知识发现(KD)研究热点与前沿的信息可视化分析
2011-07-16郭凌辉武汉大学信息管理学院武汉430072
●郭凌辉(武汉大学 信息管理学院,武汉 430072)
1 前言
知识发现(KD)是计算机科学发展最快的领域之一。
知识发现(KD)就是从大量数据中提取出可信的、新颖的、潜在有用的并能被人理解的模式的高级处理过程。[1]知识发现一个重要步骤是数据挖掘(DM),数据挖掘是从数据中提取知识的实际过程。在实践中,人们通常把数据挖掘(DM)、知识发现(KD)以及数据挖掘和知识发现(DMKD)看做同义语。随着信息时代和知识经济的到来,KD理论和技术,已成为计算机应用的重点领域,知识发现的研究范围在不断扩大,研究热度不断升温。
近年来,国内外知识发现研究学者对知识发现的研究现状、前沿与热点、发展趋势等进行了一定程度的研究。如杨炳儒等(2005) 认为目前国际上KDD的研究主要是以知识发现的任务描述、知识评价与知识表示为主线,以有效的知识发现算法为中心,这是在相当长的一段时间内保持的主流基调。[2]Krzysztof J.Cios,LukaszA.Kurgan(2006) 认为,除了设计和实施一个新的DMKD框架之外,还需要更多的实际行动。它包括设计一种高性能的新一代数据挖掘系统,该系统具备复合数据挖掘方法,能从海量复杂数据中特别是多媒体数据中挖掘有用的知识,并能可视化分析结果。[3]孙吉红和焦玉英(2006) 认为知识发现研究的重点领域和趋势集中在:文本挖掘、数据挖掘(查询)语言的设计、数据立方的数据挖掘、概念知识库挖掘、基于可视化的知识发现、复杂数据类型挖掘的新方法、可伸缩的数据挖掘方法。除此之外,知识发现与数据隐私保护和信息安全、开发知识发现语言、专项挖掘查询语言及其优化等领域也是数据挖掘未来发展的趋势。[4]黄紫菲(2006) 则认为,目前,国外对KDD的研究主要有:对Bayes(贝叶斯)方法以及Boosting方法的研究和提高;传统的统计学回归法在KDD中的应用;KDD与数据库的紧密结合。在应用方面包括KDD商业软件工具不断产生和完善,注重建立解决问题的整体系统,而不是孤立的过程。[5]靳展(2008) 认为知识发现的研究重点也逐渐从发现方法转向系统应用,并且注重多种发现策略和技术的集成,以及各种学科之间的相互渗透。[6]杨炳儒(2008)认为当前KD&DM研究的趋向主要有:原有理论方法的深化与拓展;复杂类型(系统)数据挖掘成为热点;新技术方法的引入(其他学科领域的渗透);理论融合交叉性研究;强化基础理论研究等。[7]李进华(2009)认为网格环境下的分布式知识发现将朝着更广范围与更大规模的数据集、更丰富的知识发现工具、更加智能化的知识发现调度策略、更高程度自动化的知识发现流程、更加个性化的知识服务等方面发展。[8]
前述有关研究基本均是定性分析,是主观思辩的结果。笔者拟在相关文献研究的基础上,基于科学计量学的方法,从科学知识图谱的角度,对近年来国际上对知识发现(KD) 前沿主流研究领域与相关热点问题进行初步的以定量分析为主,定性分析为辅的探析,希望对知识发现(KD)的研究有所裨益。
2 数据来源与研究方法
本文所使用的数据,全部来源于美国的科学情报研究所(Institute for Scientific Information,缩写为ISI) 出版的Web of Science数据库中的 (SCI-EXPANDED,SSCI,A&HCI,CPCI-S,CPCI-SSH) 文献。数据的检索策略是“TS(主题)=Knowledge discovery AND 语言 =(English)AND文献类型 =(Article) 数据库 =SCI-EXPANDED,SSCI,A&HCI AND入库时间 =1986-2009,检索结果为3987条文献记录,数据下载日期为2010年3月10日。
