视频镜头显著性提取技术
2011-06-29墨洁,魏维
墨 洁, 魏 维
(成都信息工程学院计算机系,四川成都610225)
1 引言
随着互联网上多媒体信息的迅速膨胀,媒体数据的信息需求量迅速增长,视频中关于动态和静态的信息量也迅速增长。人们对于较复杂的场景镜头的提取技术一直都在探索中,在视频技术中,静态模型的提取技术已经发展到成熟的地步,在20世纪初,由ITTI等人提出的基于显著度(saliency-based)的注意计算模型,首先融合图像的一些低层视觉特征生成显著图(saliency map),然后使用一个动态的神经网络按照显著度递减的顺序依次发现图像中的注意点。此方法比较适用于静态的显著计算,而20世纪中期,Stentiford等人[1-2]也在研究如何将由生物启发的视觉注意力模型应用到图像检索中,其图像的显著性用视觉注意力图(visual attention map)表示。随着复杂场景下图像分析的进展,在动态图像显著性提取中的发展中以基于运动优先的注意力模型为主线进行了探讨,但是以上研究只是针对与镜头静态模型和动态模型分开来进行研究,忽视了提取技术的整体性。研究目的就是针对这些复杂镜头下的图像进行动态和静态模型相融合的方式,采用动静结合的提取技术来实现以上目的。
2 提取静态图像显著性的视觉注意力模型
检测技术发展到近阶段,根据生物机制对视觉场景的特点提出了基于视觉注意机制提取的方法,方法[3]主要是以ITTI算法最具代表性,其框架图如图1所示。
ITTI框架模型描述[4]将在图像中初始图像通过高斯线性滤波提取出最底层特征:颜色特征、方向特征、亮度特征。通过高斯金子塔中央周围操作算子[5](center-surround)形成了12张颜色特征图,6张亮度特征图,24张方向特征图,将这些特征图进行标准化操作N(),得到各特征值组成的关注图,分别是颜色、亮度、方向关注图。这3个特征图经过 S函数。S()=1/3*[(N(I)+N(O)+N(C)]合成显著图,通过两层赢者取全神经网络[6](winner-take-all,WTA)得到显著区域,最后通过返回抑制机制(inhabitation of return),抑制当前的显著区域,转而寻找下一个显著区域,得到相应的显著区域。选择注意的注视点就是显著图中的极大值点,选择注意区域就是以注视点为中心的固定半径的圆形区域,显著度值越大越先被注意。
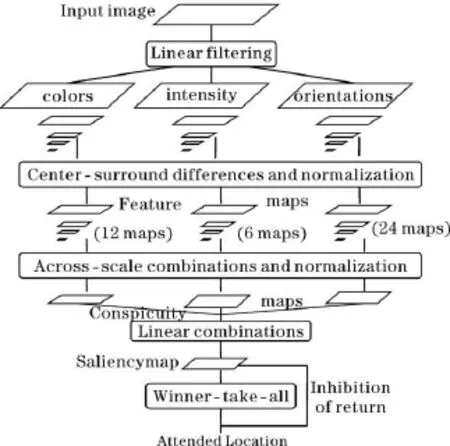
图1 模型ITTI的流程框架
3 基于运动特征的动态显著图提取
视觉机制是在对整个场景初步感知[7]的基础上形成的,人们对视频镜头的感知也分为空间上和时间上两部分,有效地将时间和空间进行动态融合对于视频注意区域的生成有着重要的影响。在已有的动态特征图提取技术[8]方法中加入一个新的元素将方向上的反差也考虑其中,4个方向上视觉上的反差,更有益于动态特征图的提取,采用加权思想在运动场景角度发生剧烈变化时,提高运动方向特征上的权重,缩小在运动速度上的权重,分别提取出运动方向上的4张特征图和1张速度特征图,通过小波融合技术,将运动速度和运动方向进行融合形成动态特征图。
根据对视频镜头中动态特征的分析,动态特征流程框架如图2所示,首先根据块匹配算法[9],在相邻帧中一定范围的搜索区域内,按照匹配准则,寻找最为相似的块作为预测块。前后帧之间匹配块位移的大小即可说明宏块运动的剧烈程度。搜索范围就可根据运动的剧烈程度进行调整以获得精确的匹配,根据复杂度较小的绝对差和准则(SAD)作为匹配准则,其数学表达式定义为
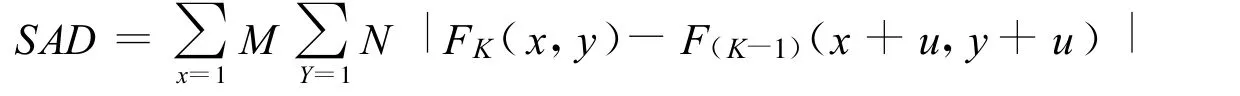
