基于神经网络的改进行为协调控制及其在智能轮椅路径规划中的应用
2011-08-18蒲兴成张军张毅
蒲兴成,张军,张毅
(1.重庆邮电大学数理学院,重庆 400065;2.重庆邮电大学自动化学院,重庆 400065)
基于神经网络的改进行为协调控制及其在智能轮椅路径规划中的应用
蒲兴成1,张军2,张毅2
(1.重庆邮电大学数理学院,重庆 400065;2.重庆邮电大学自动化学院,重庆 400065)
针对传统的基于行为的智能轮椅的路径规划方法在室外非结构环境下的路径规划效果差的问题,提出一种新的智能轮椅的路径规划算法.该算法利用模糊逻辑设计了基本控制行为,并在此基础上结合大量实际经验使用神经网络设计了行为协调控制器.改进的算法将仲裁机制和命令融合机制2种行为协调方法有效结合起来,并吸收了这2种行为协调方法的优点,从而改善了系统的反应速度,极大提高了控制精确;另一方面,该算法还可以识别陷阱区域并通过自主改变行为的权重方法控制轮椅逃出陷阱区域,因而具备了较强的人工智能特征.仿真和实物实验验证了该算法智能性高且实现简单,适用于室外非结构化环境下的机器人路径规划.
机器人;智能轮椅;非结构化环境;路径规划;神经网络;行为协调控制器
路径规划是移动机器人领域的核心技术之一[1],其目的是在有障碍物的工作空间中,寻找一条从起始点到目标点的最优或者近似最优路径,该路径是无碰的且一般为最短的.针对移动机器人的路径规划问题,国内外许多学者进行了大量的研究,获得了很多有效的控制方法.全局路径规划技术[2-4]已经相对比较成熟,可以在环境信息已知的情形下获得全局最优路径,现在比较活跃的领域是研究在未知环境中的局部路径规划[5].比较成熟的局部规划算法有人工势场法[6]、滚动窗口法[7]、神经网络方法[8]、粒子群算法[9]、遗传算法[10]等,以上算法都存在各自的优点和不足;但是其共同的缺点是以上各算法都是基于认知模型的功能规划法,这种基于感知—建模—规划—动作的方法缺乏实际运行所需的灵活性和实时性[11].
近年来兴起的基于行为的规划方法完成了从感知到动作的直接映射,机器人要完成的任务由几个单独封装的行为配合完成,机器人对外部环境反应迅速、实时性好.自从 Brooks[11]提出 SA(simulated annealing)模型以来,SA模型得到了广泛的应用,其主要优点是实现简单、反映灵敏,缺点是多个行为之间的反复切换导致路线不够平滑且在机器人运动中控制不够精确.命令融合机制[13-17]的引入解决了这一问题,通过每一时刻多个行为相互配合得到最终输出,常用模糊逻辑作为工具进行命令融合的设计,但是其缺点是设计复杂,有时控制器规则较多或者要求控制精确时,甚至导致控制失去实时性.为解决这一缺陷,笔者提出一种改进的行为协调机制,该机制利用BP网络设计一个行为协调控制器,控制器将基于优先级的方法和模糊命令融合的方法相结合,系统同时具备了二者的主要优势,具有较好的实时性,同时可以实现精确控制.当机器人进入陷阱区域时,控制器可以识别陷阱区域并灵活地改变原有各个行为的控制权重,控制轮椅尽快逃离陷阱区域,进一步提高了系统的智能性.
1 行为设计
智能轮椅在室外环境下完成自主导航,需要3个基本行为:目标趋向行为、避障行为、沿墙走行为.考虑到模糊逻辑控制器设计的简便性和控制的有效性,采用模糊逻辑对3种行为分别进行设计.本设计所涉及的智能轮椅的绝对坐标系和体坐标系如图1所示.