本文采用以定量分析为主的科学知识图谱的绘制方法,[9,10]借助陈超美博士开发的信息可视化软件Citespace,[11]形象地展示出国际KD研究的热点与前沿。通过绘制科学知识图谱,可以将知识和信息中令人注目的最前沿领域或学科制高点,以可视化的图像直观地展现出来,帮助人们挖掘、分析和显示科学知识以及它们之间相互关系,并能够较为直观地识别学科前沿的演进路径及学科领域的经典基础文献。分析共被引作者,可以发现该学科的重要核心人物及相互之间的学术亲缘关系。[12,13]此外,CiteSpace还具有关键词聚类和膨胀词探测功能,以此便可确定某研究领域的前沿领域和发展趋势。
3 结果分析
3.1 国际知识发现研究的关键节点文献与作者
我们将1986—2009年发表的全部3987篇“知识发现”的题录数据输入Citespace软件中,这些题录数据主要包括标题、关键词、摘要和参考文献等。选择网络节点确定为参考文献,将1986—2009年这24年跨度分为8个时间分区(每3年一个分区),阈值分别设置为 (2,2,20),(4,3,20),(4,3,20),运行Citespace软件,得到国际知识发现研究共引网络知识图谱(见图1)。字体越大表明越是重要的节点文献。

图1 国际知识发现(KD)研究的关键节点文献
通过图1我们可以清晰地看到国际知识发现研究领域经典文献之间的共被引关系。在这张图谱中我们可以看到6个最突出的关键节点文献。根据陈超美博士的定义,共引网络图谱中的关键节点是图谱中连接2个以上不同聚类,且相对中心度和被引频次较高的节点。这些节点可能成为网络中由一个时间段向另一个时间段过度的关键点。[14]从知识领域的角度看,关键节点文献一般是提出重要的新理论或是具有重大理论创新的经典文献,也是最有可能形成科学研究前沿热点的文献。
从图1可以看出,按照节点在共引网络中的大小,视图中最突出的是Agrawal R,Imielinski T和Swami A(1993) 年发表的《Miningassociationrules betweensets of items in large databases》。在该文中,Agrawal等首先提出了挖掘顾客交易数据库中项集间的关联规则问题,其核心方法是基于频集理论的递推方法。关联规则是Agrawal等人提出的数据挖掘领域中的一个重要课题,它是描述在一个交易中物品之间同时出现的规律的知识模式。关联规则的分析方法用于隐藏在大型数据集中令人感兴趣的联系。所发现的联系可以用关联规则或频繁项集的形式表示。关联规则可以揭示事物之间的联系,也用于购物篮分析,金融服务和科学数据分析等。[15]
并列排在第一位的作者是QuinlanJ R,他在1993年出版了《C4.5:Programs for Machine Learning》一书。决策树方法在机器学习、知识发现等领域具有广泛应用。在该书中,他提出了ID方法的改进版本C4.5算法。C4.5决策树算法的核心思想是利用信息熵原理,选择信息增益率最大的属性作为分类属性,递归地构造决策树的分枝,完成决策树的构造。[16,17]
排在第三位的是Agrawal R和Srikant R 1994年发表的Fast algorithms for mining association rules in large databases一文,文中Agrawal等人提出了著名的Apriori算法,改进了1993年提出的算法中支持度的计算方法,利用支持度的单调性来对候选项集进行剪枝,从而大大减少了候选项集的数量和计算时间,其后的许多关联规则算法都是基于Apriori算法或者是其变种。[18,19]
此外,Breiman L,Friedman J H,Olshen R A,Stone C J在1984年出版的Classification and Regression Trees[20]一书提出了分类与回归树算法CART(Classification and RegressionTree),Quinlan J R在1986年发表的《Induction ofdecision trees》[21]一文提出了 ID3决策树算法。
