基于树结构的Web表格信息抽取方法
2011-08-28孙全红张贞贞
孙全红,张贞贞
(华北水利水电学院,河南郑州450011)
随着信息技术的发展和Web资源的极度膨胀,网络资源传统的信息获取方式已不能满足用户的需求.因此现在面临急需解决的问题是怎样从海量的网络资源中挖掘出有价值的和感兴趣的信息.网络信息挖掘是一个极其复杂的过程,它不同于传统的数据仓库技术和简单的知识发现,它面对的海量信息不是简单的结构化数据,而常常为半结构化数据,甚至是异构型数据[1].笔者从Web表格信息抽取方法的研究及实现方面来研究基于树结构的Web表格信息抽取的建模理论,简化建模的过程,缩短实现周期,为Web信息抽取建模提供新的思考方法.
1 Web表格信息抽取的设计
1.1 系统构成
Web表格信息抽取系统是以Web表格中的数据为信息抽取对象开发的工具,具有较高的通用性.主要有以下2个工具构成[2]:
a.二叉树构建工具.此工具也是Html文档分析工具,实现对文档结构的重建,包括Html解析和二叉树构建,即将一个Html文档转化成一颗含有文本信息的二叉树,供信息抽取使用.
b.信息抽取工具.利用全文二叉树进行查找、信息抽取,并具有选项抽取等功能,即从一篇 Web文档的表格中提取出与用户感兴趣的关键词相关的表格信息.
二叉树构建工具以Html文档作为输入数据,将Html文档解析成DOM树,再将用户感兴趣的标记及其中的内容重新构建成一棵含有文本信息的二叉树.在此以表格为例进行信息抽取,设定“title(文档标题)、table(表)、td(列)、tr(行)”为感兴趣标记.图书信息见表1.

表1 图书信息表
表1对应的Html代码如下:


值得注意的是,这是一段纯净的Html代码,省去了属性值的设置,其所对应的DOM树形式如图1所示.

