汉语缩略语自动处理研究现状
2011-06-28王厚峰
王厚峰
(北京大学 信息科学技术学院,北京 100871;北京大学 计算语言学教育部重点实验室,北京 100871)
1 引言
缩略语是自然语言中的一种典型现象,广泛存在于不同语言中。例如,汉语中的“非典”是由“非典型性肺炎”缩略的,对应于英语的缩略语“SARS”则来自于完整形式“Severe Atypical Respiratory Syndrome”;日语中的“健保連”由“健康保険組合連合会”缩略而成;德语的“KGI”由“Katholische Glaubensinformation”缩略而成;法语的“RDI”由“Le Réseau d’Information”缩略而成[1]。据统计,在汉语新闻文章中,有大约20%的句子可能含有缩略语[2-3]。自然语言处理毫无疑问地不能避开缩略语问题。
所谓缩略语,在构形上是一个或多个词经过压缩和变序而形成的长度缩短,意义不变的特殊“词”。压缩之前的形式称为完整形式、原形语或者定义式。
上述定义是非形式化的。虽然语言学上已有相当多的研究,但目前并没有被广泛认可的缩略语形式化定义或界定准则。我们知道,汉语词的界定缺乏形式准则,缩略语的界定同样如此,而且缩略语与普通词之间的界限还存在模糊。如“美”既可以是普通词又可以是“美国”的缩略;并且不少缩略语也会固化为普通词,例如,由“铁车路”缩略而成的“铁路”以及由“高等学校统一招生考试”缩略成的“高考”,现在大多不再认为是缩略语。因为缩略语界定有一定的难度,所以使缩略语的处理在一开始就遇到了很大困难。对汉语而言,缩略语的界定是缩略语识别的基础,而缩略语的识别直接影响词切分的性能。缩略语是未登录词的主要来源,有分析认为,未登录词造成的切词精度失落比歧义切分精度的失落大5.6~14.2倍[4]。
同其他的未登录词一样,缩略语还会导致自然语言处理的其他困难,甚至还会造成理解上的障碍。例如,在1998年1月2日的《人民日报》中一篇文章上有这样一句话: “中国还广泛认真地参与了联合国大会有关人权、裁军、维和、经社、环发和科技等总计160多项议题的审议”,在本句中,人们也不容易在所给的这一局部上下文理解缩略语“经社”和“环发”。
理解缩略语的关键是确定对应的完整形式。完整形式很可能与缩略语同现于上下文,此时的理解就是建立彼此间的关联,即所谓的衔接[5];但并不是在所有情况下,两种形式都会同时出现在上下文中。为了解释这类缩略语,还需要有一部缩略语与完整形式的对照表。然而,两者之间并不总是一对一的关系,例如,“人大”可以是“人民代表大会”,也可以是“中国人民大学”。对于这样的情况,还需要进行 “词义消歧”;当然,这类现象在英语中更突出。例如,缩略语 CIA除了表示美国中央情报局(Central Intelligence Agency)以外,还可以表示很多其他的完整形式,2010年8月初通过英语缩略语网站 http://acronymfinder.com 查询缩略语“CIA”,结果返回了110个完整形式。
缩略语对信息检索之类的典型应用也有很大的影响。有的文档可能只含有检索项对应的缩略语,有些可能只含有完整形式。如果用户给出的检索条目只有其中一种形式,就会导致目标文档的漏检。我们曾在一个月份的《人民日报》语料上检索“欧洲经济与货币联盟”,只检索到了约20%的目标文档,漏检的目标文档不含有“欧洲经济与货币联盟”,只含有缩略语“欧盟”。当然,为了减少漏检,可以同时输入两种形式的检索项,但这样无疑会加重用户的负担。特别是有的完整形式可能对应着多个缩略语,如“中央电视台”可以缩略为“中央台”或者“央视”;有的还可以多重缩略。例如,“道·琼斯股票价格平均指数”缩略成“道·琼斯指数”,还可以进一步缩略为“道指”。
缩略语与完整形式之间多对多的关系也不少见。在百度上分别使用检索词“华师”,“华师大”搜索,结果发现这两个缩略语都被大量使用,而且都可以是“华东师范大学”、“华中师范大学”和“华南师范大学”;此外,三所大学分别还可以有缩略语“华东师大”、“华中师大”和“华南师大”。这种多对多的关系如图1所示。

