基于函数式中间语言的XML查询并行化
2011-07-06陈荣鑫
陈荣鑫
(1.集美大学计算机工程学院,厦门 361021;2.北京工业大学计算机学院,北京 100124)
随着网络的普及和网络服务的发展,XML作为信息交换和存储标准被日益广泛应用[1-4]。XML是半结构化数据,用户对其进行查询和变换等操作需要通过特定的语言实现。XQuery语言[5]是W3C推荐的查询XML数据的国际标准,被业界广为接受。从桌面系统、企业级Web服务到云计算平台,XQuery在各种应用场景中得到逐步推广。XQuery语言的编译和执行依靠XML查询引擎完成,各种查询的编译设计和优化措施对引擎性能的提升起关键作用[6]。
由于单机系统日益难以满足服务级的查询需求,不少研究转向多机群集系统,试图利用分布式技术来提高查询性能。S.Abiteboul等[7]开展的ActiveXML(AXML)项目把 Web服务函数嵌入XML文档中,函数调用后将把执行结果更新到XML文档中,支持各种优化和延迟求值。C.Re等[8]把 XQuery语言扩展成面向分布计算的XQueryD语言,给出分布式查询方案,支持查询迁移,以避免高代价的数据迁移。M.F.Fernàndez等[9]设计了用于分布式XML查询的DXQ语言,支持更新语义和远程异步执行。Y.Zhang等[10]结合XQuery函数和RPC规范提出XRPC,按消息传递机制实现远程调用。这些研究为用户提供分布计算的语言描述和执行环境支持,而XQuery查询并行化研究目前开展得还很有限。X.Li[11]给出一个XQuery并行化框架,由编译器完成并行化重写,但未结合XQuery语义分析典型查询条件下的情况,适用性有限。
由于多核计算环境的日益普及,并行化成为进一步提高应用程序性能的重要途径,也是软件设计和开发的趋势[12],但面向多核计算的XML并行化的有效方法还有待发展。本文关注XML查询在多核计算环境中的并行化问题,介绍XML查询相关背景,指出中间语言的作用,给出函数式中间语言pFL的语法和语义以及执行层的并行化设计,构建一个基于pFL的查询引擎,并进行实例测试,最后展望了未来的研究方向。
1 XML查询相关背景
1.1 XQuery查询语言
XQuery语言作为 XML专用查询语言,于2007年1月成为W3C正式推荐标准。由于XQuery是声明式语言,语法简洁,易学易用,而且表达能力强,适合描述各种复杂的XML数据查询,正成为主流的XML查询语言而被广为接受。XQuery的主要作用是从XML数据中查找和提取元素及属性,并重新组织XML数据输出。XQuery也支持各种算术/逻辑运算和字符串处理等其他通用数据操作。XQuery中最重要的语法结构是FLWOR语句,对应的语法元素包括for/let绑定(FL)、where谓词过滤(W)、order by排序(O)和return返回结果(R)。FLWOR语句可以嵌套使用,以构成功能强大的查询程序。
由于XQuery是一种函数式语言,程序各个部分的计算顺序无关性适合并行化处理[13],且函数式求值无副作用,正确性容易保证,因此可考虑通过重写变换实现并行化。
1.2 XML 数据模型
XML查询基本操作依赖特定的数据模型。由于处理的数据对象是半结构化的XML数据,因此XQuery使用的数据模型XDM(XQuery/XPath Data Model)[14]与传统的关系数据模型有很大差别。XDM是一种层次化、节点顺序敏感且具备唯一性的结构。XQuery的查询输入和输出均为XDM的实例,具备封闭性计算特点。XDM中包含有文档、元素、属性、文本、名字空间、指令和注释等类型的节点,同时还包含原子值节点,对应 XML Schema中定义的各种简单类型。XML查询引擎内部通过各种accessors方法存取XDM的节点序列来访问XML数据,而用户则可以通过XQuery定义的轴操作函数来访问XML数据。某些查询引擎使用了自定义的内部数据模型,以支持特定的操作,比如为了提高XQuery的处理效率,有必要支持高效的Twig查询[15],可通过为 XDM扩展内部数据表示,增加特定的XML编码描述,以支持Twig查询。
