模糊c-均值算法和万有引力算法求解模糊聚类问题
2011-08-18谷文祥郭丽萍殷明浩
谷文祥,郭丽萍,殷明浩
(东北师范大学计算机科学与信息技术学院,吉林长春 130117)
模糊c-均值算法和万有引力算法求解模糊聚类问题
谷文祥,郭丽萍,殷明浩
(东北师范大学计算机科学与信息技术学院,吉林长春 130117)
针对单纯使用模糊c-均值算法(FCM)求解模糊聚类问题的不足,首先,提出一种改进的万有引力搜索算法,通过一定概率按照不同方式对速度进行更新,有效增大了种群的搜索域.其次,提出了模糊万有引力搜索算法(FGSA).最后,在模糊万有引力搜索算法(FGSA)和模糊c-均值算法(FCM)的基础上,提出了一种新算法(FGSAFCM)来求解模糊聚类问题,有效避免了单纯使用模糊c-均值算法时对初始值敏感且易于陷入局部最优的缺点.采用目标函数和有效性评价函数作为评价标准,选取10个经典数据集作为测试数据,实验结果表明,新算法比单一的模糊c-均值算法有更高的准确性和鲁棒性.
模糊聚类;模糊c-均值算法;万有引力搜索算法;模糊万有引力搜索算法
聚类分析是中非监督模式识别的一个重要分支.它试图将数据分成几个不同的组,要求组内的数据相似性大,组间的数据相似性小,这样的组在聚类中被称为“簇”.目前,求解聚类问题主要包括硬聚类、模糊聚类、可能性聚类3种方法.硬聚类方法[1]在分类时具有绝对性,即“非此即彼”,这种方式虽然时间消耗非常少,但是也割断了数据之间的联系.模糊聚类方法[2]把Zadeh的模糊理论引入到聚类中,使每个样本对各个类别的隶属度扩展到[0,1]区间,这种方法在处理各类别之间含有交集的聚类问题时,效果明显优于硬聚类方法.可能性聚类[3]方法在模糊聚类方法的基础上,不再限定样本对每个类别的隶属度之和为1.
模糊 c-均 值 算 法 (fuzzy c-means algorithm,FCM)[2]是求解模糊聚类问题最经典的算法之一.然而,模糊c-均值算法对初始值非常敏感,而且很容易陷入局部最优.万有引力算法(gravitational search algorithm,GSA)[4]是由 Rashedi和 Nezamabadi-pour在2009年提出来的一种模拟物理学中的万有引力进行优化的新算法.它通过群体中各微粒之间的万有引力来指导整个种群的搜索.实验证明,万有引力搜索具有较强的全局搜索能力.本文首先利用万有引力算法找到较好的初始解,然后用模糊c-均值算法进行深入搜索,最终找到较优的解.
1 模糊c-均值算法
模糊 c-均值算法[2,5-6]是由 J.C.Bezdek 等人于1973年提出的,该算法试图把n个数据O={o1,o2,…,oi,…,on}分成k(1 <k<n)类,利用隶属度矩阵μ表示样本数据属于各个类别的程度,元素μij表示第i个样本数据属于第j类的程度,矩阵μ应该满足如下约束条件:

FCM算法的目标函数为
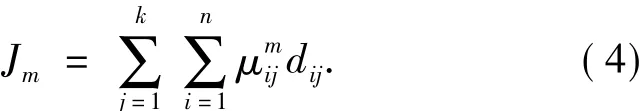
式中:m(m>1)是一个调节聚类结果的模糊程度的参数,m越大,聚类的结果就越模糊.FCM算法可以描述如下:
1)选定m,初始化迭代次数t及隶属度矩阵元素 μij,i=1,2,…,n;j=1,2,…,k.
2)按照式(5)计算聚类中心:

3)计算每个样本数据到各个簇的欧氏距离:

4)对于任意的i和l,如果dil>0,则按照式(6)更新隶属度.
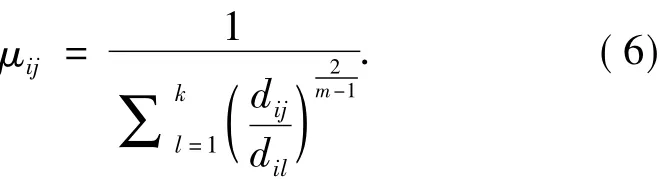
否则,如果存在dil=0,则μil=1,且对于任意的j≠l,μij=0.
5)如果算法仍未收敛,转2).
这里,评价算法的收敛条件包括2个,一个是达到算法设定的最大迭代次数,另一个是目标函数(4)的值在指定迭代次数内无法再变小.
2 万有引力搜索算法
2.1 标准的万有引力搜索算法
万有引力搜索算法[4,13](gravitational search algorithm,GSA)是2009年由Rashedi等提出的,该算法模拟物理学中的万有引力定律“宇宙中任意2个质点之间存在吸引力,该引力的大小与它们质量的乘积成正比,与它们之间的距离成反比”,通过个体间的万有引力作用引导搜索.在该算法中,每个个体包含4个属性:位置、惯性质量、主动引力质量和被动引力质量,个体的位置就是问题的解.由N个个体组成的种群 X={X1,X2,…,Xi,…,Xn},其中,

式中:表示第i个个体在第d维空间的位置.在第t次迭代过程中,个体j作用于个体i的力定义为

式中:G(t)是时间t下的万有引力常量,Maj(t)是个体j的主动引力质量,Mpi(t)是个体i的被动引力质量.ε是一个非常小的常量,Rij(t)表示个体i和个体j之间的欧氏距离,
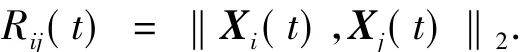
个体i在第d维空间上受到其他个体的合力表示为

式中:randj是一个[0,1]区间内的随机数,增加了算法的随机性.
个体i在第d维空间上的加速度按照式(7)计算得出:

式中:Mii(t)表示个体i的惯性质量.个体i的位置按照式(8)进行更新:

式中:(t)是个体i在第d维空间上的速度,(t)是个体i在第d维空间上的位置,randi是一个[0,1]区间内的实数,可以增强算法的随机搜索能力.
G0是万有引力常量G的初始值,随着迭代次数的增加,G会逐渐减小来控制搜索的精确性.G是关于G0和t的一个函数:
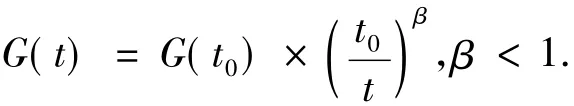
引力质量和惯性质量通过适应度函数计算得出,假设引力质量和惯性质量相同,通过如式(9)更新个体的引力质量和惯性质量:
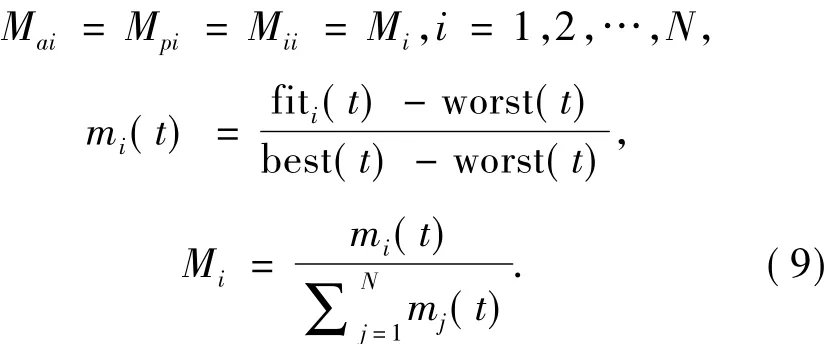
式中:fiti(t)表示个体i在时间t的适应度值,best(t)和worst(t)定义如式(10):