同时将各像素的运动矢量在 0°,45°,90°,135°这 4个方向上投影 ,生成 4 个运动方向图(x=0°,45°,90°,135°)来反映各个像素在运动方向上的位移。位移的变化越大,说明宏块前后的差别越大,相邻两帧的宏块的水平和垂直位移运动矢量变化越大。根据运动矢量的计算结果,可以得到相邻两帧图像中每个像素点运动距离,生成一个运动速度图来反映图像中各像素的运动速度。对于提取出来的运动速度与运动方向特征图,分别构造高斯金字塔,得到不同分辨率下的特征图,金字塔底部的图像分辨率较高,而金字塔顶部的图像分辨率较低,其中每个像素均可看作是与原图位置相对应的区域,中心点与其周围区域的反差通过处于金字塔不同层的图像差减来计算。
通过匹配算法[6],可以得到一个水平和垂直位移的运动矢量,根据运动矢量的运算结果,得到相邻两帧之间宏块或每个像素点的运动位移,并得到各像素的运动速度,表达式为:
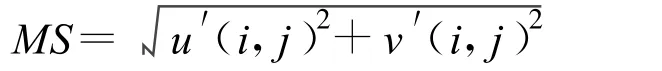
其中,MS是相邻两帧之间像素点的运动长度,u是指水平方向上即在0°方向上投影的位移,v是指垂直方向上即在90°方向上投影的位移。将各像素点在0°,45°,90°、135°这4个方向的投影,生成4个运动方向上的位移M00(i,j)、M045(i,j)、M090(i,j)、M0135(i,j),根据这4个方向上位移,通过高斯金字塔的低通滤波,然后进行中央-周围算法操作,

其中c表示中央尺度,s表示边缘尺度,c∈{2,3,4),其中运算符Θ表示金子塔不同层之间即尺度不一样的图像之间进行差值操作。
将上述操作得到的5张特征图进行标准化处理 N()进行融合,最后得到运动速度显著图和运动方向显著图,最后通过小波融合计算得到运动图像的总体显著图。
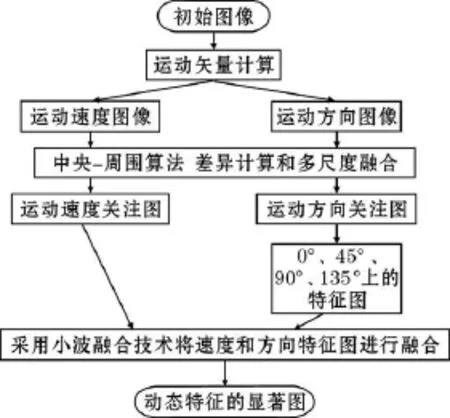
图2 动态特征提取的框架流程说明
引入运动方向这个元素,使得动态特征图的提取效果更接近于对人眼反应最刺激的区域的提取,可以采用如图3所示的提取技术和流程,视频镜头是在水面上匀速行驶的3艘船,提取出包含镜头信息量最多的关键帧,将此帧根据中央周围算法提取在0°特征点上的图像,可以明显看出白色亮光所在是吸引人注意的区域,同样,在其余3个方向分别按照相同的方法提取出来,因船行驶方向是水平的,因此在0°上的运动反差是最大的,垂直方向上没有任何变化,因此图像没有亮光点所在,均为黑色背景。
4 动静结合显著性区域
利用人的视觉对场景感知的特点,在提取了以上动态显著图和静态显著图后,提取出一种基于运动优先时空混合思想并给出一种自适应时空动态混合方法[10],这种方法的策略是:依靠运动反差来控制运动显著图和空间显著图的权重,当检测到运动方向上的反差加强并占据优势时,把运动显著图上的权重迅速加强,空间显著图上的权重迅速减小,当运动反差达到一个平稳的状态时,提高空间上的权重时,它的混合表达式
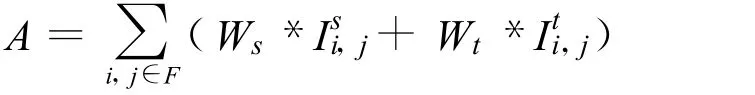
其中,Wt、Ws分别为空间和时间显著度权重,采用固定权重值无法自适应根据视频内容变化调整运动和空间显著度比例,其中F定义为关键帧的区域,Ii,j表示空间域上的亮度值,公式中重要的两个参数Ws,Wt分别为动态特征显著图和静态特征显著图的权重值。
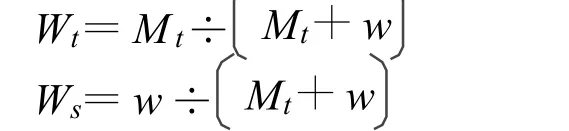
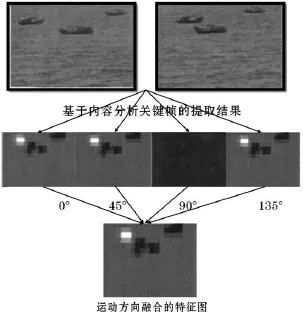
图3 引入运动方向元素的提取实验效果
