针对医学数据案例挖掘系统的算法设计
2011-08-07陈杰
陈杰
浙江省人民医院 计算机中心,浙江杭州 310014
近年来,随着医疗行业信息化的迅猛发展,在医疗信息系统中,每天都有数以千百计的病例添加到数据库中,如果能够从数据库里大量的数据中找到有规律性的诊断规则和参考案例,就可以供医生在诊断时作为参考,也可以以此为基础建立一个医疗诊断的专家系统,这对于提高诊断的效率和效果、更深入地了解疾病的机理都是有很大帮助的。许多系统是使用数据挖掘技术来构建案例库的,如YLI等人[1]提出了一种案例库建设方法,该方法通过减少合并特征案例选择来建立推理分类器。基于案例推理的混合型专家(MOE4 CBR,Mixture of experts for casebasd reasoing)使用群体和特征选择技术,发现有代表性的案例并建立一个完整的案例库[2]。本文提出的案例挖掘系统,它能运用数据挖掘的优势来挖掘典型案例。
1 系统构架
案例挖掘系统的架构(图1)包含两个主要模块,特征提取和案例挖掘该系。特征提取器使用模糊测量的方法来选择数据的重要特征,通过评价其相关系数、重叠率和信息增益来发现特征之间的关联,计算案例的相关性。将具有较高相关性的案例选定为重要特征用来挖掘案例,为数据挖掘产生每一个权重。案例挖掘则是利用聚类分析的遗传算法来选择具有代表性的个案。

图1 系统架构
2 案例特征提取算法设计
特征分析的目的在于确认有意义的特征。R.Caruana和P.Langley 发现为特征选择有关的特征都非常重要[3-4],有些系统还可以使用数据挖掘的特征选择。X.Zhu 利用特征和作为权重类的相关特征之间的关联来处理错过值[5]。C.Lee和G.G.Lee使用信息增益和不同的特征选择方法来查找相关的特征[6]。G.Qu引入了一个新特征的相关性和子集优点措施来计算特征的相关性和相互关系,提高预测和数据挖掘算法的准确性[7]。本文采用模糊特征提取成分分析(FCA)来评价特征的相关性。

CC、OR和IG分别代表相关系数、重叠率、信息增益。
CC表示计算两个变量的值的变化:
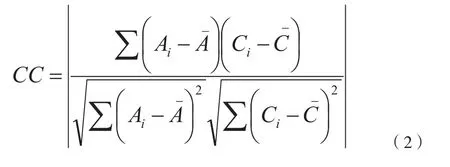
式中,Ai、Ci、、分别表示特征值、类值、特征值的平均值和类值的平均值。
OR表示特征值在不同的类之间的重叠度:
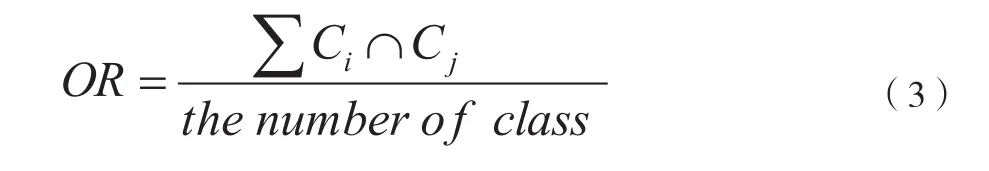
式中,Ci和Cj是指i类和j类的特征值的范围。
IG表示根据增益率计算一个特定特征的存在频率[6]:
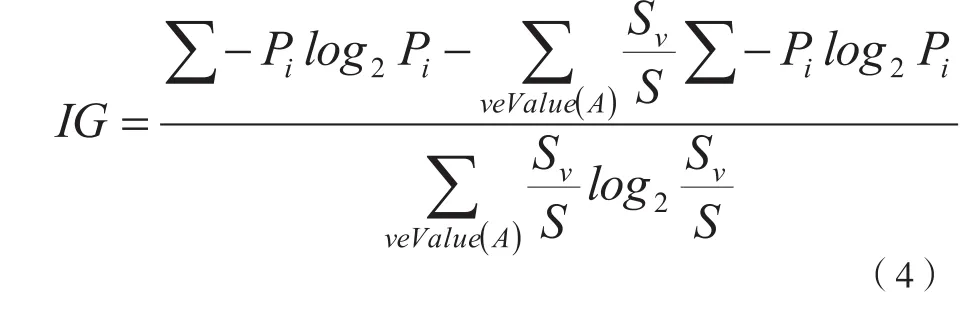
式中,P、S和Sv 分别是概率,特定特征的案例数量,以及类的值是v的个案数量。
特征提取运用模糊理论来计算FCA的隶属度(图2)。
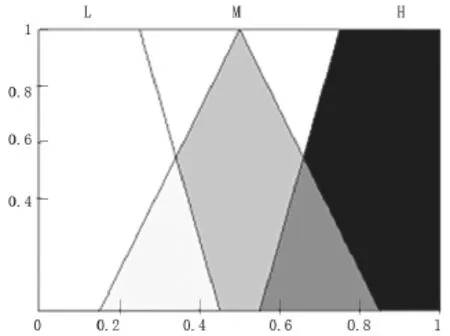
图2 模糊集隶属函数
特征提取器利用作为模糊理论的矩阵计算方法来算出每个所选特征的权重。
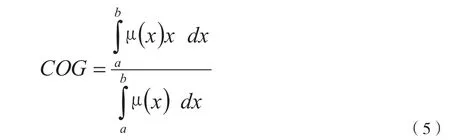
式中,μ(x)是特征x的隶属度。
新的模糊关联矩阵,见表1;新的模糊集隶属函数,见图3。
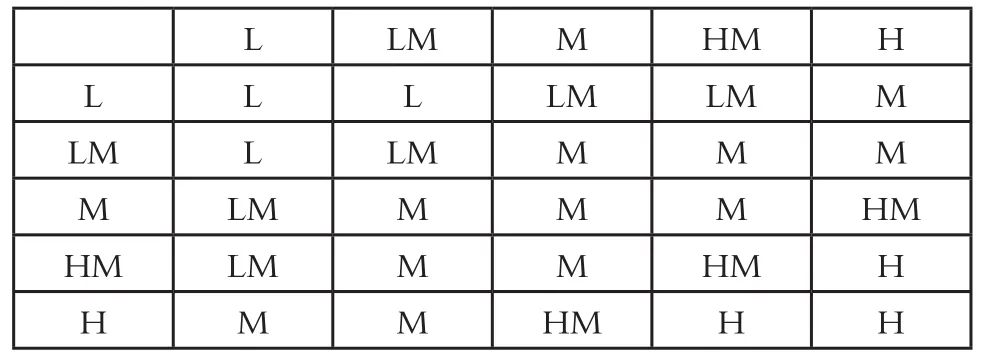
表1 模糊关联矩阵
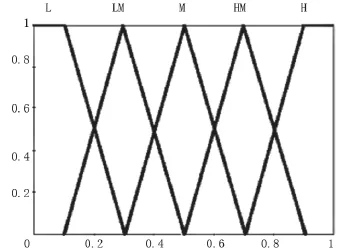
图3 新的模糊集隶属函数
3 针对案例的挖掘算法设计
案例挖掘运用遗传算法来选择有代表性的案例,即从原始数据集中选出代表性案例。选择该基因的长度等于案例数目,图4显示了基因的代表性, 基因数字用1和0表示案例被选中或没被选中。

