基于可信度模型的中文人名识别研究
2011-06-14朱巧明李培峰
倪 吉,孔 芳,朱巧明,李培峰
(苏州大学 计算机科学与技术学院,江苏 苏州 215006;江苏省计算机信息处理技术重点实验室,江苏 苏州 215006)
1 引言
命名实体识别是文本信息处理的基础,在机器翻译、信息检索、自动问答、知识管理、实体关系抽取等应用领域中都有重要的作用。命名实体识别首先在MUC-6上作为子任务提出[1],主要任务是识别文本中人名、地名、机构名、时间表达式、数量表达式等。由于中国人名在实体中所占的比例较大,据统计,在《人民日报》1998年1月的语料库(2 305 896字)中,平均每100个字包含未登录词1.192个(不计时间词和数量词),其中48.6%的实体是中国人名[2],另外中文语义复杂,中国人名的用字又具有很大的任意性,所以中国人名的识别是命名实体识别任务中主要任务和主要难点之一。
2 相关工作
虽然中文命名实体的研究相比英语命名实体识别尚处于不成熟阶段,但在中文人名识别上也已经有了不少的研究,主要有基于规则和基于语料库统计[3-6]的人名识别方法,这类方法的核心是统计人名用字在语料中的频率,通过计算概率来确定文本中的候选人名为确定人名的可能性;罗智勇等[7]提出的基于可信度的中国人名识别方法也是统计人名的用字频率作为人名的可信度,但他在统计人名用字概率时去除了人名用字在语料中作为普通词出现的情况,是一种解决传统统计误区的方法;李中国等[8]提出了基于边界模板和局部统计相结合的中国人名识别方法,该方法从标注语料库中抽取边界模板,利用边界模板对人名进行粗略定界,然后根据局部统计量和启发式规则对识别结果进行校正;另外,贾宁等[9-11]使用了机器学习模型对人名进行识别。上述方法通常会受到训练语料规模的约束,所以如何在有限语料库基础上提高统计数据的有效性,充分利用语料库中的知识,从而使整体识别性能得到提高也是重要的研究方向之一。除此之外,文献[12]指出了目前命名实体系统准确率较高而召回率较低的情况,该文基于CRFs使用0/1标签方法和Non-local特征来提高系统的召回率,所以如何在保证准确率的同时能有效地提高召回率也是目前命名实体识别系统需要解决的问题之一。