1.3 查询中间语言
XQuery语言面向开发人员,语法形式丰富且复杂,在查询引擎设计中,需要引入更为简洁的中间语言作为变法表达形式,以降低复杂性。此外,采用特定中间语言以描述查询计划,便于执行层的设计和优化实现。W3C给出的XQuery核心语法[16]可作为中间语言,不少查询引擎设计据此作为描述查询计划的方法,而某些查询引擎为了支持树查询模式[15],引入了特定的中间语言,通过中间语言的分析和重写,较易实现查询并行化处理。本文为了便于并行化处理,引入了pFL函数式中间语言。
2 pFL函数式中间语言
2.1 pFL 语法描述
pFL中间语言语法如表1所示。表中e∈Exp为表达式;id∈ID为变量或函数名;c∈Const为常量。带局部变量表达式中id=e表示变量绑定,即变量id的定义;id(id*)=e表示函数绑定,即函数id()的定义,该函数本身带有数个变量。函数调用表达式中,当id为并行原语标记时(比如PMAP、PIPELINE、PARA、PFUTURE 和 PCOND),用于描述对应的并行行为。
pFL使用PMAP描述用于数据并行操作,其功能简单表示为 PMAP(D,f)=join(map(D,fork(f)),其中:D为数据对象;f为操作任务,用fork指定线程执行任务;map用于描述数据迭代处理的基本原语,包括核心语法中 for循环绑定和where谓词过滤等对应的执行原语;join进行必要的结果排序和除重。pFL还包含流水线并行原语PIPELINE,以及2种类型的任务并行原语PARA和PFUTURE,分别用于预测(speculative)任务并行和保守任务并行。用PCOND表示pcond(e1,e2,e3),该函数支持条件表达式的预测并行化求值,对应XQuery核心语法中的if e1 then e2 else e3表达式。pFL语言是函数式的,和XQuery语言特性完全兼容。此外,该语言进一步简化了XQuery核心语法的表达方式,便于底层执行机制的实现。

表1 pFL基本语法
2.2 pFL 语义描述
中间语言通过并行原语组织,表达并行化语义;并行原语执行,实现了查询的并行处理。语义方程中的变量定义如:ρl,ρs∈Env=(id┣Val)*+(t┣Thread)*局部环境与共享环境,这里:┣表示绑定关系;id∈ID为变量/函数名称;t∈Thread为逻辑工作线程;局部环境ρl由线程、函数闭包、局部堆空间(例如本地变量、中间计算结果等)等对象组成,可带数字以区别不同局部环境;共享环境ρs包括线程池、共享堆空间(如XML-dom信息等)等。由并行原语实现并行处理,只需考虑id(e*)中出现调用并行原语的求值语义。有以下的求值语义描述,其中用[]表示表达式求值计算,用{}表示环境的内容。

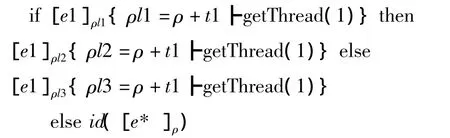
原语函数pmap、partition、getone、touch等定义了几个主要的求值规则,如下所示:
1)数据并行规则

2)数据划分规则
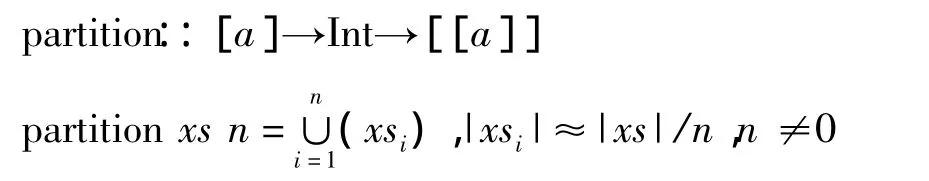
3)流水线的数据传递规则

2.3 执行层并行化设计
在共享求值环境中定义了多线程执行服务线程池 Executor exec←new Executor(),结合 Java Concurrent设计执行层的数据并行,简要的框架算法如下:


输入参数是各个数据集合信息。第1行新建一个以数据集内数据块数目为参数的计数器,用于任务同步计数;第2行获取共享环境中的多线程执行服务;第4行指派各个线程并行执行任务;第5行保证所有子任务的同步。完成所有任务后,系统将通过exec.shutdown();关闭线程服务。