图1 智能轮椅的绝对坐标系和体坐标系Fig.1 Absolute and body coordinate systems of the intelligent wheelchair
图1中X、Y轴组成绝对坐标系,在实际应用中,该坐标系即为地球的经纬度坐标系,以X表示纬度,Y表示经度.x、y轴组成智能轮椅的体坐标系,其中x表示智能轮椅当前的运动方向.di表示智能轮椅的各个超声传感器探测的障碍物的距离信息,d表示智能轮椅与目标点之间的距离,φ表示轮椅当前运动方向偏离目标点的角度大小.
1.1 目标趋向行为
目标趋向行为不考虑外界环境中障碍物的信息,只控制轮椅由任意位置向目标点靠近.趋向行为的模糊控制器的输入有2个:轮椅和目标点之间的距离d,轮椅当前运动方向和轮椅当前位置及目标点之间连线的夹角φ,输出为轮椅运动速度VG和转动速度WG.各语言变量的隶属度函数如图2所示.

图2 趋向行为模糊控制器各输入输出变量的隶属度函数Fig.2 Membership function graphs of input and output invariables of the fuzzy controller with trend behavioral
模糊规则如下:

1.2 避障行为
避障行为通过传感器检测轮椅前方是否存在障碍物,如果有则通过合理的动作避过障碍物使得轮椅安全行进.避障行为的模糊控制器输入为:左侧传感器的读数dL、右侧传感器的读数dR、前方传感器的读数dF,输出为行进速度VO和转动速度WO.各语言变量的隶属度函数如图3所示.
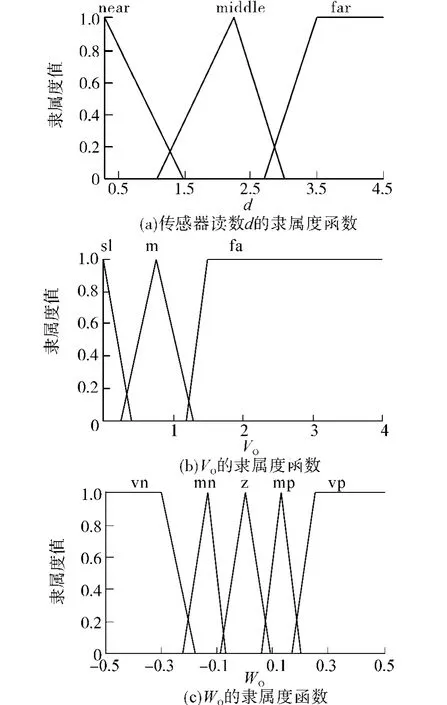
图3 避障行为各语言变量的隶属度函数Fig.3 Membership function graphs among language invariables of avoiding behavioral
模糊规则如下:
1.3 沿墙走行为
沿墙走行为可以使轮椅完成对障碍物边沿的实时跟踪.控制器的输入是左右传感器的读数dL、dR,输出为轮椅的行进速度VF和转动速度WF,各语言变量的隶属度函数与避障行为相同,模糊规则如下所示:

2 行为协调控制器的设计
行为协调机制的实现方法通常分为基于仲裁和基于命令融合2类.基于仲裁的行为协调机制在一个时刻内只允许一个行为实施控制,而命令融合则允许将多个行为的结果综合成一个命令,每一个行为都对最终的控制产生贡献.仲裁机制实现简单、反应迅速,但是由于在多个动作之间切换,机器人动作不够平滑,而且由于每一时刻只有一个行为有控制权,当某一行为被执行时会牺牲其他行为,该控制方法智能性较低,当环境复杂时很容易导致路径规划失败.命令融合机制可以克服以上缺点,这种方法动作输出更平滑,控制更精确,智能性较高,但是命令融合反应速度更慢,有时甚至失去实时性.考虑到以上因素,将二者有效结合可以获得更好的控制效果.笔者设计的改进的行为协调控制器如图4所示.

图4 改进的行为协调控制器Fig.4 Improved behavioral coordinated controller
BP神经网络的输入输出变量如图5所示.距离传感器的信息和标志变量I作为神经网络的输入,各个行为的权重作为神经网络的输出,该输出可以和各个行为的输出相结合从而得到整体的输出,如式(1)所示.

图5 神经网络的输入输出Fig.5 Input and output of neural network
另一方面,神经网络的输出可以作为控制信号控制某个行为是否能够被激活,当某个行为的权值小于预设的阈值K时,该行为将不被激活.例如表1中,若K=0.01,则第1行所示外界环境下仅趋向行为被激活,第2行所示外界环境下所有行为均被激活,利用式(1)得到整体输出.