2.2 改进的万有引力搜索算法
为了增强算法的全局搜索能力,本文提出了一种新的速度更新方式:首先,随机生成一个[0,1]区间的实数r,如果r<0.5,就按照式(8)对速度进行更新,否则,按照式(11)更新速度:
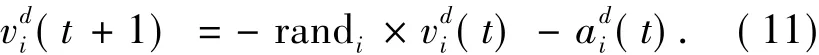
实验结果表明,这种方式能够有效地扩大了算法的搜索域,对于避免算法陷入局部最优值有一定效果.
2.3 模糊万有引力搜索算法
Pang等[7]在2004年提出了一种修改的粒子群算法(particle swarm optimization,PSO)用于求解旅行商问题(traveling salesman problem,TSP),它采用粒子的位置和速度表示变量之间的模糊关系.本文把这种方法用在万有引力搜索算法中来求解模糊聚类问题,提出了模糊万有引力搜索算法(fuzzy gravitational search algorithm,FGSA).
在FGSA中,用粒子的位置矩阵X表示样本和簇之间的隶属程度.X的形式化表示如式(12):

式中:μij表示个体i属于簇j的程度,它必须满足式(1)~(3)的约束条件.这样,就把粒子的位置和隶属度矩阵对应起来,每个粒子的位置和速度均由一个n行c列的矩阵来表示,并按照如下方式进行更新:随机生成一个[0,1]区间内的实数r,若r<0.5,则

式中:⊕、Θ和⊗分别表示矩阵加法、减法和乘法运算.更新结束之后,可能会有些元素违背式(2)、(3)中的约束,则需要对其进行标准化,标准化过程如下:
1)如果矩阵中的元素为负,就把该元素赋为0;
2)如果矩阵中的某一行元素全为0,则用[0,1]区间内的随机实数重新对其进行赋值;
3)如果矩阵中的所有元素都不违背约束,则按如式(16)进行转换:
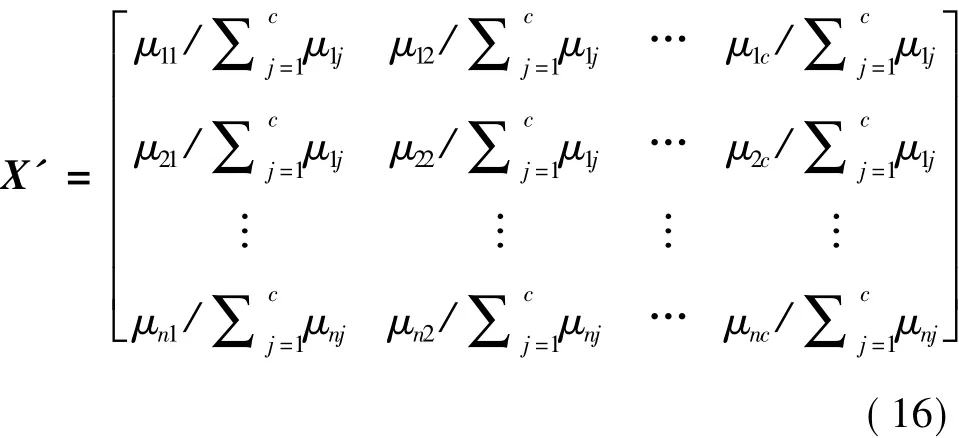
在FGSA算法中,采用式(4)作为适应度函数,适应度函数的值越小,解的质量也越高.FGSA算法求解模糊聚类问题的流程如下:
1)初始化最大迭代次数maxt及其他参数;
2)生成初始种群,初始化种群中每个个体的位置和速度;
3)按照式(5)计算聚类中心;
4)按照式(4)计算适应度函数值;
5)更新G;
6)为每个个体更新惯性质量;
7)计算每个个体受到的合力F及加速度a;
8)按照式(13)~(15)更新每个个体的位置和速度;
9)重复3)~8),直到满足算法的停止条件.
3 混合新算法求解模糊聚类问题
和FGSA算法相比,FCM算法由于需要的参数少,所以它的收敛速度比FGSA快,但是它也很容易陷入局部最优值;FGSA算法由于出色的全局搜索能力,往往能找到较好的解.因此,在FCM算法和FGSA算法的基础上,设计了一种新的算法——FG-SAFCM算法.在FGSAFCM算法中,算法初期采用FGSA算法寻找较好的初始解,然后利用FCM算法进行深入搜索.该算法继承了FGSA和FCM算法的优点,有效避免了对初始值敏感和易于陷入局部最优的缺点.
在FGSAFCM算法中,每个个体的位置由一个n行c列的矩阵表示,第i行第j列的元素表示样本i属于簇j的程度,在存储时,把每个个体的位置转换成一个行向量表示.结构图如图1.