3 原型系统设计
XML查询引擎通过整合并行化中间语言pFL,实现对并行查询的支持,其工作示意图如图1所示,具体包括以下工作模块。
1)词语法分析:完成XQuery源码的词法和语法分析,生成XQuery语法树。
2)规范化:实现向XQuery核心语言转换。为了降低中间语言描述的复杂性,该步骤根据XQuery语义规范[12]生成核心代码,完成语法树的预处理。
3)静态类型检查:根据XQuery的语义规范,完成静态类型检查。XQuery是强类型语言,该步骤进行类型合法性验证,完成早期程序错误检测,以提高程序健壮性。
4)依赖分析:完成基本计算的依赖分析,提供并行化的判别条件。通过分析核心语法树,找出各计算之间的相互依赖关系和数据在各计算之间的传递方式。
5)pFL重写:实现pFL查询计划重写,在适当位置使用并行原语。根据依赖分析结果,对存在相互独立的计算考虑采用任务并行;对存在数据平行迭代计算的情况考虑采用数据并行;对存在数据传递的计算考虑采用流水线。各种并行方法按重写规则进行合理组织。
6)并行执行:在执行层执行查询计划。调用并行原语函数,以实现并行处理。
7)XML解析:进行XML解析,获取DOM信息,通过包装提供查询可用的数据模型。该部分是相对独立的工作模块。
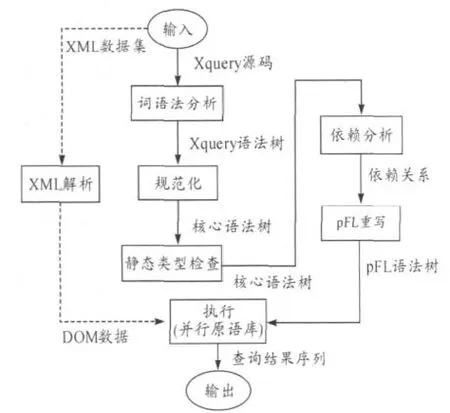
图1 XML查询引擎整合工作示意图
4 实例测试
为了测试基于pFL的原型系统在多核计算环境下的工作效果,采用典型案例,获取不同数量工作线程下的执行时间,并计算各案例的加速比。查询案例如表2所示。编写一个具有较高时间复杂度的自定义函数local:bigfun,用以模拟关键执行步。Loop程序是简单的循环绑定操作,适合进行数据并行,验证FOREACH原语的并行工作效果;Flwor程序是个典型的FLWOR语句,可以验证FILTER原语并行工作;XmarkQ是来自XMark测试平台的一个查询实例,用于测试一般的XQuery查询程序的并行化执行效果。
本文的测试硬件平台是AMD Athlon II X4 620(2.60 Ghz)4核PC,软件环境是Windows XP系统,运行JDK1.6.0_18。通过获取测试程序在各线程条件下的平均执行时间计算加速比。以程序原有的串行执行时间T1作基准,在n个线程下的解析时间为Tn,则此时的加速比Sn=Tn/T1。实验获得的加速比结果如图2所示。由于Loop是简单的循环绑定,各循环项负载容易均衡,获得了接近理想线性的加速比。XmarkQ是实际应用中的一般查询程序,在4个工作线程条件下,获得的平均加速比为3.1,效果良好。

表2 测试程序
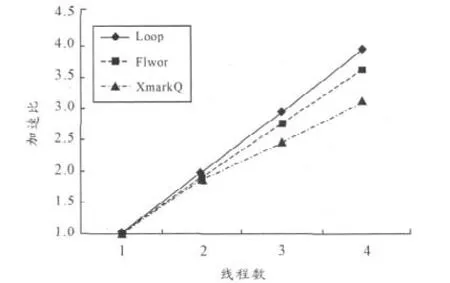
图2 加速比
5 结束语
XML查询性能的提升是现实应用中的重要需求。目前存在多种查询编译优化方法,并发展了各种适应多机系统的分布式查询方式。随着多核环境的普及,并行化作为重要优化途径值得深入研究。本文给出基于函数式中间语言pFL进行并行化的方法,通过原型系统的初步测试实验,获得较好加速比。未来的研究主要考虑引入代价模型,以便更有效地进行任务划分。通过逐步完善自动并行化的机制,实现面向多核并行计算的XML查询并行化,以满足日益增长的查询性能提升需求。
[1]朱庆生,戴刚.基于XML的安全数据交换模型[J].重庆工学院学报:自然科学版,2009,23(6):36-39.
[2]汪维华,汪维清,李灵.基于XML的Web模型研究[J].重庆文理学院学报:自然科学版,2006,(5)4:16-19.
[3]罗凌.XML数字签名在电子公文交换中的应用[J].重庆师范大学学报:自然科学版,2008,25(2):46-49.
[4]刘长勇,宁正元.基于XML的高性能数据库连接池设计方案[J].重庆工学院学报:自然科学版,2009,23(2):176-180.