本文在前人研究的基础上,利用标注语料库和人名相关的知识库,研究了中国人名形成的特征,定义了人名可信度的计算方法,并通过实验将可信度模型嵌入到基准系统中,着重研究了可信度模型对已有命名实体识别系统中人名识别召回率提高的作用。实验证明,可信度模型对中国人名识别性能提高有一定的帮助,也说明本文的可信度模型在考虑人名成词时更具有完整性。
3 可信度模型
可信度模型是通过计算人名内聚度、人名区分度(文献[2]和文献[7]中就将其称为可信度)和边界模板可信度的综合概率,判断某个候选人名确实为人名的可信程度。人名可信度模型主要用途包括两个方面: 第一,对系统已标注的人名通过计算其可信度判断该人名是否识别正确,主要针对一些低准确率的情况;第二,对系统未识别的人名进行补充识别,是一种使用可信度模型解决低召回率问题的方法。
3.1 人名内聚度
通常,一个完整的中国人名由姓字(SN)、姓名首字(FN)、姓名尾字(LN)组成。其中姓名首字特指字数超过两字的人名的中间用字,例如孙中山的“中”字。假设中国人名在文本中出现不超过四字,于是我们定义人名的出现有以下几种形式:
四字: SN(复姓)|FN|LN,SN|SN|FN|LN(港澳台的已婚妇女),还有较少的SN|FN|FN|LN和SN|FN|LN|LN;
三字: SN|FN|LN,SN(复姓)|LN,SN|SN|LN
二字: SN|LN,FN|LN
单字: SN,LN
人名内聚度的概念是借鉴于“物以类聚”的思想,即人名常用字也会以一定的强度聚在一起,即一个字符序列若为人名,则这个序列是由人名常用字聚集而成,也可以这么认为: 若某个字为SN,则紧接着很有可能出现FN、LN,这些连续的字内聚成人名的可能性则比较大。如果SN后紧接的字不为FN或LN,则可以认为这两个字内聚成人名的概率为0(内聚不考虑单字人名的情况)。也就是说,内聚度的强弱说明了连续的几个字内聚成人名的概率大小,而这种内聚强度在本文中采用了人名用字的常用程度来体现。
我们从网络上收集了8万多中国常见人名,记录所有不同的SN、FN和LN用字以及它们分别出现的次数(表1),并计算每个不同SN(FN、LN)用字在SN(FN、LN)总数中的比例,记为Cohe(XNi),XNi表示SN、FN或LN中的第i个字,计算方法如公式(1)所示。
(1)
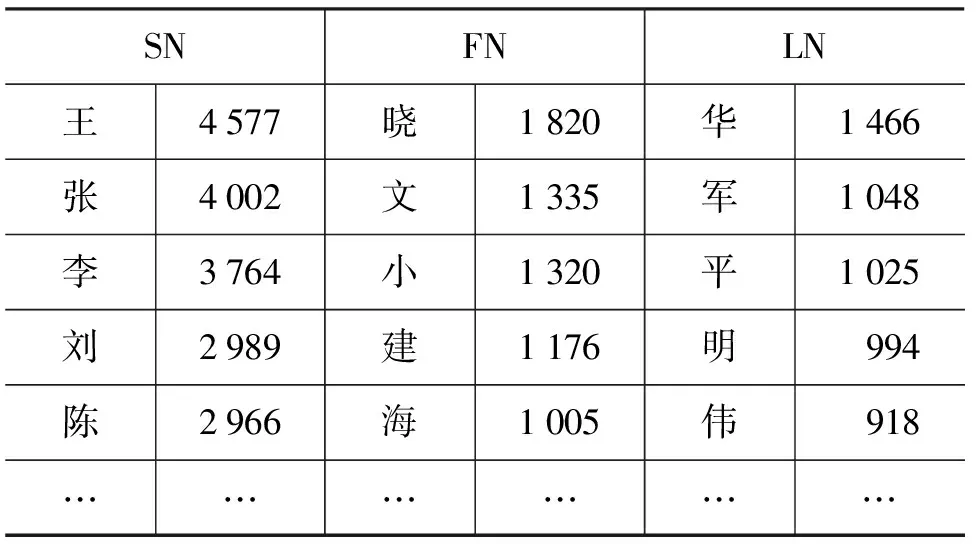
