基于支持向量机与余弦夹角法的中文网页过滤的研究与设计
2011-06-29杨义先
胡 迪, 陈 运, 杨义先, 陈 悦
(1.成都信息工程学院信息安全研究所,四川成都610225;2.北京邮电大学信息安全中心,北京100083)
1 引言
网页过滤可以嵌套在基于安全网关网络(Secure Internet Gateway,SIG)上,提供给移动、联通等运营商。重点过滤色情、赌博、毒品、低俗等对青少年危害较大的一些网页。营造一个安全、绿色的上网环境。
中文网页过滤首先要经过分词。目前常用的分词技术有Httpcws、Paoding、ICTCLAS[1](Institute of Computing Technology,Chinese Lexical Analysis System)等。

表1 分词方法对比
根据表1对各种分词方法的比较,采用由中国科学院张华平教授等开发的开放源码分词系统ICTCLAS,在其基础上添加去禁用词模块,通过实验在windowsXP系统上使用C++语言实现。
特征选择是通过频数(Document Frequency,DF)信息增益(Information Gain,IG)、互信息(Mutual Information,MI)、χ2(亦为CHI)统计等特征评估函数实现。

表2 特征评估函数对比
如表2所示各种特征评估函数都有其优缺点,根据分类对色情、毒品等类别关注度高的特点,通过DF保留到达一定次数的特征,再通过MI将DF过滤的特征将类别相关性高的特征保留的方法实现特征提取。
2 基于SVM与余弦夹角法的网页文本过滤流程
SVM(Support Vector Machine)[2]方法适合大样本集的分类,特别是文本分类。基于结构风险最小化原理,将原始数据集合压缩到支持向量集合,然后用子集学习得到新知识,同时也给出由这些支持向量决定的规则。近年来不少学者对SVM在分类应用中进行不断完善和改进。SVM主动学习策略[3]和直推式算法[4]来解决大规模语料库消耗大量人力和时间;在SVM学习过程中加入文本的先验知识[5]改善学习模型的泛化能力。文章采用自适应C-支持分类向量机。
哈尔滨工业大学郑德权[6]利用基于模板匹配的相似度计算Blog网页相似度,很好的区分blog网页和其它网页。文章以色情网页为例,运用余弦夹角法过滤掉色情、毒品等对青少年危害较大的网页。
基于SVM与余弦夹角法的网页文本过滤是先对总库中的URL进行判断,如果是以文字为主采用的分类算法是支持向量机SVM。如若不是就通过基于网页结构的余弦夹角法就是分类。具体实现如图1所示。
3 基于SVM的网页文本分类
3.1 去禁用词的ICTCLAS分词法
ICTCLAS是基于5层隐马模型的系统。原始的中文字串根据分隔符、回车换行符进行断句形成短句。把短句切割成不可再分割的最小语素单位即为原子分词。原子的所有可能的组合再进行 N-最短路径粗切分,粗切分结果通过简单未登录词识别之后又进入嵌套未登录词中识别阶段。再通过基于类的隐马分词和词类的隐马标准得到词法分析结果。文章除原有词库外,添加一个禁用词词库。在此系统基础上将第4层HMM中添加去禁用词(副词、介词、连词等虚词)功能。在程序运行初,先把原有词库和禁用词词典均加载到内存中,以提高访问的速度。去除禁用词算法如下:
(1)输入中文字串L;
(2)输出中文字串 L′;
(3)Begin;
(4)While L≠Φ;
(5)flag=isInStopWordList();
(6)If(flag==ture)
(7)delete();
(8)End.
原始中文字串“一朵朵的牡丹很漂亮”用原始ICTCLAS分词之后变为:
一朵朵/m的/u牡丹/n很/d漂亮/a
通过去禁用词之后分词结果为:
一朵朵/m牡丹/n漂亮/a
这样去除了对文本分类没有作用的词,降低了维度,提高分类速度。
3.2 特征处理
经过预处理分词后得到的关键词集合就是特征集。频率统计、降维技术和特征权重等特征处理技术是对特征集中的特征进行频率统计,然后去除弱关联词,保留强关联词构成用于学习的特征集,给这些特征赋予不同的权重,表示特征对文本的重要程度。
3.2.1 改进的TF-IDF统计方法
TF-IDF(Tenn Frequency-Inverse Document Frequency)通过突出重要特征、抑制次要特征的方法评估某特定特征对一个文件集或者语料库中的其中一份文件的重要程度。对于Web文档,特征词在不同位置对文档内容的反映程度不同,因此权重的计算方法应该体现HTML的结构特征。由于TF-IDF没有体现出特征的位置信息。所以提出一种改进的TF-IDF方法对处于网页不同位置的特征词赋予不同的系数,再乘以特征词的词频来提高文本表示的效果。TF-IDF权重计算公式表示为:

图1 基于SVM和余弦夹角法的网页过滤流程图

式中 TFij码是特征词tj在文本di中的词频;DFj为训练集中出现特征词tj的文档频率;N为训练集的文本总数;θ为权重系统且 0<θ<1,k 为特征出现位置(url、title、keywords、description、subtitle、content)。
3.2.2 基于DF和MI的特征提取
基于DF和MI的特征提取首先根据文档频率计算特征词在类别中出现频率,计算公式如(2)式所示:

其中DFt是特征词t在类别c中出现的文档数量;Nc是c中的文档总数。然后设置阈值Dmin,将(2)式中计算的DF(t,c)与之比较。大于Dmin直接保留。小于Dmin再通过MI计算特征与类别之间的相关性。如(3)式所示:

其中t,c分别表示特征和类别
为了计算简便,(3)式可转化为:

其中N为训练集中包含的文本总数;A是t,c同时出现的次数;B只指出现t的次数;C是只出现c的次数。最后设置阈值D′min,将(4)式中计算的 MI(t,c)值大于D′min值保留。
3.3 向量空间模型表示文本
将通过DF和MI综合考虑提取的特征作为特征项,并赋予一定的权重。那么一个文本可以表示成 d=(w1,w2,…,wi),wi为第i个特征词ti对应的权重。用向量空间模型VSM(Vector Space Model)表示文本。文本表示为赋予权重的特征词的集合。即为构成特征空间的一个向量。具体表示方法为:

3.4 SVM分类实现
步骤1:确定训练集
分类类别数已经确定,并设其值为 M(M ∈N+)。对于给定训练集 T={(dj,Mi)}其中dj={(t1j,w1j),(t2j,w2j),…}表示第 j个文本;表示第i(i=1,2,3,…,M)个分类。需找到一个决策函数 f(dj):dj→Mi,用以推断任意输入文本dj对应的分类Mi。
邓乃扬、田英杰等认为成对分类方法以及一类对多类分类方法不适合文本分类[7]。前者需求解(M-1)◦M/2个两类问题,计算量大。后者的缺点为考虑的两类问题往往不对称会引起误差。使用自适应惩罚因子C。即为惩罚因子随训练点的不同而不断调节。原问题变为:

图2 基于DF和M I的特征提取流程图

步骤2:选择核函数以及惩罚因子
由于文本数据具有特点不明确、数据量大等特点。而高斯函数处理数据速度快,适应新数据能力强,学习能力较强。所以本文采用高斯函数作为核函数。惩罚因子是为了平衡训练误差和间隔。对于较少的正类选取较大的惩罚因子C。
步骤3:构造、求解凸二次规划

步骤4:确定 b

步骤5:构造决策函数

4 基于余弦夹角法的网页过滤
针对色情等重点关注类采用网页结构相似度计算方法进行再次验证。以色情类为例,具体实现如下:
步骤1:提取色情网页的结构特征
色情网页有很大的相似性。这些相似性主要体现在:(1)设置风格相同或者相似;(2)采用同一类逻辑(列表或者表格)对象进行表示;(3)在页面内容的组织上,通过相同的静态关键字标识同一数据项取值。
步骤2:页面相似度计算
运用余弦夹角法计算页面相似度。

其中sim(di,dj)为余弦值,反映文本i与文本j的相似度,sim(di,dj)越小相似度越高;wik表示第k个特征词在文本i中对应的权值;
wjk表示第k个特征词在文本j中对应的权值。
步骤3:设定阈值Dsim(di,dj)
具体方法为将已经分类准确的网页作为训练集,得到Dsim(di,dj)T,然后再从待分类样本中随机抽出3/10的作为测试集不断修正确定出
5 实验结果及分析
在URL总库存在情况下对已经校对正确过的10个类别(每个类别各100条URL)进行实验。实验过程中分别采用一般SVM方法和基于SVM与网页结构结合的网页过滤方法。得到结果如表3和表4所示。