图1 DOM树示例
此DOM树转化成二叉树的格式如图2所示.在用树自动机时经常将DOM转转化为二叉树,具体见文献[3].这里为了提高操作效率,并不将DOM树所有结点转化成二叉树的结点,而只是将用户感兴趣的结点转化成二叉树.由于通常情况下一个文档只有一个Title,在信息抽取时可将Title进行单独处理,而不必放入到二叉树中.二叉树的左结点为DOM树中此结点的第一个孩子结点,右结点为此结点的兄弟结点,若有多个兄弟结点依次连线为右结点.
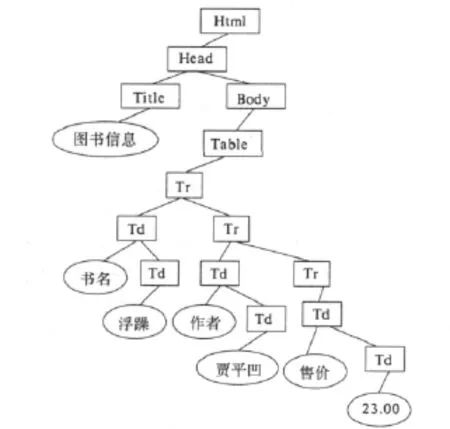
图2 文档二叉树
当Html文档转化成一棵二叉树后,信息抽取工具通过遍历二叉树查找用户感兴趣的关键词,然后将该关键词结点所在的行、列或所在的子表格中的所有内容作为信息抽取结果进行输出.
信息抽取时可使用较复杂关键字,用来表示信息抽取时的结合条件以支持多种信息抽取方式.如可使用参数and或or指定信息抽取关键字之间的关系.当只有一个信息关键字时,忽略该参数.信息抽取时,用信息抽取关键字和二叉树中所有结点的文本段进行匹配,有一个匹配成功时,认为该结点满足信息抽取条件.当有多个信息抽取关键字时,可使用该参数.信息抽取时,用所有的信息抽取关键字和二叉树结点的文本进行交叉匹配或重复匹配.关键词“and”表示所有的信息抽取关键字都可以和任意一个结点的文本相匹配时,认为该结点满足信息抽取条件.关键词“or”表示任意一个信息抽取关键字可以和任意一个结点的文本相匹配时,认为该结点满足信息抽取条件.
1.2 关键技术
开发工具采用JAVA语言,关键技术为构建二叉树构建和信息抽取2个工具时相关的类、方法及函数的构造及编程.在实现过程中,二叉树构建工具可包括 BinNode类、BinTagNode类、HtmlUtil类、FileUtil类、FileDownLoadUtil类和 HtmlParser类.
2 Web信息抽取的实现
2.1 二叉树构建工具
二叉树构建工具的功能是将获取到的Html文档转化为一棵含有文本信息的二叉树,供信息取用.图3为二叉树构建工具功能模型图.
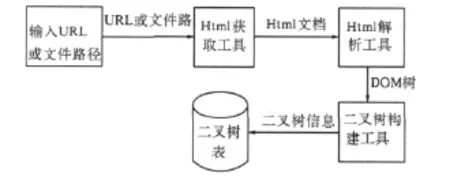
图3 二叉树构建工具功能模型图
Html获取工具由FileUtil类和FileDownLoadUtil类实现.Html解析工具由HtmlParser包实现.Html-Parser是一个纯JAVA写的Html解析库,它不依赖于其它的JAVA库文件,主要用于改造或提取Html.在实际的项目中只需要将HtmlParser.jar导入classpath中,就可以使用HtmlParser提供的API.
2.2 信息抽取工具
信息的抽取功能由类BinTagTree实现.主要是遍历二叉树,查找符合条件的结点,将信息提取到结果变量中.此方法用于遍历二叉树,找到满足条件的结点后,开始回溯到指定的抽取范围结点,提取信息放到结果列表中.有局部布尔变量isSuccess,表示是否匹配成功,初值为 true[4].
2.3 设计结果评测
该方法解决了在Html文档中的表格信息抽取问题.以抽取 http://www.265.com/weather/中的如图4所示的表格信息为例,阐述整个信息抽取过程.

图4 网页用例
a.根据给出的URL抽取信息.
以“河北”这个关键字为例,进行以下测试.当抽取范围为table时,输出所有河北省的天气信息.
当抽取范围为tr时,只输出河北保定的天气信息.输入关键字为“河,北”.测试结果:当抽取范围为table且抽取条件为and时,输出河北省的所有天气信息;当抽取范围为table且抽取条件为or时,输出所有包含“河”字或“北”字的省市的天气信息.本例中将输出河北省和北京市的所有天气信息;当抽取范围为tr且抽取条件为and时,输出河北保定的天气信息;当抽取范围为tr且抽取条件为or时,输出河北保定和北京市的天气信息.
b.从本地文件夹中选取指定文件,同时还支持多个相似网页的抽取.
这里选择2个文件,分别是华北地区和港澳台地区的天气信息.输入关键字“河,北”,抽取条件为or且抽取范围是tr,结果是输出河北保定、北京市和台北地区的天气信息.
3 结语
网络信息挖掘是数据挖掘技术中的一个新的分支,它涉及到网络技术、数据挖掘技术、多媒体技术、文本处理技术、人工智能技术等多个领域.参考WWW文本信息挖掘当前的流行技术,在以往研究的基础上,利用二叉树模型实现了针对表格的信息抽取引擎的开发,解决了表格的信息抽取问题,协助用户进行信息过滤,具有较强的通用性.
[1]蒲筱哥.基于Web的信息抽取技术研究综述[J].现代情报,2007,10(10):216 -217.
[2]王治和.表格信息抽取引擎的设计与实现[J].计算机科学,2006,33(10):126 -127.
[3]庄重.Web信息抽取的研究[D].武汉:湖北工业大学,2009.
[4]邹涛,黄源,张福炎.基于WWW的文本信息挖掘[J].情报学报,1999,18(4):291 -295.