图1 FGSAFCM算法中的个体结构图Fig.1 The presentation of an object in FGSAFCM
FGSAFCM算法求解模糊聚类问题的流程如下:
1)初始化最大迭代次数maxt及其他参数;
2)生成初始种群,初始化每个个体的位置和速度;
3)设置迭代次数:Gen1=Gen2=Gen3=0;
4)FGSA算法).
①利用FGSA算法更新种群的每个个体;
②Gen2=Gen2+1;如果 Gen2<8,转4);
5)对每个个体i:
①个体i的位置对应于样本和簇之间的隶属度;
②用FCM算法更新聚类中心;
③Gen3=Gen3+1;如果 Gen3<4,转5);
6)Gen1=Gen1+1;如果 Gen1< maxt,转4).
4 仿真实验
实验环境为:Pentium 2.0 GHz处理器,1.00 GB内存,采用Visual Studio 2008编码.
4.1 数据集
实验数据包括 ArtSet1、ArtSet2、Fisher’s Iris 、Breast-Cancer-Wisconsin(Cancer)、Glass、Wine、Contraceptive Method Choice(CMC) 、Vowel[8]、Teaching AssistantEvaluation (TAE)、Vertebral Column(VC)[14]10个数据集.这些数据集涵盖了低维、中维、高维的不同数据,具有一定的代表性.
ArtSet1和ArtSet2是2个人造数据集;Iris包括3类鸢尾花,每类包含萼片长、萼片宽、花瓣长和花瓣宽4个特征;Cancer通过细胞大小、细胞形状、核染色质等9个特征,将癌症分为恶性和良性2类;Glass通过折射率、钠、镁、铝等9个特征把玻璃分为6类;Wine分为3类,包括酒精、苹果酸、花青素、色度等13个特征;CMC源于1987年印尼的避孕调查,根据社会统计学特征将被调查者分为未避孕、长期避孕和短期避孕3类;Vowel包括6种不同类型的印度泰卢固语元音发音,每种包含3个特征;VC是Henrique在一次医学研究中整理出来的,他根据6个生物学特征将脊柱数据分为正常、椎间盘突出、脊椎前移3类;TAE是威斯康星大学麦迪逊分校整理的关于151个助教的授课评估情况,根据5个评价指标将结果分为低、中、高3类.数据集的详细描述见表1.

表1 数据集描述Table 1 The description of datasets
4.2 实验结果
实验参数设置:FCM算法中,m的值设置为2,最大迭代次数maxt为100;FGSAFCM算法中,种群数目设置为20,万有引力常量初值G0为100,最大迭代次数为20.实验结果为10次独立实验的平均值.为了更全面地测试新算法的性能,引入了有效性评价函数(PC)Partition Coefficien[9].
该函数的形式化描述为
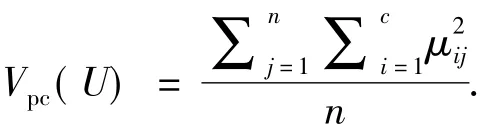
PC的值越大,分类的有效性就越大.表2和表3分别是FCM算法和FGSAFCM算法的目标函数值、有效性评价函数值的实验结果对比.从表2和表3可以看出,无论是目标函数值,还是有效性函数值,FGSAFCM算法都要优于FCM算法,并且随着数据集维数的增加,这种优越性更加明显,充分体现了新算法的有效性和鲁棒性.

