基于独立成分分析和模糊支持向量机的车标识别新方法*
2011-08-14孙娟红李文举韦丽华
孙娟红,李文举,冯 宇,韦丽华
(辽宁师范大学 计算机与信息技术学院,辽宁 大连 116081)
车辆识别技术是智能交通领域的重要研究课题,在桥梁路口自动收费、停车场无人管理、违章车辆自动记录、盗抢车辆追查等领域都有广泛的应用,具有重大的经济价值和现实意义。车标识别是车辆识别技术的重要组成部分,其核心技术是车标定位和车标识别,在准确地定位车标后,车标图像识别就成为一个关键问题。现有的车标识别方法有:基于模板匹配[1]、基于边缘直方图[2]、基于边缘不变矩[3]、基于 SIFT特征[4]以及基于主成分分析和BP神经网络[5]等方法。但是,基于模板匹配的方法在图像倾斜的情况下效果不太理想;基于边缘直方图的方法提取的车标边缘方向直方图特征有时并不十分明显,容易造成识别误差;基于边缘不变矩的方法虽然对图像的平移、缩放和旋转等不敏感,但计算量大且易受噪声影响,使车标识别率受到影响;基于SIFT特征的方法算法复杂,时间复杂度高;基于主成分分析和BP神经网络的方法对于模糊车标图像识别率较低。因此,针对现有车标识别方法的不足,本文提出了一种新的车标识别方法。该方法的基本思想是,首先应用主成分分析 PCA(Principal Component Analysis)进行数据降维,然后应用独立成分分析ICA(Independent Component Analysis)提取车标特征,最后应用模糊支持向量机FSVM(Fuzzy Support Vector Machine)设计分类器。实验结果表明,本文提出的车标识别方法比其他车标识别方法有更好的识别效果。
1独立成分分析及车标特征提取
1.1独立成分分析
ICA是信号处理领域在20世纪90年代后期发展起来的一项新处理方法,最初是用于盲信号的分离,目前已广泛应用于模式识别、数据压缩、图像分析等领域。ICA可以在不知道信号源和传输参数的情况下,根据输入信号源的统计特征,仅观测信号恢复或提取源信号。
对于一组盲源信号 S=(s1,s2,…,sM)T,有 N 路观测信号 X=(x1,x2,…,xM)T,每一路都是一维行向量的形式。存在系数(混合)矩阵 A,使得独立源信号 S与观测信号 X可以用如下的线性关系来表示:

式中,A∈RN×M。
存在分离矩阵W∈RM×N,使其满足下式:

式中:WA=I,I为单位矩阵;Y为统计独立的未知源信号S的最佳估计。基本的ICA模型如图1所示。
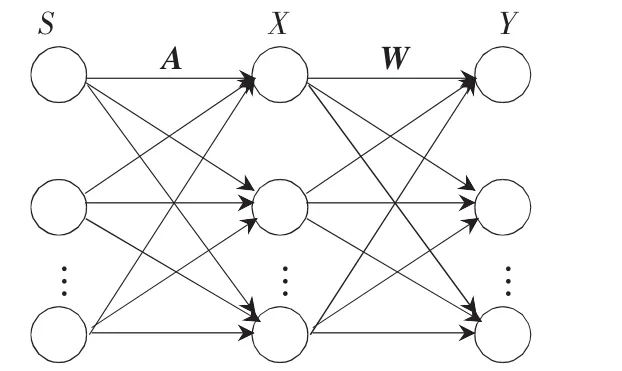
图1 基本ICA模型
在ICA中求解分离矩阵W是关键。目前已有很多求解分离矩阵的算法,考虑到快速性,本文采用了FastICA方法[6]。该方法是基于负熵的固定点算法,效率较高。
1.2基于ICA的车标特征提取
ICA是PCA从二阶统计分析向高阶统计分析的拓展,基于数据的高阶统计信息提取数据的独立特征,能够更好地表示车标特征。但实际处理时在进行ICA之前,先要对原始数据进行预处理。预处理的内容主要包括去均值、向量归一化以及PCA降维等。降维既可以去除噪声,突出主要矛盾,又可以减少计算量[7]。
设训练集共有M 幅原始图像 pi(i=1,2,…,M),每个pi是1×N行矢量(N>M),则车标特征提取步骤如下:
(1)去均值及归一化
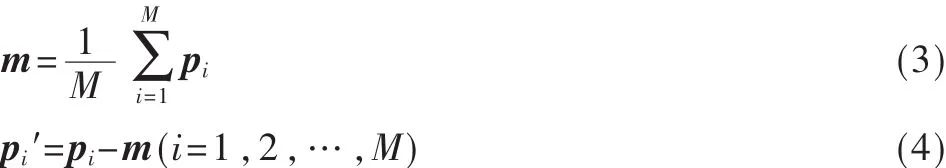
再将各个 pi′归一化为 xi后,构建 M×N原始数据矩阵:

(2)求协方差矩阵和PCA,取主值
协方差矩阵C=XXT,它是 M×M矩阵。
求 PCA:C=UΛUT。 其中,U=[u1u2…uM]。 各 ui是 M×1特征矢量,U是M×M特征矢量矩阵,Λ是特征值对角矩阵。
取前 d个主值(d<M),相应的特征矢量为:Ud=[u1u2…ud],它是 M×d矩阵。
(3)求PCA后的输出Z是X在Ud所构成子空间上的投影,Z=UdTX,为 d×N矩阵。
(4)对 Z求 ICA,先利用 FastICA方法求得分离矩阵W,并由下式求得输出Y:

其中,Y是d×N矩阵,其每一行代表一个基本图像。
(5)对任一样本ps,按下式获得其ICA特征向量:

其中,E=[e1,e2, …,ed],e1,e2, …,ed称为样本 ps的投影系数。在得到训练样本的ICA特征后就可以进行分类器的设计、训练和测试样本的测试工作。
2基于FSVM的分类器设计
2.1模糊支持向量机
FSVM是一种改进的支持向量机SVM(Support VectorMachine)。FSVM有两种表现形式:一种是由Takuga与 Shigeo提出的 FSVM[8-9],一种是由 Lin Chunfu等人提出的FSVM[10]。
Lin Chunfu等人提出的FSVM算法的主要依据是:在机器学习的训练过程中,每个训练数据对支持向量机所起的作用是有差异的,边缘数据是最容易错分的并且成为支持向量的机会多一些,而中间的数据成为支持向量的可能性要小一些,甚至根本不可能成为支持向量。因此,根据训练样本在训练过程中的不同作用,对所有数据(包括异常数据)都会赋予一个隶属度,加大对容易错分样本的惩罚。所以,FSVM较传统的SVM有较高的识别率、较强的抗噪能力和较短的训练时间。
对于最简单的两分类问题,首先,事先选择一个适当的隶属函数,对所有样本进行模糊化,得到每一个样本xi的隶属度Γi,则训练集合便成为模糊训练集:
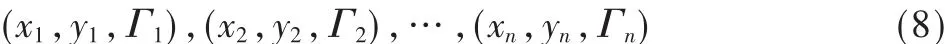
其中,xi∈Rm为 输 入 模 式 ;yi∈{-1,+1} 为 输 出 ;Γi(0≤Γi≤1)为样本的隶属度。
对于上述的训练集,为了得到最优分类超平面,需要解决以下优化问题:

其中,C为常量;φ将xi从Rm映射到高维空间,将隶属度Γi引入决策函数。求解式(9)、式(10)的优化问题,可由以下Lagrange函数的鞍点给出:
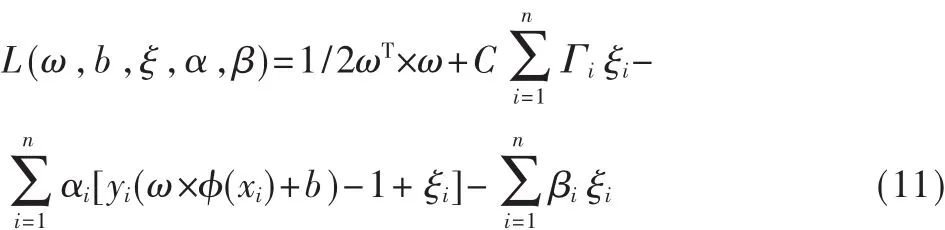
其中,α=(α1,α2,…,αn);β=(β1,β2,…,βn)为 Lagrange乘子,将式(11)分别对 ω、b、ξ求导并置为 0,则有:
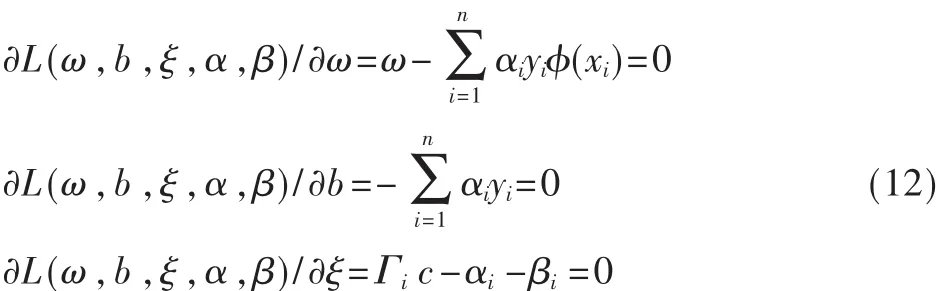
将式(12)代入式(11),则可将式(9)、式(10)转换为:

通过对式(13)、式(14)解优化问题,构造出最优分类超平面,得到决策函数。
2.2基于FSVM的车标分类器设计
本文分类器设计的关键在于以下三点:
(1)从二分类到多分类的推广策略
本文分类器的设计是基于Lin Chunfu等人提出的FSVM。对于SVM解决多分类问题,目前使用较多的方法有:一对多方法、一对一方法和DDAG方法。这些方法同样也适用于FSVM多分类器。对于一个n分类问题,一对一的多分类器构造方法需要构造n(n-1)/2个FSVM,每类样本要参与n-1个FSVM的训练。而且FSVM数据的增加,也增加了测试的时间,让分类器的性能有所损失;DDAG分类器虽然加快了测试速度,但其分类精度又依赖于DDAG上类别的顺序,因此本文采用一对多方法构造车标分类器。
(2)核函数及其参数的选择
本文采用RBF(Radial Basis Function)核函数(也称为高斯函数):

其中,γ决定了该高斯函数围绕中心点的宽度,其大小可以控制支持向量的个数,对于分类面的形成有直接的影响,但目前还没有统一的方法来确定γ的大小,往往需要根据特征数据分析的结果来取经验值,在本文中,取 γ=0.004,系统参数 C=100。
(3)模糊隶属度的确定
如何确定样本的隶属度即正确估计样本对分类的贡献大小,是基于FSVM分类器设计的一个关键的问题。本文利用参考文献[11]中所提到的方法来确定样本的隶属度。假设车标识别是一个k分类问题,则有如下的训练样本:
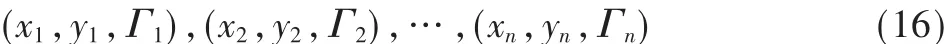
其中,xi∈Rm为输入模式,yi∈{1,2,…,k}为输出,Γi(0≤Γi≤1)为样本的隶属度。
在介绍模糊隶属度Γi的计算方法之前,首先引入类中心的概念。
定义:对于 Rm上的一类点{x1,x2,…,xn},记 xc为类中心点,r为半径。则:
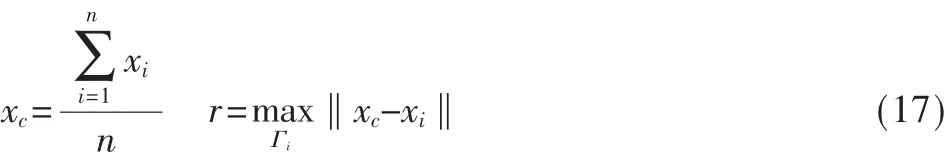
本文采用一对多组合思想进行分类识别,即训练k个两类分类器,且每次训练过程都事先为每个样本xi生成一个模糊隶属度Γi。例如要将第q类和剩余样本分开,由以上定义可得到第q类的中心点x+,类半径记为r+;剩余样本看作一类,其中心点记为 x-,类半径记为r-。为了避免Γi=0,给定一个充分小的δ,则模糊隶属度Γi可定义为:
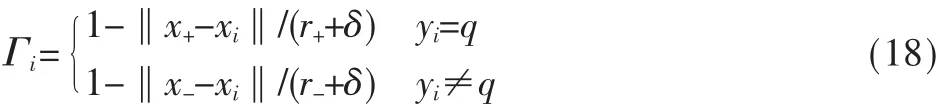
接下来就可以进行模糊支持向量机的训练过程,每次可得一个两类分类器。当所有训练结束时,得到k个两类分类器。分类函数为:
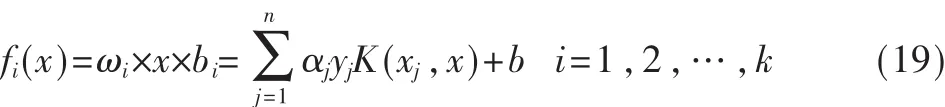
3实验结果与分析
3.1实验对象
目前在车标识别领域还没有标准的车标图像库,因此本文采用自建的车标库进行实验。由于天气或拍摄角度等因素的影响,所获得的车标并非全部都是理想车标图像。如图2所示,其中第1列为理想车标,第2列为光照不均车标,第3列为含有噪声的车标,第4列是由于车标定位分割不准以致图像边缘含有大量非车标信息,第5列是倾斜车标。