表1 权值控制行为Table 1 Weight control behavior
该方法将仲裁机制和命令融合机制有效结合起来,训练后的神经网络根据外部环境的情形可以选择全部或者部分行为的激活.例如:周围没有障碍物时能够单独执行趋向行为,忽略避障和沿墙走行为,可以节省不必要的系统开销,系统具有较快的反应速度;如果附近有障碍物则可以综合所有行为的结果得到整体的输出,提高系统控制精度.
为进一步提高系统的智能性,行为协调控制器引入标志变量I用以监测轮椅是否进入陷阱区域,并执行相应的操作.系统控制流程图如图6所示.
图6中,dt为t时刻轮椅与目标点的距离,该距离可以通过GPS计算.dt+1为t的下一个采样时刻轮椅与目标点的距离.当dt+1>dt时表示轮椅向着背离目标点的方向运动,反映出轮椅进入了陷阱区域,此时将I赋值为y.当I=y时,行为协调控制器监测到轮椅进入陷阱区域,神经网络的输出为output_trap,此输出针对陷阱区域所设计,具备以下2个特点.
1)可以忽略周围障碍物信息而单纯执行趋向行为,如表2所示.表2中,当I=y时,避障和沿墙走行为不被激活,而相同的环境下I=x时,所有的行为均被激活.
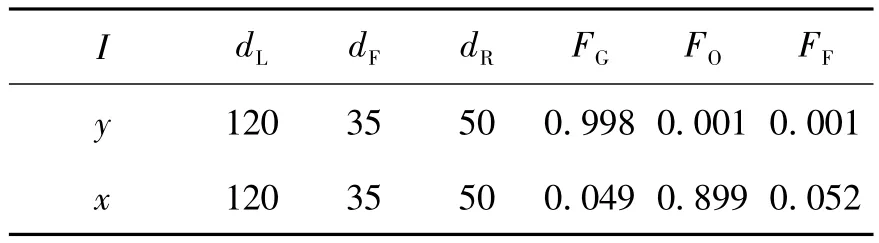
表2 I取不同值时神经网络的输出Table 2 Neural network output in different I
该特性相当于改变了行为的优先级或者控制权重,在存在障碍物的环境条件下趋向行为也将有机会被单独执行.陷阱区域的障碍物信息导致控制器输出的控制决策失去了路径规划的目的性,因此忽略障碍物的信息而执行趋向行为可以提前终止不合理的控制决策,控制轮椅能尽快逃出陷阱区域.
2)output_trap=[0,WG],将趋向行为的线速度设置为0,轮椅可以原地完成方向的调整,从而保证了轮椅的安全.
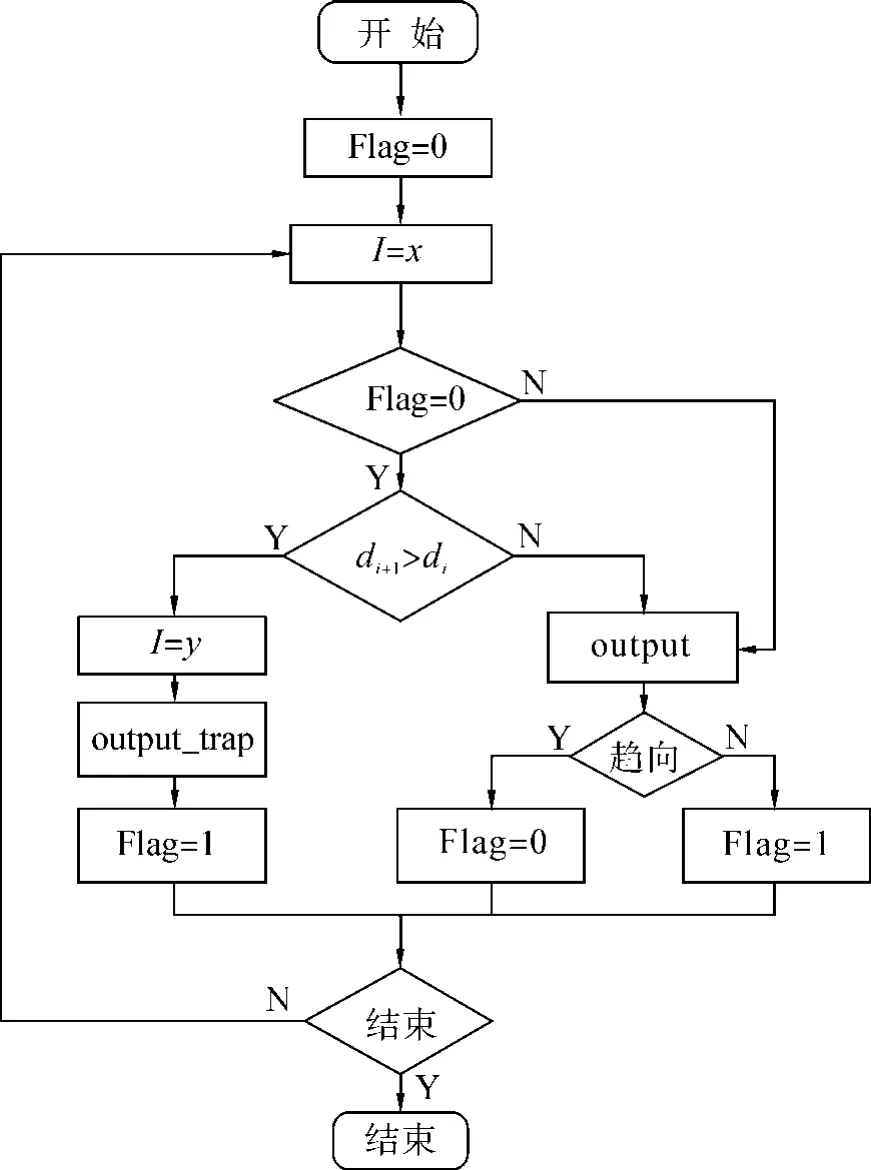
图6 系统控制流程Fig.6 Flowchart of system control
图6中,Flag用以控制识别陷阱区域功能的开启和关闭,Flag=0时开启该功能,此时将对dt进行监测.当控制器输出output_trap后,Flag被置为1关闭该功能,直至下一次执行趋向行为后Flag重新被置为0,该功能再次启动.关闭陷阱识别功能的目的是防止轮椅一直在陷阱区域反复不前.
3 仿真及实物实验
为了验证算法的有效性,本节对上述提及的各种算法进行了仿真实验,并导航时间、路径轨迹、对于陷阱区域的处理能力进行了比较.
3.1 导航时间比较
轮椅的工作环境如图7所示,图中方块表示障碍物,五角星表示目标点,为了更真实地展示3种行为协调机制的导航效果,笔者设置了3个初始位置,如图中圆圈所示.