表1 SN、FN、LN统计结果
表1的数据实际上反映了每个字作为人名的常用程度,所以Cohe(XNi)值越大表示XNi作为XN出现机会越大。定义WN=C1C2...Cn为连续的字符序列,则WN的内聚度记为Cohe(WN)。由于收集的人名中复姓、港澳台姓名都较少,为了保证内聚概率的可靠性,我们仅计算WN符合上述中国人名出现形式中SN|FN|LN和SN|LN时的Cohe(WN),即:
除此之外,对于有名无姓的形式FN|LN和LN,有姓无名的情况SN,由于这些形式都有其在文本中出现的特殊情况,首先,一般在上文中出现了人名的全名,后文才会使用简称;其次,若为SN是人名,则往往以老|小SN、SN某、SN称谓词等搭配形式出现。所以可以单独采用规则的算法进行处理。
3.2 人名区分度
人名内聚度从人名用字的常用程度及通过这种常用程度反映的字串序列间的内聚度来决定这个字串成为人名的可信程度。但是在文本中,每一个SN、FN、LN用字都有可能是普通用字。例如,表1中的“王”字,虽然是中国人名的大姓,但是“王”字作为普通用字的时候也很多,如“大王”、“王爷”;又如“刘”字,虽然其从统计中获得常用程度不如“王”,但它的区分度较高(表2),则“刘”字在文本中作为姓字的概率也会很高。所以我们需要为每个人名常用字定义一个区分于普通用字的概率,记为Diff(Ni)。人名区分度是根据每个字的Diff值,综合计算一个字符序列是人名还是普通字词的区分概率。区分度的计算需要语料库的支持,设2.1节中获得的人名常用字为C,C综合了SN、FN、LN,则Diff(C)的计算方法如公式4所示。
本文考虑到分词错误可能会带来的统计错误,例如,句子“对白/n 晓/v 燕/n 说起/v”进行切分后使用文献[7]中的统计方法会对“白”字的统计产生偏差,所以本文采用了传统基于字的统计方法,通过内聚度和区分度的综合来减少传统统计的不合理之处;本文利用微软研究院(MSRA)标注的训练文件进行统计,统计结果如表2所示,从表2中可以看出,表1中常用的人名用字可能其区分度并不高,而表2中区分度高的用字,在表1中得到的出现次数并不多,所以内聚度和下文定义的人名区分度是决定人名可信度共同的内部因素。
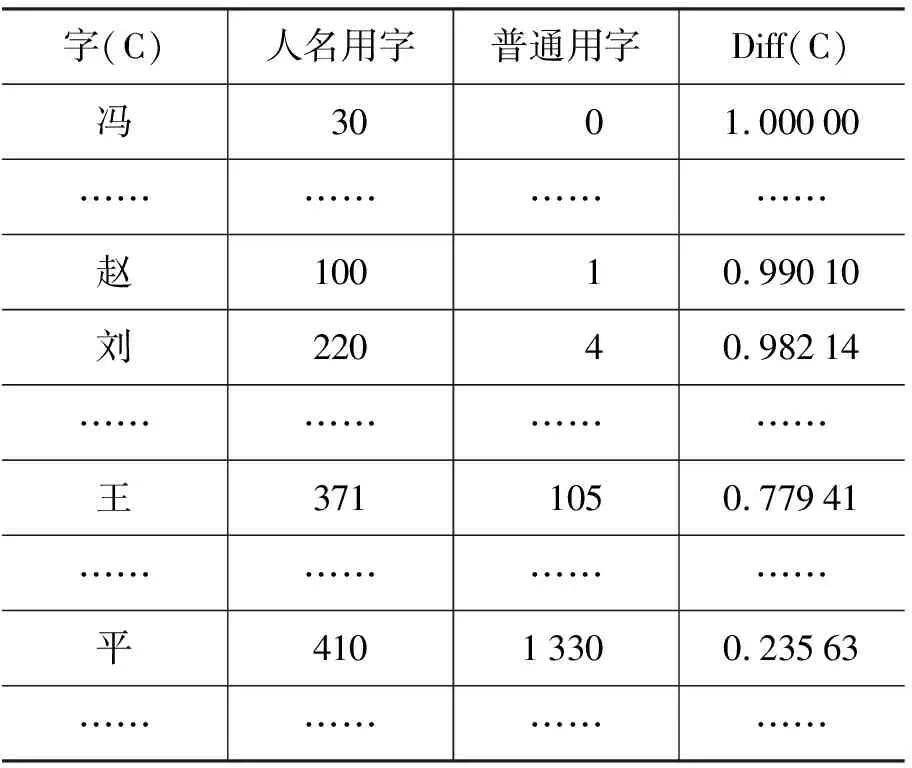