图1 多缩略语与多完整形式对应关系
上述分析表明,无论作为一种典型的语言现象本身,还是对语言分析的影响以及实际的应用需求,都要求对缩略语问题展开深入系统的研究。目前从计算的角度开展的研究相对还不多,但不乏有一些值得总结的方法。本文的主要目的是针对汉语的缩略语处理研究的现状和问题进行分析。为借鉴其他语言缩略语处理的方法,本文还简要总结了英语缩略语的研究现状,并比较了两种语言缩略语在处理上的差异。
2 缩略语的使用与生成
一般认为,缩略语与完整形式之间具有等价关系,但事实上,两者至少在用法上存在差异。例如,“物超所值”的缩略语“超值”,可以用于“这套家具十分超值”,但几乎不能替换成“这套家具十分物超所值”。马庆株先生对缩略语功能和性质作了研究[6],他认为:
(1) 缩略语既是常用的,又是定型的。常用体现为它在一定时期、一定范围内经常会被使用,有的缩略语在一段时间的使用之后甚至取代了其完整形式的地位,如“高中(高级中学)”、“铁路(铁车路)”等。定型则体现在缩略语一旦确定就很难改变。
(2) 大部分缩略语受到时空限制,少数被长期广泛使用。有的缩略语具有地域性、行业性,例如,“第一汽车制造厂”在长春常被简称作“汽车厂”,而全国范围内则一般被简称作“一汽”;同样,合肥的“科大”指“中国科技大学”,长沙的“科大”则指“国防科学技术大学”;此外,“清华大学”,在大陆缩略成“清华”,而在台湾缩略成“清大”。
(3) 缩略是形成新词的一种重要手段,新的缩略语每天都在产生,因而缩略语具有开放性,并且数量巨大。
从完整式向缩略语变换有三种主要形式: 缩合、截略和统括[7]。
所谓缩合,是指将完整形式按意义分成几个部分,然后从各部分中抽取最能代表原义的语素(或词)保留,省掉其他部分。例如,“邮编(邮政/编码)”、 “政协(政治/协商/会议)”、“老少边穷地区(老区、少数民族地区、边疆地区、穷困地区)”、“特别联大(联合国/大会/特别/会议)”和“中西医(中医、西医)”。
所谓截略,是指在完整形式中,直接截取其中某个连续的子串作为缩略语。例如,“清华(清华大学)”、解放军(中国人民解放军)”和“也门(阿拉伯也门共和国)”。
所谓统括,是指把完整形式的并列短语中原词语所共有的一个词或语素抽取出来,然后在它之前加上表示原词语数目的数词或数量短语,省略其余部分。例如,“两汉(西汉、东汉)”和 “三老(当老实人、说老实话、办老实事)”。
上述的三种变换形式涵盖了大部分的对应关系,但有些缩略语并不简单的由某种对应关系产生。如“参众两院(参议院、众议院)”和“四总部(总参谋部、总政治部、总后勤部、总装备部)”,都不能单独采用上述任何一种方式生成。此外,缩合和截略之间有时具有交叉性,例如,“甘(甘肃)”和“清华(清华大学)”从构词上看实际是两种很不一样的缩略方式——“甘”不是一个可成词的成分,而“清华”在一定程度上可以认为是一个可成词的成分,从这个角度看,“甘(甘肃)”似乎更适合归入“缩合”而非“截略”。
3 汉语缩略语处理的现状
3.1 缩略语处理分类
自然语言处理在词层面上的两个关键问题是识别与解释,而缩略语的解释很大程度上依赖于其完整形式。因此,汉语缩略语处理分成以下四种情况。
(1) 缩略语识别
缩略语识别就是判断哪些字串是缩略语,这在汉语中尤其突出。因为汉语的书面表达是汉字(有时会包含特殊字符)流,没有明显的词界限。汉语缩略语的识别包括分界和判别两个方面,对应于分词和分类(是缩略语/不是缩略语)。
(2) 缩略语与完整形式的对应关系挖掘
对应关系挖掘就是从文本中获取缩略语及其完整形式,形成缩略语与完整形式对照表,为缩略语解释服务。缩略语和完整形式很可能在文本中同现,特别是当一个新的缩略语出现的时候。在这种情况下,可以利用上下文信息获取对应关系。
(3) 完整形式的缩略: 缩略语预测