图4 基因的表示
在具有代表性案例的范围内,用合适的函数通过计算最接近的案例数量,来评估案例的覆盖范围。
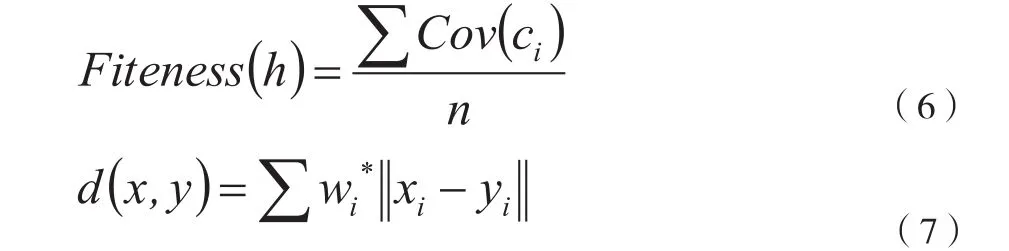
式中,h、Ci、n、cov(Ci)、d(x,y)和 Wi分别代表假设,假设的侯选案例,侯选案例的数量,包含侯选案例Ci的案例,权重距离量度和第i个特征的权重。当代表性案例覆盖90%以上的案例时,评估结束。值得注意的是,交叉和变异概率是100%和1%。
最后,通过不断增加具有重要意义特征值的案例,可以在丰富的案例库中进行案例挖掘。显著特征的值不包含在代表性案例的范围内。
4 结论
通过对案例挖掘系统的算法设计,可以构建一个为数据挖掘服务的医学案例库系统。然后在医疗案例库构建中采用了3个标准医疗数据集,包括有大肠直肠癌数据库、甲状腺癌数据库以及乳癌数据库,用这3种医疗数据集作为测试数据来进行数据挖掘。然后以典型案例的涵盖程度以及其使用率作为检视案例库完整性的依据(实验数据量大,就不在本文中描述)。最后对案例库的建设也使用决策规则和神经网络的分类规则进行了评估,研究表明,该系统可以找到正确的典型案例。
[1]Y.Li,S.C.K.Shiu and S.K.Pal,Combining Feature Reduction and Case Selection in Building CBR classifiers[J].IEEE Transactions on Knowledge and Data Engineering,2006,18(3):415-429.
[2]N.Arshadi and I.Jurisica.Data Mining for Case-Based Reasoning in High-Dimensional Biological Domains[J].IEEE Transactions on Knowledge and Data Engineering,2005,17(8):1127-1137.
[3]R.Caruana,D.Freitag.Greedy Attribute Selection[A].In Proceedings of International Conference on Machine Learning[C].Morgan Kanfman,1994:28-36.
[4]P.Langley.Selection of Relevant Features in Machine Learning[J].AAAI Fall Symposium on Relevance,1994:97(1-2):1-5.
[5]X.Zhu,X.Wu.Data Acquisition with Active and Impact-Sensitive Instance Selection[A].Proceedings of 16th IEEE International Conference on Tools with Artificial Intelligence[C].Boca Raton:IEEE computer Society,2004,721-726.
[6]C.Lee,G.G.Lee.Information Gain and Divergence-Based Feature Selection for Machine Learning-Based Test Categorization[J].Information Processing and Management,2006,42(1):115-165.
[7]G.Qu,G.Hariri,M.Yousif.A New Dependency and Correlation Analysis for Features[J].IEEE Transactions on Knowledge and Data Engineering,2005,17(9):1199-1207.
[8]T.Michae.Machine learning[M].Sigapore:McGraw-Hill,Singapore,1997.