表2 人名常用字区分度
根据区分度的定义,设WN=C1C2…Cn为人名估计字符序列,我们认为只有当WN中的每个字都为非人名用字时,该WN才不是人名;否则,如果存在任意Ci表现为人名用字时,该WN都有可能为人名。所以,序列WN的人名区分度可用公式(5)表示。
(5)
区分度是指区别一个字是人名用字或是普通用字的能力。但是仅靠区分度参数进行判定时会遇到一些困难,例如,“张”字,其统计获得的区分度仅为0.422 68(“张”的人名用字次数为287,普通用字次数为392),则从区分度参数很难判断“张”是否为姓字。而通过综合“张”字作为人名的常用程度考虑会使判定更具有可靠性。
3.3 边界模板可信度
人名内聚度和区分度都是根据人名的内部信息计算人名的可信程度。边界模板可信度则是通过人名的上下文边界统计信息来计算可信度。
本文实验系统中使用的边界模板集合是从MSRA的标注语料中获得,统计和记录模板及其出现的次数,如出现次数较多的模板有“记者 PER 报道”、“、 PER 、”、“| PER 说”、“, PER 、”、“| PER 在”…… 其中“|”表示句首。类似与人名区分度,处于边界模板之间的字词不一定为人名,例如对于模板“、 PER 、”,顿号之间可能是地名、普通形容词、名词等,所以我们也统计了所有模板在标注语料中出现的总次数,以计算模板作为人名边界的概率。由于本文主要是对于中国人名边界模板的处理,在统计每个模板总数时,只考虑了模板间字数小于4的情况。
在上述统计到边界模板中,不管模板作为人名边界的概率有多大,只要在边界模板之间的字词都有可能为人名,所以不能因为作为边界模板的概率低而使模板之间的人名可信度降低,所以我们定义的模板可信度如公式(6)所示。
(6)
公式(6)的定义主要是为了体现边界模板对人名可信度的加强作用,所以人名的可信度模型定义可如公式(7)所示。
K(WN,PER)=Cohe(WN)*Diff(WN)*Tj
(7)
特殊地,当边界模板在模板集合中不存在时,Tj=1。
4 实验和结果分析
本文使用微软亚洲研究院(MSRA)标注的语料进行实验,首先建立基准平台,用于人名的初步识别,之后使用可信度模型对初步结果文本进一步处理,最后得到整个系统的最终识别结果。系统流程如图1所示。