缩略语预测就是依据完整形式推测可能的缩略语。根据情况不同,缩略语预测的难度也不相同。例如,在有对照表的情况下可以利用对照表;在没有对照表的情况下,如果有上下文信息,可以利用上下文信息;最难的情况是只有“孤立”的完整形式(如信息检索的检索项),而没有任何上下文信息。
(4) 缩略语的扩展: 完整形式预测
完整形式预测是指在给定缩略语的情况下,预测对应的完整形式。这正好是缩略语预测的逆过程。
在汉语中,上述四类问题都有相应的研究。下面分别予以介绍。
3.2 汉语缩略语四类问题的研究现状
汉语缩略语研究中较有代表性的工作当属Chang[2]。他研究了汉语完整形式的缩略语预测、缩略语向完整形式的扩展及其在汉语切词中的运用。
为了在切词过程中识别缩略语,Chang会先将“疑似”缩略语按一定准则还原为完整形式,然后在没有缩略语的词序列上建立模型。Chang的这一处理实际上隐含着一个假设: 缩略语与完整形式具有等价关系。

(2)


其中PA(c|w)为已知对齐A的字符串生成概率,它可通过如下式子估算:
Chang的方法有较严格的约束,如公式(1)。此外,还要求完整形式中的每个词必须至少有一个字在缩略语中出现,将“Word-to-Null”的映射排除在外。其实,汉语中有大量的缩略语存在“Word-to-Null”的情况,例如,“甲亢”对应的“甲状腺功能亢进症”,“非典”对应的“非典型性肺炎”,“驾校”对应“汽车驾驶员培训学校”以及“国家语委”对应的“国家语言文字工作委员会”。此外,他们的方法还要求缩略后的字顺序与完整形式的出现的字顺序保持一致,没有考虑变序问题。
Chang和Teng进一步研究了通过词缩略成字,再组合生成缩略语[3]。如“台湾大学”可以看成两个词“台湾”与“大学”,其中,台湾缩略成“台”,“大学”缩略成“大”,于是“台湾大学”缩略成“台大”。这种分离加组合的模式忽视了完整形式内在的关系。例如,“北京”在形成缩略时,常取“北”;如“北大”,“北影厂”,但是,“北京棉纺厂”则缩成“京棉”,“北京郊区”缩成“京郊”。同样是“北京”,在不同情况下所取的缩略字是不一样的。
在缩略语向完整形式的扩展方面,Fu 也做了类似于Chang的工作。基本思想是将“压缩”、“截略”、“统括”三种对应关系划分成两大类,“压缩”作为第一类,“截略”和“统括”均作为第二类,两类各自生成完整形式的候选,然后再利用HMM 模型对每一候选打分[8]。
对于第一类扩展,主要利用缩略语中的短形式(主要是缩略语中的字)和可能包含该短形式的词构成映射关系,然后将映射后的词顺次连接成完整形式的候选。例如:
工: 工业/工程/工会/工作/……
委: 委员/委员会/委内瑞拉/……
由于每一个短形式(如上面的缩略字)对应的词表可能很大,通过组合后得到的候选完整形式的数目也将十分庞大。
对于第二类扩展,主要通过“缩略语—完整形式”对照表形成对应的完整形式。例如:
三通: 通邮、通商、通航;
世贸: 世界贸易组织。
当然,如果已经有了对照表,再查表是比较容易的,但通常没有这样的对照表,即便有,也是难以穷尽的,因为新的缩略语在不断增加之中。
与上述情况相对的是预测某个完整形式的缩略语,孙栩对这一问题进行了较为系统的研究[9]。这里所指的缩略语预测,是在没有上下文的情况下,孤立地对一个(或多个)词可能的缩略语进行预测。
孙栩首先研究了基于支持向量回归(SVR)的缩略语预测方法,这实际上是一种排序方法,即,对于预测的各个可能候选,通过回归方式计算得分,分值在 [0, 1] 之间,值越大,成为正确缩略语的可能性也越大。在训练时,参考答案对应的值为1,其余的情况按串的相似程度计算。在模型中,引入了五类特征模板: 映射模式特征,词特征(完整形式中的哪些词类的词可能被完全忽视,哪些词类的词中会有字保留在缩略语中),字特征,形成特征和长度特征。其中,映射模式类似于Chang的bit缩略模式;词特征则用于表示完整形式中的哪些词类的词可能被完全忽视;哪些词类的词中会有字保留在缩略语中;字特征表示哪些类型的字可能保留在缩略语中;形成特征表示了缩略语与完整形式之间的概念对应关系,例如,“上影厂”和“北工大”可以认为服从同一个概念结构“地名+行业名+机构名后缀”,并通过聚类获取这种关系。
