常好的伸缩性。DB2为用户提供数据可用性,完整性、安全性、可恢复性以及高效的执行能力,满足了各个层次用户的需要。本文接着就DB2的索引方面进行一下简单介绍。
2 DB2索引
DB2索引也是一种 DB2 对象(一个单独的 VSAM 数据集),它由一组排好序的键组成,这些键是从相应表中的一个列或多个列抽取出来的。
2.1 DB2索引类型
2.1.1 非唯一索引
实际应用当中大部分的索引是非唯一索引。一般性的数据都具有可重复性特性,所以他们不能被定义为唯一索引。
2.1.2 唯一索引
唯一索引用来保证数据的唯一性,唯一索引一般性能要高于非唯一索引,这与索引的稠密度有关。唯一索引的稠密度永远等于数据总条数的倒数。
2.1.3 纯索引
纯索引的概念是相对与一般索引。如下方式表中有俩个字段,其中字段1是唯一主键,字段2为数据,实际的查询中经常是select * from 表 where col1=?这样的查询条件可以使用纯索引来避免表查询,具体创建命令为:CREATE UNIQUE INDEX
2.1.4 群集索引
群集索引允许对数据页采用更线性的访问模式,允许更有效的预取,并且避免排序。群集索引是要求数据在插入时,做更多的操作,将相临的数据条目放入相同的页,使得查询速度更快,因为每次访问索引页要将所有的索引条目都访问完毕才移到下一页,保证了缓存池中任何一个时刻都只有一个索引页存在。
群集索引的特点:
1)高查询速度,数据页以键的顺序排列;
2)以键的顺序扫描整张表。
插入和更新需要做更多的事情,不建议经常插入和更新的表上做群集索引。
2.2 DB2索引结构

图1 B+树的一个简单实例
在DB2中,索引的物理结构是一个独立的VSAM数据集,逻辑结构是一颗B+树。B+树把它的存储块组织成一棵树。这棵树是平衡的,即从树根到树叶的所有路径都一样长。通常B+树有3层:根、中间层和叶,但也可以是任意多层。
典型的B+树结构:
根结点中至少有两个指针被使用。所有指针指向位于B+树下一层的存储块;
叶结点中,最后一个指针指向它右边的下一个叶结点存储块,即指向下一个键值大于它的块。在叶块的其他n个指针当中,至少有个指针被使用且指向数据记录;未使用的指针可看作空指针且不指向任何地方。如果第i个指数被使用,则指向具有第i个键值的记录;
在内层结点中,所有的n+1个指针都可以用来指向B+树中下一层的块。其中至少2个指针被实际使用(如果是根结点,则不管n多大都只要求至少两个指针被使用)。如果j个指针被使用,那该块中将有j-1个键,设为K1,K2……,Kj-1。第一个指针指向B+树的一部分,一些键值小于K1的记录可在这一部分找到。第二个指针指向B+树的另一部分,所有键值大小等于K1且小于K2的记录可在这一部分中。依此类推。最后,第j个指针指向B+树的又一部分,一些键值大于等于Kj-1的记录可以在这一部分中找到。注意:某些键值远小于K1或远大于Kj-1的记录可能根本无法通过该块到达,但可通过同一层的其他块到达。
假若我们以常规的画树方式来画B+树,任一给定结点的子结点按从左(第一个子结点)到右(最后一个子结点)的顺序排列。那么,我们在任何一个层次上从左到右来看B+树的结点,结点的键值将按非减的顺序出现。下图为B+树的一个简单实例。(图1)
2.3 DB2索引访问机制
快速索引式访问
一般来将DB2最快的数据访问方式就是使用索引。索引是为了快速找着数据块的数据结构。