其中 w 取值 0.3,如图 4曲线所示,Mt在取到 0.3时,Wt、Ws交汇到一个点上,两个显著图上权重值是相同的,该方法的优点是相比以前的技术,较灵活的运用权重值的增减来控制动态和静态特征图在融合时占的比重范围,在提取运动特征时不会受到低纹理、光流等因素影响,计算量比较小,速度较快,而且一般情况下,在光流场和像素域上直接分析运动特征时,会包含较多的随机噪声,这种提取方法可有效抑制噪声,这是突出显著的地方。
5 实验验证对比结果

图4 基于运动优先的动态显著图和静态显著图的融合
根据运动特征中的运动速度和运动方向这两个特点,结合中央周围算法,将视频镜头依据内容分析方法提取出能代表图像信息量最多的关键帧,将此关键帧通过线性滤波高斯金字塔提取出在0°,45°,90°,135°这4个方向上的关注图,将这4个关注图进行标准化融合生成图像在运动方向上的特征图并结合提取出的运动速度特征图,最后生成动态情况下图像的显著区域,根据运动方向的特征图并结合运动速度特征图得到的实验验证对比图如图5所示。
截取第2节中海面上行驶的3条小船水平匀速向右行驶,可以发现在图片最左边的船速明显高于中间船的速度,视频镜头压缩的第2帧中就超过了中间行驶的小船,根据前面探讨的动态特征提取方法:以运动速度和运动方向作为两条线索得到各自的显著图,通过小波融合分析算法最后得到动态上的显著图,通过赢者取全和返回抑制算法得到动态图像中的FOA(Focus Of Attention),依次用圈标注先后注意的次序,通过本文得到的FOA区域与通过ITTI模型得到的FOA相比较,可以发现最刺激人类注意的区域1是不相同的,而文中提出的模型方法更接近于人类视觉机制的选择。
5个小球匀速向右运动,中间部位的小球相较周围4个小球速度最快,通过视频压缩得到的一些关键帧去比较,实验验证对比结果如图6所示。

图5 实验验证对比图一

图6 实验验证结果对比图二
实验中处于中间位置的小球以较快的速度水平向右滚动,则根据文中提取的技术得到了运动方向显著图、运动速度显著图,最后通过返回抑制和赢着取全得到了图像中的FOA区域,很明显此区域最接近人类视觉上的刺激选择。
6 结束语
借鉴了生物视觉机制的研究成果,引入了一种根据运动速度和运动方向融合提取的动态特征显著图,并结合现有的空间显著图提取技术IT TI模型中的算法,通过运动优先时空混合思想的结合方法,将两者紧密融合成视频镜头的显著性提取。
在视觉注意计算模型中,如何更好的去利用人类视觉生物机制去提取显著区域,快速从海量的信息中得到用户感兴趣的信息,以及在各种不同的场景下都能稳定提取出动态的显著区域都是有待进一步研究的问题。
[1]Stentiford F W M.An Attention Based Similarity Measure with Application to Content Based Information Retrieval[C].In Proceedings of the Storage and Retrieval for Media Databases conference,SPIE Electronic Imaging,Santa Clara,CA,2003.
[2]Bamidele A,Stentiford F W M.An Attention Based Similarity Measure Used to Identify Image Clusters[C].In Proceedings of 2nd European Workshop on the Integration of Knowledge,Semantics&Digital Media Technology,London,2005.