孙栩提出的另一种方法是在序列标注的基础上引入了隐变量的模型[10]。下面图2是一般的序列标注模型和带隐变量的序列模型。
带隐变量的序列模型可以形式化为式(5):
其中,y=y1y2…ym,x=x1x2…xm,h=h1h2…hm。
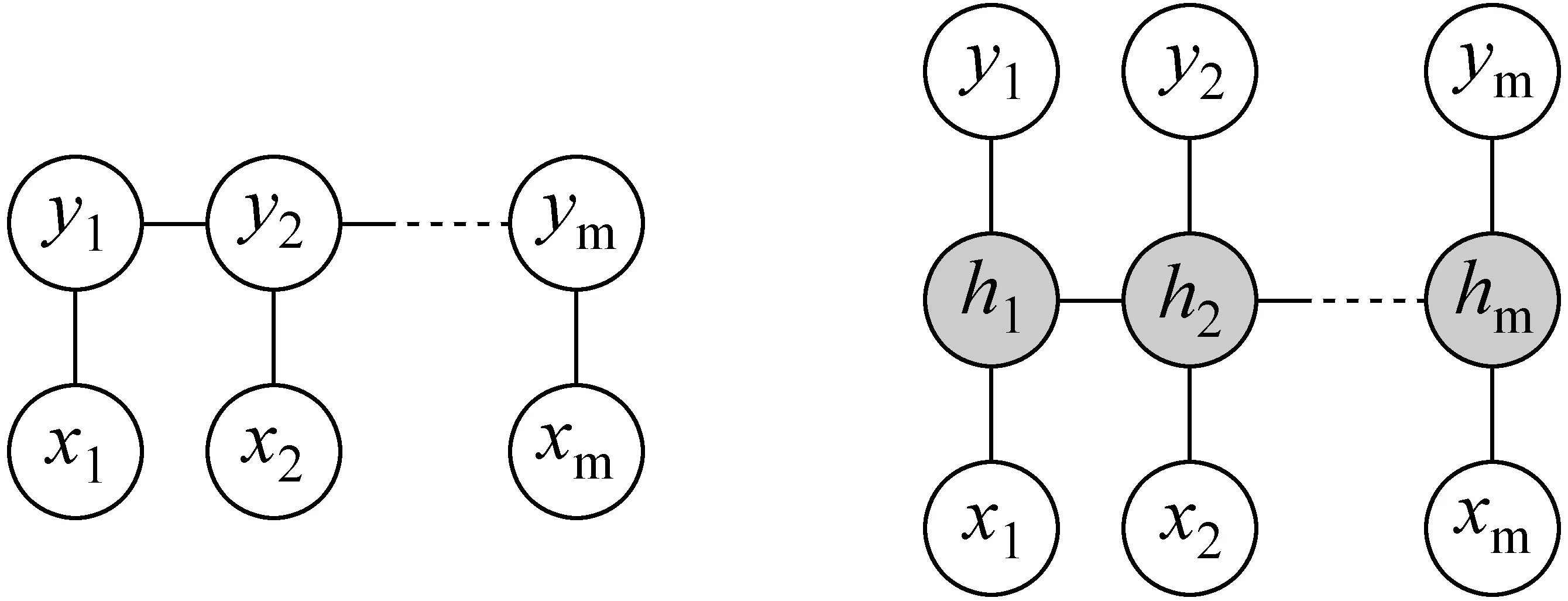
图2 一般序列标注与带隐变量的标注模型
在不带隐变量的序列标注模型,比较了两种标注方法,第一种引入标注集{p,s}: 如果某个字标成p,则该字出现在缩略语中;反之,如果标为s,则略去;第二种序列标注方法是建立p和s之间的联系,这种联系通过p的下标和s 的下标表示,基本思想如下:
(1) 第一个p的下标总是为1;
(2) 每个p的下标都是在前一个p的下标基础上加1;
(3) 每个s 的下标总是与其前面最近的p的下标一样;如果前面没有p,s的编号为0。
以“香港武术联合会”缩略为“港武联”为例,两种序列标注见图3。

图3 两种序列标注
从图3可以看出,后一种标注考虑了更大距离的上下文关联,其实验也表明,得到的结果更好。
此外,计峰针对汉语机构名(主要是公司企业名和高校名)的缩略(作者称为简称)预测也使用序列标注方式[11]。通过CRF模型对完整形式中的每个字作{0,1}标注。该方法特别强调了地名在缩略时的作用。
缩略语扩展和缩略语预测的困难都是因为缺乏缩略语与完整形式对照表,或者对照表不够全。因此,挖掘照应关系是缩略语处理的最重要任务之一。
崔世起等人研究了在大规模的语料中自动抽取汉语缩略语与对应的完整形式[12]。基本思想利用“字—词”对齐关系,辅之以概率模型抽取“缩略语—完整形式”对。不过,他们严格限定了两者之间的对应关系,规定:
(1) 缩略语中的每个字都唯一映射到完整形式中的某一个词;
(2) 完整形式中的每一个词也都唯一映射到缩略语中的某一个字;
(3) 不存在序列的重排。
上述限制与Chang的限制基本是一致的,因此,也存在类似的不足。
孙栩使用机器学习方法研究了汉语缩略语与完整形式的挖掘。以缩略语与潜在的完整形式的上下文以及两者的相对位置作为特征,进行正负类的分类判断[13]。
Li 在汉英机器翻译中,研究了缩略语的翻译问题,基本思想是将未知的汉语缩略语转换为对应的完整形式,然后再翻译为英语。为了便于转换,他们研究了在大规模的汉语语料中挖掘相应的完整形式。在挖掘中,主要用到了共现频率[14]。
Liu 通过Web 资源,研究了汉语缩略语的完整形式挖掘方法[15]。基本思想是先用部分缩略语和完整形式的对应关系作为实例,通过搜索引擎获取结果片段,学习能反映两者关系的“帮助词表”,再利用帮助词表和搜索引擎,获取含有可能完整形式候选的片段,利用启发式规则得到候选集合,再利用KNN排序得到最后的完整形式。
谢丽星利用查询日志和锚文件以及相关的URL作为桥梁,挖掘汉语缩略语和完整形式匹配对[16]。不过,查询日志的获取是一个问题。
上述挖掘方法都是用了网络资源。网络上含有丰富的信息,可以通过利用相同的链接(如机构名与其缩略相同网址)以及通过大量网络数据扩大两者同现的可能性来挖掘对应关系。
Chang工作的一个重要内容是汉语缩略语识别。即,在切词过程中,识别出汉语的缩略语。另一方面,缩略语识别可以采取排除方法,即,排除哪些不是缩略语。汉语的词可以分为一般的词典词、命名实体、数值(包括日期)以及缩略语为代表的衍生成词[17],缩略语属于衍生词。
孙栩在没有限定缩略语类型的情况下,研究了汉语缩略语的识别问题[18]。其思想是先进行分词处理,包括命名实体和日期数字识别,不能识别的部分作为“未知词”;然后再对未知词使用SVM分类器进行分类处理,以判断是否为缩略语。当然,“未知词”并不一定恰好为一个“词”,也可能包含多个。为此,该方法将缩略语的长度限定为2~4个汉字,并进行词的形态分析,视情况还可能将未知词分割为多个“词单元”。