以上这些文献都是国际知识发现(KD)研究中的关键文献,在知识发现知识图谱中均处于较重要的中心位置,对推动国际知识发现研究起了重要作用。而这些文献的作者是国际知识发现研究的重要节点文献作者。
3.2 国际知识发现的研究热点
关键词在一篇文章中所占的篇幅虽然不大,但却是文章的核心与精髓,是文章主题的高度概括和凝练,因此对文章的关键词进行分析,频次高的关键词常被用来确定一个研究领域的热点问题。[22,23]Citespace是一个由Java语言编写的基于共引分析的引文网络可视化软件。运行该软件时,可以选择使用关键路径(pathfinder)算法或最小生成树(minimumspanning trees)算法对科学文献引文共引网络的路径进行分析和处理,并可以通过显示高频关键词来确定国际KD研究的主要研究领域和研究热点。
我们将1986—2009年发表的全部3987篇“KD”相关文献数据输入到Citespace软件中,网络节点确定为关键词(keyword),主题词来源选择标题(title)、摘要(abstract)和关键词(descriptors与identifiers),词项选择名词短语(noun phrases),调节Citespace阈值为 (2,2,20),(4,3,20),(4,3,20),选择pathfinder算法,经整理生成主题词被引频次大于10的主题词列表(见表2) 以及图2所示的国际KD研究热点领域知识图谱。
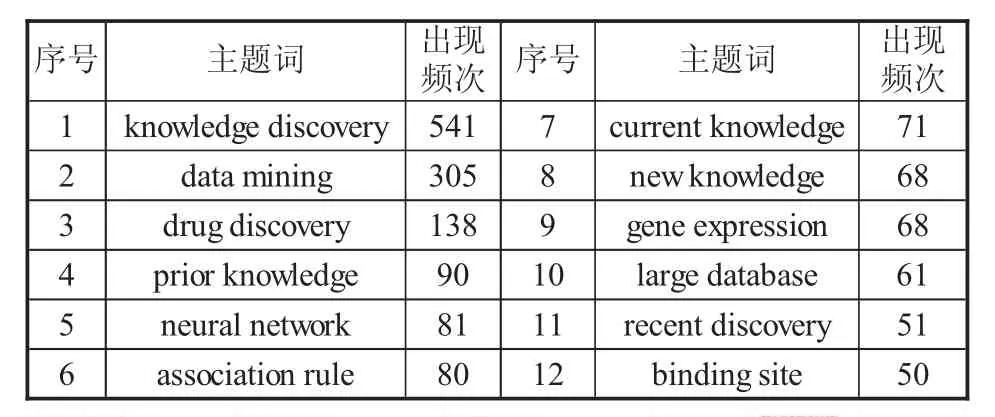
表2 “KD”研究文献出现频次〉50的主题词

图2 国际KD研究的研究热点知识图谱
图2显示的是高频关键词共现网络图,从图2和表2中可以清晰地看出,出现频次最高的主题词是knowledge discovery,出现的频次达541次;其次是datamining,出现的频次为305次,表明数据挖掘与知识发现不可分割,数据挖掘也是国际KD研究的核心和基点。高频主题词反映出国际KD研究的其他主要热点领域还包括drug discovery(药物发现)、prior knowledge(先验知识)、neural network(神经网络)、associationrule(关联规则)等。数据挖掘技术为新药发现提供一种新的思路和方法。数据挖掘技术能够帮助科研人员在大的数据库中发现隐含的知识,更好、更快、更有效地决策,增强竞争力,加快药物研发速度,提高药物研发水平。此外neuralnetwork(神经网络)、associationrule(关联规则)也是当前知识发现领域人们研究的热点。
3.3 国际知识发现的研究前沿和发展趋势
同样是针对1986—2009年发表的全部3987篇“KD”相关文献的题录数据,我们利用Citespace软件中提供的膨胀词探测(burst detection) 技术和算法,通过考察词频的时间分布,将其中频次变化率高的词(burstterm)从大量的主题词中探测出来,依据词频的变动趋势,而不仅仅是频次的高低,来确定国际KD研究的前沿领域和发展趋势。24网络节点选择为(keyterm),并选择膨胀词短语(burstphrases),阈值选择默认值 (2,2,20),(4,3,20),(4,3,20),点击探测膨胀词(findburstphrases),通过运行Citespace软件,探测出的膨胀词居于前7位的是,false discovery rate(错误发现率)、pharmaceutical industry(医药产业)、gene expression data(基因表达数据)、bindingsite(结合点位)、clusteringalgorithm(聚类算法)、genetic algorithm(遗传算法)、potential discovery(潜能发现)。可以认为,这些方向是近年来国际知识发展研究的前沿领域,代表着国际知识发现研究的发展趋势。
[1] Fayyad UM.Advances in Knowledge Discovery and Data Mining[M].AAAi/MITPress,1996.