表2 FCM、FGSAFCM算法的目标函数值对比Table 2 The comparison of objective function for FCM,FGSAFCM
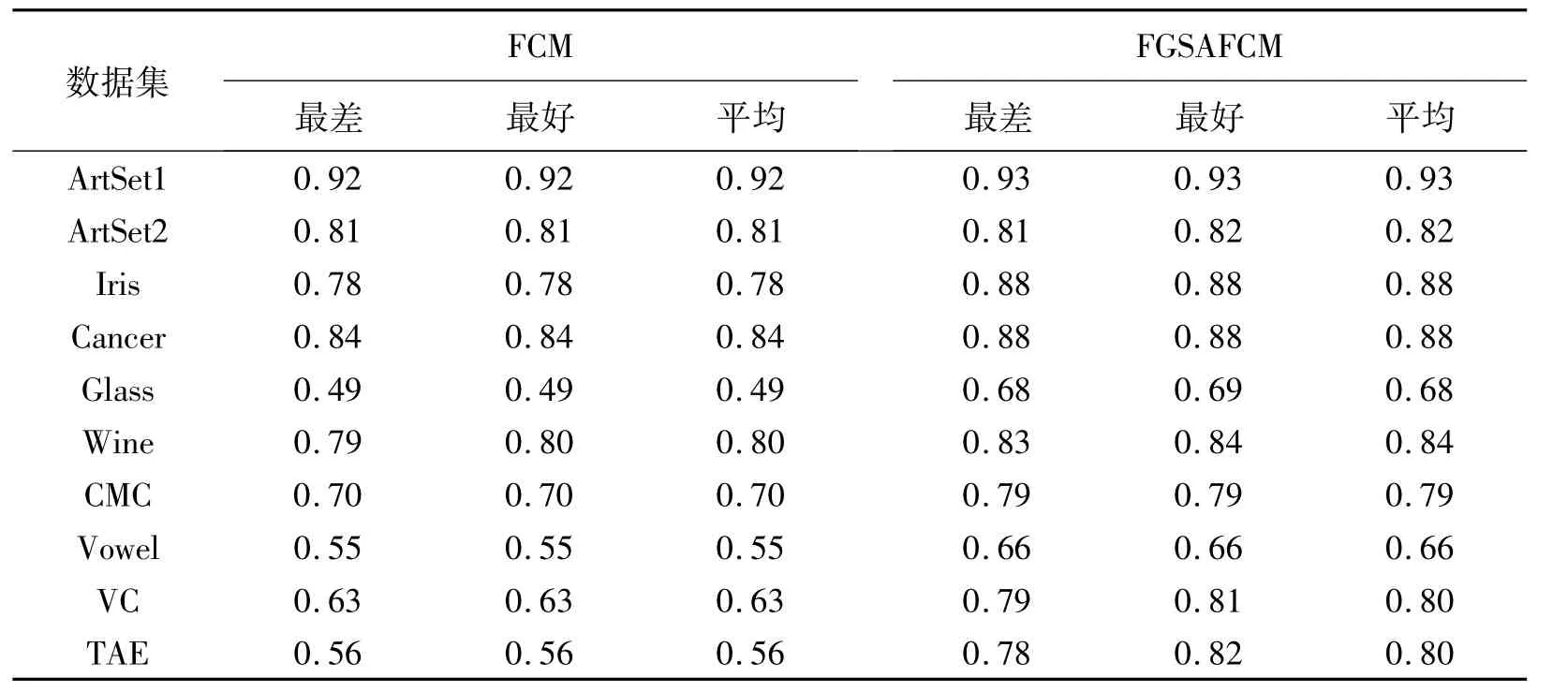
表3 FCM、FGSAFCM算法的有效性函数PC对比Table 3 The comparison of validity function for FCM,FGSAFCM
5 结束语
提出了一种改进的万有引力搜索算法,并在此基础上,提出了模糊的万有引力搜索算法;通过结合模糊的万有引力搜索算法和模糊c-均值算法,提出了一种新的求解模糊聚类问题的方法——FGSAFCM算法,实验结果表明,新算法的目标函数值和有效性评价函数值都要优于模糊c-均值算法,并且随着数据集维数的增加,优越性更加明显,体现了新算法的有效性.
未来主要工作包括把该算法应用到其他聚类问题中,以及寻找更优的算法求解模糊聚类问题.
[1]DUBES R C,JAIN A K.Algorithms for clustering data[M].Englewood Cliffs,USA:Prentice Hall,1988:1-20.
[2]BEZDEK J C.Pattern recognition with fuzzy objective function algorithms[M].New York,USA:Plenum Press,1981:43-93.
[3]KRISHNAPURAM R,KELL J M.The possibilistic c-means algorithm:insights and recommendation[J].IEEE Trans FS,1996,4(3):385-393.
[4]RASHEDI E,NEZAMABADI-POUR H,SARYAZDI S.GSA:a gravitational search algorithm[J].Information Sciences,2009,179(13):2232-2248.
[5]BEZDEK J C.Fuzzy mathematics in pattern classification[D].Ithaca:USA Cornell University,1973:18-42.
[6]DUNN J C.A fuzzy relative of the ISODATA process and its use in detecting compact well-separated clusters[J].Journal of Cybernetics,1973,3(1):32-57.
[7]PANG W,WANG K,ZHOU C,et al.Fuzzy discrete particle swarm optimization for solving traveling salesman problem[C]//Proceedings of the Fourth International Conference on Computer and Information Technology.Wuhan,China:IEEE CS Press,2004:796-800.
[8]PAL S K,DUTTA M R D.Fuzzy sets and decision making approaches in vowel and speaker recognition[J].IEEE Transactions on Systems,Man,and Cybernetics,1977,7(8):625-629.
[9]BEZDEK J C.Cluster validity with fuzzy sets[J].Cybernetics,1974,3(3):58-73.
[10]RUNKLER T A,KATE C.Fuzzy clustering by particle swarm optimization[C]//InternationalConferenceon Fuzzy Systems Vancouver Canada,2006:601-608.
[11]WANG Yingje.Fuzzy clustering analysis by using genetic algorithm[J].ICIC,2008,2(4):331-337.
[12]MAULIK UJJWAL,BANDYOPADHYAY SANGHAM-ITA.Genetic algorithm-based clustering technique[J].Pattern Recognition,2000,33(9):1455-1465.
[13]谷文祥,李向涛,朱磊,等.求解流水线调度问题的万有引力搜索算法[J].智能系统学报,2010,5(5):411-418.
GU Wenxiang,LI Xiangtao,ZHU Lei,et al.A gravitational search algorithm for flow shop scheduling[J].CAAI Transactions on Intelligent Systems,2010,5(5):411-418.
[14]ASUNCION A,NEWMAN D J.UCI machine learning repository[DB/OL].Irvine,USA:University of California,School of Information and Computer Science,2007.