也有研究只考虑命名实体的缩略语(或简称)识别。如Sun使用简单的启发式规则来识别人名、地名和机构名的缩略语[19]。他们分别使用了三条启发式规则:
(1) 人名缩略语: 如果一个姓后面跟了一个职务头衔,则认为此字符序列为一个人名缩略语。例如,“左/校长”。
(2) 地名缩略语: 如果两个地名缩写(有一个地名缩写表用来识别地名缩写)连续出现,则认为此字符序列在总体上也是一个地名缩写。例如,“中/日/关系”中的“中/日”。
(3) 机构名缩略语: 如果机构名缩写(有一个机构名缩写表用来识别机构名缩写)后面跟了一个地名,然后又跟了一个机构名关键词,则认为这三个部分在总体上形成了一个机构名缩略语。例如,“中共/北京/市委”。
与 Sun 类似,沈嘉懿研究了机构名简称(主要是缩略语)的识别问题,也是通过引入相应的规则实现[20]。
命名实体的缩略语规律性相对明显,处理相对容易,处理的效果也好一些。
4 英语缩略语与汉语缩略语的比较及处理特点
英语缩略语与汉语缩略语的生成方式表面上看大同小异,但实际上有着很大的不同。
其一,汉字本身具有语义,在生成汉语缩略语时,很大程度上也会考虑汉字语义的代表性。人们即便未见过缩略语的完整形式,常常也能推测可能的意义,其原因就在于此。这在英语中几乎是不可能的,因为英语的字母本身不代表特别概念;其二,由于上面的原因,汉语缩略语通常体现着某种隐含的概念结构。例如,“哈尔滨工业大学”缩略成“哈工大”,“中国科学技术大学”缩略成“中科大”,两者都具有: 地名缩略+行业属性缩略(如工业、科学技术)+分类属性缩略(大学)。同样“北京电影制片厂”(北影厂)和“亚洲游泳联合会”(亚泳联)也属于这种结构; 其三,在汉语的缩略语与完整形式之间虽然也存在一对多、多对一和多对多的关系,这种非一对一的关系相对于英语而言要少得多。
基于上述情况,两种语言的研究侧重点也有所不同。在汉语中,孤立地由完整形式预测缩略语或由缩略语预测完整形式都有一定的可行性,但在英语中,如果没有对照表和上下文,进行两种预测几乎是不可能的。因此,英语缩略语处理研究的重点之一是挖掘缩略语与完整形式的对应关系,尽可能完善对照表;此外,缩略语对应多完整形式的情况也相对严重,有研究表明,在MEDLINE摘要中,81%的缩略语有歧义,且平均义项 (sense) 数达到了16[21]。因此,英语缩略语的歧义消解是另一个重要的研究内容。下面,针对这两种情况介绍几种代表性的方法。
在对应关系的挖掘上,Park 和 Byrd利用英语习惯的文本表达形式,提出了基于规则的处理方法[22]。其一,用特殊的符号识别对应关系,例如,小括号和中括号,括号内可能就是完整形式的缩略语或缩略语对应的完整形式;其二,使用了特殊的线索词(例如,stand, short 等);其三,使用了三元组缩略规则
Chang 使用了动态规划法实现缩略语与完整形式的对齐,类似于找最长公共子序列,找出所有与缩略语对齐的完整形式候选。再从所有对齐中获得特征向量,并使用逻辑斯蒂回归进行分类,得到正确的完整形式。该方法属于有指导的机器学习方法[23]。
Schwartz 和 Hearst 提出了一个简单而快速的匹配算法来发现缩略语与对应的完整形式[24]。该算法有两个条件,其一,缩略语的第一个字符必须与完整形式的第一个词的首字符匹配;其二,缩略语中的其他字符只需要出现在潜在的完整形式中,没有位置要求,但是顺序必须一致。为了加快速度,算法按照从两者的末端反方向匹配。