[3]Itti L,Koch C,Niebur E.A model of saliency-based visual attention for rapid sceneanalysis[J].IEEE Trans on PAMI.1998,20(11):1254-1259.
[4]Itti L,Koch C.Computational Modeling of Visual Attention[J].Nature Reviews Neuroscience,2001,2(3):194-203.
[5]蒋鹏,秦小麟.基于视觉注意模型的自适应视频关键帧提取[J].中国图像图形学报,2009,14(8):1650-1655.
[6]高静静,张菁.应用于图像检索的视觉注意力模型的研究[J].测控技术,2008,(2):19-21.
[7]张菁,沈兰荪,高静静.基于视觉注意模型和进化规划的感兴趣区域检测方法[J].电子与信息学报,2009,31(7):1646-1652.
[8]Zhiwen Yu,Hausan Wong.A Rule Based Technique for Extraction of Visual Attention Regions Based on Real-Time Clustering[J].IEEE TRANSACTIONS ON MULTIMEDIA,2007,9(4):766-784.
[9]L G Ungerleider,J V Haxby.What and where in the human brain[J].Current Opinion in Neurobiology,1994,4:157-165.
[10]Milancese R,G il S,et al.Attentive mechanisms for dynamic and static scene analysis[J].Op t Eng,1995,34(8):2428-2434.
[11]Bulthoff H H,Lee S W,Poggio T,et al.Biologically Motivated Computer Vision[M].New York:Springer Publishing Company,2003:150-159.
[12]Huang L,Pashler H.Working memory and the guidance of visual attention:Consonance-driven orienting[J].Psychonomic Bulletin&Review,2007,14(1):148-153.
[13]蒋鹏,秦小麟.一种动态场景中的视觉注意区域检测方法[J].小型微型计算机系统,2009,36(3):494-499.
[14]F Liu,M Gleicher.Region enhanced scale-invariant saliency detection[J].In Proceedings of IEEE ICME,2006.
[15]Tie Liu,Jian Sun.Learning to detect a salient object[J].IEEE Computer Society Conference on Computer Vision and Pattern Recognition(CVPR2007),2007:1-8.
[16]Liansheng ZHUANG,Ketan TANG,Nenghai YU.Fast Salient Object Detection Based on Segments[J].International Conference on Measuring Technology and Mechatronics Automation of IEEE,2009:469-472.
[17]K RDobkins,T D Albright.What happens if changes color when it moves:The nature of chromatic import to visual Area MT[J].Journal of Neuroscience,1994,14(8):4854-4870.
[18]Jiawei Chen,Kunhui Lin,Changle Zhou.A Visual Attention Model for Dynamic Scenes Based on Two-Pathway Processing in Brain[A].Fourth International Conference on Natural Computation[C],2008:128-132.
[19]M Kim,JG Chou,D Kim,et al.A VOP generation tool:automatic segmentation of moving objectsin image sequences based on spatial temporal information[J].IEEE Trans Circuits Syst.Video Technol,1999,9(8):1216-1226.
[20]Y Tsaig,A Averbuch.Automatic segmentation of moving objects in video sequences:a region labeling approach[J].IEEE Trans.Circuits Syst.Video Technol.,2002,12(7):597-612.
[21]V Mezaris,I Kompatsiaris,M G Strintzis.Video object segmentation using Bayes-based temporal tracking and Trajectory-based region merging[J].IEEE Trans.Circuits Syst.Video Technol,2004,14(6):782-795.
[22]Junwei Han.Object Segmentation from Consumer Videos:A Unified Framework Based on Visual Attention[J].IEEE Transactions on Consumer Electronics,2009,55(3):1597-1605.
[23]Ma YF,Hua X S1 A generic framework of user attention model and its application in video summarization[J].IEEE Transactions on Multimedia,2005,10(7):907-919.
[24]Yun Zhai,Mubarak Shah Visual attention detection in video sequences using spatiotemporal cues[A].In Proceedings of 14th Annual ACM International Conference on Multimedia[C],Santa Barbara,CA,USA,2006:815-824.
[25]桑农,李正龙.人类视觉注意机制在目标检测中的应用[J].红外与激光工程,2004,33(1):38-41.
[26]叶聪颖,李翠华.基于HIS的视觉注意力模型及其在船只检测中的应用[J].厦门大学学报:自然科学版,2005,44(4):484-488.