4.1 基准平台
基准平台是系统对待识别文本进行的初步处理,本文使用CRFs分类器和MSRA标注的训练语料训练形成模型,使用的特征有一元特征(w0),窗口大小为2,即考虑前后各两个单元(w1,w2,w-1,w-2);二元特征(w0/w1,w-1/w0);三元特征(w-2/w-1/w0,w-1/w0/w1,w0/w1/w2)。其中,w0表示当前位置的字面特征,w-i表示从当前位置往分析方向相反的第i个字,w+i表示从当前位置与分析方向一致的第i个字,二元和三元特征都为组合特征。基准平台即是通过上述特征训练形成的模型对源文本进行人名识别。
使用MSRA提供的测试文本对基准平台进行测试,初步识别结果的性能如表3所示。
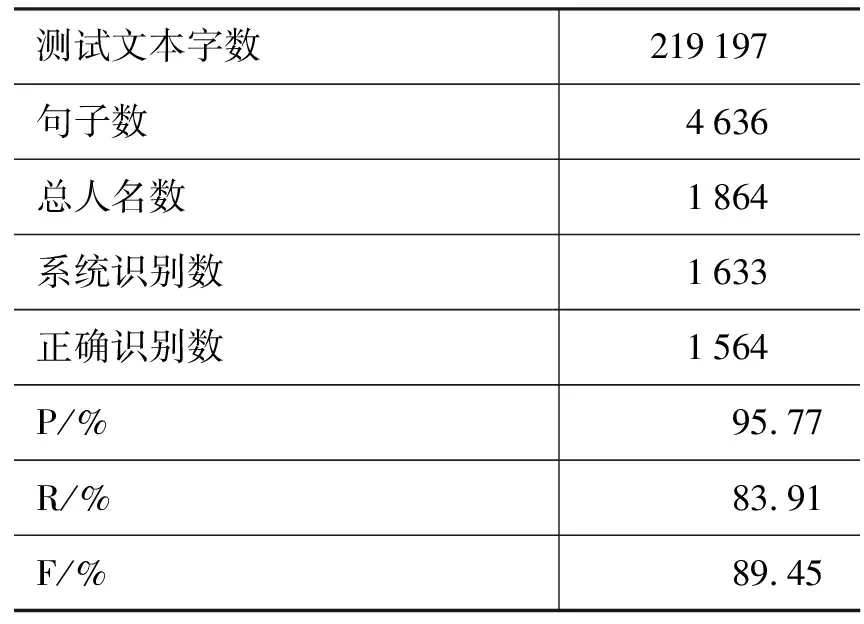
表3 基准平台识别性能
4.2 可信度模型实现
可信度模型的核心是通过计算一个字符序列内聚度、区分度和边界模板可信度的综合概率来衡量该字符序列作为人名的可靠性程度,其中区分度和模板可信度的数据即为第二节中介绍的方法获得,只是对内聚度的数值进行了转换: ①根据公式(2)和公式3计算SN|FN|LN和SN|LN的初始内聚度;②确定Cohe值的范围分别为4.1E-5~3.4E-15、1.3E-3~1.9E-10;③将步骤②中Cohe值按表4进行转换,本实验中C的取值为0.9。
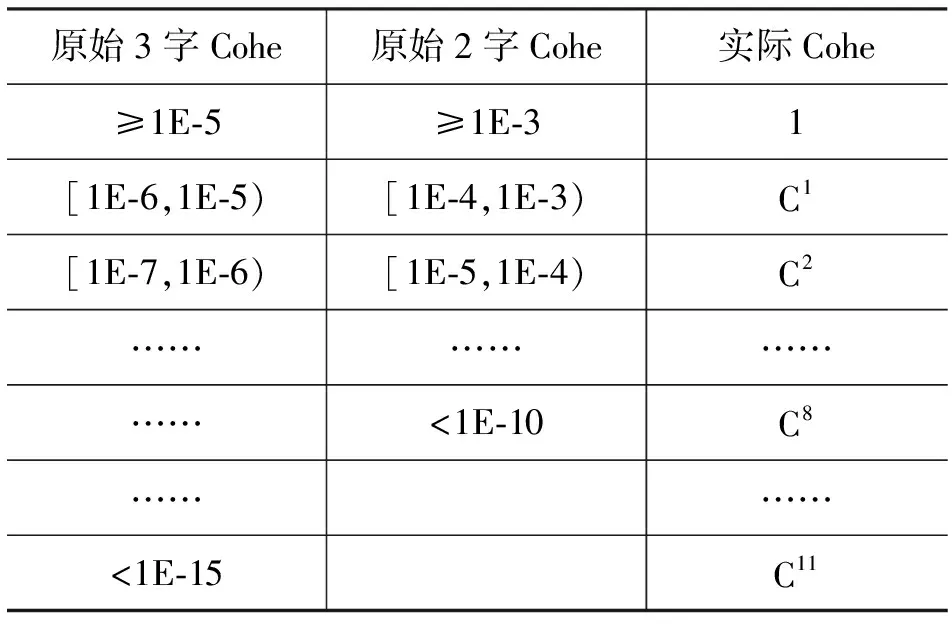
表4 Cohe转换表
另外,影响内聚度的因素还包括内聚的字及其上下文的成词情况,以下列举了3条常用的启发式规则,存在这些情况,则会使Cohe值降低: 设字符序列为:
S=…C1C2SNFNLNC3C4…(…C1C2SNLNC3C4…),
① (C1C2) is not phrase AND (C2SN) is phrase AND FNLN is phrase;
② (C3C4) is not phrase AND (LNC3) is phrase AND SNFN is phrase;
③ SNFNLN(SNLN) is Phrase;
4.3 实验结果分析