[5]Boag S,Chamberlin D,Fernández M F,et al.XQuery 1.0:An XML query language[EB/OL].[2011 -04 -10].http://www.w3.org/TR/xquery/.
[6]孟小峰,王宇,王小锋.XML查询优化研究[J].软件学报,2006,17(10):2069 -2086.
[7]Abiteboul S,Benjelloun O,Milo T.The Active XML project:an overview[J].The VLDB Journal,2008,17:1019-1040.
[8]Re C,Brinkley J,Hinshaw K,et al.Distributed xquery[C]//Workshop on Information Integration on the Web.Citeseer:[s.n.],2004:116 -121.
[9]Fernández M F,Jim T,Morton K,et al.DXQ:A distributed XQuery scripting language[C]//Proceedings of the 4th international workshop on XQuery implementation,experience and perspectives.[S.l.]:ACM,2007:1 -6.
[10]Zhang Y,Boncz P.XRPC:interoperable and efficient distributed XQuery[C]//Proceedings of the 33rd international conference on Very large data bases.[S.l.]:VLDB Endowment,2007:99 -110.
[11]Li X.Efficient and parallel evaluation of XQuery[D].Columbus:The Ohio State University,2006.
[12]Sutter H.The free lunch is over:A fundamental turn toward concurrency in software[EB/OL].[2011 -04 -10].http://www.gotw.ca/publications/concurrencyddj.htm.
[13]Hammond K.Parallel functional programming:An introduction[C]//International Symposium on Parallel Symbolic Computation.Citeseer:[s.n.],1994.
[14]Fernández M F,Malhotra A,Marsh J,et al.XQuery 1.0 and XPath 2.0 Data Model(XDM)[EB/OL].[2011 -04 -10].http://www.w3.org/TR/xpath-datamodel/.
[15]Bruno N,Koudas N,Srivastava D.Holistic twig joins:optimal XML pattern matching[C]//Proceedings of the SIGMOD Conference.[S.l.]:[s.n.],2002:310 -321.
[16]Draper D,Fankhauser P,Fernández M F,et al.XQuery 1.0 and XPath 2.0 Formal Semantics[EB/OL].[2011-04 - 10].http://www.w3.org/TR/xquery-semantics/.