Sohn等提出了一种基于准确度自动评估的缩略语与完整形式挖掘方法[25]。他们提出了17种匹配策略尽可能地覆盖不同构型的完整形式。匹配过程和匹配方法与上述Schwartz等人的方法一致,也是反向匹配,缩略语中的每个字需要匹配完整形式中的某个位置的字符,缩略语的首字符的匹配稍有变化,即,缩略语的首字符或者与完整形式的首字符匹配,或者是第一个节点(包括一般的词、复合词等)中非字母数字后的第一个字符(例如,Word-Word),此外,完整形式的长度(字符数)应大于缩略语的长度。在匹配过程中,缩略语中的非字母数字字符忽略不考虑。在多个匹配中,利用所谓的Pseudo-precision估计其精确度,以确定两者之间是否构成对应关系。
Okazaki等提出了缩略语与完整形式的判别式对齐方法[26]。基本思想是,若在某个句子中出现了缩略语(在小括号中),就在同一个句子中(如左边)找完整形式的候选,与缩略语对应的候选(有字符对应关系)可能存在多个。假设某个完整形式候选的字串形式为x=(x1,x2,…xL),缩略语字串为y=(y1,y2,…yM),其对应关系可以由对齐模式表示为a=(a1,a2,…aT),其中,每个ai记录了字之间的对应关系。例如,ai=(j,k),表示xj映射到yk;如果xj不映射到缩略语中,则,ai=(j,0);当然,如果某个yk不来自于完整形式(如汉语统括式中的数字或量词),则,ai=(0,k)。只有当xj与某个yk相同时,才有对齐ai。对齐关系可以用最大熵模型参数化:
其中,C(x,y) 是给定的 (x,y) 下可能的对齐集合。他们使用了大量的特征,同时进行组合优化。不同的对齐决定了不同的完整形式候选,决策就是取最佳的对齐关系,表示为:
(7)
在国内,也有相关研究。王宝勋等研究了英语缩略语和完整形式挖掘[27]。匹配过程与Schwartz等人的方法类似,同时,也引入系统相似模型对完整形式进行选择(过滤)。
英语缩略语与完整形式关系的挖掘相对于汉语而言要复杂一些,主要的原因是英文只有26个字母,导致可能的对应关系更多。例如,“We investigate the effect of thyroid transcription factor x: 1 (TTF1)...”,假设只考虑与缩略语“TTF1”同一个句子左边的完整形式,有8个“T”,3个“F”(假设不考虑 of ),于是完整形式的候选可以有“transcription factor x: 1”、“thyroid transcription factor x: 1”、“effect of thyroid transcription factor x: 1”等多个[26]。
英语缩略语歧义消解的研究也有不少,从本质上看,这一问题可以归结为词义消歧。因此,词义消歧方法可以用于缩略语消歧中。Stevenson等人作了类似研究[28]。他们使用Naïve Bayes 和 SVM 两种有指导的方法,在特征上使用了三类: (1) 缩略语的上下文特征,包括左右搭配特征(词和词性2-gram和3-gram),凸显的2-gram特征以及目标词左右窗口内的unigram特征等,这是词义消歧中最常使用的特征;(2) 概念唯一性标识(Concept Unique Identifiers,CUI)特征,语料在预处理后,每个词(term)都会映射到UMLS定义的 CUI,对于歧义的词(Term),映射后可能对应一个集合。例如句子,“Lean BSA was obtained from height and lean body weight ...”,先分成几个Chunk,Lean BSA是其中的一个Chunk。映射后,对应三个CUI: “C1261466: BSA (Body surface area)”,“C1511233: BSA (NCI Board of Scientific Advisors)” and “C0036774: BSA (Serum Albumin, Bovine)”,如果某个CUI在一个摘要中出现多于2次,便选择为特征,这类特征在医学文本的词义消歧中也常常使用;(3) 最后一类特征也是与医学领域密切相关的特征,称为Medical Subject Headings (MeSH),这是一部与生物医学和健康相关的受控词典,用于手工对文本(摘要)进行标引。