本节通过使用可信度模型对基准平台输出的初步结果进行了人名的再识别,主要是为了能提高整个系统的召回率,其过程是对整个文本中已识别为人名的字串不作任何处理,只对文本中其余部分进行再识别,识别的方法是以姓字(SN)为驱动,由姓字(SN)及其紧随的单字或双字组成字串序列,采用可信度模型计算词语序列(SN+LN)和(SN+FN+LN)的可信度概率,取两者中较大值,若该值大于设定的阈值δ则认为该词语序列为人名。在MSRA语料上封闭测试的实验结果如表5,表6所示,表5的结果是使用传统区分度作为可信度,表6则是综合了内聚度、区分度和边界模板来计算可信度的结果。
从表5的数据可以看出,随着阈值δ的降低,在召回率提高的同时精确率下降得很快,这说明了只使用区分度作为可信度缺乏稳定性,引入内聚度和边界模板正是为了在提高召回率的同时更好地保证识别的精确率。从表6可以看出, 召回率提高对精确率的损失影响比较平滑,并且在δ取0.4时,可信度模型对原有系统性能的提升最大,召回率提高了4.3%,而准确率仅下降了0.24%,从而使F提高了2.27%,高于原始可信度模型对系统F值性能提高的0.87%。

表5 传统可信度模型识别结果
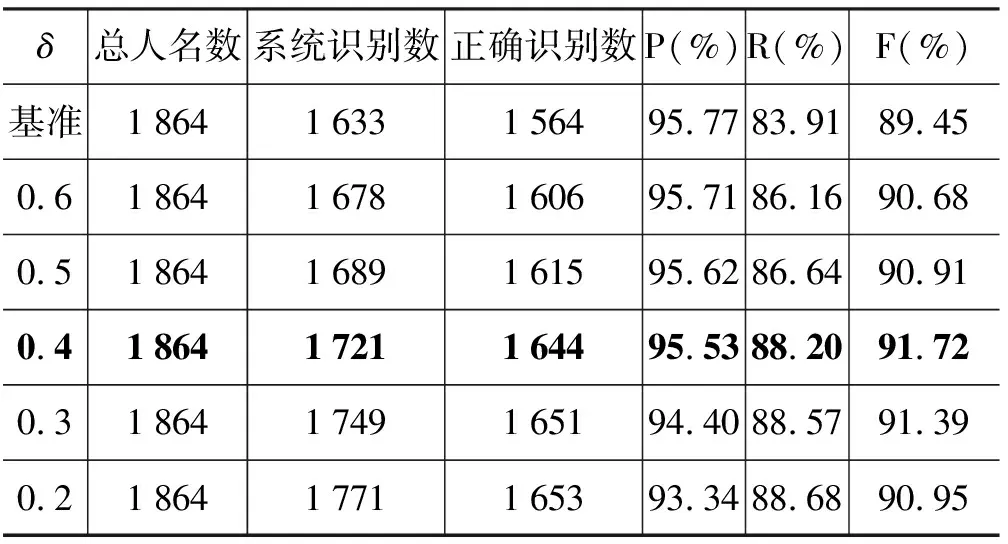
表6 加入内聚度和边界模板的可信度模型识别结果
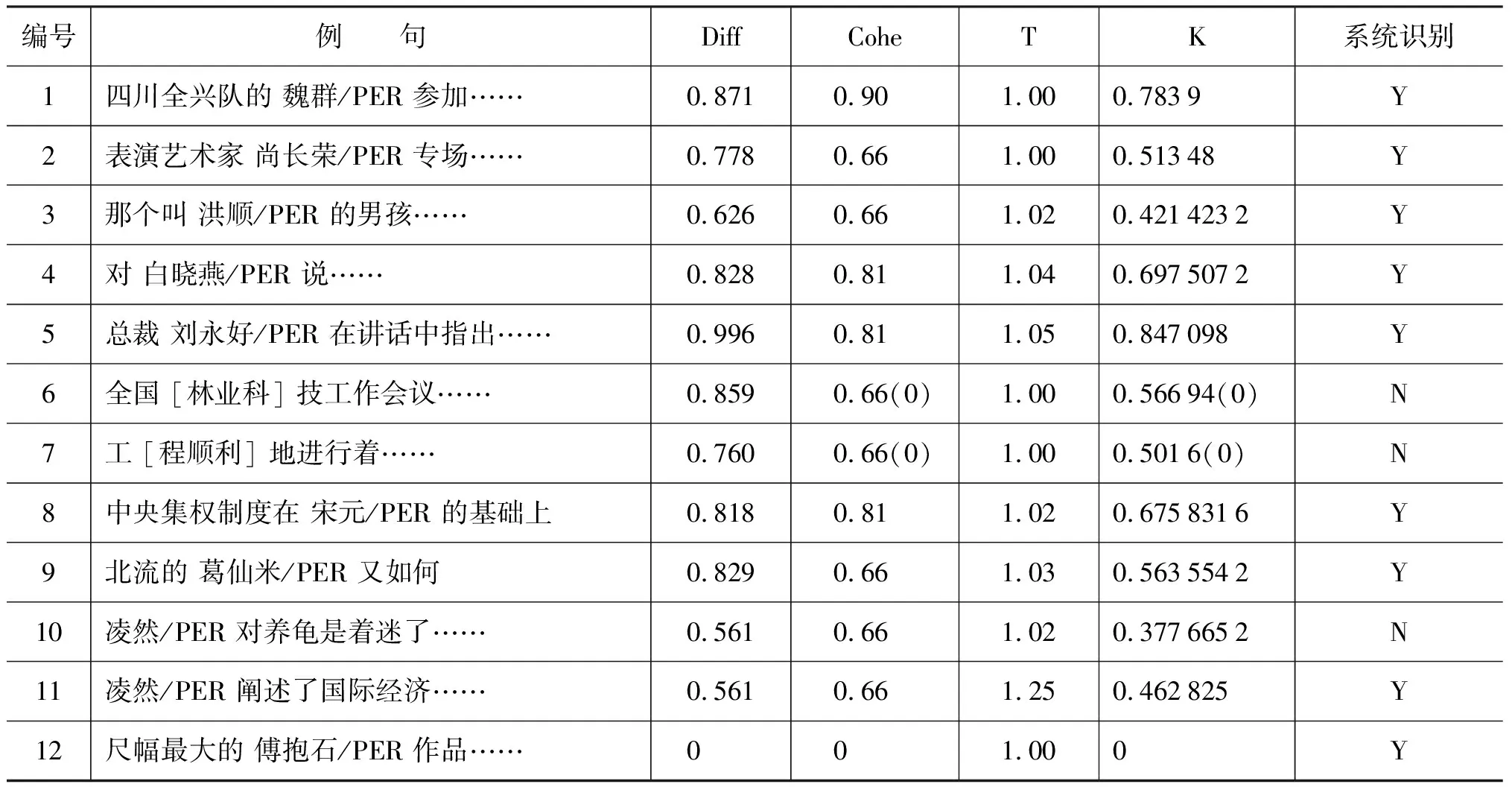
表7 系统识别结果示例
在表7列出的系统识别结果中,例句1、2、3是基准平台未能识别而通过可信度模型识别的人名;例句4、5反映了分词对人名识别的影响[13],其中“对白”、“好在”都会在分词时被作为普通词从而影响到人名的识别,所以本文只是将分词信息作为内聚度计算的辅助信息;例句6、7反映了不分词对识别的影响,其中“林业科”、“程顺利”都会被误识别为人名,所以4.2节中计算内聚度引入了启发式规则;例句8、9是可信度模型识别错误的人名;例句10是可信度模型未能识别的人名,因为人名“凌然”的可信度为0.37,小于识别性能最好的阈值0.4;例句11假设人名“凌然”出现在边界模板“| PER 阐述”之间,由于“| PER 阐述”的模板可信度较高,所以“凌然”可以被识别为人名,该例句说明了边界模板对人名识别的作用;例句12中人名“傅抱石”在基准平台中可以被识别,而使用可信度模型不能识别,原因是“抱”字在统计的人名信息中不存在,使得“傅抱石”成为人名的可信度为0,这也反映了统计方法存在的缺陷,所以本文将可信度模型作为模块嵌入到基础平台。