图7 轮椅工作环境Fig.7 Working conditions of the wheelchair
轮椅分别从3个初始位置出发,记录轮椅到达目标点的时间,每个位置分别进行20次实验最后统计取平均时间,结果如表3所示.

表3 各种行为协调方法比较结果Table 3 Comparison of results of different behavior coordination method
由表3可知,基于优先级的方法导航效果最差,主要原因是该方法某一时刻只有一个行为起作用,缺乏导航的目的性.而模糊命令融合方法每一时刻所有的行为都对最终的整体行为有贡献,因此轮椅的动作有更强的目的性.相对于传统的模糊命令融合方法而言,改进的行为协调方法在趋向行为执行时能抑制沿墙走行为和避障行为的激活,系统的反映更快,由此可见,改进的行为协调方法比传统的模糊命令融合方法所需的导航时间更短.
3.2 导航轨迹比较
基于优先级的行为协调机制控制下,轮椅的运动轨迹如图8所示.由图8可以清晰看到轮椅的运动轨迹非常不平滑,存在大量尖角,这是由于不同的行为之间相互切换造成的.当轮椅由趋向行为突然改为避障行为时,将会出现突然的转向,其他的行为切换时同样如此.实际应用中,轮椅的不平滑的运动轨迹不但容易造成轮椅硬件的损坏,而且使得轮椅的使用舒适度严重降低.

