基于CUDA的雷达线性调频信号脉冲压缩实现*
2011-08-10江艳阳黄双华白海东
江艳阳 黄双华 刘 峰 白海东
(海军工程大学研究生院1) 武汉 430033)(海军工程大学电子工程系2) 武汉 430033)
1 引言
在复杂电磁环境下,雷达信号处理机需要在短时间内处理的数据量是极大的,以合成孔径雷达(SAR)为例,其信号处理有时需要每秒几十亿甚至上百亿次运算速度,而传统的CPU运算能力是远远不够的。文献[1]中介绍了并行计算机在雷达信号处理中的应用,其主要采用微处理机系统、阵列处理机以及DEC、DSP芯片等满足信号和数据处理速度。而CUDA是一种将GPU作为数据并行计算设备的软硬件体系,使专注于图像处理的GPU超高计算性能在数据处理和科学计算等通用计算领域发挥优势[2~3]。
当前低端GPU的单精度计算能力即可以和主流CPU相媲美。以主流GT200为例,其峰值浮点计算能力接近万亿次每秒。在进行蛋白质折叠计算的Folding@home分布式计算项目中,仅有的11370颗支持CUDA的GPU提供了总计算能力的一半;而运行Windows的CPU共计208268颗,仅提供了总处理能力的6%[2]。
鉴于GPU强大的浮点处理能力,利用GPU作为雷达仿真平台,采用CUDA技术,实现雷达信号处理的仿真,并以频域脉冲压缩算法为例,与传统的CPU仿真性能进行比较。验证CUDA处理结果的正确性和数据处理速度的高效性。
2 频域脉压基本算法
实现频域脉压的方法[4~5]如图1所示。
该算法的核心是FFT、IFFT和复数点乘运算,其运算性能直接影响脉冲压缩系统仿真性能。
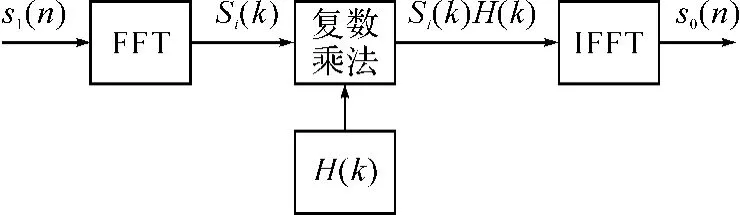
图1 频域脉压方法
3 CUDA编程模型
CUDA编程模型将CPU作为主机端(Host),GPU 作为设备端(Device)[2]。一个完整的 CUDA模型包括运行在CPU端的主机端代码和运行在GPU端的设备端代码,也称为kernel(内核函数)。一个内核函数中存在两个层次的并行,Grid中的block间的并行和block中thread间的并行。设备端运行的线程之间是并行执行的,每个线程按照指令的顺序串行执行一次kernel函数。
在一个完整的CUDA程序中,Host代码主要完成CUDA的启动,为输入数据分配内存和显存空间,完成数据在显存和内存之间的传输,调用Device端的kernel进行计算,释放内存和显存空间,退出CUDA等操作。Device端主要完成数据的处理。
利用CUDA实现线性调频信号的频域脉冲脉冲压缩处理,主要包括以下几个步骤[6~10]:
第一步:为输入及输出数据分配内存空间和显存空间。
第二步:读取回波信号序列si(n)和匹配滤波器数据H(k)的值,并将si(n)和H(k)从内存拷贝至显存。
第三步:利用CUDA提供的CUFFT库完成输入回波信号序列si(n)的快速傅立叶变换得到Si(k),利用CUDA编写的内核函数完成复数序列Si(k)与H(k)的乘法运算,将得到的结果进行IFFT,得到输出序列so(n)。
第四步:将so(n)从显存拷贝至内存。
其算法流程图如图2所示。
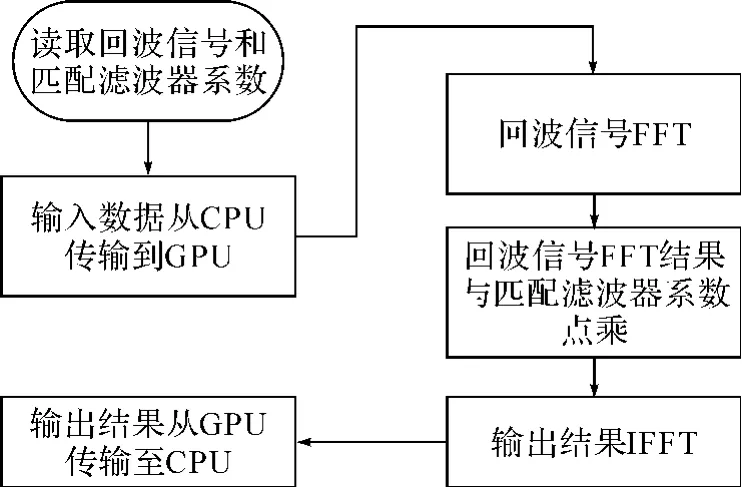
图2 利用CUDA实现的脉冲压缩流程图
在CUDA程序中,主要完成数据在主机端和设备端之间的传输以及设备端内核函数的执行。所以,在利用CUDA进行数据运算时,尽量减少数据在设备端和主机端传输所消耗的时间,从而提高运算效率。
4 仿真结果及分析