Pakhomov也研究了临床报告中的缩略语消歧问题[21]。他们在临床报告中“随机”选择了8个缩略语进行实验,义项数最少2个,最多13个,8个缩略语长度为2 或 3个字符。主要研究了半指导消歧方法,使用C5.0和基于实例的相似度方法。其中,半指导主要体现在训练语料的构造上,通过收集不同义项的语料作为训练数据。语料来源于Web网,医学领域特定的网站以及临床报告相关的数据,语料的获取方法是用完整形式作为检索条目,通过调用Google的API返回相应“义项”的上下文,在此基础上再形成特征向量。
英语缩略语处理的研究也大多针对生物医学领域的文本。一方面,生物医学上的缩略语特别多,另一方面,有相应的评测数据。汉语缩略语处理的研究并没有集中在某个特定的领域,评测语料的建立也是一个问题。
5 结束语
本文主要考察了汉语的缩略语的语言现象及其对自然语言处理的影响,并对生成方式作了分析。针对汉语缩略语对自然语言处理不同层面的影响,本文将汉语缩略语处理划分为四种不同的类别,包括缩略语识别、缩略语到完整形式的扩展、完整形式到缩略语的预测以及缩略语与完整形式对应关系的挖掘。然后,结合这四类问题,对汉语缩略语的研究现状分别作了介绍和评述。
英语缩略语处理有自身的特点,本文比较并分析了英语缩略语与汉语缩略语的区别以及处理上的不同,同时,对英语缩略语两类处理的典型方法作了总结。
在自然语言处理中,特别是在中文信息处理中,对缩略语处理的研究还不太多,特别是缩略语研究所需资源相对匮乏。目前,北京大学虽然已经做了一些工作,例如,收录了8 000多对缩略语—完整形式对照表,在《人民日报》的一部分语料上标记了缩略语以及同现的完整形式对应关系,但规模不大。加强缩略语的资源建设仍然是缩略语研究的一项基础性工作。
本文将汉语缩略语处理分成四种情况,最核心的问题则是通过分析缩略语与完整形式之间的对应关系,揭示缩略语本身的表层构成特点和深层概念结构。表层构成特点有助于缩略语自动识别,深层概念结构有助于解释缩略语。但为了尽可能完整地分析之间的关系,需要获得大规模的对照表,因此,从大规模语料中自动挖掘两者之间的对应关系也将是我们要重点研究的问题之一。
[1] Manuel Zahariev. ACRONYMS[D]. PHD thesis, Simon Fraser University, 2004.
[2] J.Chang, Y.Lai. A Preliminary Study on Probabilistic Models for Chinese Abbreviations[C]//Proceedings of the Third SIGHAN Workshop on Chinese Language Learning, 2004, Barcelona, Spain.
[3] J. Chang, W. Teng. Mining Atomic Chinese Abbreviation Pairs: A Probabilistic Model for Single Character Word Recovery[C]//Proceedings of the Third SIGHAN Workshop on Chinese Language Learning, 2006, Sydney, Australia.
[4] 黄昌宁,赵海. 中文分词十年回顾[J]. 中文信息学报,2007,21(3): 8-19.
[5] Michael Halliday, Ruqaiya Hasan: Cohesion in English[M]. London: Longman. 1976.
[6] 马庆株. 缩略语的性质、语法功能和运用[J]. 语言教学研究,1987,(3): 20-27.
[7] 张小克. 现代汉语缩略语新论[J]. 广西民族学院学报(哲学社会科学版),2004, 26(3): 112-116.