图2 部分车标图片
自建的车标图像库共有大众、本田在内的11种常见车标,每类有20幅图像,存储类型为BMP格式,每幅图像的原始分辨率为39×32~101×109。为了方便数据处理,在预处理阶段全部被归一化为56×46,并全部进行灰度化处理。
3.2实验及结果分析
本实验在P4 CPU 2.66 GHz,512 MB内存,Matlab环境下进行。与参考文献[1-4]的各车标识别方法相比较,参考文献 [5]提出的基于主成分分析和BP神经网络的车标识别算法具有较高的识别率和较短的识别时间,因此,本文与基于主成分分析和BP神经网络的车标识别方法作对比实验。实验时,两种方法均依次取每类车标的前3幅、前6幅、前10幅图像作为训练样本,其余的车标图像作为测试样本。参考文献[5]中的BP神经网络选择S型函数(Sigmoid函数)作为激活函数。实验结果如表1所示。
由表1可见,本文提出的车标识别算法(即使训练样本只有33幅的小样本情况下),识别率也能达到90.9%。当训练样本增至110幅时,识别率可达到97.3%,高于参考文献[5]方法的识别率。实验中的识别时间均为平均的识别时间,与参考文献[5]的识别方法相比,本文方法的识别速度更符合实时性的要求。其原因:在特征提取时,本文所用的ICA特征提取方法得到的基图像不仅是不相关的,而且是统计独立的,由此得到的图像更能表示车标的局部信息,并能抑制光照等对识别的影响。而参考文献[5]所用的PCA方法只是通过图像的总体协方差矩阵得到更多的总体信息。在分类器方面,本文所使用的FSVM是在传统SVM的基础上,根据不同输入样本对分类的贡献不同,赋以相应的隶属度,从而能正确估计样本对分类的贡献大小,抗噪声能力强,因此具有更高的识别率,其特征提取和分类器的设计更为合理、有效。而参考文献[5]所采用的BP神经网络存在局部极小点、三层网络隐节点数难确定等问题[12],因此BP神经网络作为车标识别分类器时存在一定的局限性。

表1 实验结果比较
本文提出的车标识别方法在特征提取方面应用ICA方法,充分而有效提取了车标特征;在分类器设计方面,基于FSVM的分类器保证了较高的识别率、较强的抗噪能力和更短的训练时间。实验结果表明,本文提出的车标识别方法具有更高的识别率和更快的运算速度,具有应用价值。
[1]李贵俊.运动车辆类型精确识别技术研究[D].成都:四川大学,2005.
[2]罗彬,游志胜,曹刚.基于边缘直方图的快速汽车标志识别方法[J].计算应用研究,2004(6):150-157.
[3]王枚,王国宏,高小林,等.基于 PCA和边缘不变矩的车标识别新方法[J].计算机工程与应用,2008,44(4):224-229.
[4]高倩.车标识别方法研究[D].大连:大连海事大学,2008.
[5]宁莹莹,李文举,王新年.基于主成分分析和BP神经网络的车标识别[J].辽宁师范大学学报,2010,33(2):179-184.
[6] HY V A, OJA E.Independentcomponentanalysis:algorithm and application[J].Neural Networks, 2000,13(4-5):411-430.
[7]杨福生,洪波.独立分量分析的原理与应用[M].北京:清华大学出版社,2006.
[8]INOUET T,ABE S.Fuzzysupportvectormachinesfor patterclassification [C].Proceding ofInternationalJoint Conference on Neural Networks.Washington DC:[s.n.],2001:1449-1455.
[9]TSUJINISHI D,ABE S.Fuzzy least squares support vector machines for multiclass problems[J].Neural Networks,2003,16(5-6):758-792.
[10]Lin Chunfu,Wang Shengde.Fuzzy support vector machinew[J].IEEE Transactions on Neural Networks,2002,13(2):464-471.
[11]刘太安,梁永全.一种新的模糊支持向量机多分类算法[J].计算机应用研究,2008,25(7):2041-2046.
[12]鲍立威,何敏,沈平.关于 BP模型的缺陷的讨论[J].模式识别与人工智能,1995,8(1):1-4.
