基于MATLAB的车牌识别系统设计与实现*
2011-08-14刘忠杰宋小波周培莹刘百辰
刘忠杰,宋小波,何 锋,李 芬,周培莹,刘百辰
(常州先进制造技术研究所 机器人系统实验室,江苏 常州 213164)
随着世界经济和科学技术的不断发展,智能交通系统越来越多地被人们所关注。车牌识别LPR(License Plate Recognition)是智能交通系统中重要研究课题[1],已成为图像处理和模式识别研究中的热点。整个车牌识别系统主要包括图像预处理、车牌定位、车牌字符分割、车牌字符识别4个模块,其流程图如图1所示。

图1车牌识别流程图
图像预处理主要是将输入的彩色图像转换为灰度图像,再进行灰度增强,以达到较好的凸显车牌字符的效果。这里首先将 24位R、G、B的彩色图像按式(1)转换成256级的灰度图,以减少存储和计算量,图2是转换后的车牌灰度图。


1车牌定位
车牌定位是车牌识别系统中关键的一步,直接关系到车牌字符分割的准确性和系统识别的正确率[2]。通过比较4种典型的边缘检测算子,选择Canny算子对车牌进行边缘检测,然后对车牌进行形态学处理,并统计图像中白色像素点的个数定位出车牌区域。
1.1 4种典型的边缘检测算子
边缘检测的目的是标识数字图像中亮度变化明显的点,车牌识别4种典型的边缘检测算子有:Roberts算子、Prewitt算子、Sobel算子和 Canny算子,图 3是这 4种典型的边缘检测算子对车牌图像的检测效果图。

图3不同边缘检测算子比较
实验结果表明,Roberts算子对边缘定位比较准,但对噪声过于敏感,在图像噪声较少的情况下分割效果相当不错。Prewitt算子有一定的抗噪能力,但是这种抗噪能力是通过像素平均来实现的,相当于低通滤波,所以图像有一定模糊,其边缘检测时会受到一定影响。Soble算子对噪声有抑制作用,但对边缘的定位不是很准确,不适合对边缘定位的准确性要求很高的应用。Canny算子具有高定位精度,即能准确地把边缘点定位在灰度变化最大的像素上,同时较好地保留了原有车形的边缘特征,并能抑制虚假边缘的产生,因此本文选取Canny算子作为车牌图像边缘检测算子。
Canny算子边缘检测的实现是由MATLAB图像处理工具箱中edge函数来完成的。edge函数主要是在灰度图像中查找图像的边缘,处理图像的格式为BW=edge(I,′Canny′,thresh),其中I为灰度图像;thresh是一个包含两个阈值的向量,第一个元素是低阈值,第二个元素是高阈值,本文Canny算子边缘检测的MATLAB参数设置如下:

1.2数学形态学处理
数学形态学是由一组形态学的代数运算算子组成的,用这些算子可以对图像的形状和结构进行分析及处理[3]。通过对图像的腐蚀和膨胀运算能使车牌区域连通,并最大限度地消除非车牌区域的噪声干扰。腐蚀和膨胀后的车牌图像如图4所示。