在DB2使用索引来查询数据前,必须满足以下要求:
1)至少有一个SQL谓词必须是可索引的;
2)其中一列必须作为可用索引中的列而存在。
2.4 DB2索引创建原则
DB2索引的数据结构实现是一个B+树,通过索引可以实现快速查询,避免全表扫描以此来减少IO操作。
索引是对表数据的一种抽象,通过抽取有限数据,对数据的分布进行计算,以此来完成对数据的快速检索。
索引创建基本语句:
“CREATE INDEX
创建索引需要注意的地方:
索引应该用来提高查询速度,但是会对更新和删除操作带来负面影响,因为要同步更新索引。所以索引应该创建到更新、删除相对比读取少的表上。
索引需要独立的空间进行存储和管理。索引是需要磁盘空间来存储。所以避免重复创建冗余索引。
索引用来避免表扫描。通过索引对大量数据抽取有限部分,形成一个相对少量的有序数据结构,通过对有序数据结构的查找可以快速想要查找的数据。所以索引适合建立在数据量比较大的表上,而且该表上的查询经常是根据条件查询部分数据。比如一些系统基础表,如SYSTEM表,这些表数据量小,而且经常是查询全部数据,所以这些表上建立索引对性能的影响不是很大,完全可以避免,以免对管理造成影响。
创建索引的目的还有一个就是保证数据唯一性。
主键会隐式创建索引,所以请不要在主键上创建索引浪费空间。
尽量减少索引的创建。DB2路径访问优化器会根据表中所提供的索引来完成尽可能多的访问路径的成本估计。创建过多的索引意味着DB2优化器生成更多的访问路径,完成更多的访问计划成本估算,这会增加SQL语句编译时间。
创建唯一索引可以避免排序。因为索引是有序数据结构,在进行扫描时,DB2会默认按照顺序输出结果,而不是按照插入先后。通过创建唯一索引可以避免排序,提高查询性能。
具有大量重复数据的列上不要创建索引。在大量重复的列上创建索引没有任何意义。
2.5 DB2索引优化
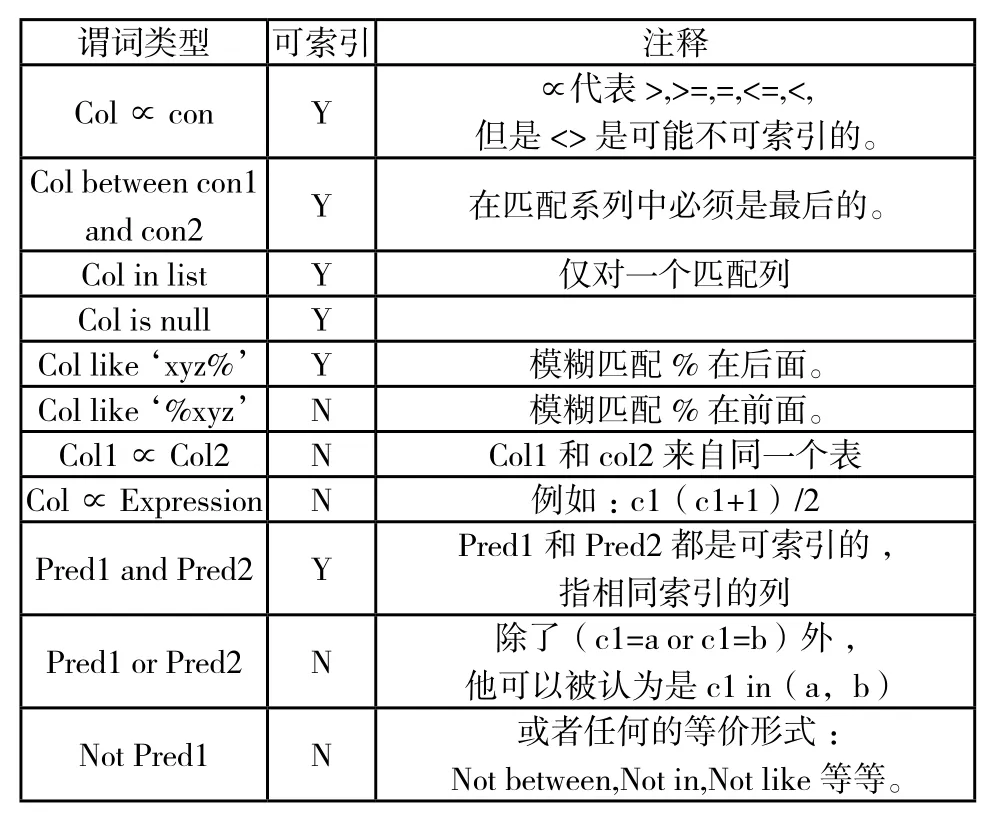
谓词类型 可索引 注释Col∝con Y ∝代表>,>=,=,<=,<,但是<>是可能不可索引的。Col between con1 and con2 Y 在匹配系列中必须是最后的。Col in list Y 仅对一个匹配列Col is null Y Col like ‘xyz%’Y模糊匹配%在后面。Col like ‘%xyz’N模糊匹配%在前面。Col1∝Col2 N Col1和col2来自同一个表Col∝Expression N 例如:c1(c1+1)/2 Pred1 and Pred2 Y Pred1和Pred2都是可索引的,指相同索引的列Pred1 or Pred2 N 除了(c1=a or c1=b)外,他可以被认为是c1 in(a,b)Not Pred1 N 或者任何的等价形式:Not between,Not in,Not like等等。
[1]牛新庄.DB2数据库性能调整和优化[M].清华大学出版社,2009.
[2]牛新庄.循序渐进DB2—DBA系统管理、运维与应用案例[M].清华大学出版社,2009.
[3]温涛,戴慰,等.DB2深度解析——高级DBA和开发者篇[M].东软电子出版社,2009.
[4]王飞鹏,等.DB2设计与性能优化——原理、方法与实践[M].电子工业出版社,2011.