仿真采用的显卡是计算能力为1.1的NVIDIA GeForce GTS250,操作系统为 Windows XP SP3。由于本实验中设备的计算能力为1.1,不支持双精度浮点运算,所以实验中CPU与GPU处理的数据均为单精度浮点数。
在仿真中,设定LFM信号中心频率f0=1.8×108Hz,信号带宽B=20kHz,发射信号脉冲宽度τ=640μs,多普勒频移fd=12kHz,采样频率fs=32MHz,信号延迟td=0.64ms。
图3为线性调频信号发射波形及静止目标回波与动目标回波波形。
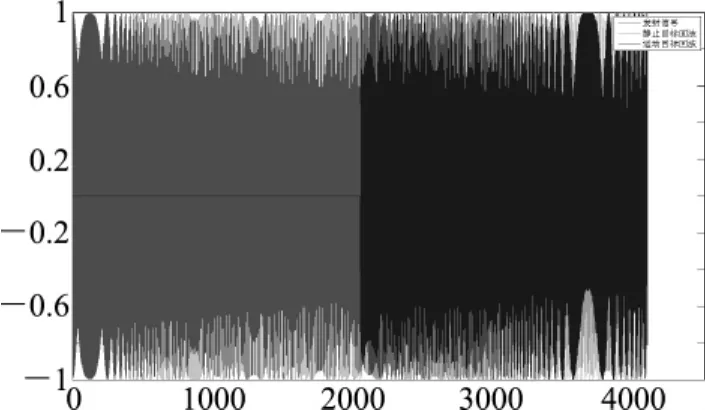
图3 发射信号与回波信号波形
利用CUDA对回波信号进行脉压处理,局部放大之后脉压输出波形如图4所示。
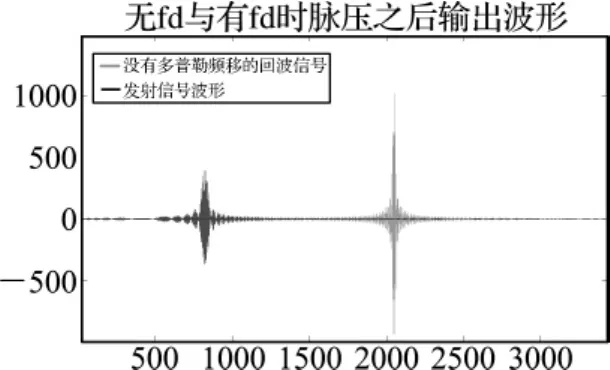
图4 回波信号脉压之后波形—GPU
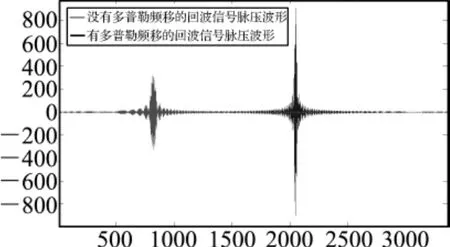
图5 回波信号脉压之后波形—CPU
利用CPU对回波信号进行脉压处理,局部放大之后脉压输出波形如图5所示。
由图4和图5可得,基于GPU的仿真结果和基于CPU的仿真结果在数据处理结果上的一致性,但是两者的运算速度却有明显的差距,处理相同数据尺寸的运行时间对比表如表1所示。

表1 GPU—CPU运行时间对比表(单位:ms)
由表1可得,实际上调用内核kernel进行计算所用的时间是很短的,数据量的大小对其执行时间的影响相对较小,但是,数据在CPU端和GPU端传输占用了大量的时间。进一步验证了在第2节提到的尽量减少数据在CPU和GPU之间的数据传输,以提高数据计算速度。
5 结语
实验结果表明,在频域脉冲压缩处理中,采用CUDA技术不仅取得了与CPU相同的处理结果,而且在运算效率上取得了明显的加速比,且随着数据尺寸的增加,加速比也越来越大。同时基于CUDA的线性调频信号脉冲压缩处理具有较好的实时性,为利用CUDA技术进行雷达信号处理提供了借鉴,也为CUDA技术在软件化雷达中的应用提供了可能。
[1]黄鸿勋,王秀春.并行计算机在现代雷达信号处理中的应用[J].现代雷达,2004,26(3):25~28
[2]张舒,褚艳利,赵凯勇,等.GPU高性能运算之CUDA[M].北京:中国水利水电出版社,2009:5~8,14~18
[3]多相复杂系统国家重点实验室多尺度离散模拟项目组.基于GPU的多尺度离散模拟并行计算[M].北京:科学出版社,2009:7~9,37~41
[4]吴顺君,梅晓春.雷达信号处理和数据处理技术[M].北京:电子工业出版社,2008:88~94
[5]张明友,汪学刚.雷达系统[M].第二版.北京:电子工业出版社,2006:247~264
[6]柳彬,王开志,刘兴钊,等.利用CUDA实现的基于GPU的SAR成像算法[J].信息技术,2009(11):62~65
[7]罗军辉,罗勇江.MATLAB7.0在数字信号处理中的应用[M].北京:机械工业出版社,2005:157~197
[8]Bassem R.Mahafza,Atef Z.Elsherbeni.雷达系统设计MATLAB仿真[M].朱国富,等译.北京:电子工业出版社,2009:168~186
[9]Bassem R.Mahafza.雷达系统分析与设计(MATLAB版)[M].第二版.陈志杰,等译.北京:电子工业出版社,2008:214~234
[10]杨万海.雷达系统建模与仿真[M].西安:西安电子科技大学出版社,2007:151