图像经过膨胀以后依然存在许多连通的小区域,但这些小区域明显不是车牌候选区域且形状不规则。由车牌的先验信息知,我国车牌形状为矩形,一般高14 cm,宽44 cm,宽高比3.14。根据我国车牌的特征很容易就能够删除这些干扰对象,即使用bwareaopen函数来处理干扰对象。bwareaopen函数的格式为BW2=bwareaopen(BW,P,conn),其作用是移除二值图像BW中面积小于阈值P的对象。通过实验得阈值P取2 000~3 500之间效果较好,这里阈值P的取值为2 800。图5是移除小对象后得到的车牌图像。
1.3车牌剪切
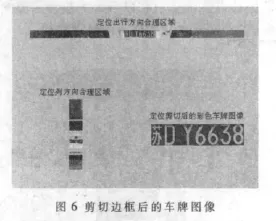
通过数学形态学处理之后已大体上定位出车牌的位置,接下来就是从原彩色图像中把车牌剪切出来,并去除车牌边框。图像中车牌位置可以通过统计图像中的白色像素点的个数获得[4],再使用MATLAB中imcrop函数剪切出车牌。针对车牌边框可以通过设置不同的阈值来去除,以L1=Width/7为阈值对剪切出的车牌图像按行扫描,如果有线段的长度大于L1就可以认为是牌照的上下边框,再以L2=Height×3/5为阈值对剪切出的车牌图像按列扫描,如果有线段的长度大于L2,则认为是牌照的左右边框。找到车牌的上、下、左、右边框之后,重新剪切车牌图像去除车牌边框,完成车牌的定位,如图6所示。
2车牌字符分割
车牌字符分割是指将单个字符从车牌图像中分离出来。车牌字符分割方法主要有数学形态学法、投影法、松弛标记法、连通分支法和颜色块法[5]。本文综合使用了数学形态学和投影法来分割车牌字符,其基本流程是:首先对定位出的车牌进行二值化和形态学开运算,以去除灰尘及铆钉等干扰噪声,然后利用投影二分法分割出7个车牌字符,并对字符进行归一化。
2.1二值化和形态学开运算
二值化图像的目的主要是找出一个合适的阈值或一个阈值范围,将车牌区域划分为前景和背景两部分,以方便车牌字符的分割。常用的二值化方法有直方图统计法、固定门限法、动态阈值法、松弛法、抖动矩阵二值法等。本文使用了迭代求图像最佳分割阈值的算法,得到的二值化图像如图7所示。

二值化图像以后,使用fspecial函数对图像进行平滑滤波,在保留字符笔画结构特征的前提下,尽可能去除噪声。然后对图像进行形态学开运算,以去除图像中的孤立区域和毛刺,将背景保留下来,得到背景的估计,并使图像的边界变得平滑。图8所示为滤波及形态学开运算图像。

2.2字符分割及归一化
在车牌字符分割中,使用最多的是垂直投影法,该方法将灰度车牌图像像素列方向上求和,这样有字符的地方投影较高,而字符中间,理想情况下是没有像素的,但现实图像中由于噪声的干扰会存在一定的像素。在现实环境中车牌图像上往往有灰尘、铆钉等噪声,由于垂直投影受噪声影响较大,易造成分割字符的粘连与断裂,严重情况下会造成车牌字符之间的投影很难辨认,在一定程度上影响了车牌的识别率。针对传统投影法的不足,冼允廷等提出了基于投影二分法的车牌字符分割方法[6]。该方法主要是通过迭代寻找最佳分割点,能够很好地解决车牌字符分割中存在的粘连和断裂问题,因此本文选用投影二分法对车牌图像进行分割,通过投影二分法分割出的车牌字符图像如图9所示。

由于分割出的字符大小尺寸不相同,为提高车牌字符识别准确率,需要对分割出的字符进行归一化处理。本文采用最近邻插值法,即为零阶插值,其输出的像素值就等于离它映射到的位置最近的输入像素的值。图10是将字符的大小归一化为40×20的图像。

3车牌字符识别
在车牌字符识别环节,本文使用模板匹配和特征统计相结合的方法,通过计算待识别字符与各样本字符的欧氏距离来实现对该字符的模板匹配识别,然后再对相似字符进行特征统计优化识别结果,以提高车牌字符识别的准确率。
3.1模板匹配初次识别
模板匹配方法是最直接的识别字符方法,其实现方式是计算输入模式与样本之间的相似性,取相似性最大的作为输入模式所属类别。我国车牌有7个字符,其标准车牌格式是:X1X2·X3X4X5X6X7,X1是各省、直辖市和自治区的简称,X2是英文字母,X3X4是英文字母或阿拉伯数字,X5X6X7是阿拉伯数字。根据我国车牌的特征,建立3个模板库,即汉字库、字母库和数字库,识别时,对第1个字符采用汉字库,第2个字符采用字母库,第5~7个字符采用数字库,其他的采用数字库和字母库。
模板匹配法的基本算法是最小欧氏距离法,即对任一原型模式Zi,计算它和待匹配字符X的欧氏距离Di,Di=|X-Zi|,然 后 找 到 最 小 的 Di, 其 对 应 的 Zi就 是 识 别 出的字符。下面以二维图像的处理为例来说明模板匹配算法,具体描述如下:
设输入字符用输入函数f(x,y)表示,标准模板用函数F(x,y)表示,在相关器中比较后输出为T(x,y)。随机变量用x、x1表示,相关器输出为:

式(3)和式(4)为输入字符的自相关函数,且有T(0,0)≥T(X,Y)成立。T(X,Y)会在T(0,0)处出现主峰,而在其他标准字符处出现一些副峰,然后选用相关函数来对这些主峰和副峰进行鉴别。图像与模板匹配程度的相关函数可以由式(5)来测定:

其中,R(i,j)为互相关算子,S为待检测的图像,Si,j为待检测的子图,T为模板。将待识别的字符逐一和所有模板进行匹配,并用上述相似度式子来计算车牌字符与每个模板字符的匹配程度,最相似的就是匹配结果,从而判断并识别出待识别的字符。
计算二维图像相似度可以用Matlab中提供的corr2函数来实现。corr2函数的调用方法是R=corr2(A,B),其中R是相关系数,数据类型为双精度,A、B为大小和数据类型相同的图像矩阵。因为前面的车牌字符分割环节中已把车牌字符大小归一化为40×20的图像,与模板图像大小相同,所以模板匹配过程只需调用此函数,将分割出来的每个字符与设置好的模板进行相关运算,然后使用MATLAB中max函数寻找出它们中的最大相关值,即最相似的匹配结果,就完成了模板匹配过程。
3.2特征统计优化识别
由于车牌字符中的个别英文字母与阿拉伯数字具有相似的结构特征,投影点的欧氏距离相差较小,因此,需要对部分相似字符的识别结果进行优化识别,并将优化结果作为最终识别结果输出。例如:
(1)数字 0与 8:利用数字 0与 8的“空心”个数进行区分。数字0从上到下只有一个空心,而数字8从上到下有两个空心。因此,可以将数字0与8区分开。
(2)数字 6与 9:利用数字 6与 9的“空心”区域分别位于图像的中下部与中上部的特点,可以将其区分开。
(3)数字8与字母B:利用数字8和字母 B中部左边像素点的位置进行区分。对字符图像的中部(从上向下第11个像素点至第21个像素点)从左向右检测第1个白色像素点,并记录该点的位置。取这些点的算术平均值,若该值在 4个像素点以下,则该字符为字母 B,否则为数字8。
本文对不同天气情况下采集的358幅图片进行了MATLAB仿真测试。如果仅使用模板匹配法,可以识别出284幅图片,识别正确率为79.3%,其中有45幅是在相似字符识别时出错;如果使用模板匹配和特征统计相结合的方法,可以识别出329幅图片,识别正确率为91.9%,其中相似字符的识别准确率大大提高。与单一使用模板匹配相比较,本文方法明显优于传统的模板匹配法,分析原因主要是通过特征统计对相似字符的再次识别弥补了模板匹配对相似字符识别较弱的不足。与传统使用神经网络方法识别率只有75.7%相比较,本文91.9%的识别正确率具有明显优势。总之实验结果表明,经过特征统计再次优化识别以后大大提高了整个系统的识别正确率,图11所示为本文车牌识别图像。

目前,车牌识别技术已经取得一定突破,但在现实应用中车牌识别正确率还不理想,仅使用一种特征和识别方法都有其优点和局限性,走多特征组合、多方案集成的道路,已成为车牌识别系统走向实用化的有效途径,因此车牌识别系统算法实用化的研究十分重要。
[1]GUO J M,LIU Y F.License plate localization and character segmentation with feedback self-learning and hybrid binarization techniques[J].Transactions on Vehicular Technology,2008,57(3):1417-1424.
[2]ZHANG C,SUN G M,CHEN D M.A rapid locating method of vehicle license plate based on characteristics of characters′connection and projection[C].Proc of the Second IEEE Conference on Industrial Electronics and Applications,2007:2546-2549.
[3]BAI H L,LIU C P.A hybrid license plate extraction method based on edge statistics and morphology[C].Proc of the 17th International on Pattern Recognition,2004:831-834.
[4]沈勇武,章专.基于特征颜色边缘检测的车牌定位方法[J].仪 器 仪 表 学 报 ,2008,29(12):2673-2677.
[5]CHANG S L,CHEN L S,CHUNG Y C.Automatic license plate recognition[J].IEEE Transactions on Intelligent Transportation System,2004,5(1):42-53.
[6]冼允廷,路小波,施毅,等.基于投影二分法的车牌字符分割方法[J].交通计算机,2007,25(5):69-71.