图8 基于优先级的行为协调机制轮椅的轨迹Fig.8 Trace of behavioral coordinated wheelchair based on priority
在传统的模糊命令融合机制和改进的行为协调机制控制下,轮椅的运动如图9所示.

图9 模糊命令融合机制和改进的行为协调机制控制轮椅的运动轨迹Fig.9 Trajectory of control wheelchair of convergence mechanisms of fuzzy order and improved behavioral coordinated controller
图9中,传统的模糊命令融合方法控制轮椅由初始位置1和初始位置3出发,2条轨迹都非常平滑.原因是二者没有行为之间的切换,每个转向动作都是所有行为综合作用的结果.改进的行为协调机制控制轮椅由初始位置2出发,2号轨迹在A、B两点处出现尖角,原因是改进的行为协调机制在以上两点处会切换到单纯的趋向行为,避障和沿墙走这2个行为没有机会被执行,这类似于基于优先级的控制方法.考虑到该方法能够在执行趋向行为时降低系统的负担及提高系统的反应速度,且仅在切换到趋向行为时才出现尖角而其他情形下轨迹非常平滑,因此认为这是可以接受的代价.
3.3 处理陷阱区域能力比较
接下来的试验中,轮椅的工作环境为图10的陷阱区域,陷阱区域在实际应用中可能会严重降低轮椅的导航质量.基于优先级的控制下,轮椅的运动轨迹如图10所示.

图10 基于优先级的控制下轮椅的轨迹Fig.10 Trace of wheelchair based on priority control
由图10所示,轮椅进入了陷阱区域后,会出现严重的导航错误,原因是基于优先级的控制下,沿墙走行为的优先级要高于趋向行为的优先级,因此直到沿墙走行为终止之前,趋向行为没有机会被执行.相同的环境下,改进的行为协调机制控制轮椅的运动轨迹如图11所示.

图11 改进的行为协调机制控制轮椅运动轨迹Fig.11 Trace of wheelchair based on improved behavioral coordinated control
由图11可见,轮椅进入陷阱区域后,改进的行为协调机制可以识别轮椅进入了陷阱区域并将趋向行为的权重设置为最大,轮椅原地调整了运动方向,由于周围环境安全轮椅接下来执行了趋向行为,因此轮椅可以很快到达目标点,可见笔者设计的改进行为协调机制控制更加合理,进一步提高了控制系统的智能性.
换一种新的陷阱区域作为实验场景,轮椅在传统的模糊命令融合的控制下运动轨迹如图12所示.同样的环境下在改进的行为协调机制控制下轮椅的运动轨迹如图13所示.图13中,改进的行为协调机制识别出轮椅进入陷阱区域后将趋向行为的控制权设为最大,在原地完成了运动方向的调整,然后关闭了识别陷阱区域功能.由于外界环境存在障碍物,改进的行为协调机制激活了所有行为控制轮椅原路返回并最终从另一个方向走出了陷阱区域并到达了目的地.

图12 传统的模糊命令融合机制控制轮椅运动轨迹Fig.12 Trace of wheelchair of under traditional fuzzy order convergence mechanisms
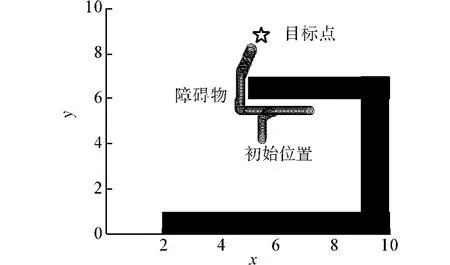
图13 改进的行为协调机制控制下轮椅的运动轨迹Fig.13 Trace of wheelchair based on improved behavioral coordinated control
3.4 实物实验结果
本节为部分实际实验效果展示,在实际实验中轮椅的初始位置和目标点之间存在多个障碍物.改进的行为协调机制可以控制轮椅安全通过障碍物区域趋向目标点,如图14所示.