[2] 杨炳儒,等.基于内在认知机理的知识发现理论及其应用[J].自然科学进展,2005,15(12):107互115.
[3] KrzysztofJ Cios,LukaszA Kurgan.Trendsin Data Mining and Knowledge Discovery[M].Springer Berlin/Heidelberg,2006:6互32.
[4] 孙吉红,焦玉英.知识发现及其发展趋势研究[J].情报理论与实践,2006,29(5):528互531.
[5] 黄紫菲.内容分析与知识发现的比较研究[J].情报理论与实践,2006,29(5):524互527.
[6] 靳展.基于语义Web的知识发现方法研究[D].哈尔滨:哈尔滨工程大学,2008.
[7] 杨炳儒.知识发现领域中当今面临的五类重大问题[J].中国工程科学,2008,11(11):76互83.
[8] 李进华.网格环境下的分布式知识发现研究进展[J].情报理论与实践,2009,32(11):120互124.
[9] 陈悦,刘则渊.悄然兴起的科学知识图谱[J].科学学研究,2005,23(2):149互154.
[10] 侯海燕,等.当代国际科学学研究热点演进趋势知识图谱 [J].科研管理,2006,27(3):90互96.
[11] Visualizing Patterns and Trends in Scienific Literature.[EB/OL]. [2010互03互14].http://cluster.cis.drexel.edu/~cchen/citespace/.
[12] Chen C. Measuring the movement of a research paradigm[J]. Proc.of SPIE- IST: Visualization and Data-Analysis,2005 (17互18):5669.
[13] Chen C.Searching for intellectual turning points:progressive know ledgedomainvi sualization [J].Proc.Nat.l Acad.Sc.iUSA,2004 (101) :5303互5310.
[14] ChenC.The centrality of pivotal points in the evolution of the scientific networks[C]//in proceedings of the international conference on intelligent user interfaces(IUI2005).San Diego,CA,2005:37互43.
[15] R Agrawal.Mining Association Rules Between Sets of Items in Large Databases[C].Washington:Proceedings of the ACMSIG MOD International Conference Management of Data,1993:207互216.
[16] Quilan JR.C4.5:Programs for Machine Learning[M].San Mateo,CA:Morgan Kaufman Publisher,1993:10互51.
[17] 李强.创建决策树算法的比较研究—ID3,C4.5,C5.0算法的比较 [J].甘肃科学学报,2006(12):84互87.
[18] Agrwal R,SrikanR.Fast Algorithms for Mining Association Rules in Large Databases[C].Proceedings of the Twentieth International Conference on Very Large Databases,Santiago,Chile 1994,9:487互499.
[19] 王卉,张红君.关联挖掘研究综述[J].软件导刊,2009(3):7互8.
[20] Breiman L,et al.Classification and Regression Tree[M].Wadsworth,Inc.1984.
[21] QuinlanJR.Induction of decision trees[J].Machine Learning,1986(1):81互106.
[22] Bailon-Moreno R,etal.Analy sis of the field of physical chemistry of surfactants with the unified scienc to metric mode.l fit of relational and activity indicators[J].Sciento metrics,2005,63 (2):259互276.
[23] BelvauxG,WolseyLA.Bc-prod:aspecialized branch-and-cutsystem forlot-sizing problems[J].Management Science,2000,46 (5):724互738.
[24] 栾春娟,等.国际科技政策研究热点与前沿的可视化分析 [J].科学学研究,2009,127(2):240互243.