谷文祥,男,1947年生,教授,博士生导师,主要研究方向为智能规划与规划识别、形式语言与自动机理论、模糊数学及其应用.主持国家自然科学基金项目3项,发表学术论文100余篇.

郭丽萍,女,1989年生,硕士研究生,主要研究方向为智能规划、智能信息处理.

殷明浩,男,1979年生,副教授,主要研究方向为智能规划与自动推理.主持国家自然科学青年基金项目1项,参与多项国家自然科学基金项目.发表学术论文30余篇,其中大部分被SCI和EI检索.
A solution for a fuzzy clustering problem by applying fuzzy c-means algorithm and gravitational search algorithm
GU Wenxiang,GUO Liping,YIN Minghao
(Department of Computer Science and Information Technology,Northeast Normal University,Changchun 130117,China)
Aiming at fixing the shortcomings of using fuzzy C-means algorithm solely to solve fuzzy clustering problems,first,this paper proposed an improved gravitational search algorithm by updating the velocity of individuals according to a probability,expanding the search space effectively.Secondly,a fuzzy gravitational search algorithm(FGSA)was proposed.Finally,a novel hybrid algorithm(FGSAFCM)based on a fuzzy improved gravitational search algorithm(FGSA)and fuzzy c-means algorithm(FCM)was proposed to solve fuzzy clustering problems.Fuzzy c-means algorithm is very sensitive to initialization and easily gets into local optima,but the new algorithm may avoid these shortcomings.This paper chooses the objective function and validity function as the evaluation criterion.The FGSAFCM was tested on ten classic datasets,and the experiment results show that the new algorithm is more accurate and robust than the sole fuzzy c-means algorithm.
fuzzy clustering problem;fuzzy c-means algorithm;gravitational search algorithm;fuzzy gravitational search algorithm
TP301.6
A
1673-4785(2011)06-0520-06
book=6,ebook=345
10.3969/j.issn.1673-4785.2011.06.007
2011-06-15.
国家自然科学基金资助项目(60803102,61070084).
郭丽萍.E-mail:guolp281@nenu.edu.cn.