图14 轮椅安全通过障碍物区域Fig.14 Wheelchair passed obstacles region safely
在改进的行为协调机制控制下轮椅的运动轨迹非常平滑,证明了改进的行为协调机制能够完成精确控制,如图15中线条所示.
图16展示了改进行为协调机制良好的处理陷阱区域的能力,轮椅能够提前结束沿墙走行为而执行趋向行为,因此可以更快地到达目标点.

图15 运动轨迹特写Fig.15 Highlight of wheelchair trace

图16 轮椅逃离陷阱区域Fig.16 Wheel escaped from the trap domain
在室外环境下进行实际的路径规划,轮椅在改进的行为协调机制控制下的运动路线如图17所示,可见该行为协调机制能够安全快速地将使用者送达目的地.

图17 室外环境中轮椅运动路线Fig.17 Trace of wheelchair escaped outside the door
4 结束语
笔者提出的行为协调机制将仲裁机制和命令融合机制2种传统的行为协调机制相结合,该控制系统反应速度快且控制精确.同时改进的行为协调机制能够识别陷阱区域的存在且通过自主改变行为控制权重的方式控制轮椅尽快逃出陷阱区域,进一步提高了控制系统的智能性.该控制器实现简单且智能性好,适用于非结构化环境下的路径规划.
[1]LATOMBE J C.Robot motion planning[M].Boston,USA:Kluwer Academic Publishers,1991:143-176.
[2]刘一松,魏宁,孙亚民.基于栅格法的虚拟人快速路径规划[J].计算机工程与设计,2008,29(5):1229-1231.
LIU Yisong,WEI Ning,SUN Yamin.Path planning algorithm based on grid method for virtual human[J].Computer Engineering and Design,2008,29(5):1229-1231.
[3]杨淮清,肖兴贵,姚栋.一种基于可视图法的机器人全局路径规划算法[J].沈阳工业大学学报,2009,31(2):225-229.
YANG Huaiqing,XIAO Xinggui,YAO Dong.A V-graph based global path planning algorithm for mobile robot[J].Journal of Shenyang University of Technology,2009,31(2):225-229.
[4]陈家照,张中位,徐福后.改进的概率路径图法[J].计算机工程与应用,2009,45(10):54-55.
CHEN Jiazhao,ZHANG Zhongwei,XU Fuhou.Modified probabilistic roadmap method[J].Computer Engineering and Applications,2009,45(10):54-55.
[5]鲍庆勇,李舜酩,沈峘,等.自主移动机器人局部路径规划综述[J].传感器与微系统,2009,28(9):1-4.
BAO Qingyong,LI Shunming,SHEN Huan,et al.Survey of local path planning of autonomous mobile robot[J].Transducer and Microsystem Technologies,2009,28(9):1-4.
[6]朱毅,张涛,宋靖雁.非完整移动机器人的人工势场法路径规划[J].控制理论与应用,2010,27(2):152-158.
ZHU Yi,ZHANG Tao,SONG Jingyan.Path planning for nonholonomic mobile robots using artificial potential field method[J].Control Theory & Application,2010,27(2):152-158.
[7]傅卫平,张鹏飞,杨世强.利用机器人行为动力学与滚动窗口路径规划[J].计算机工程与应用,2009,45(2):212-215.
FU Weiping,ZHANG Pengfei,YANG Shiqiang.Behavioral dynamics of mobile robot and rolling windows algorithm to path planning[J].Computer Engineering and Applications,2009,45(2):212-215.
[8]宋勇,李贻斌,李彩虹.递归神经网络的进化机器人路径规划方法[J].哈尔滨工程大学学报,2009,30(8):898-902.
SONG Yong,LI Yibin,LI Caihong.Path planning based on a recurrent neural network for an evolutionary robot[J].Journal of Haribn Engineering University,2009,30(8):898-902.
[9]赵先章,常红星,曾隽芳,等.一种基于粒子群算法的移动机器人路径规划方法[J].计算机应用研究,2007,24(3):181-186.
ZHAO Xianzhang,CHANG Hongxing,ZENG Junfang,et al.Path planning method for mobile robot based on particle swarm algorithm[J].Application Research of Computers,2007,24(3):181-186.
[10]郝博,秦丽娟,姜明洋.基于改进遗传算法的移动机器人路径规划方法研究[J].计算机工程与科学,2010,32(7):104-107.
HAO Bo,QIN Lijuan,JIANG Mingyang.Research on the path planning methods for mobile robots based on an improved genetic algorithm[J].Computer Engineering & Science,2010,32(7):104-107.
[11]郝冬,刘斌.基于模糊逻辑行为融合路径规划方法[J].计算机工程与设计,2009,30(3):660-663.
HAO Dong,LIU Bin.Behavior fusion path planning method for mobile robot based on fuzzy logic[J].Computer Engineering and Design,2009,30(3):660-663.
[12]BROOKS R.A robust layered control system for a mobile robot[J].IEEE Journal of Robotics and Automation,1986,2(1):14-23.
[13]ARKIN R C.Motor schema based navigation for a mobile robot:an approach to programming by behavior[C]//Proceedings of the IEEE International Conference on Robotics and Automation.Raleigh,USA,1987:264-271.
[14]ARKIN R C.Behavior-based robotics[M].Cambridge,USA:the MIT Press,1998.
[15]PIRJANIAN P.Behavior coordination mechanisms:stateof-the-art,Technical Report IRIS-99-375[R].Los Angeles,USA:Institute for Robotics and Intelligent Systems,University of Southern California,1999.
[16]ABREU A.Fuzzy behaviors and behavior arbitration in autonomous vehicles[C]//Proceedings of the 9th Portuguese Conference on Artificial Intelligence:Progress in Artificial Intelligence.London,UK:Springer-Verlag,1999:237-251.
[17]PEREZ M C.A proposal of behavior based control architecture with reinforcement learning for an autonomous underwater robot[D].Girona,Spain:University of Girona,2003.