表3 一般SVM分类
从表3可以看出此分类器对计算机、时尚、生活等类识别准确率较差。对色情类识别能力虽然比较高,但由于色情类是重点关注类,所以没有达到理想效果。
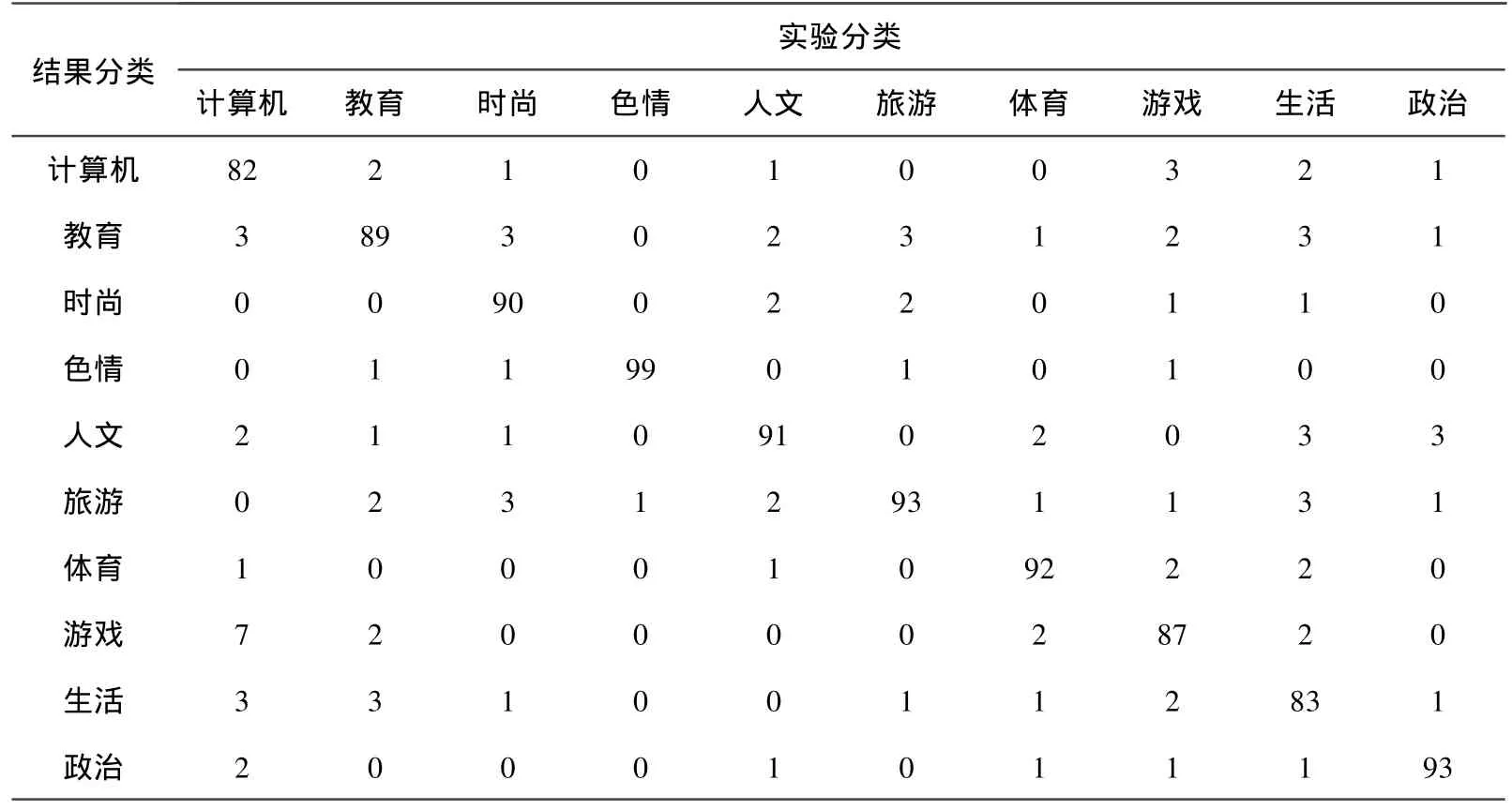
表4 基于SVM和余弦夹角法分类
表4是利用基于SVM与网页结构结合的余弦夹角方法对网页进行识别。从表中可以看出此方法对各个类别的识别率都有提高。特别是色情网页的识别率高达99%。

表5 准确率对比
从表5可以看出表4的方法在时尚、色情、生活这3个类比表3识别率明显提高。而这3个类有一个共同点就是网页结构有一部分是由很少的文字以及大量的图片构成。所以基于SVM与网页结构相结合的余弦夹角方法对大量图片组成的网在页识别率方面占有一定的优势。
6 结束语
对Web文本分类作了较为深入的阐述和分析,实现了一种能够很好区分色情等对青少年危害较大的网页分类方法。在ICTCLAS系统基础上添加去禁用词功能,并采用DF和MI综合考虑实现特征提取。根据色情网页结构上相似的特点,采用SVM与网页结构结合的余弦夹角方法进行网页过滤,初步实验获得较好效果。在今后工作中,将添加语言识别功能模块,并将其应用到毒品、犯罪等网页分类,并不断改进,以获得更好的分类识别效果。
[1]屈培,葛秦.Nutch-0.8.1中二分法中文分词的实现[J].计算机时代,2007,22(7):9-11.
[2]Vapnik V.The Nature of Statistical Learning Theory[M].New York:Springer-Verlag,1995.
[3]Tong S,Koller D.Support vector machine active learning with application to text classification[J].Journal of Machine Learning Research,2002,2(1):45-66.
[4]卢增祥,李衍达.交互学习算法及其在文本信息过滤中的应用[J].清华大学学报,1999,39(7):93-97.
[5]李辉,史忠植,许卓群.运用文本领域的常识改善基于支持向量机的文本分类器性能[J].中文信息学报,2002,16(2):7-13.
[6]郑德权,张迪.Blog网页分类与识别技术研究[J].通信学报,2007,28(12):28-32.
[7]邓乃扬,田英杰.支持向量机-理论、算法与扩展[M].北京:科学出版社,2009:189-191.