5 总结与展望
本文提出了一种计算中国人名可信度的方法,通过内聚度、区分度和边界模板可信度的综合概率来衡量一个字串序列为人名的可靠程度,并将实现的可信度检测模块嵌入到一个简单的人名识别系统中,可以对系统已识别的人名进行纠正,也可以对系统未识别的部分进行再识别。本文的实验说明了可信度模型的有效性,另外,实验中将可信度模型嵌入到基于CRFs的基准平台,是为了将统计方法可能带来的偏差缩小在一个较小的范围,能够在损失较小准确率的前提下提高召回率。可信度模型可以独立于已有命名实体识别系统存在,单独地对人名进行判断,但其性能对统计信息的可靠性及相对应的启发式规则的要求较高,需要更进一步地研究和完善。由于使用的测试语料中包含了大量的译名,而可信度模型是对于中国人名的判断,所以对整个系统人名识别性能的提升也存在局限性。
本文对内聚度的计算只考虑了SN|FN|LN和SN|LN的情况,下一步的工作可以增加人名内聚情况以提高可信度模型的覆盖程度。另外,区分度和内聚度已经很好地反映了一个人名的内部信息,但是人名的外部信息边界模板并没有充分发挥其作用,所以更好地制定边界模板可信度的计算策略对人名的识别也有重要的作用。之后可以尝试将可信度模型的计算方法应用到译名、地名、机构名的识别中。
[1] Sundheim B M. Named entity task definition, version 2.1[C]//Proceedings of the Sixth Message Understanding Conference. Morgan Kaufmann, California, 1995:319-332.
[2] 张素香. 信息抽取中关键技术的研究[D]. 北京: 北京邮电大学, 2007.5.
[3] Li Jianhua,Wang X.L.An Effective Method on Automatic Identification of Chinese Name[J].High Technology Letters. 2000, 10(2): 46-49.
[4] 黄德根,杨元生等. 基于统计方法的中文姓名识别[J]. 中文信息学报, 2001,15(2): 31-37.