蒲兴成,男,1973年生,副教授,博士,主要研究方向为非线性系统、随机系统和智能控制等.主持和参与省部级基金项目8项,发表学术论文40余篇,出版学术专著1部、教材1部.

张军,男,1985年生,硕士研究生,主要研究方向为人工智能和机器人控制.

张毅,男,1966年生,教授,博士生导师,中国人工智能学会理事、青年工作委员会副主任、智能机器人专业委员会委员,中国计量测试学会高级会员,《机器人技术及其应用》杂志理事.主要研究方向为智能服务机器人、信息无障碍技术、智能人机交互技术.申请国家发明专利20项,获得国家发明专利10项,发表学术论文150余篇,其中被SCI、EI、ISTP检索80余篇,出版专著2部,撰写教材3部.
Modified behavior coordination for intelligent wheelchair path planning based on a neural network
PU Xingcheng1,ZHANG Jun2,ZHANG Yi2
(1.Mathematics and Physics College,Chongqing University of Posts and Telecommunications,Chongqing 400065,China;2.Automation College,Chongqing University of Posts and Telecommunications,Chongqing 400065,China)
In order to solve the poor effects of traditional behavior-based path planning of intelligent wheelchairs in an outdoor unstructured environment,a new path planning method was proposed in this paper.The new algorithm uses fuzzy logic to design basic control behavior,and on this basis applies a neural network to design behavior coordination by combining a large amount of practical experience.The improved algorithm can combine arbitration mechanisms with fusion mechanisms successfully;it absorbs the major advantage of these two original algorithms and improves response speed of the system while enhancing the control accuracy significantly.On the other hand,the method can identify trap area and control the wheelchair escape from the trap by changing the behavior weights independently,therefore displaying strong artificial intelligence characteristics.The simulation and real experimental results verify that the algorithm is capable of advanced intelligence and can be implemented easily.Additionally,it can be used in an outdoor unstructured environment for robot path planning.
robot;intelligent wheelchair;unstructured environment;path planning;neural network;behavior coordination control
TP24
A
1673-4785(2011)05-0456-08
10.3969/j.issn.1673-4785.2011.05.011
2011-01-16.
科技部国际合作资助项目(2010DFA12160);重庆市科委资助项目(CSCT,2010AA2055);重庆邮电大学青年基金资助项目(A2009-50).
蒲兴成.E-mail:puxingcheng@sina.com.