[8] Guohong Fu, Kang-Kuong Luke, Min Zhang, Guo-Dong Zhou. A Hybrid Approach to Chinese Abbreviation Expansion[C]//Proceedings of ICCPOL. LNAI 4285, 2006, Springer.
[9] Xu Sun, Hou-Feng Wang, Bo Wang. Predicting Chinese Abbreviations from Definitions: An Empirical Learning Approach Using Support Vector Regression[J]. Journal of Computer Science and Technology. Jul. 2008, 23(4): 602-611.
[10] Xu Sun, Naoaki Okazaki, Jun′ichi Tsujii. Robust Approach to Abbreviating Terms: A Discriminative Latent Variable Model with Global Information[C]//Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP. Suntec, Singapore, 2009.
[11] 计峰,高沫,邱锡鹏,等. 中文机构名简称的自动生成研究[C]//孙茂松,陈群秀. 中国计算语言学研究前沿进展,北京: 清华大学出版社,2009: 546-550.
[12] 崔世起, 刘群,林守勋,等. 中文缩略语自动抽取初探[C]//孙茂松,陈群秀. 自然语言处理与大规模内容计算,北京: 清华大学出版社,2005: 53-58.
[13] Xu Sun, Houfeng Wang, Yu Zhang. Chinese Abbreviation-Definition Identification: A SVM Approach Using Context Information[C]//Proceedings of PRICAI 2006: Trends in Artificial Intelligence. LNAI-4099, Springer, 2006.
[14] Zhifei Li, David Yarowsky. Unsupervised Translation Induction for Chinese Abbreviations using Monolingual Corpora[C]//Proceedings of ACL-08: HLT, 2008.
[15] Hui Liu, Yuquan Chen, Lei Liu. Automatic Expansion of Chinese Abbreviations by Web Mining[C]//Proceedings of the International Conference on Artificial Intelligence and Computational Intelligence. LNAI 5855, 2009, Springer.
[16] 谢丽星,孙茂松,佟子健,等. 基于用户查询日志和锚文字的汉语缩略语识别[C]//孙茂松,陈群秀.中国计算语言学研究前沿进展.北京: 清华大学出版社,2009:551-556.
[17] J. Gao, M Li, C. Huang. Improved Source-channel Models for Chinese Word Segmentation[C]//Proceedings of the 41st Annual Meeting of Association for Computational Linguistics (ACL). 2003, July: 8-10, Sapporo, Japan.
[18] Xu Sun, Houfeng Wang. Chinese Abbreviation Identification Using Abbreviation-Template Features and Context Information[C]//Proc. of ICCPOL-2006, LNAI-4285, 2006.
[19] J. Sun, J. Gao, L. Zhang, M. Zhou, C. Huang. Chinese Named Entity Identification Using Class-based Language Model[C]//Proceedings of the 19th International Conference on Computational Linguistics(COLING), Taipei, 2002.
[20] 沈嘉懿,李芳,徐飞玉,等. 中文组织机构名称与简称的识别[J].中文信息学报,2007,21(6):17-21.
[21] S. Pakhomov, T. Pedersen, C.G. Chute. Abbreviation and Acronym Disambiguation in Clinical Discourse[C]//Proceedingd of the American Medical Informatics Association Annual Symposium, Washington, DC. 2005.
[22] Y. Park, R.J. Byrd. Hybrid Text Mining for Finding Abbreviations and Their Definitions[C]//Proceedings of the 2001 Conference on Empirical Methods in Natural Language Processing, Pittsburgh (USA). 2001 : 126-133.
[23] Chang JT, Schutze H, Altman RB. Creating an Online Dictionary of Abbreviations from MEDLINE[J]. JAMIA, 2002, 9(6).
[24] Schwartz A, Hearst M. A simple algorithm for identifying abbreviation definitions in biomedical texts[C]//Proceedings of the Pacific Symposium on Biocomputing, 2003.
[25] Sohn S, Comeau DC, Kim W, Wilbur WJ. Abbreviation definition identification based on automatic precision estimates[J]. BMC Bioinformatics, 2008,(9).
[26] N. Okazaki, S. Ananiadou, J. Tsujii. A Discriminative Alignment Model for Abbreviation Recognition[C]//Proceedings of the 22nd International Conference on Computational Linguistics (Coling 2008). Manchester, UK.
[27] 王宝勋, 王晓龙, 刘秉权, 等. 一种基于无监督学习的词变体识别方法[J].中文信息学报,2008,22(3): 32-36.
[28] Mark Stevenson, Yikun Guo, Abdulaziz Al Amri, Robert Gaizauskas. Disambiguation of Biomedical Abbreviations[C]//Proceedings of the Workshop on BioNLP, 2009.