[5] 刘秉伟,黄萱菁等. 基于统计方法的中文姓名识别[J]. 中文信息学报, 2000,14(3): 16-24,36
[6] 郑家恒,李鑫,谭红叶. 基于语料库的中文姓名识别方法研究[J]. 中文信息学报, 2000, 14(1): 7-12.
[7] 罗智勇,宋柔. 一种基于可信度的人名识别方法[J]. 中文信息学报, 2005, 19(3): 67-72,86.
[8] 李中国,刘颖. 边界模板和局部统计相结合的中国人名识别[J]. 中文信息学报, 2006,20(5): 44-50,57.
[9] Zhou Guodong, Su Jian. Named Entity Recognition using an HMM-based Chunk Tagger[C]//Proceedings of the 40thAnnual Meeting of the Association for Computational Linguistics. Philadelphia, USA, 2002:473-480.
[10] 贾宁,张全. 基于最大熵模型的中文姓名识别[J]. 计算机工程, 2007, 33(9): 31-33.
[11] 王志强. 基于条件随机域的中文命名实体识别研究[D]. 南京: 南京理工大学, 2006.8
[12] Mao Xinnian, He Saike, Bao Sencheng, Dong Yuan and Wang Haila. Chinese Word Segmentation and Named Entity Recognition Based on Conditional Random Fields[C]//Proceedings of the Sixth SIGHAN Workshop on Chinese Language Processing, Hyderabad, India, 2008:90-93.
[13] 张跃,姚天顺. 基于结合性自动识别中文姓名[J]. 小型微型计算机系统, 1997, 18(10): 43-48.
[14] 张华平,刘群. 基于角色标注的中国人名自动识别研究[J]. 计算机学报, 2004, 27(1): 85-91.
